# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在生成式 AI 的浪潮中,自回归(Autoregressive, AR)模型凭借其卓越的性能占据了统治地位。然而,其「从左到右」逐个预测 Token 的串行机制,天生限制了并行生成的可能性。
作为一种极具潜力的替代方案,扩散语言模型(Diffusion Language Models, dLLMs) 引入了全新的非自回归范式:通过迭代去噪来优化文本序列 。这种机制不仅支持双向上下文建模,更允许并行更新多个 Token,为更快的生成速度和更强的可控性打开了大门。
但在「美好愿景」与「实际落地」之间,横亘着一道巨大的鸿沟 —— 效率。
相比于高度成熟的 AR 模型,dLLM 面临着训练成本高昂、推理步骤繁琐、KV Cache 难以复用等棘手问题 。为了厘清这一新兴领域的关键技术路径,自动化所、香港中文大学与香港大学等机构撰写了一篇最新的综述论文,该综述系统地梳理了高效 dLLM 的研究进展,从训练、推理、上下文及系统框架等维度,拆解 dLLM 是如何一步步跨越效率瓶颈的。


dLLM 若要从头训练,不仅数据需求大,算力消耗也极其惊人。因此,如何「借力」现有的预训练模型成为关键。
论文将训练侧的提效策略主要归纳为 「AR 到 dLLM 的迁移」 与 「架构优化」。
与其从零开始,不如利用已有的 AR 模型权重。DiffuLLaMA 和 Dream 等工作探索了通过调整注意力掩码(Attention Mask)或引入特定的过渡微调阶段,将 AR 模型的能力「蒸馏」或「转换」为扩散模型 。更有趣的是 Block Diffusion(块扩散) 的思路,它保留了部分自回归的结构(块与块之间串行),但在块内部进行并行扩散,这种折中方案在保留 AR 预训练优势的同时,显著降低了适应成本 。
为了减少计算量,研究人员开始对架构动刀。E2D2 采用了编码器 - 解码器(Encoder-Decoder)架构,让编码器处理清晰的输入,解码器专注于去噪,从而复用特征并降低训练成本 。此外,MoE(混合专家) 架构也被引入 dLLM(如 LLaDA-MoE),通过稀疏激活在保持模型容量的同时减少推理时的参数计算量 。
推理速度是 dLLM 能否落地的核心痛点。由于扩散过程本质上是多步迭代,如果每一步都全量计算,延迟将无法接受。综述将推理加速主要分为 「并行解码」 和 「压缩技术」 两大类。
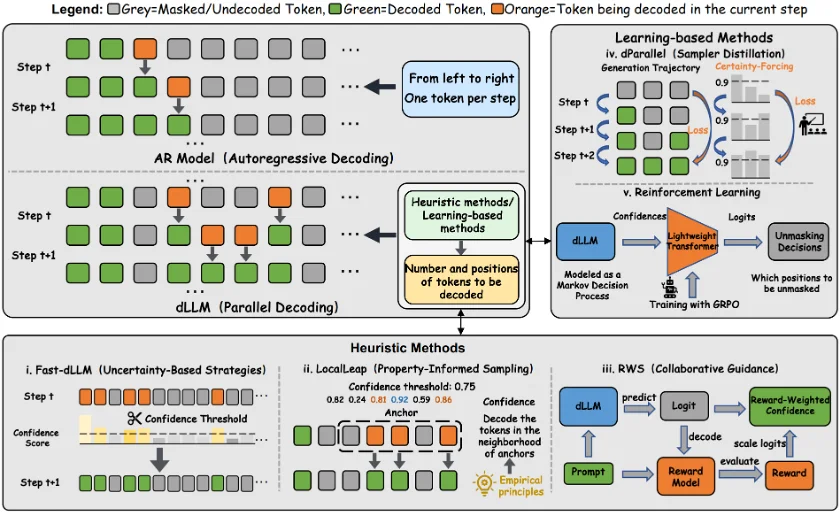
1. 并行解码(Parallel Decoding)
dLLM 的核心优势在于可以一次性更新多个 Token。但具体更新哪些?更新多少?
