# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在大模型后训练阶段,监督微调(SFT)和强化学习(RL)是两根不可或缺的支柱。SFT 利用高质量的离线(Off-policy)数据快速注入知识,但受限于静态数据分布,泛化能力往往容易触及天花板并带来灾难性遗忘;RL 则允许模型在探索中不断自我迭代,产生与当前策略同分布(On-policy)的数据,上限极高,但往往伴随着训练极度不稳定、计算资源消耗巨大的痛点。
那么,我们有没有可能取长补短?直接产生 On-policy 数据并用高效的 SFT 训练,从而达到媲美甚至超越 RL 的效果?
为此,微软、东南大学联合提出新工作「Towards On-Policy SFT: Distribution Discriminant Theory and its Applications in LLM Training」。量化和理解 SFT 和 RL 在数据层面的差距,并提出 IDFT / 域内微调(损失层面)和 Hinted Decoding / 提示解码(数据层面)等高效后训练技术。

「On-policy 数据」到底是什么?如何「量化」?
什么是 On-policy 数据?简单来说,就是模型用当前自身能力生成的数据,而传统的 SFT 使用的是外来的、人类或更强模型生成的「标准答案」(Off-policy)。这两者之间存在天然的分布偏移(Distribution Shift)。
以往大家可能会想,直接用大模型领域最常用的困惑度(Perplexity, PPL)或者对数概率(Log-Likelihood)来衡量不就行了?PPL 低说明模型对这部分数据「很熟」,PPL 高就说明是陌生的分布外数据(OOD)。
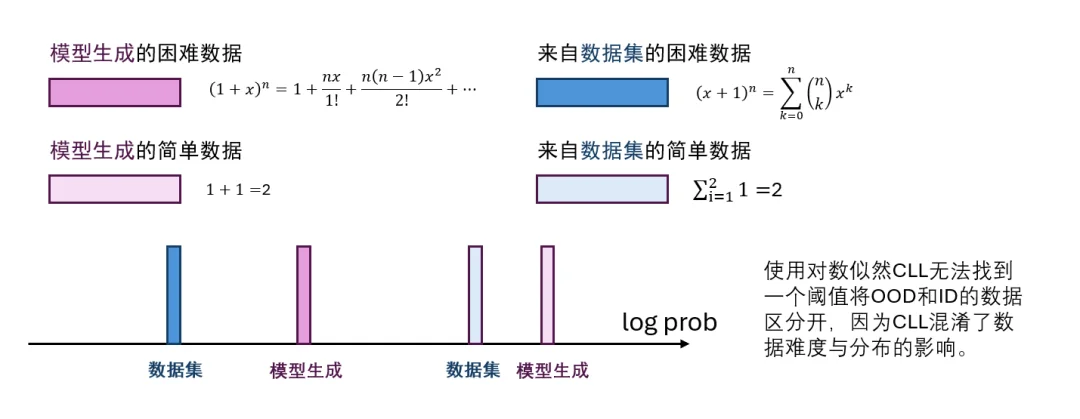
但实际上,困惑度(PPL)会把「题目本身的难度」和「数据分布的偏移」混为一谈。比如在解答一道极具挑战性的数学题时,由于推理步骤复杂、可能的走向众多,模型输出的 PPL 自然会很高。但这仅仅是因为「题目难」(上下文难度大),并不代表这段推理不是模型用自己的「原生语感」写出来的。
换句话说,传统的对数概率或 PPL 在计算时,包含了大量来自上下文本身难易度的「噪声方差」。为了精准剥离这层干扰,本研究通过将问题建模为统计学假设检验背景来证明,存在一个信噪比(SNR)严格最优的量化指标——中心化对数似然(Centered Log-Likelihood, CLL):
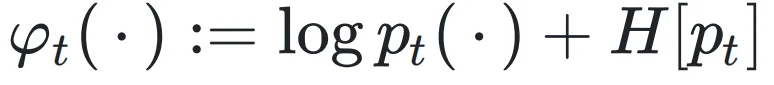
即:量化指标 = Token 的对数概率 + 当前上下文的预测熵。文章利用信号检测理论,证明了这个指标具有信噪比意义下的最优性,并给出了用和序列进行判断的误差界。具体细节见原文。

这套理论的优点是它几乎没有任何偏离 LLM 场景的理论假设,因此可以直接进行实验验证:
