# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在生成式 AI 浪潮中,文生图技术已实现跨越式发展,在视觉呈现上达到了前所未有的高度。然而,在生成图像中准确合成拼写正确、结构规范且风格协调的文字 —— 视觉文本渲染(Visual Text Rendering, VTR),至今仍是该领域尚未攻克的核心难题。
即便是当前最先进的文生图模型(如 Nano Banana,Seedream、Qwen-Image),也难以稳定生成结构忠实的文本,常伴有笔画错位、结构畸变与字符缺失等问题,在中文等字形结构复杂的语言中表现尤为明显。这一短板直接制约了 AIGC 技术在海报设计、广告创意、图文排版及电商场景等高价值商业领域的规模化落地。
针对这一难题,华中科技大学白翔教授团队等提出了 TextPecker,一个为视觉文本而生的「啄木鸟」。该方法是一种基于结构感知的即插即用型强化学习优化策略,无需修改底层模型即可灵活适配各类主流生成器,并带来显著的性能增益:搭载 TextPecker 后,FLUX 的语义对齐度与结构保真度分别提升了 +38.3% 和 +31.6%;即便面对已为中文场景高度优化的 Qwen-Image,仍取得了 +8.7% 和 +4.0% 的显著增益,将视觉文本渲染推向了全新 SOTA。
目前,该工作已被 CVPR 2026 接收。

TextPecker 的核心洞察在于:制约视觉文本渲染质量的瓶颈,并非生成模型本身的能力上限,而是优化流程中负责评估文字质量的「裁判」存在根本性缺陷。
