# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
作者介绍:中科大团队包括共一作者冯源(博二)、郭浩宇(硕一)以及通讯作者谢希科(研究员),致力于以简洁算法优化大模型长文本推理,曾提出 AdaKV、CriticalKV 等主流 KV Cache 压缩方法,仅需数行代码显著提升压缩效果。新作 DefensiveKV 延续这一理念,仅需两行算法改动,显著降低 KV Cache 压缩损失。
随着大模型长上下文能力快速增长,海量 KV Cache 存储需求急剧增加,各类 KV Cache 压缩方法如雨后春笋般涌现。然而,这些方案在真实场景中的工程落地却常常陷入困境。

中科大研究团队在 ICLR 2026 的论文 DefensiveKV: Taming the Fragility of KV Cache Eviction in LLM Inference 中给出了答案:KV Cache 压缩领域的底层假设存在根本性缺陷!当前主流方法都基于一个核心假设:KV Cache 的重要性在不同时间段是稳定的。因此它们不约而同地选择观测一段历史窗口内的平均重要性,并据此淘汰 "不重要" 的 cache。然而,研究团队惊讶地发现,这一看似合理的稳定性假设在真实场景中十分脆弱!
通过深入分析大模型在真实长文本任务上的行为,团队观察到一个令人震惊的现象:尽管平均观测重要性指标在绝大多数时候能够准确反映 cache 的真实重要性,但在某些特定区间却会显著失效,甚至完全反转!
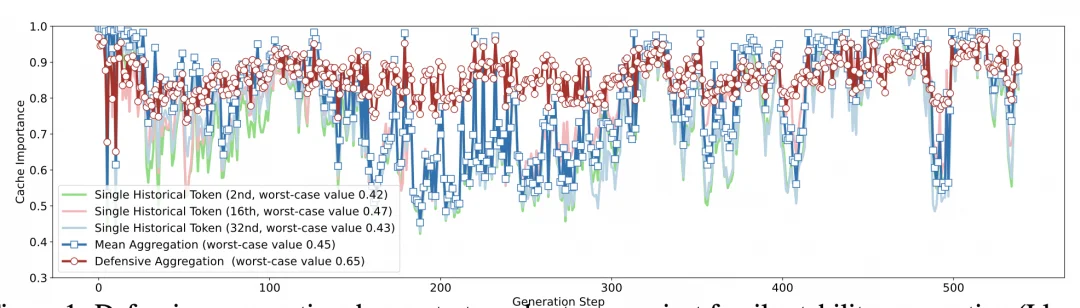
图 1:稳定性假设失效现象
如上图所示,蓝色曲线代表按照平均重要性保留的一半 "重要" Cache。虽然绝大部分时刻这一半的 cache 能保持整体 90% 以上的真实重要性,但在特定时刻(如第 200-300 时间步),保留的 cache 甚至无法达到全部 cache 50% 的真实重要性!这种” 稳定性崩溃 " 绝非偶发,在单次回复中竟出现高达 65 次之多。
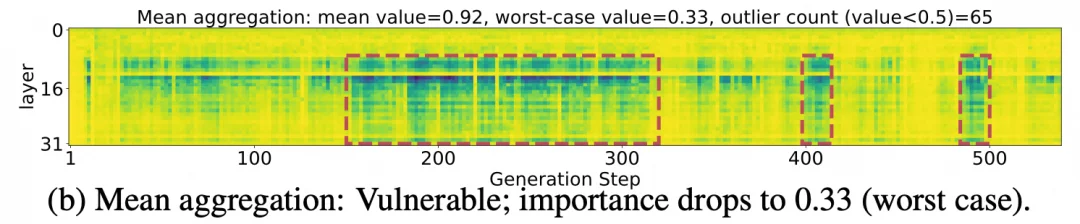