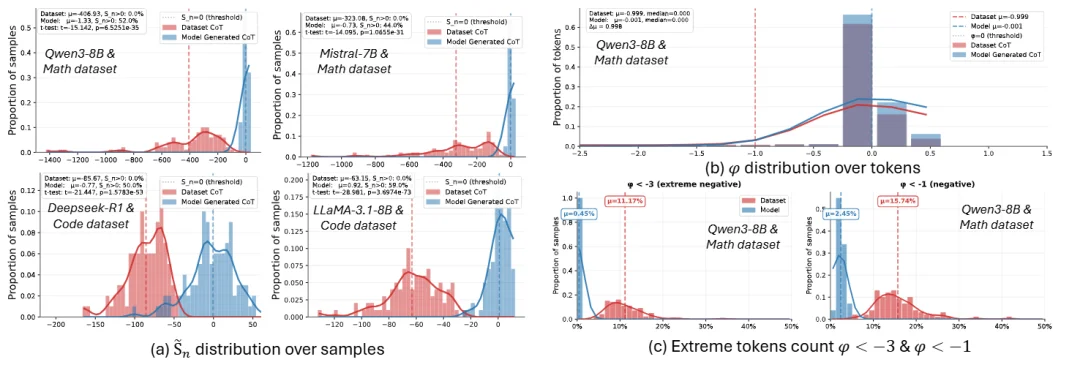
结果表明,文章中提出的指标确实明显地将来自模型生成的数据(红色)和其他来源的数据(蓝色)显著区分开。并且发现一条数据是否来自模型,事实上只受少量离群值 Token 的影响——就像你我语言风格不同,但区别也仅在少量语气词和用词习惯上不同,大部分 Token 为了满足语法和逻辑连贯性,区别是不大的。
这个工作的核心是一个简单清晰的第一性原理:先找一个稳定的量化指标指示 On- 和 Off-policy 数据的差距,然后在算法和数据上消除指标的差距,是否就意味着消除 SFT 和 RL 的差距?
传统的 SFT 有一个致命的假设:它认为训练集里的每一个词都是绝对的「真理」。
因此,SFT 的标准损失函数会对预测错误施加极其严厉的惩罚:当模型对某个词的初始预测概率趋近于 0 时,其梯度会直接爆炸(趋向于无穷大)。
这就导致了一个极其严重的后果:一旦训练数据中混入噪声,或者遇到了大幅超出模型当前能力的「分布外(OOD)」硬核数据,SFT 就会强迫模型通过剧烈的参数更新去「死记硬背」。这种暴力的拟合会粗暴地打碎模型在预训练阶段建立起来的通用知识网络和内在 Pattern。这也是为什么 SFT 往往会引发严重的「灾难性遗忘」,导致模型学了新知识,却丢了泛化能力。
为了拔除这个病根,文章提出了域内微调(In-Distribution Fine-Tuning, IDFT)。
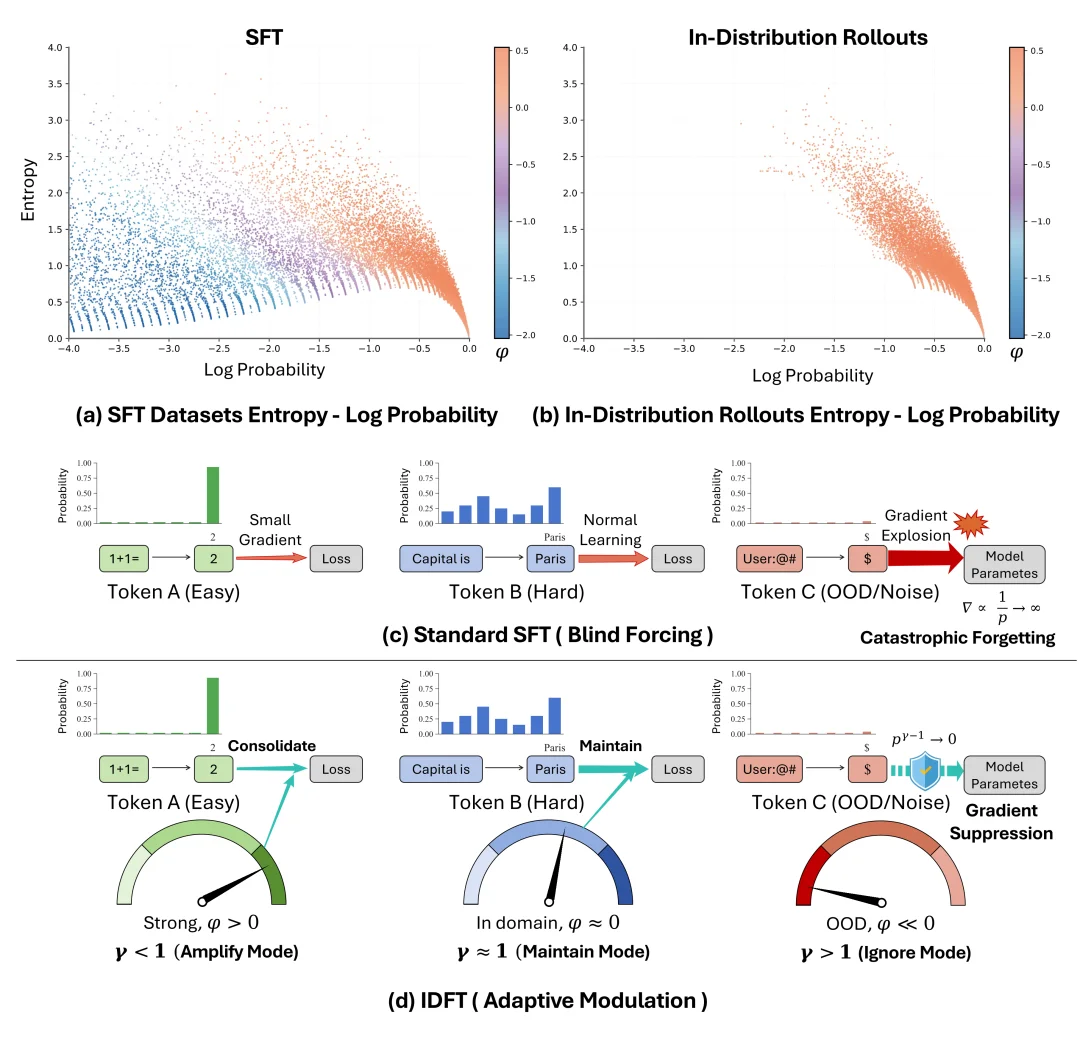
