# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
某电商平台上,一名用户反复对比三款降噪耳机的评价、续航与材质。这购物决策背后藏着预算、参数对比与审美偏好的博弈。但在 AI 智能体(Agent)的世界里,这种纠结往往不存在。传统的 AI 购物助手更像是一个任务完成机器:接到指令,搜索,下单。他们或许能跑通流程,却完全无法理解用户为何在最后一刻因为一条关于 “夹耳朵” 的差评而放弃支付。简而言之,传统的电商 Agent 只是任务导向的(task-oriented),而不是模拟导向的(simulation-oriented)。为此,来自亚马逊(Amazon)的研究团队提出了名为 Shop-R1 的训练框架 。

Shop-R1:从 “指令执行” 到 “行为复刻”
在传统的电商 AI 研究中,衡量标准往往是单一的成功率。然而,真实世界的网购环境是一个充满噪声、促销陷阱与主观偏好的动态迷宫。研究团队观察到,这种 “黑盒式” 的任务导向模型在面对复杂环境时,往往会产生逻辑断层:它们可能因为偶然的网页跳转完成了任务,却完全偏离了真实人类的消费习惯。
Shop-R1 的核心野心,是实现从 “任务完成” 到 “行为模拟” 的范式转移。对于模拟导向的购物 Agent,它的终极挑战在于:它需实时解构历史浏览链路与当前的交互细节,从而在动态的上千种可能的操作中精准预测用户在当前页面维度的下一步操作。为了复刻决策过程,Shop-R1 将复杂的网购过程中的行为归纳为三类动作:
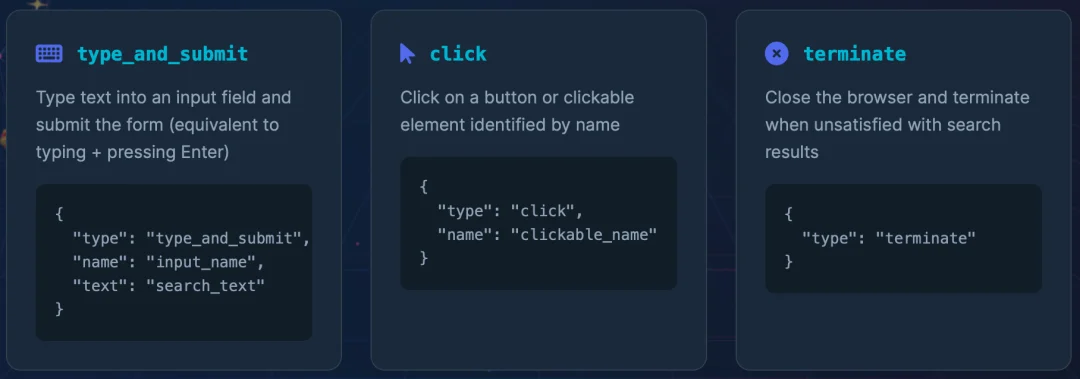
模型以用户过往浏览页面及对应操作作为输入,并以结构化的 JSON 形式输出对用户下一步动作(Action)的预测以及其背后的推理逻辑(Rationale)。
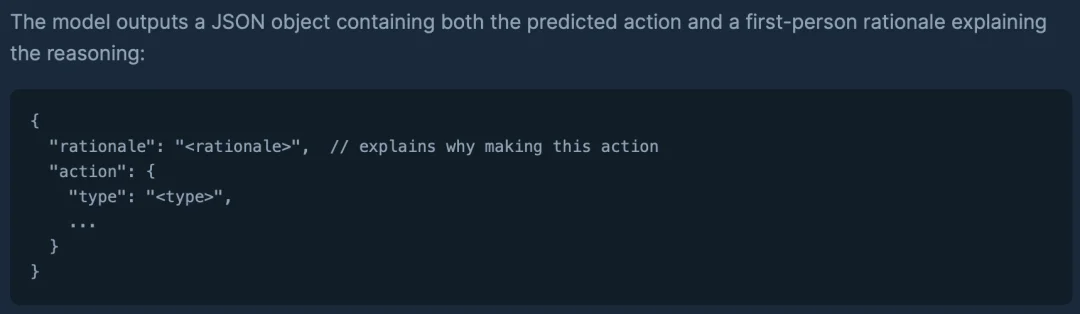
Shop-R1 采用双阶段训练范式:首先通过监督微调(SFT)实现行为基准的 “冷启动”;随后在强化学习(RL)阶段,利用多层级奖励机制(Hierarchical Rewards)驱动深度迭代,旨在提升模型在复杂动态环境下的逻辑推理与泛化表现。
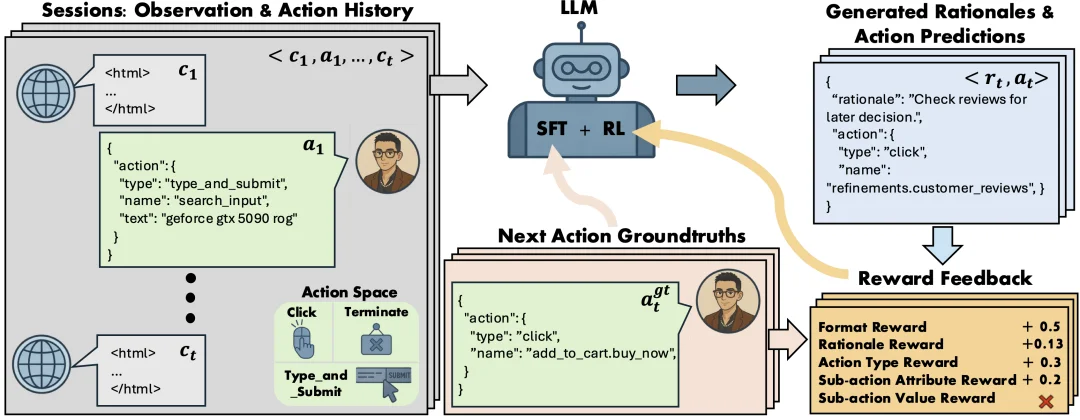
第一阶段:SFT 冷启动