当前主流范式普遍采用强化学习(RL)后训练来提升模型的文字生成能力,并依赖 OCR 模型或多模态大模型(MLLM)作为奖励信号的来源。然而,研究团队发现,这些评估模型缺乏对文字结构异常的细粒度感知能力,在面对不完美的生成文字时,表现出两类典型失效模式:

图 1 现有 OCR 模型与多模态大模型难以感知生成文字中的细粒度结构异常,成为 VTR 评估与强化学习优化的关键瓶颈。红色标注为误识别字符。
这两类失效直接导致强化学习的奖励信号中混入大量噪声,模型无法获得细粒度的结构级反馈,构成了当前 VTR 评估与优化的双重瓶颈。
1. 重新定义「好」的标准:结构感知的复合奖励
TextPecker 基于 Flow-GRPO 框架构建,是一种即插即用的强化学习优化策略。其核心改进在于重新定义奖励函数:引入一个具备细粒度结构异常感知能力的评估模块,替代传统的 OCR 编辑距离信号,从结构质量与语义对齐两个维度同时评估生成文字的质量。

图 2:TextPecker 方法整体框架

以往方法简单地将生成文本视为一条长字符串,直接与目标文本计算编辑距离。这种方式隐含一个假设:生成文字的排列顺序与 Prompt 完全一致。但在真实渲染场景中,文字的空间布局未必与 Prompt 中的出现顺序一致

最终,TextPecker 将结构质量与语义对齐两个维度的分数通过加权融合构成复合奖励。这一设计使得优化过程不再仅仅追求「文字内容对不对」,而是同时关注 「文字结构好不好」,实现二者的联合优化。
2. 打造「好裁判」:字符级结构异常数据集的构建