IDFT 放弃了强硬的盲目拟合,而是基于前文提到的量化指标 CLL(中心化对数似然),引入了一个精妙的「自适应调节」机制:
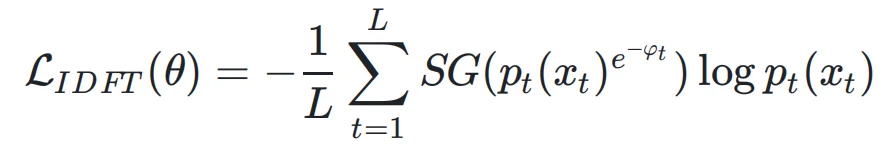
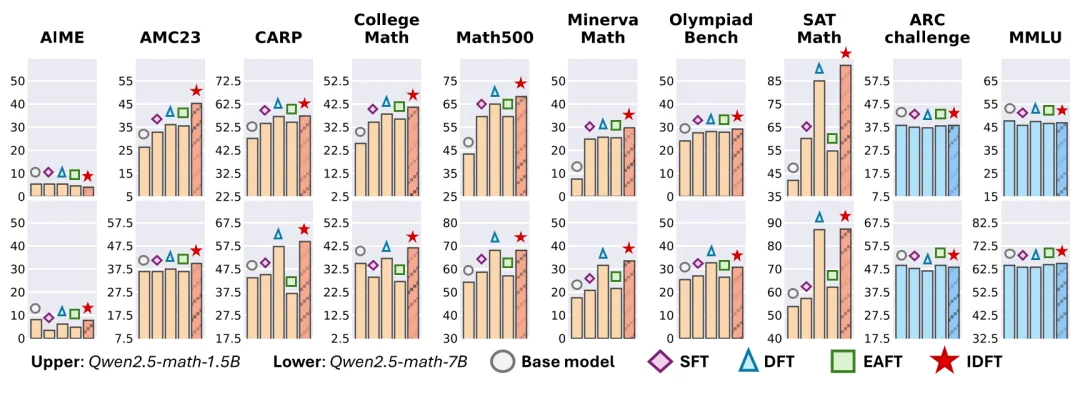
最终的实验结果也符合预期:
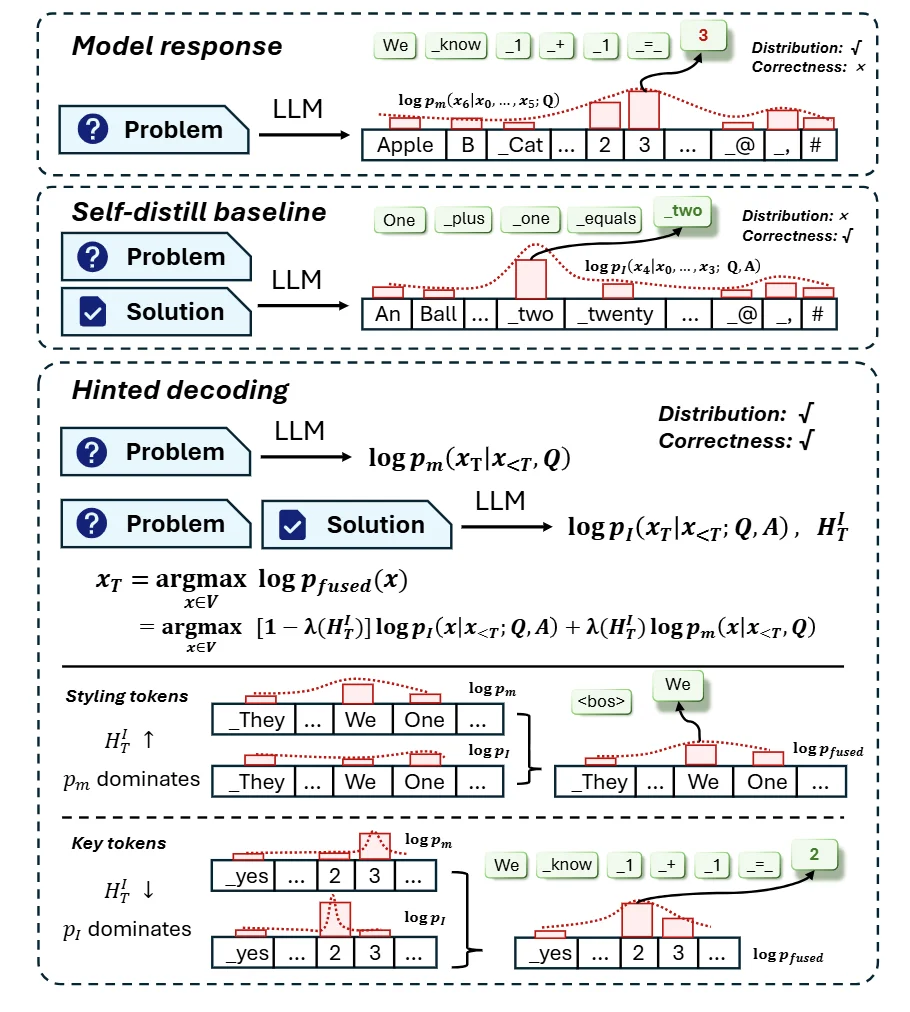
回到如何把数据集转化为 On-policy 版本的问题,一个非常直接的想法是给一个样例让模型重写 CoT 并模仿模型的风格。这被前人工作称为 Self-distillation。然而,文章表明,无论是 Case study 还是量化指标还是训练结果都表明:哪怕人眼看 Self-distill 的数据很像模型的分布,但对于模型训练来说,还是 Off-policy 的。

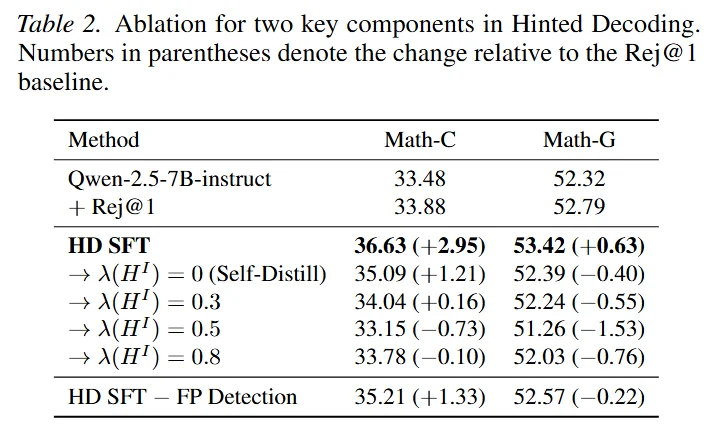
为了解决这个问题,文章提出了 Hinted Decoding,在 Self-distill(Teacher)和正常做(Student)之间做模式切换。以 Teacher 的熵为切换依据:如果看得到答案的模型认为当前 Token 确定性极高,说明是决定答案正确性的关键内容,则 Teacher 的比重增加;否则,则是风格性 Token,交给原本模型保持。结果表明,使用 Hinted Decoding 确实把模型的分布性指标提升上去了。
