# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文中的“我们”指的是两位硬核教授,
张家俊教授,
中科院自动化所研究员、
中国科学院大学岗位教授、
武汉人工智能研究院副院长;
王金桥教授,
中科院自动化所研究员、
武汉人工智能研究院院长;
再加我,科技作者谭婧。
这次表面上是聊一篇论文,
其实要聊两篇论文。

第一篇论文来自字节SEED团队,
打了一些基础;
《Over-Tokenized Transformer》。
论文标题看上去在讨论“过度分词”。
而重点必然是在第二篇上——
DeepSeek公司的学术成果Engram。
《Conditional Memory via Scalable Lookup》
也就是Engram模块所出处的论文。
毋庸置疑,Engram“核心思想”是检索,
但它并不是为了做检索而检索。
既然资源总是有限,
那么就需要计算和记忆和平衡。
本质上,既然能直接从记忆中检索到,
就不用重复计算。
那么废话少说,
现在开始吧。
当下的AI,
记忆是一个宏大的叙事,
外挂,压缩,总结都是方法,
想去解决大模型记忆能力不足,
一杆子打三枣肯定不行,
摘光低垂的果实,再跳起来够高处的。
也肯定会有博士,博士后,
拿出人生的宝贵时光,专攻于此。
Engram它是模型的“记忆模块”,
肯定算是高处的果实,
它的出现也水到渠成,
正巧处于“上下文”技术并不完美的阶段。
“上下文”,像一种临时草稿纸。
扩展上下文,就是在增强记忆,
它属于扩大计算窗口的路径。
然而,“上下文”再怎么长,
还是有一个明确的边界。
无论你的长度从几千,
还是到几百万token的数量。
当下看来,“上下文”的方法还是“保守了”:
所有信息都用注意力计算(attention),算一遍,
也就是让模型给每个词算“和其他所有词的关系”,
当然,成本线性上升。
比如,一篇文章里,
“彭于晏”出现了88次,
与其算88次,
不如把“彭于晏”,
压缩成一个记忆单元,
以后就只算一次。
这个就是Engram的思路。
学术说法是:
将这种高频,常见的信息,抽取为结构化记忆,
需要之时,直接检索,而不是重新计算。

这真是一个好想法,
但是,
在哪里检索?
以何种形式检索?
这些都是重要技术细节。
模型架构改进,
它解决的是计算路径怎么高效。
如果想成一个二维坐标,
横轴(模型架构)=让大脑“更聪明”
纵轴(记忆系统)=让大脑“记得住”
这俩不是一回事,而且互相替代不了。
DeepSeek想解决,
如何在“计算”和“记忆”之间找到最优平衡。
怎么把记忆变成拓展无限的呢?
这个问题,光想想都觉得十分有趣,
需要记忆的东西也很多,
比如你女友的生日,例假日期,忌口。
这些是常识,是基础知识,不能犯错。
而“知识”是智慧的结晶,
那就更高级了,必须被“记忆”搞定。
Deepseek也是从记忆“知识”下手,
人类世界,有很多信息是固定不变的知识,
比如人名、地名、机构名,成语。
别重新计算了,
要不然还占了用于复杂推理的资源,
省下的算力就可以增加计算的深度。
目前多数方法依赖计算,
而很少用检索。
这是一个非常有价值的思想,
它代表着一种范式的探索:
Engram的核心创新在于,
将检索扩展到N元组或短语级别,
通过识别固定下来的短语和组合来检索。
常言道:“找”比“算”快。
“gram”源自希腊语,
本义是,写下来的东西,
program(往前写 → 计划),
telegram(远写 → 电报),
Engram(记忆 + 书写 → 记忆单元),
好的,小学生单词词尾记忆法介绍到这里。
我们接着聊计算机科学,
后面演化出:
“最小有意义的语言片段”的含义。
2-gram,3-gram,
多了就是N-gram,
于是,N-gram就是语义候选单位。
token是模型为了计算切出来的“碎片”,
而gram是这些碎片,
在语境中重新长出来的“意义”。
“中国”和“科学院”,
分别是两个token的话,
“中国+科学院”,就是2-gram,
也是两个连续token的组合,
实际上,模型事先并不知道,
哪些是有意义的2-gram组合,
因此,枚举所有2-gram,
都进行向量表示(embedding),
这样,后面模型碰上的话,
就不用再计算语义组合了。
还有两个好问题。
第一,为什么强调连续?