上述复合奖励的有效性,取决于一个前提:结构感知评估模块能够准确识别生成文字中的细粒度结构异常。而训练这样的模块,首先面临一个基础性难题 —— 缺乏大规模、带有字符级结构异常标注的高质量数据。为此,TextPecker 设计了一套系统化的三阶段数据构建流程(如图 3 所示)。
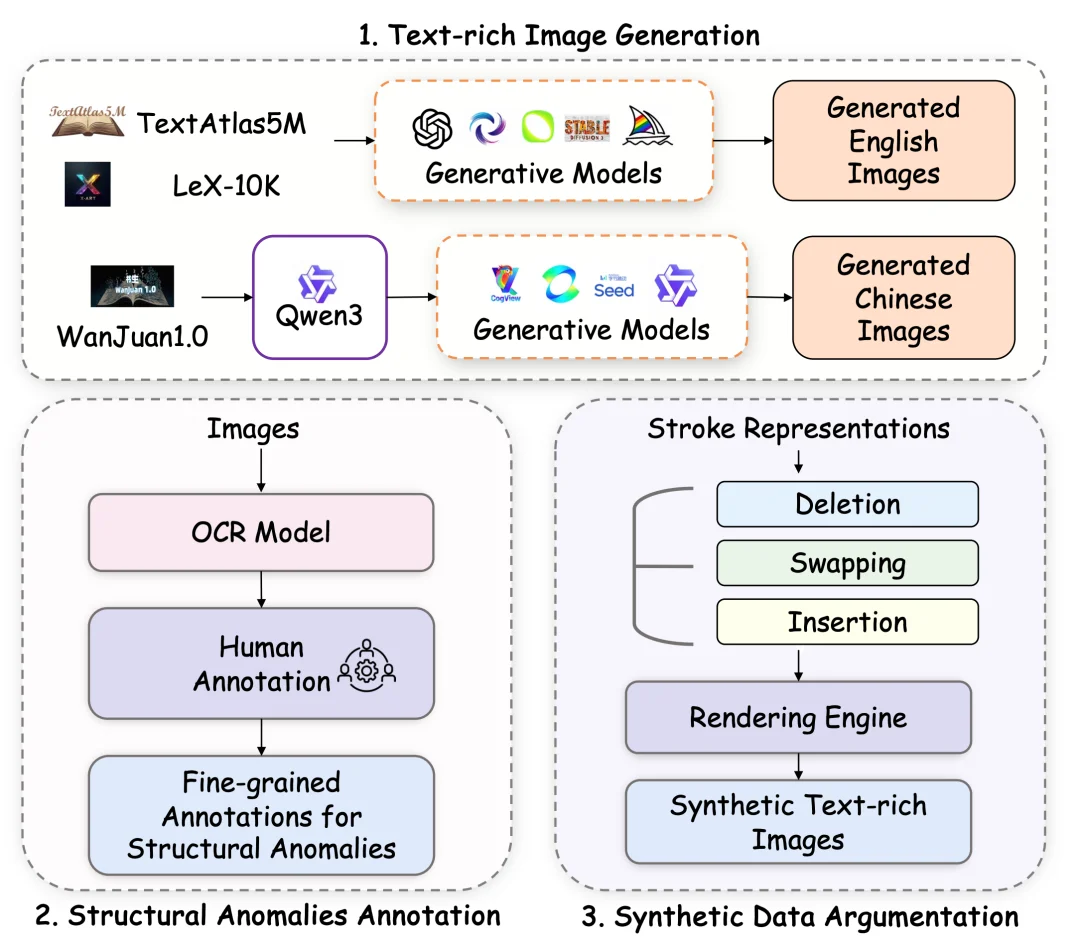
图 3 TextPecker 数据构建流程概览
阶段一:大规模多样化富文本图像生成
由于不同生成模型产生的结构错误各有特点,单一模型的输出难以反映真实场景下错误类型的多样性。因此,第一阶段的核心策略是多模型、多来源的交叉生成。
具体而言,团队针对中英文场景分别设计了数据生成方案:
阶段二:高成本的字符级结构异常精标注
获取富文本图像后,研究团队投入了大量人工标注资源,对数据进行字符级的结构异常检查。这里,结构异常被定义为:任何因模糊、扭曲、笔画缺失或冗余伪影导致的结构性失真,使得字符的语义可识别性受损。
具体的标注流程分为两步:首先利用 OCR 模型获取初步识别结果,再由标注人员逐字符检查并以特殊标记标注所有结构缺陷(如图 4 所示)。对于结构严重粘连、无法逐字区分的区域,则采用统一占位符标记。这一阶段将监督粒度细化至单字符的结构完整性层面,为结构感知评估模块的训练提供了精确的字符级监督信号。
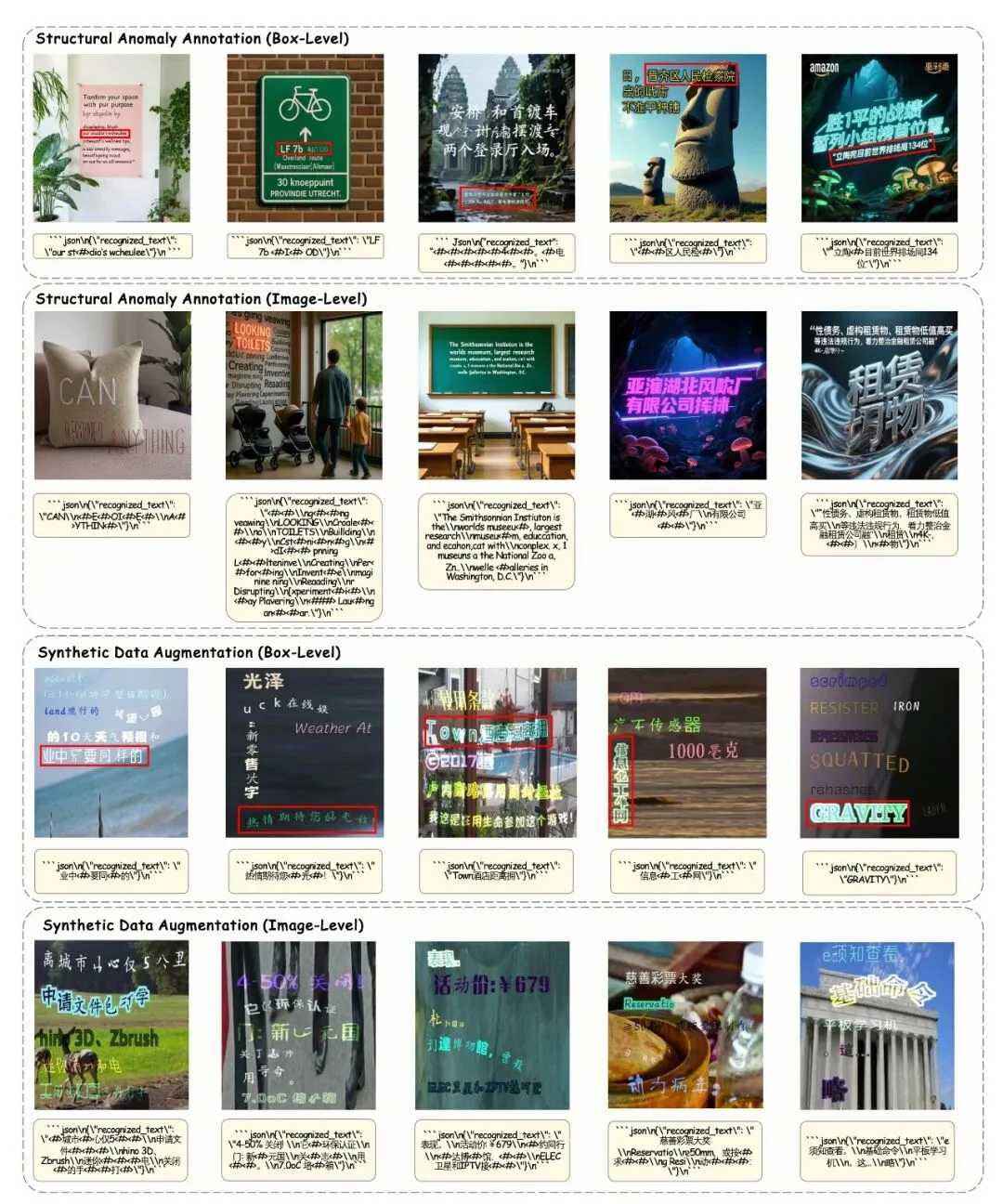
图 4 TextPecker 数据集可视化
阶段三:基于笔画编辑的合成数据增强
