
具身智能最缺的“空间常识”,被这套隐空间强化学习一次性补全 | ECCV‘26
具身智能最缺的“空间常识”,被这套隐空间强化学习一次性补全 | ECCV‘26大规模视频扩散模型,画面越来越真,却总在“物理定律”上栽跟头。
来自主题: AI技术研报
5190 点击 2026-07-29 13:49
 搜索
搜索
大规模视频扩散模型,画面越来越真,却总在“物理定律”上栽跟头。
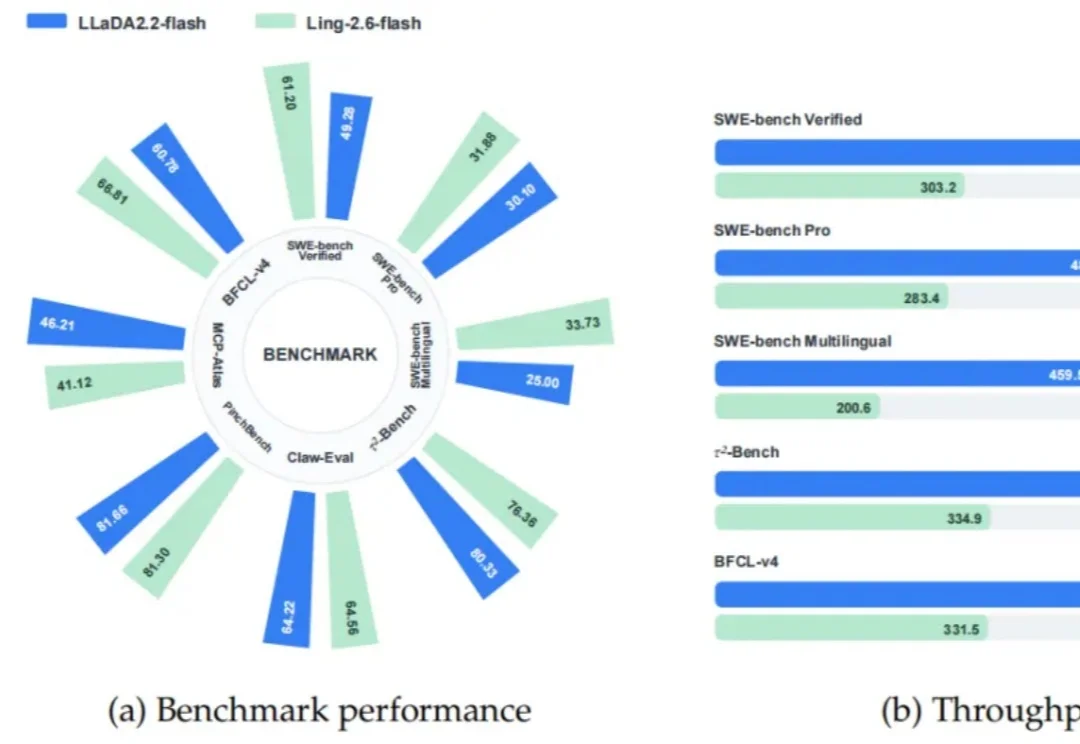
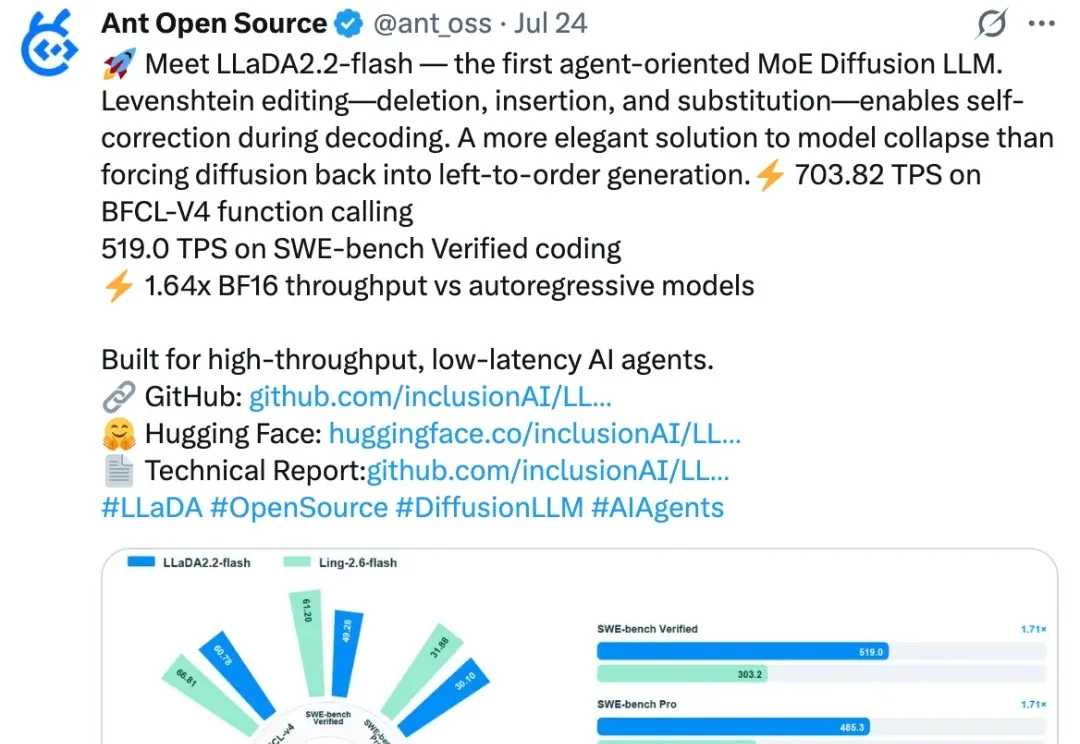
终于!Agent赛道,不再是自回归(AR)模型一家独大。
还记得「苦涩的教训」(The Bitter Lesson)吗?