这种监督式初始化(supervised initialization)在训练流程的早期阶段发挥了关键作用,它帮助模型尽早内化上下文(context)、推理过程(rationale)与动作(action)之间的结构性依赖关系。通过在一开始就让模型建立这些模式,进而显著提升了后续强化学习(RL)阶段的稳定性和样本效率。更重要的是,这种方法为什么样的长文本输出才算高质量提供了明确的信号,例如正确命名被点击的按钮或给出有意义的搜索查询。而这些能力如果仅依赖强化学习往往难以获得,尤其是在奖励信号稀疏且延迟的情况下。
第二阶段:多层级奖励的强化学习
为了在人类行为模拟(human behavior simulation)场景中更好地引导策略优化,每一步决策被拆分为两个子任务:rationale 生成和 action 预测。针对每个子任务,分别设计了专门的奖励函数,以提升模型的对齐性(alignment)和可解释性(interpretability)。
1)二值格式奖励(Binary Format Reward)
为了保证能够方便且正确地从模型输出中解析出预测的 rationale 和 action,引入了二值格式奖励,鼓励模型以结构化 JSON 格式生成响应。该格式遵循一个字典结构,包含两个键:rationale 和 action。
2)推理奖励 (Rational Reward)
对于 rationale 生成,采用 self-certainty score,用于衡量模型对其生成 rationale 的置信程度。具体而言,我们计算模型在词表上的预测分布与均匀分布之间的 KL 散度,并在整个输出序列上取平均。
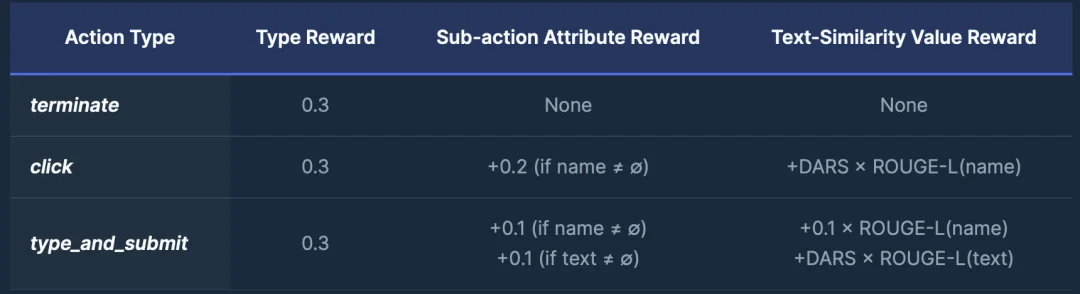
3)层级式动作奖励 (Hierarchical Action Reward)
对于 action 预测,我们用一种层级式奖励机制(hierarchical reward scheme)替代了原本脆弱的二值奖励信号。该机制同时对粗粒度的动作类型和细粒度的子动作给予奖励,从而稳定训练过程,并抑制退化的 reward hacking 策略。这种层级奖励机制使得奖励空间更加稠密(densify the reward landscape):它扩大了能够获得正收益的轨迹集合,使智能体能够摆脱在策略搜索过程中常见的 “无奖励平台(no-reward plateau)”,同时也使得 reward hacking 的收益变得不再划算。