仅依赖阶段二人工标注的数据训练模型存在局限:对未见异常类型的泛化能力不足,且对标准汉字的识别能力下降。其原因在于中文的固有复杂性:不同于英文字母的线性形态,汉字具有二维空间构成且规模庞大(常用字超过 8000),潜在的结构异常类型呈组合爆炸式增长,远超人工标注所能穷举。
为此,团队设计了一套基于笔画编辑的程序化合成流程。利用公开笔顺数据将汉字表示为有序笔画序列,并在此基础上定义三种笔画级结构编辑算子:
关键在于,这三种算子并非独立使用,而是按顺序随机组合叠加,从而能够模拟远比单一编辑更复杂、更贴近真实生成错误的结构异常类型。在此基础上,团队自研了一套基于 SynthTIGER 的文本渲染引擎,将生成的异常字符与规范字符放置到多样化的背景与排版布局中,合成最终的富文本图像(如图 4 所示)。最终,将阶段二的人工标注数据与本阶段的合成数据合并,形成训练集与测试集,数据集统计与分布详见图 5。
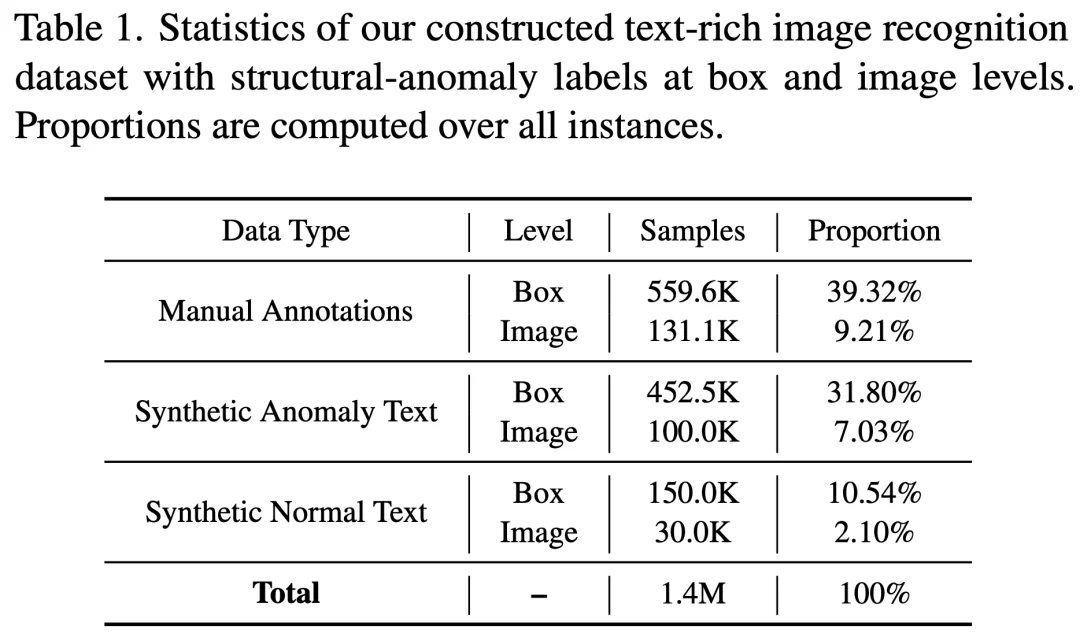
图 5 TextPecker 数据集统计
结构感知评估模块的训练
基于上述数据集,研究团队对 Qwen3-VL 与 InternVL-3 进行监督微调(SFT),得到最终的结构感知评估模块,为强化学习提供结构级奖励信号。
1. 结构异常感知能力:现有模型近乎失灵,TextPecker 大幅领先
团队设计了两项专用评测任务:文本结构异常感知(TSAP)和规范文本识别(CTR),系统检验模型对生成文本中细粒度结构缺陷的辨识能力。结果揭示了一个严峻事实:无论是专业 OCR 模型(PP-OCRv5、GOT-OCR-2.0、MonkeyOCR 等)还是顶尖多模态大模型(GPT-5、Gemini-2.5-Pro 等),在 TSAP 任务上的 F1 均不超过 0.23,部分模型甚至完全无法检出异常字符。
