# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一段几十秒的音视频,上万Token,一半以上是冗余——Omni-LLM的计算浪费,比想象中更严重。
快手可灵团队、中科院自动化所和南京大学的最新研究,给出了一个解决方案:OmniSIFT。
这套模态非对称Token压缩框架的核心洞察是:视频信息远比音频密集,让视频“带着”音频走。
具体来说,先通过时空联合剪枝压缩视频Token,再用筛选后的视觉特征去引导音频Token的选择——与当前视觉内容高度相关的声音被保留,无关背景音直接过滤。
实验结果令人惊喜:只保留35%的多模态Token,模型性能不仅没掉,反而在部分基准上超过全量输入。推理时间减少42%,GPU显存占用同步下降。

OmniSIFT的核心思想是利用音视频之间的非对称依赖关系:先通过视频信息找到关键视觉线索,再据此筛选最相关的音频Token,从而在大幅压缩序列长度的同时保留关键语义信息,剔除大量重复画面或无关声音Token。
随着多模态模型不断向“全模态”演进,Gemini-2.5-Pro、Qwen2.5-Omni等模型已经能够同时理解视频与音频信息,让AI逐渐具备类似人类的综合感知能力。
然而,这种能力的代价同样巨大。一段几十秒的视频在进入模型之前,往往会被编码成成千上万个Token,但其中大量Token都是冗余的。注意力可视化实验结果进一步揭示了这一问题。如图所示,在Qwen2.5-Omni-7B的多模态推理过程中,只有少量Token获得较高的注意力权重,而大部分Token的贡献非常有限。这意味着,大量计算资源其实消耗在冗余信息上。

尽管研究者已经提出了一些视觉Token压缩方法,但在音频+视频的全模态场景下,这些方案仍然面临挑战。一方面,视频包含大量空间与时间冗余;另一方面,音频对时间连续性高度敏感。更复杂的是,两种模态之间还存在紧密的语义关联,简单的统一压缩策略往往会破坏关键线索。
正是在这样的背景下,OmniSIFT被提出。该方法从模态冗余结构本身出发,通过非对称的压缩策略,在保持关键语义信息的同时显著减少多模态Token数量。
为了解决全模态模型中音视频信息量极度不对称、冗余度极高的问题,OmniSIFT提出了一种模态非对称的Token压缩框架。与传统方法分别压缩各模态不同,OmniSIFT将视频与音频的信息结构结合起来进行协同筛选。如图2所示,该框架由时空视频剪枝模块(STVP)和视觉引导音频选择模块(VGAS)组成。
二者协同工作,使模型在大幅减少Token数量的同时,依然能够保留关键语义信息。如图3所示,在“比分从27–26变为28–26时发生了什么?”这一问题中,OmniSIFT能够保留比分牌变化这一关键视觉线索,并结合对应的音频片段,从而正确推断出比分变化的原因。相比之下,传统方法在压缩过程中往往会丢失这些关键信息,导致模型产生错误理解。
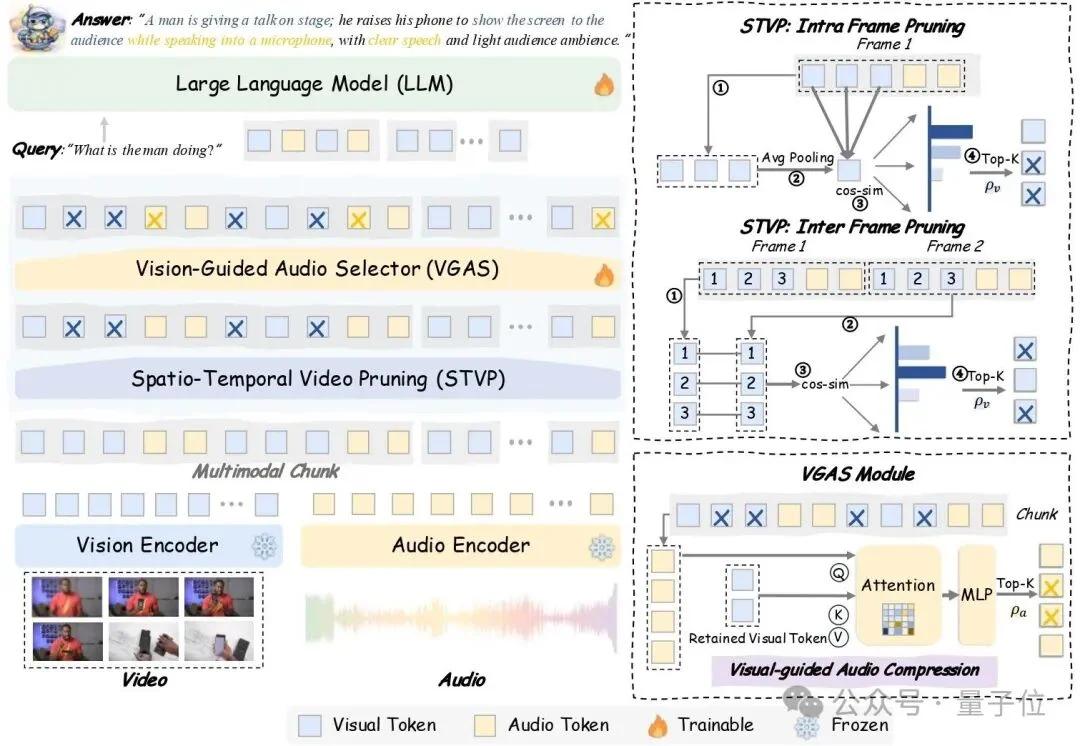
视频端:时空联合剪枝
在多模态输入中,视频Token往往占据绝大多数。为此,OmniSIFT设计了时空视频剪枝模块(STVP),从空间和时间两个维度识别冗余信息。
Intra-Frame Pruning(帧内剪枝)
在单帧内部识别背景区域或重复纹理,只保留具有语义价值的视觉特征。
Inter-Frame Pruning(帧间剪枝)
对连续帧之间的视觉相似度进行分析。当相邻帧变化较小时,系统会自动丢弃重复帧,从而减少时间维度上的冗余。
通过交替进行帧内与帧间剪枝,STVP能够在保证视觉语义完整性的同时,大幅压缩视频Token数量。
音频端:以“视”驭“听”
与视频不同,音频信息对时间连续性更加敏感。如果简单丢弃音频Token,往往会破坏语义完整性。
因此,OmniSIFT提出了视觉引导音频选择模块(VGAS)。该模块利用已经筛选后的视觉特征,通过跨模态注意力机制评估每个音频Token的重要性。
与当前视觉内容高度相关的音频片段(例如说话声、碰撞声或关键环境音)会被优先保留,而无关背景音则被过滤。
为了使离散的Token选择过程能够参与训练,研究者还引入Straight-Through Estimator(STE),从而实现端到端的可微优化。这使得压缩模块能够在训练过程中逐渐学习哪些信息对模型最重要。