强调是连续的2个token组成的片段(词块)。
因为其本质在捕捉局部关系(上下文);
也就是,只看近处,远处不看。
第二,token和gram如何比大小?
token是文本序列切分的最小单元,
gram是组合的最小单元,
1-gram就是一个token,
这时候,gram=token,
但是,gram也可以根据组合规则确定,
例如gram等于一个词语的词性,
那么n-gram就是关于词性的n-元组,
也就是说,n-gram的基本组合单元,
由我们人为定义的语义决定,
而token是相对确定的。
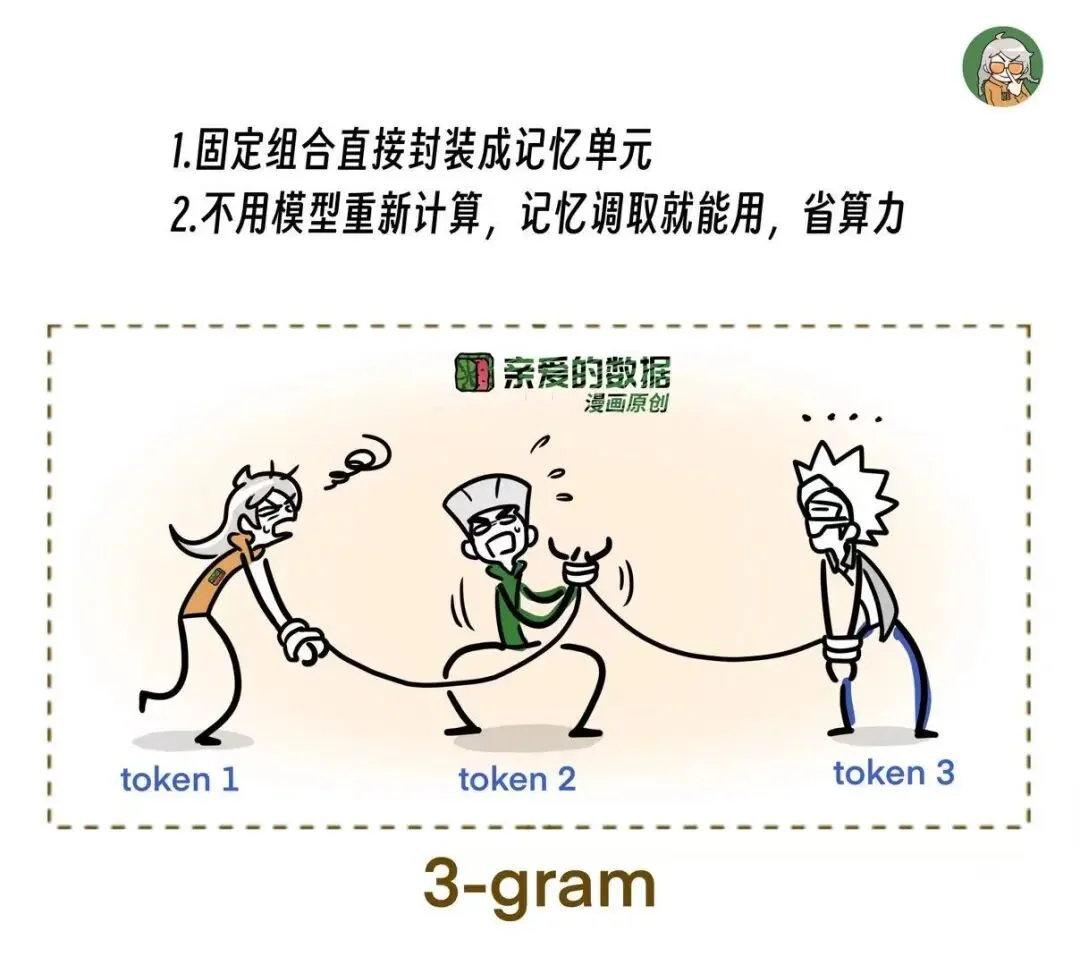
既然要组合,那就再讲一下组合爆炸怎么来的?