相比之下,TextPecker 在英文和中文 TSAP 上分别取得 0.87 和 0.93 的 F1 值,同时在 CTR 上也显著优于基线模型,验证了其结构感知能力的全面优势。
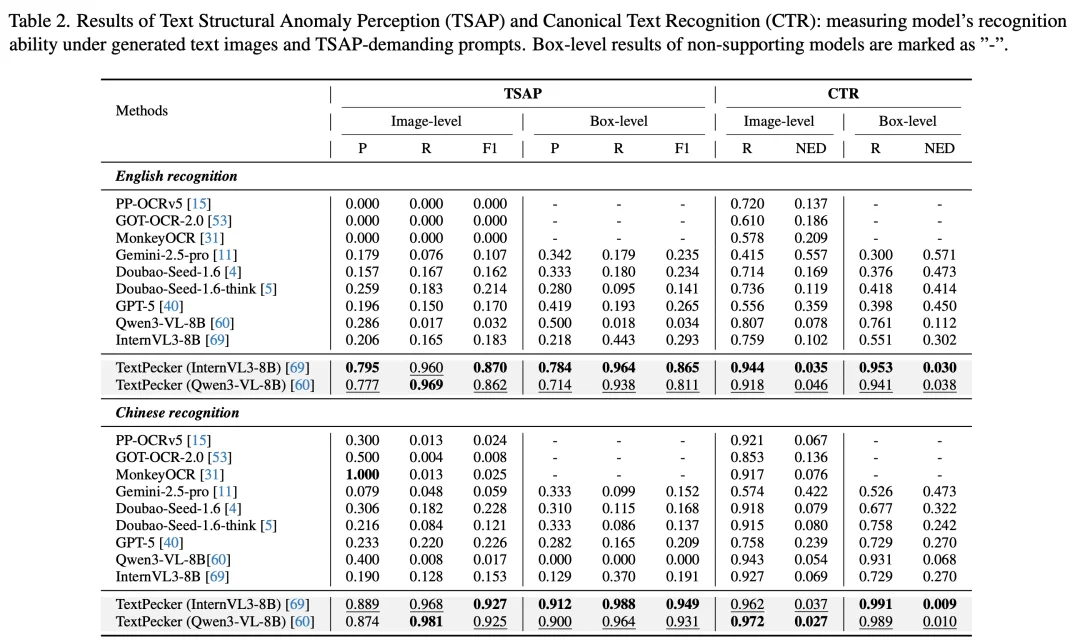
图 6 现有模型在文本结构异常感知(TSAP)与规范文本识别(CTR)任务上的表现对比。TextPecker 在所有维度上大幅领先。
2. VTR 生成优化:跨模型、跨语言的一致性提升
团队在 SD3.5-M、Flux.1 [dev]、Qwen-Image 三个生成模型上进行了 RL 优化实验,覆盖 OneIG-Bench、LongText-Bench、CVTG-2K 及自建 GenTextEval 四个基准。
结果显示,TextPecker 奖励信号在所有配置下均带来一致提升。以 Flux.1 [dev] 英文生成为例,语义对齐(Sem.)和结构质量(Qua.)分别提升 +38.3% 和 +31.6%,同时在语义维度上超越 OCR 奖励基线 +11.7%。
更具说服力的是,即便在已经对文字生成高度优化的 Qwen-Image 上,TextPecker 在中文渲染任务中仍实现了 +8.7% Sem. 和 +4.0% Qua. 的显著增益,刷新了高保真 VTR 的 SOTA。