推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
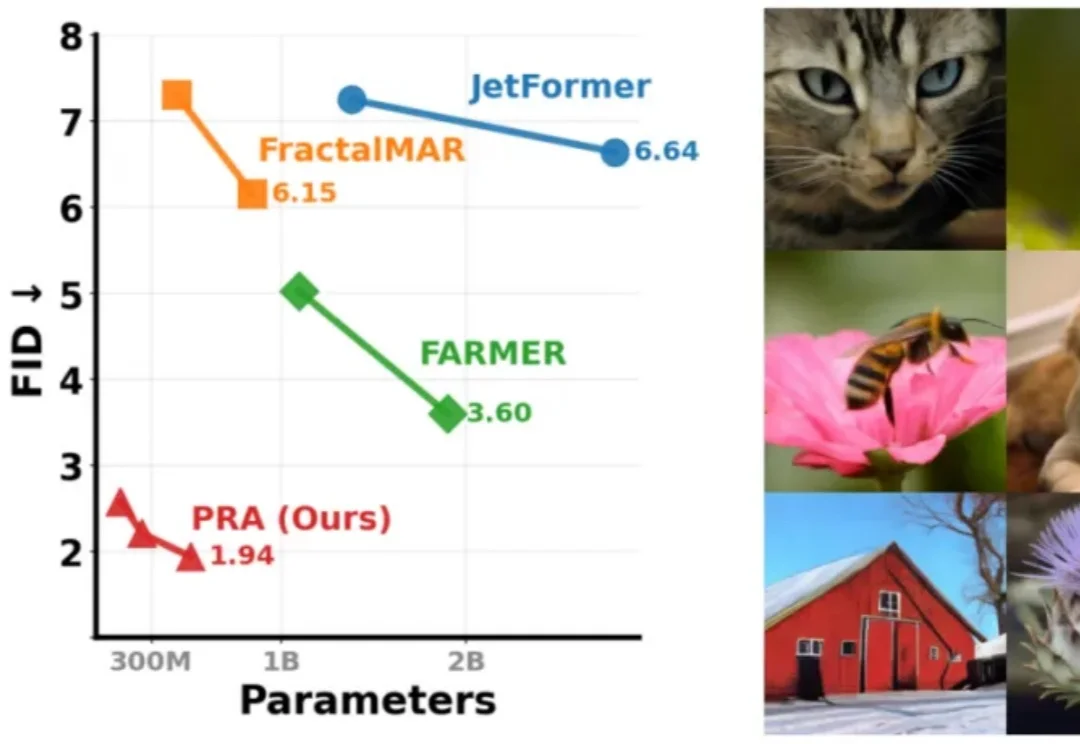
过去几年,扩散模型几乎定义了高质量图像生成:从随机噪声出发,经过多轮迭代,逐步 “雕刻” 出一张图像。但随着大语言模型席卷人工智能领域,另一条路线正迅速走到舞台中央 —— 图像,能否也像语言一样,通过自回归方式逐步生成?