图 2:稳定性崩溃统计
这揭示了一个深刻的认知盲区:以往工作过分信任 "平均情况",却忽视了真实部署中最致命的最坏风险。正如金融领域的经典教训 —— 只优化平均收益而忽视极端风险的策略注定失败。当稳定性假设在关键时刻失效时,使用平均值作为压缩指示器就像在薄冰上行走,随时可能坠入深渊。
针对这一根本性缺陷,团队提出了革命性的防御性聚合(Defensive Aggregation)策略。这一策略彻底颠覆了传统的 "平均优化" 范式,转而采用 "最坏风险控制" 的防御性思维 —— 不再关注平均损失,而是将全部注意力投入到 worst-case 的预防中。
在重塑关注点之后,团队提出了一个极简的优雅设计 —— 核心算法仅需两行代码即可实现:

图 3:核心算法仅需两行代码
第一步:最坏风险估计(Worst-case Risk Estimation)
团队从风险控制角度重新思考驱逐策略 —— 驱逐一个 KV cache 的最大风险等价于它在未来可能达到的最大重要性。由于未来不可知,团队巧妙地用历史观察中的最大值来估计这一风险:只要一个 cache 在任一历史时刻表现重要,就将其视为高风险而保留。这个看似简单的 "取最大" 操作,却能精准捕获那些可能在未来关键时刻大放异彩的 token。
第二步:自适应先验风险修正(Adaptive Prior-Risk Correction)
考虑到最坏风险估计中的观测次数有限(通常仅 32 次),可能遗漏一些关键的风险。团队受贝叶斯估计中 Laplace 平滑启发,提出了一种基于先验的观测风险修正机制:计算每个注意力头中所有 KV cache 的平均观测风险作为先验风险。当某个 cache 的观测风险低于该注意力头中所有 cache 的平均风险时,自动用先验风险进行修正,防止因观测不足而遗漏高风险 cache,提供更保守的保护。
这两步操作均为线性时间,计算复杂度与传统平均值聚合相同,却带来了质的飞跃:图中防御性聚合(红色曲线)相较于之前的平均值聚合(蓝色曲线),几乎完全消除了离群点,将最坏情况下保留的重要性分数从 0.45 提升至 0.65。