具体而言,一旦高层动作类型预测正确,无论该动作是简单还是复杂,都可以获得相同的粗粒度奖励;而只有较复杂的动作,才可以通过其长文本子组件(sub-actions)进一步获得额外奖励。因此,简单地反复执行 “terminate” 这一简单动作将不再具有竞争性的回报,而完整执行 (“click”, “type_and_submit”) 等动作序列则成为收益最高的策略。比如,“click” 动作包含一个子动作,用于指定需要点击的按钮名称;只要子组件预测正确,模型即可获得部分奖励。类似地,“type_and_submit” 也包含子动作,用于提供需要输入并提交的文本内容。相比之下,“terminate” 不包含任何子动作,因此仅在动作类型层级进行评分。
在评估预测准确度时,我们采用任务特定的指标:
4)难度感知奖励缩放因子(Difficulty-Aware Reward Scaling, DARS)
由于长文本子动作预测难度较高 (现代网页可能包含数千个候选元素)我们进一步引入了 DARS,对正确预测这些组件的奖励进行放大。该机制可以有效防止一种常见的 reward hacking 行为:智能体不断选择简单的 “terminate” 动作来获取容易的奖励。
实验结果
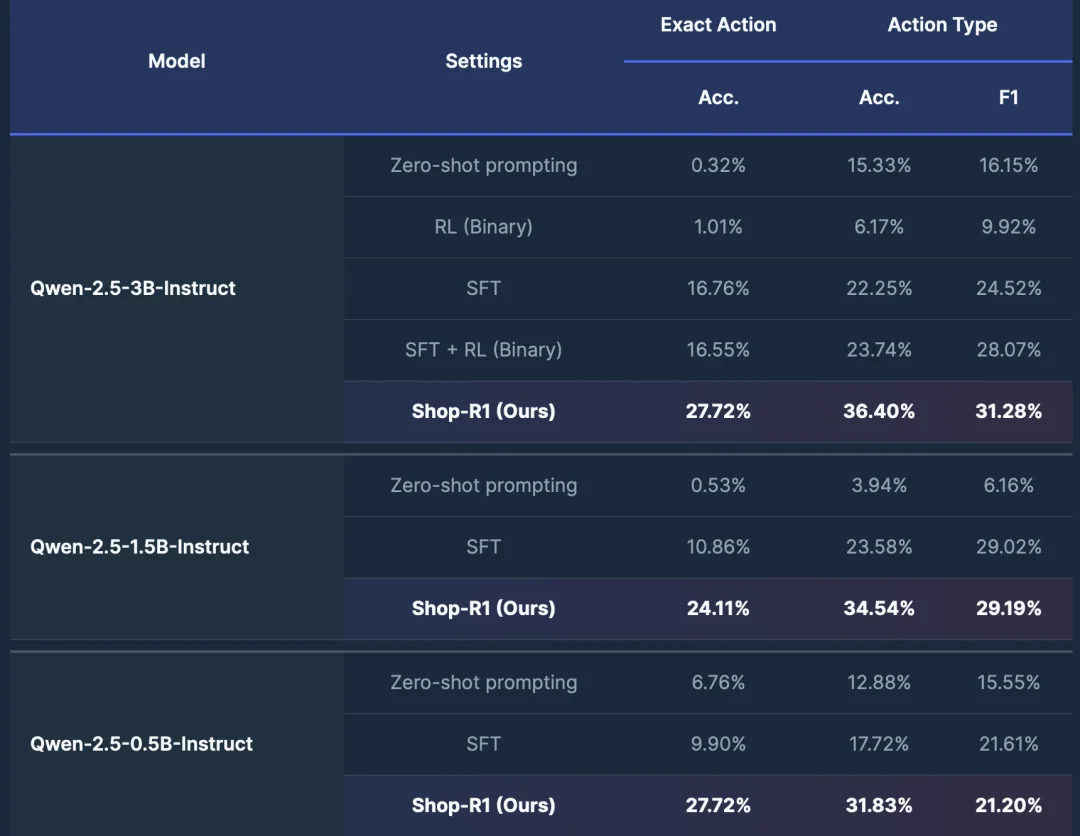
如表格所示,直接使用 zero-shot 提示几乎无法完成该任务,Qwen-2.5-3B-Instruct 的 exact-action 准确率仅 0.32%,说明长序列网页行为无法仅靠通用指令能力恢复。仅使用 稀疏二值奖励的强化学习同样效果有限,从零训练仅达到 1.01% exact-match 和 6.17% type accuracy。
相比之下,一轮 监督微调(SFT)可以显著提升性能(16.76% exact-match,22.25% type accuracy),表明密集的示例轨迹对于学习 context → rationale → action 的结构非常关键。但在 SFT 之后继续使用二值奖励 RL 提升有限。而 Shop-R1 通过结合层级奖励、self-certainty 信号、格式奖励以及难度感知奖励缩放,将 exact-action accuracy 提升至 27.72%(相对 仅 SFT 提升 65%),同时显著提升动作类型指标,表明模型不仅更容易识别正确意图,也能更准确生成按钮名称或搜索查询等长文本参数。
未来展望:视觉感官与性格派 AI
Shop-R1 的出现仅仅揭开了电商 Agent 进化史的一角,未来的突破点将集中在感官增强与个性化模拟上。
引入视觉语言模型(VLM)[1] 将是下一场进化的重头戏。现有的 Agent 高度依赖 HTML 代码,但人类网购时,往往会被一张富有氛围感的头图击中,或通过买家秀实拍图的细节来判断质感。赋予 AI “看” 的能力,意味着它能捕捉到那些无法被文本描述的隐含情绪。