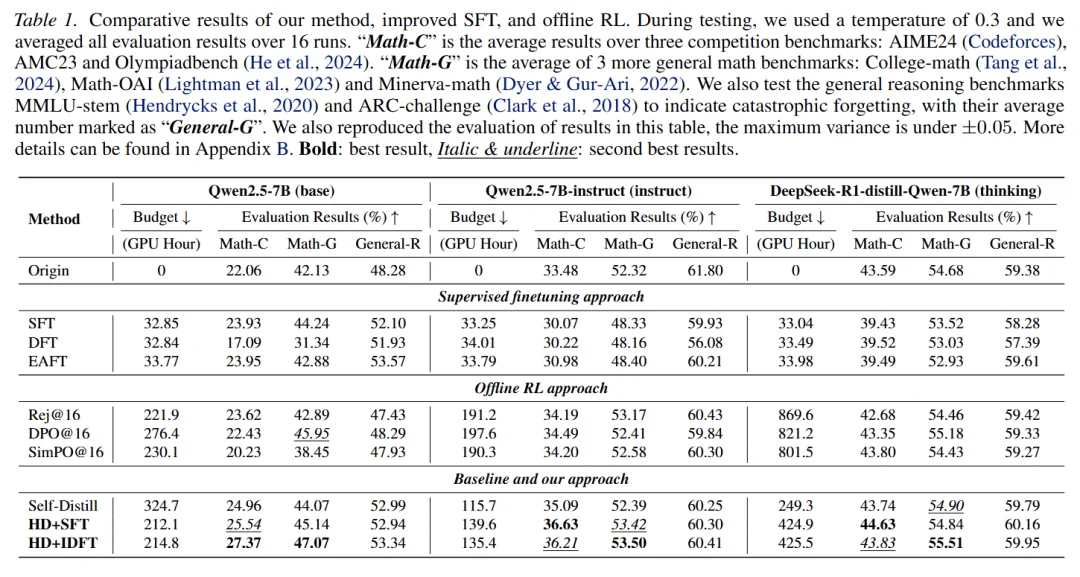
由于文章是对数据集一次性全处理的,因此与 Offline RL 算法公平比较。可以看见,文章提出的新方法不仅超越了出名的 Offline RL 算法,并使用远低于 RL 的资源。消融实验表明,Hinted Decoding 并不是简单的两种方案的加权,直接简单加权并不能取得很好的效果。基于熵的自适应模式切换是极其重要的。
强化学习因为监督信号弱,被图灵奖得主 Yann LeCun 比作蛋糕上的樱桃。不可否认,在很多智能体、偏好学习等场景,强化学习难以替代。但对于拥有大量过程数据的场景,没有理由设计不出一个算法比只用答案验证的强化学习好。本文的工作提供了一个初步的尝试。
除此之外,这个工作还与多个领域和场景有天然交集:CoT 补全的过程和 dLLM 解码过程高度相似;文章中的指标可用于给定输入的 LLM 生成检测;双模型解码的过程与 Speculative Decoding 可以自然结合;文章中的理论可以应用于 On-policy Distill、OPSD 等的改进中;提示解码也可以应用于蒸馏当前不开放 CoT 只返回输出结果的商业模型。是一个具有发论文和应用潜力的基线工作。
本文两位共同一作:
文章来自于“机器之心”,作者 “张淼森、刘益杉”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
