# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
OpenClaw-RL的核心价值在于:它能让您的OpenClaw🦞仅仅通过与你日常对话产生的自然反馈(如你的纠正、补充说明或环境报错),就能在后台实时自动更新权重,变得越来越符合您的个性化偏好,并在实际任务中不再犯同样的错误。
谁能用?有两种人。前提是普林斯顿的这套工具是只为开源模型自托管玩家准备的。并且严格限定在CUDA生态内。因为系统需要执行实时的梯度下降操作,所以您必须掌握Agent背后大模型的完整控制权。
那如果我的设备没有cuda怎么办?(假设您用的Mac mini)对于这种情况,官方给的方案是Tinker云端路线,您的Mac只负责运行OpenClaw/OpenClaw-RL的本地代理与控制逻辑,真正的LoRA训练和云端采样由Tinker在它自己的GPU集群上执行。

OpenClaw-RL目前只有上述两种方案,如果您的龙虾🦞只想用闭源API(如Claude-Opus4.6)那这个框架就与您无缘了。明确了环境边界后,接下来,我们将硬核拆解其底层的Binary RL与OPD算法实现。项目地址:https://github.com/Gen-Verse/OpenClaw-RL

这篇论文最值得您注意的,不是又造了一个PPO变体,而是它对“交互数据”的重新定义。
换句话说,OpenClaw-RL的出发点不是“如何造更多训练数据”,而是“如何把已经存在的数据从上下文恢复成监督”。这是整篇论文最重要的思想支点。

在OpenClaw-RL的设计中,任何交互流都被形式化为一个马尔可夫决策过程(MDP),定义为四元组 :
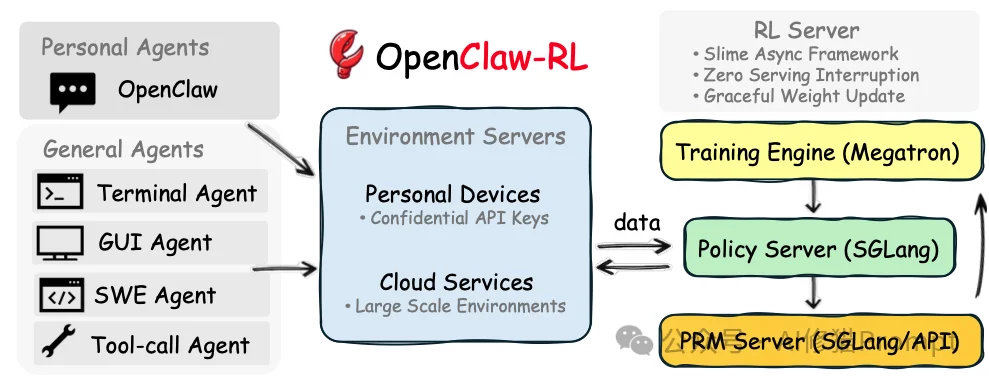