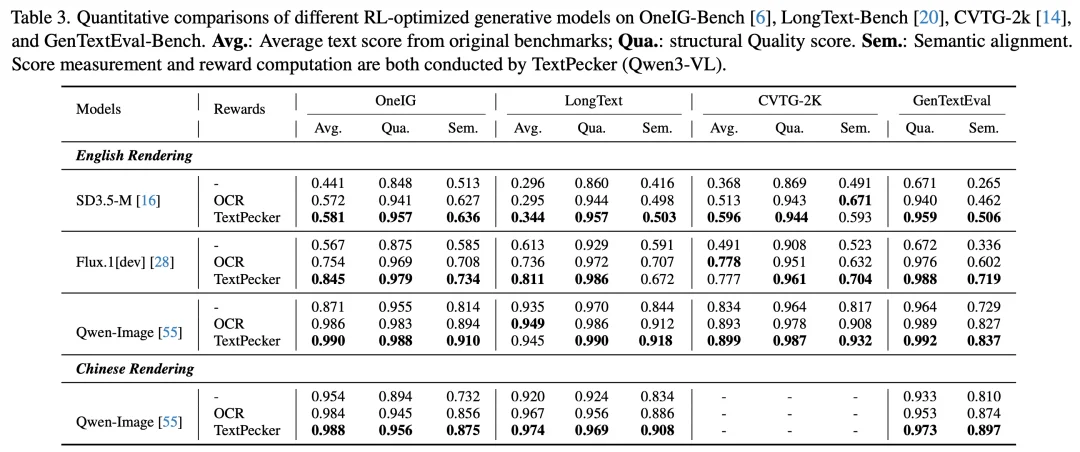
图 7 TextPecker 在三大主流模型上的定量结果对比。
3. 定性对比:从「语义接近」到「结构忠实」的质变
原始 Qwen-Image 在小字、密集排版等高难场景中频繁出现模糊、扭曲与错位;基于 OCR 奖励的 RL 优化虽改善了语义一致性,但结构缺陷依然存在。而 TextPecker 驱动的优化则在结构保真与语义准确两个维度实现了同步提升:以论文中的「英文菜单」和「中文论文」渲染案例为例,文字笔画清晰、行列对齐,结构畸变问题得到有效消除。

图 8 TextPecker 显著改善了 Qwen-Image 的文字渲染质量,定性对比。
4. 消融实验:数据构建与奖励设计的协同效应
研究团队通过两组消融实验验证了方法各组件的贡献(如图 9、图 10 所示):
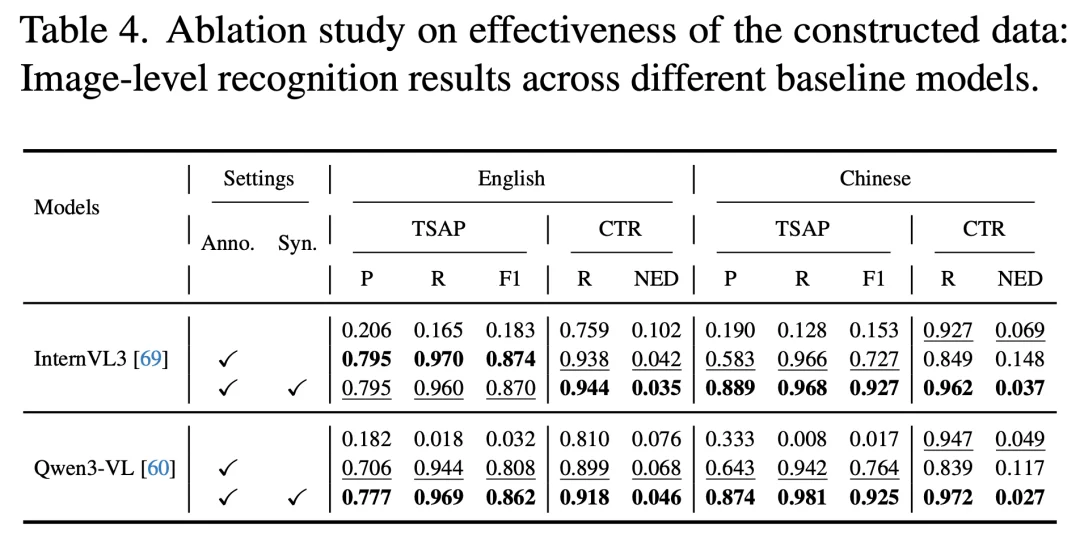
图 9 数据组成消融实验
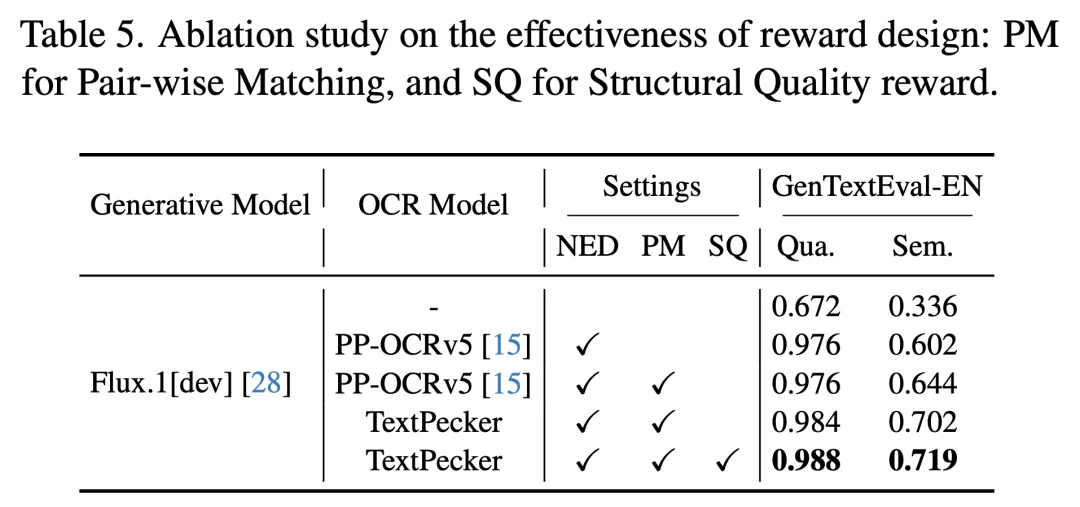
图 10 奖励设计消融实验
5. 补充实验:从跨模型泛化到多奖励协同下的鲁棒优化
除主实验外,研究团队在论文附录中提供了两组补充实验,从不同角度进一步验证了 TextPecker 的泛化能力与实用潜力。
TextPecker 评估器是否仅对训练中涉及的生成模型有效?为此,团队选取训练过程中从未接触过的 Nano Banana(Gemini-2.5-flash-image) 作为测试对象,在常规渲染、极端艺术字、低对比度排版三种递进难度下进行验证(见图 11)。