更具颠覆性的构想在于 “性格化” (Character Injection) [2]。通过调整强化学习的奖励权重,研究人员可以赋予 AI 不同的消费画像:
这种多样化的智能体矩阵,将使 AI 能够复刻出真实世界中 “千人千面” 的消费心理。
结语:电商的 “购物模拟器”
Shop-R1 的落地价值,远不止于帮用户省下对比时间。对于电商巨头而言,它更像是一个低成本、高保真的 “虚拟 A/B 测试” 环境。在传统的运营逻辑中,测试一个新的推荐算法或页面布局,往往需要真实的流量和真金白银的补贴。而拥有了 Shop-R1 这样具备 “人类逻辑” 的模拟导向智能体,平台可以在实验室环境中投喂数万个 “AI 购物者”,观察它们在面对价格波动、界面改版时的实时反馈。这不再是一个简单的对话框,而是一个深刻理解人类欲望与权衡的购物模拟器。当 AI 开始学会解构那些复杂的浏览链路,并精准预测下一秒的操作时,人类与算法之间的博弈,才真正进入了认知的深水区。
参考文献:
[1] Zhang Y, Gesi J, Xue R, et al. See, Think, Act: Online Shopper Behavior Simulation with VLM Agents [J]. arXiv preprint arXiv:2510.19245, 2025.
[2] Wang Z, Lu Y, Zhang Y, et al. Customer-R1: Personalized simulation of human behaviors via RL-based LLM agent in online shopping [J]. arXiv preprint arXiv:2510.07230, 2025.
第一作者介绍:
张益萌,现任 Amazon Applied Scientist,研究方向为生成式 AI、AI Agent 与多模态智能体。2025 年于 Michigan State University 获计算机科学博士学位,曾为 OPTML 实验室成员,导师为刘思佳副教授。曾就读于 Columbia University 与 University of Sheffield。其研究关注高效机器学习、模型鲁棒性与安全,涵盖 LLM、扩散模型和对抗学习等领域,在 CVPR、NeurIPS、ICLR、ICML 等国际会议发表多篇论文。

文章来自于微信公众号 “机器之心”,作者 “机器之心”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