扩散模型已经越来越会「画」,却还远没有学会「守住要求」。决定系统是否可靠的,已不再只是画质,而是生成结果能否持续遵守条件、维持状态,并符合人类与现实世界的基本标准。

扩散模型又被玩出新花样了。
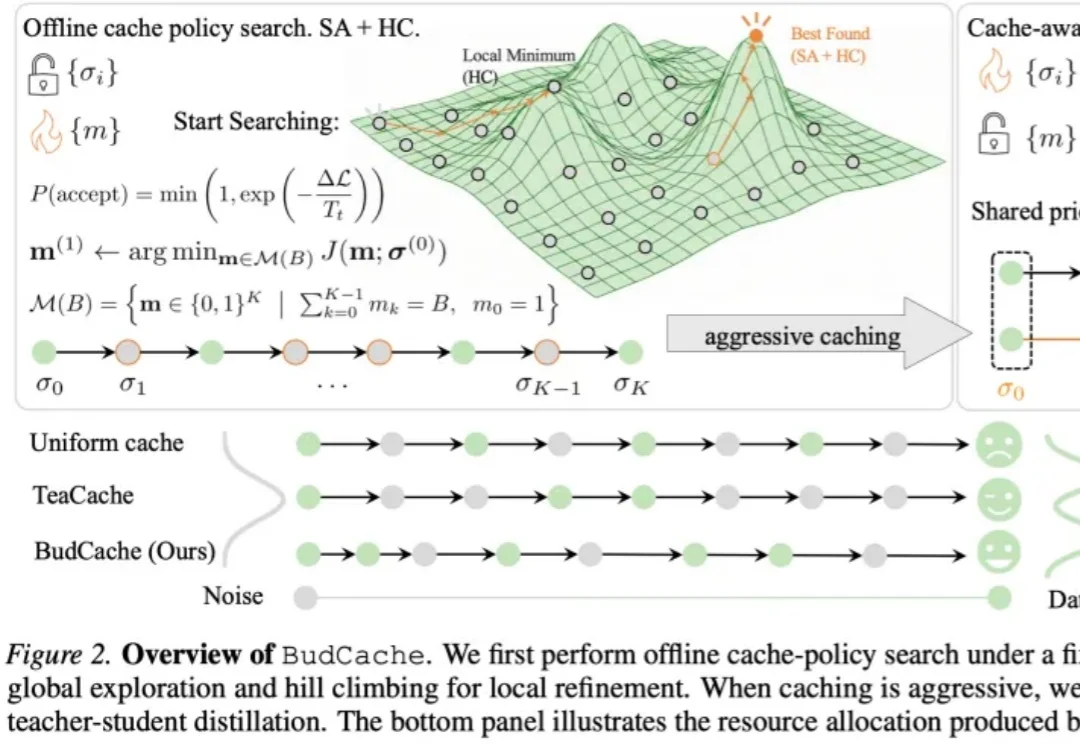
扩散模型生成得越来越好,但也越来越慢。

大语言模型的RL技术已日趋成熟,多模态生成模型的强化学习训练却仍在“各自为战”——图像扩散模型一套流程、视频生成另一套标准、VLM和LLM又有不同的技术栈。
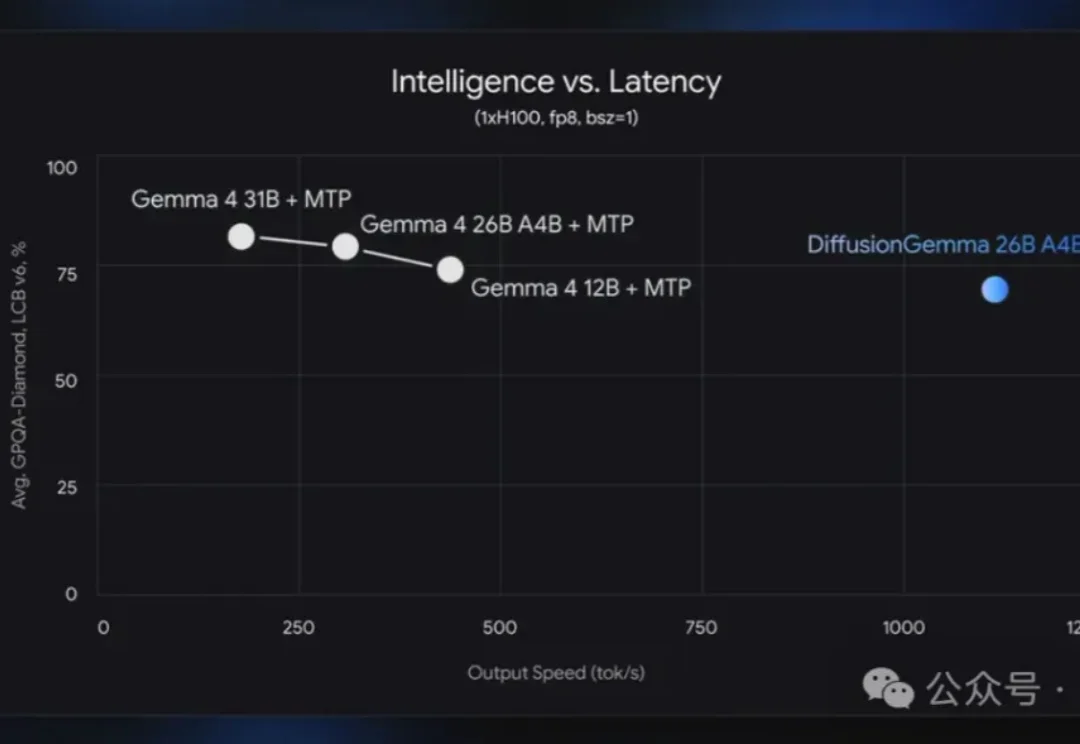
就在刚刚,谷歌闷头干了件大事:把生成图片的扩散模型,拿来写文字了,而且一出手就是4倍加速。 新模型名为DiffusionGemma,它直接抛弃了传统自回归那套“逐Token生成”的打字机模式,而是像“印刷机”一样工作——