结果显示,TextPecker 在未见过的生成模型上依然保持强劲的结构感知能力,常规与低对比度条件下表现尤为稳健;性能衰减主要出现在极端艺术化字体场景,此时艺术变形与真实结构缺陷的界限趋于模糊,也为后续研究指出了明确方向。
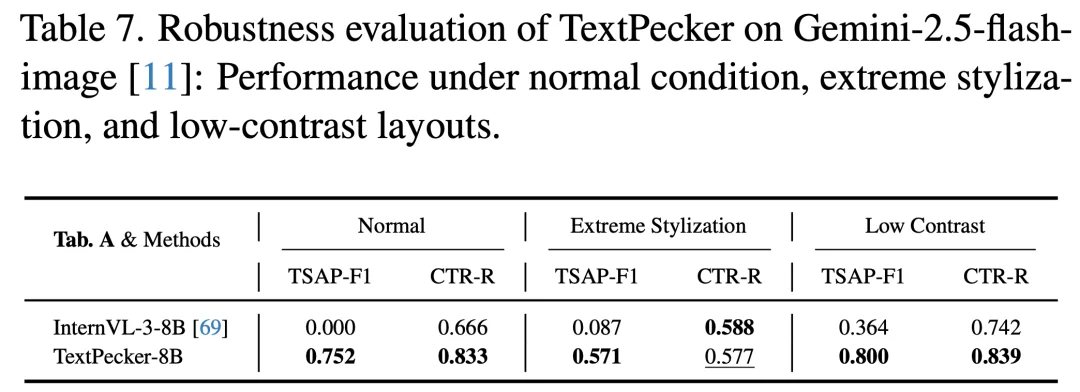
图 11 TextPecker 的跨模型泛化表现
主实验中 TextPecker 仅使用文本渲染奖励,单一目标在实际应用中不可避免地会影响图像美学质量。
为此,团队构建了增强 RL 框架:训练层面引入 Flow-GRPO-Fast、GRPO-Guard 及 Velocity KL 正则化以提升稳定性;奖励层面将 TextPecker 与 PickScore、Aesthetic Score 组合为多目标奖励,兼顾文字准确性与画面美学。实验覆盖三个模型在 7 个英文基准和 3 个中文基准上的完整评测。
结果显示,TextPecker 在多奖励体系中的提升与主实验一致甚至更为显著,在中英文场景下均取得了大幅度的质量与语义双重增益,验证了其奖励信号与其他优化目标的兼容性,也表明 TextPecker 具备产品级优化流程的落地潜力。
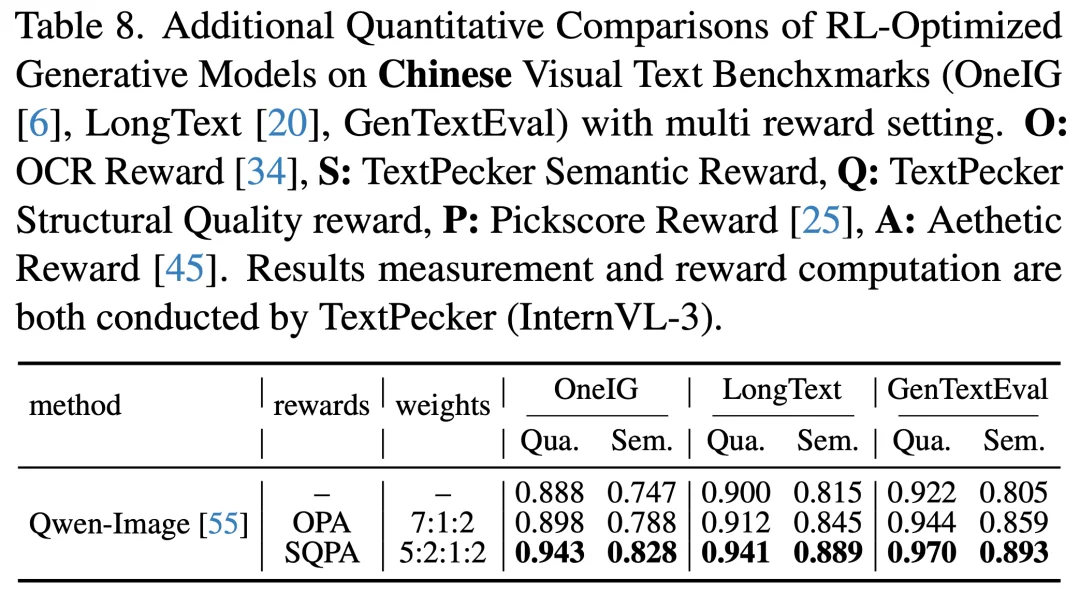
图 12 TextPecker 在多奖励协同优化下提升依然显著(中文)
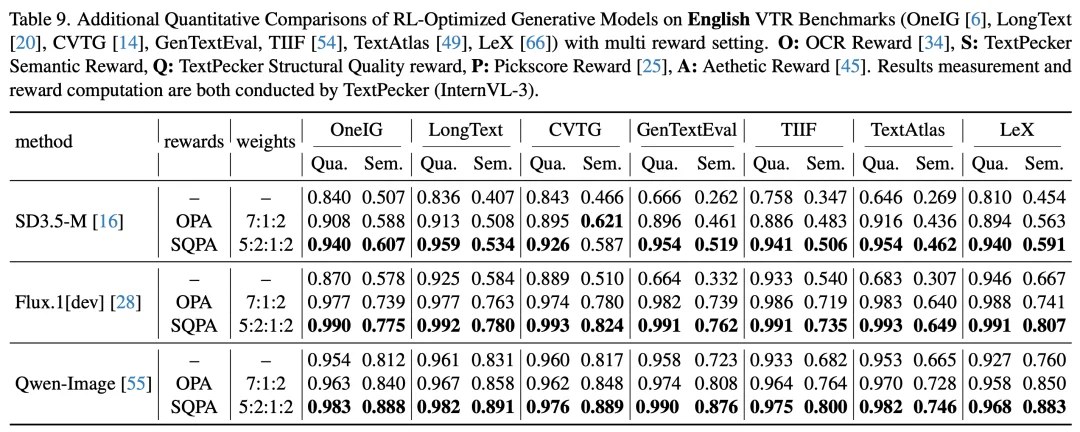
图 13 TextPecker 在多奖励协同优化下提升依然显著(英文)

图 14 Qwen-Image 经 TextPecker 多奖励协同优化后,文字保真度与画面美学实现良好平衡
TextPecker 揭示了制约视觉文本渲染质量的关键瓶颈 —— 现有评估模型无法感知生成文字中的细粒度结构异常,并围绕这一问题给出了完整的解决方案:构建字符级结构异常数据集训练专用评估器,设计兼顾语义对齐与结构质量的复合奖励函数,以即插即用的方式为主流生成模型提供结构级优化信号。
实验表明,该方法在所有测试模型上均带来一致提升,将高保真视觉文本渲染推向了新的水平。
从更宏观的视角看,可靠的文字渲染能力是多模态 AI 走向真实应用的关键基础设施,从 AI Agent 自主生成海报文档,到多模态大模型输出含文字的视觉内容,都以此为前提。TextPecker 为这一方向提供了基础性的评估工具与优化范式。
文章来自于“机器之心”,作者 “机器之心”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【部分开源免费】FLUX是由Black Forest Labs开发的一个文生图和图生图的AI绘图项目,该团队为前SD成员构成。该项目是目前效果最好的文生图开源项目,效果堪比midjourney。
项目地址:https://github.com/black-forest-labs/flux
在线使用:https://fluximg.com/zh
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