为了支持从单设备个人代理到云端大规模并发环境的在线强化学习,研究者基于slime框架构建了一个完全解耦的异步流水线。
OpenClaw-RL包含四个独立运行、互不阻塞的循环组件:
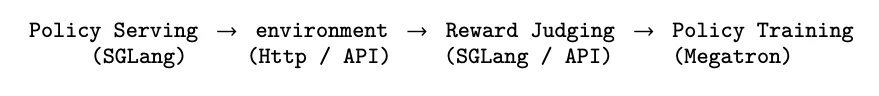
在这种架构下,模型在服务下一个用户请求的同时,PRM正在并行评估上一个响应,而训练器正在计算梯度并应用更新。这实现了服务零中断(Zero serving interruption),并避免了长周期任务导致的长尾阻塞问题。
系统支持两种环境拓扑:
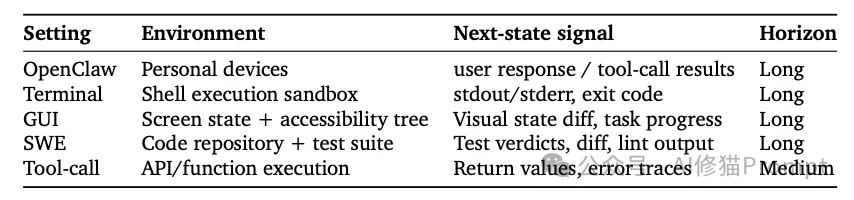
所有交互与评估数据(包括完整消息历史、生成的Token、PRM并行投票得分、提取的提示以及接受/拒绝决策)均通过后台线程以“触发即忘(fire-and-forget)”的模式实时写入JSONL日志。这确保了不会为推理或评估链路引入任何延迟。每次策略权重更新时,系统会自动清除日志文件,以确保收集的样本严格对应单一版本的策略。
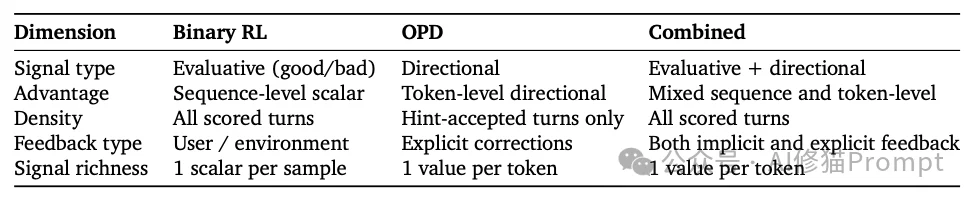
研究者设计了三种机制来处理不同丰富度的反馈流。
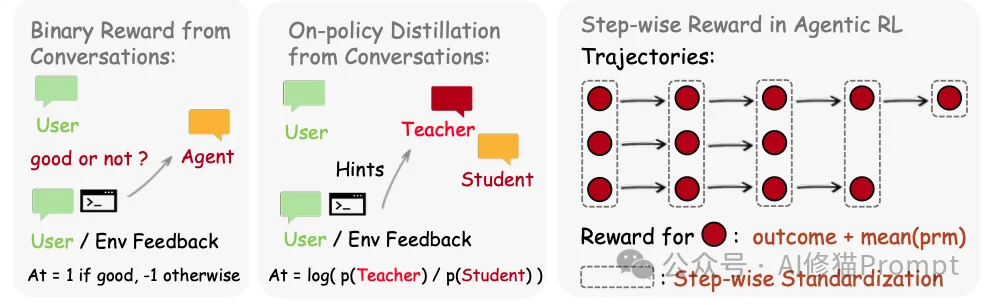
当信号仅包含“评估性”特征时,系统将其转化为标量过程奖励。

纯量奖励会丢失文本中的“指导性信息”。研究者提出了OPD算法,将下一步状态转化为Token级别的教师监督。具体操作分为四个步骤:

Binary RL覆盖面广(接受所有已评分轮次),OPD精度高(仅针对含有明确纠正指令的轮次)。研究者提出共享同一PPO损失函数,直接计算联合优势:
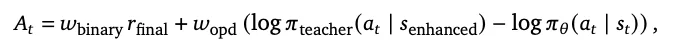


研究者在两条独立的赛道上对OpenClaw-RL进行了验证:个人代理赛道(验证从对话信号中持续个性化)和通用代理赛道(验证在终端、GUI、SWE、工具调用环境下的扩展性)。

**50%**)并采用自然的段落表述;教师代理仅需24次交互便学会提取学生的中间步骤并附加鼓励性表情符号。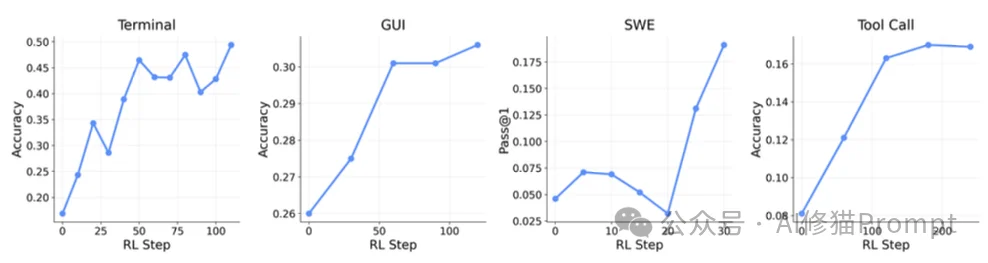

了解模型如何作为PRM进行判决是复现本论文的关键。研究者为不同场景设计了精确的系统提示(System Prompts)。


\boxed{1},差则输出 \boxed{-1},中立为 \boxed{0}。\boxed{1} 并在 [HINT_START]...[HINT_END] 内提供具体且可执行的1-3句话提示;否则输出 \boxed{-1} 并禁止提供提示。对于通用代理,裁判必须依据具体的环境反馈进行推理:
OpenClaw-RL证明了一个核心结论:每一次代理交互生成的信号都是流无关(Stream-agnostic)的,单一策略可以完全依赖这些伴生数据在同一个循环中进行同步学习。通过在架构层实现四路解耦异步,在算法层引入Binary RL提取评估纯量与OPD提取Token级方向指导,该系统彻底摒弃了对离线预收集数据的依赖。您部署的代理,只需处于正常的交互使用中,就能在长周期工具执行与个人风格偏好上实现全自动的策略进化。
文章来自于微信公众号 “AI修猫Prompt”,作者 “AI修猫Prompt”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