2. 压缩与量化
除了少走几步,把模型「变小」也是硬道理。虽然量化(Quantization)在 AR 模型中已很成熟,但 dLLM 对异常值和时间步(Timestep)高度敏感。QDLM 和 Quant-dLLM 等工作专门针对扩散过程中的激活分布特点,设计了细粒度的量化方案,甚至实现了 2-bit 的极低比特量化 。
这是 dLLM 与 AR 模型在底层机制上最大的不同点,也是工程优化的深水区。
在 AR 模型中,历史 Token 是固定的,因此 KV Cache 可以一直复用。但在 dLLM 中,整个序列在每一步去噪中都在变化,双向注意力机制意味着所有 Token 互相依赖,导致标准的 KV Cache 失效。
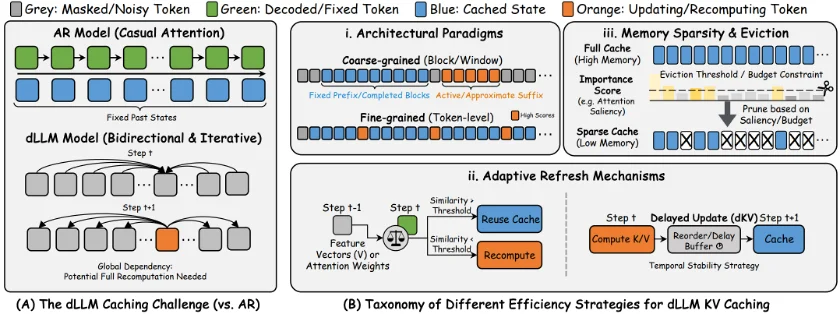
综述总结了三种应对策略:
1. 架构范式调整:采用 Block Diffusion 或 DualCache 设计,将序列分为「固定的前缀」和「动态的后缀」,只对变化的部分进行重计算 。
2. 自适应刷新(Adaptive Refresh):利用 Token 的稳定性。如果某个 Token 的特征在两步之间变化很小(Similarity Threshold),就直接复用上一轮的 Cache,否则才更新。dKV-Cache 和 d²Cache 就是此类策略的代表 。
3. 稀疏化与驱逐(Sparsity & Eviction):既然存不下,就只存重要的。通过注意力显著性(Attention Saliency)判断哪些 Token 对当前生成最关键,动态驱逐不重要的 KV 对,从而在有限显存下支持更长的序列 。
投机解码(Speculative Decoding, SD)在 dLLM 中呈现出两种独特的形态:
除了上述算法层面的优化,论文还探讨了 上下文扩展(Context Scalability) 和 系统框架(System Framework)。目前,包括 SGLang 在内的主流推理引擎已开始初步支持 dLLM,但相比 vLLM 对 AR 模型的那种极致优化,dLLM 的生态系统仍处于「基建」阶段 。
未来值得关注的方向:
1. 统一的评测标准:目前的效率对比往往基于不同的假设,急需建立涵盖训练成本、显存占用、端到端延迟的统一 Benchmark。
2. 硬件感知的内核优化:目前的加速很多停留在算法层,缺乏针对 FlashAttention 那样底层的 CUDA Kernel 优化,这限制了理论加速比向实际墙钟时间(Wall-clock time)的转化 。
3. 多模态融合:dLLM 天然适合多模态任务(因为图像生成本身多为扩散模型),如何在多模态场景下实现统一的高效推理,将是下一个爆发点 。
这篇综述不仅是对现有技术的总结,更是一份「作战地图」。它清晰地表明,dLLM 正从纯粹的学术探索走向工业级应用。随着 KV Cache 管理、并行解码策略的日益成熟,我们有理由相信,在不久的将来,dLLM 将在需要高质量、高可控性生成的场景中,成为 AR 模型强有力的竞争者甚至互补者。
延伸阅读与资源
纸上得来终觉浅。为了方便大家查阅文中提到的所有算法实现及后续更新的论文,作者整理了配套的 GitHub 资源库。如果你关注扩散语言模型推理加速、模型压缩 或 高性能计算,建议将此链接加入书签:
该仓库实时追踪 dLLM 领域的最新动态,欢迎 Star 关注或贡献你的代码!
文章来自于“机器之心”,作者 “机器之心”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