为了验证OmniSIFT的实际效果,研究团队在Qwen2.5-Omni-7B和Qwen2.5-Omni-3B上进行了系统评测。实验覆盖了多个具有代表性的音视频理解benchmark,包括OmniVideoBench, DailyOmni, WorldSense. Video-MME和video-SALMONN-2 testset为了保证公平比较,研究者使用完全相同的训练配置对全量Token输入模型进行微调作为baseline,并与多种现有Token压缩方法进行对比。
实验结果揭示了一个有趣的现象:在多模态推理过程中,超过65%的Token实际上是冗余的。即使在大幅压缩Token数量的情况下,模型依然能够保持接近甚至超过全量输入的性能。
实验结果如表所示。在仅保留35% Token的情况下,OmniSIFT在多个音视频理解任务上仍然保持甚至超过了全量输入模型的表现。例如,在WorldSense基准上,OmniSIFT在Qwen2.5-Omni-7B上取得50.0的成绩,高于full-token baseline的49.7。
在更严格的25% Token保留率设置下,OmniSIFT依然能够维持稳定性能,并整体优于OmniZip、DyCoke等压缩方法。这表明该方法能够有效去除大量冗余信息,同时保留关键语义线索。

为了分析各模块的作用,研究者对OmniSIFT进行了多组消融实验,结果如图所示。
当移除STVP的空间剪枝模块或时间剪枝模块时,模型性能均出现明显下降。这说明视频中的空间冗余和时间冗余都需要被同时建模。
更重要的是,当将视觉引导的音频Token选择(VGAS)替换为音频自身的注意力剪枝时,DailyOmni上的得分从73.2降至69.3。这一结果表明:在全模态理解任务中,视觉线索能够显著帮助模型识别重要音频信息。

除了性能保持之外,OmniSIFT在推理效率方面同样表现突出。由于Token数量大幅减少,模型的计算开销明显降低。如表所示,在35% Token保留率下,OmniSIFT在Qwen2.5-Omni-7B上将总推理时间从15097秒降低至8756秒,减少约42%,同时GPU显存占用也有所下降。尽管计算开销显著减少,模型准确率依然保持稳定,甚至略有提升。这说明OmniSIFT在计算效率与模型性能之间实现了良好的平衡。

综合来看,OmniSIFT不仅能够在极高压缩率下保持模型性能,还显著降低了推理开销,为Omni-modal大模型在实时交互和端侧部署等场景中的应用提供了新的可能。
随着Omni-LLM逐渐成为多模态模型的重要发展方向,如何在有限算力下高效处理音视频信息,正在成为新的关键问题。
OmniSIFT通过模态非对称的Token压缩策略,在仅保留少量关键Token的情况下依然保持了强大的多模态理解能力,为全模态模型的高效推理提供了一种新的思路。它也揭示了一个简单却深刻的事实:真正决定模型理解能力的,并不是Token的数量,而是信息的密度。
论文标题:
OmniSIFT: Modality-Asymmetric Token Compression for Efficient Omni-modal Large Language Models
作者机构:
中科院自动化所,快手可灵,南大等
论文链接:
https://arxiv.org/abs/2602.04804
文章来自于“量子位”,作者 “OmniSIFT团队”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