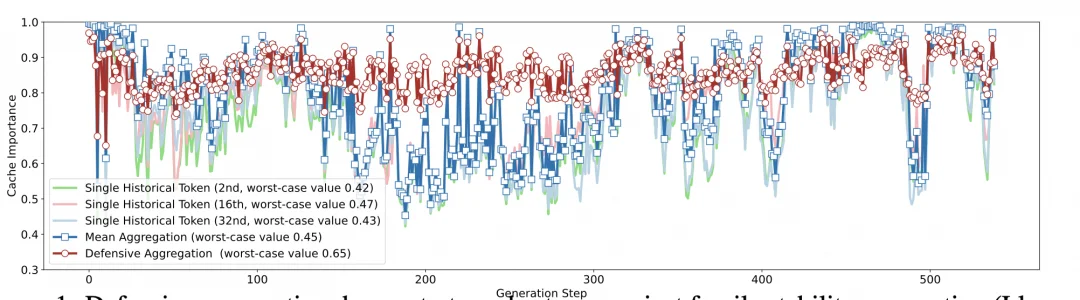
图 4:Defensive Aggregation(红色曲线)有效对抗脆弱假设,消除离群点
研究团队将之前的 SOTA 压缩方法 CriticalKV 中的平均聚合替换为防御性聚合,实现了全新的压缩方法 DefensiveKV 及其层间调度增强版 Layer-DefensiveKV。实验结果令人震撼:仅需两行代码的修改,就实现了显著的性能飞跃。
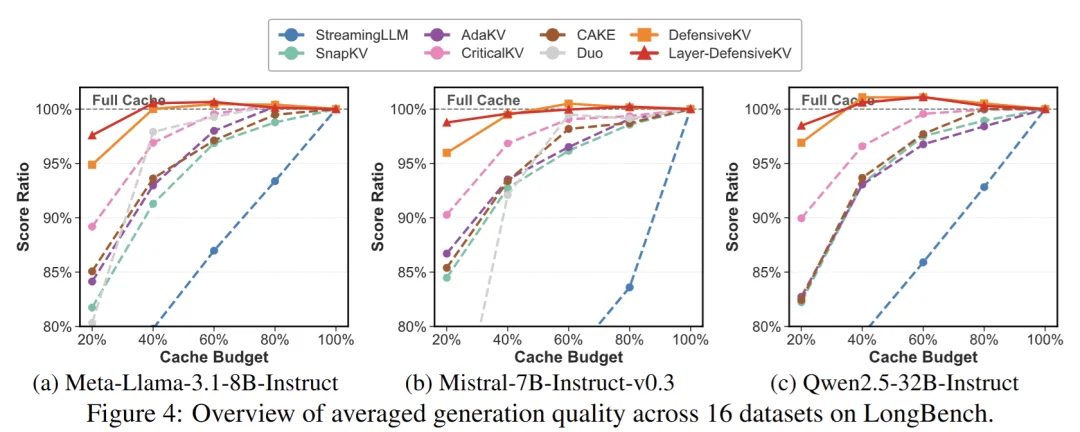
图 5:DefensiveKV 和 Layer-DefensiveKV 展示了领先的性能
文章中的测评横跨 7 个任务领域、18 个数据集、3 个不同规模的主流开源模型,一致性地刷新了 KV Cache 压缩的性能边界。例如,在 Llama-3.1-8B 模型 20% cache 预算的严苛压缩条件下,相比最强基线 CriticalKV(质量损失 9.6%),DefensiveKV 将损失降至 4.1%(2.3 倍提升),而 Layer-DefensiveKV 更是仅为 2.1%(4.6 倍提升)。
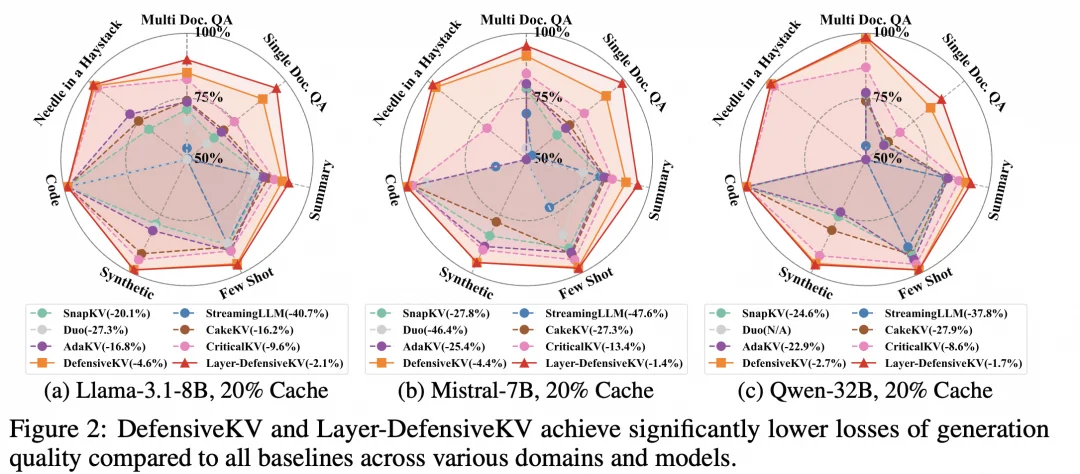
图 6:DefensiveKV 和 Layer-DefensiveKV 平均压缩损失极低
这项工作的重要价值不仅在于算法性能提升,更在于重新定义了 KV Cache 压缩的优化目标。它首次揭示了现有算法底层稳定性假设的本质脆弱性,开创性地将最坏风险控制思想引入该领域,为后续研究指明了全新方向:与其设计更精密的重要性指标,不如构建更具防御性的策略来对抗底层假设的脆弱性。这种防御性思维 —— 宁可错留、不可错删 —— 或许是通往真正鲁棒长上下文推理的关键钥匙。
DefensiveKV 的全部代码已经开源,提供了完整的实验环境配置、打包数据集、评测代码以及详细的使用文档。团队额外特别提供了一个一小时内完成的迷你复现 Demo,感受防御性聚合带来的强大性能。
文章来自于“机器之心”,作者 “机器之心”。