假设词表大小 = V
2-gram的数量 = V²
3-gram的数量 = V³
n-gram的数量 = Vⁿ
词汇表一般几万甚至几十万,
2-gram就是几万的平方就是几亿,
3-gram就是几万的三次方就是千亿量级。
为什么只做到3-gram?
超过3就不现实,存储和检索成本太高。
模型为了直接利用这些组合进行处理,
这时候需要将组合(如2-gram、3-gram等),
预先映射到一个Embedding空间中,
形成一个可以高效存储和检索的表示,
使得固定的、稳定的模式可以被快速检索。
有了组合(短语),下一步就是检索。
这些片段是Engram检索的核心对象。
这些词块变成了“检索单位”。
一旦成为检索单位,
系统就不再依赖“语义相似”,
这一步,把检索从“像不像”,
变成了“有没有”。
再往深聊,
语义理解解决的是,
你知不知道它是什么,
而检索解决的是,
你能不能稳定地把它找出来。
检索中用到什么技术呢?
哈希映射的结构化记忆单元。
张家俊老师所带领的NLP研究组,
曾做过这种分组哈希的方式。
为了去解决规模太大,
又希望语义表达空间充足的时候,
会用到的方法。
哈希的目标就是,
希望用更少的存储来实现更多的表征。
哈希映射的作用是将token序列(或N-gram),
映射到一个结构化的内存空间,
通过哈希表的方式索引,
例如,如果“檀健次颜值高”,
作为一个稳定的短语出现频率很高,
Engram可能会为它分配一个哈希位置,
将这个短语的语义,
与哈希表中的某个索引关联起来。
这样,当模型处理类似的短语时,
通过哈希检索,
就可以直接找到对应的信息,
而不需要重新计算。
既然要找(检索)东西,
在建模阶段,就必须讨论清楚,
“要找的东西”到底怎么表示。
假设“要找的东西”就是一个“概念”。
Token组合可以形成比较完整的概念,
但毕竟token是从词汇切分而来,
那就要思考:怎么分,才更好算?
如果词汇切分token切粗一些,
token是否不用组合,
就能形成比较完整的概念?
最极端的方式,就不切分词汇,
一个完整的词汇,就是一个token,
那样词汇表将非常大,
学习词向量(embedding)就成为难题,
很多词汇出现次数太少,
那就很难学到准确的表征。
也就说,token不能切太“完整”,
因为越完整 → 出现越少 → 模型学不会。
字节的论文为DeepSeek的论文,
打下了什么基础?
字节的做法是通过“暴力推测”,
来尽量预见哪些组合会在后续有意义,
从而在后续阶段减少计算量。
字节SEED团队论文的方法,
也是一种预处理的手段,
没有用到检索的这个方式,
检索是DeepSeek“原创”的。
两篇论文,目标一样,方法不一样。
因为Deepseek没有用“暴力推测”,
而是用检索的方法替代了输入的爆炸。
至此,检索这个关键动作终于付出水面。
我们认为,这两篇论文的思想目标是一样的。
就是为了怎么更好,更快的,
把能固定的语义提前给它计算好,
进而理解为,
让模型把“提前算好”的东西,
给提前给它记住。
从检索到记忆,逻辑就是如此。
字节的方法往前推进了一步,
尽管后面省力气,
但是,用分词和过度分词来处理输入文本,
这样的计算方式可能会导致输入的膨胀,
即文本的处理量会急剧增加,
更别谈在长文本或复杂句子中,
模型需要处理更多的token。
过大的计算负担始终存在。
回到论文结果,
如果每一层都能查记忆,
那到底哪一层查,效果最好?
Engram在使用时,
并不是每个层级都直接检索。
相反,模型会逐层探索,
查看在哪一层检索的效果最好。
Deepseek论文里的结论是,
第二层效果最佳,
也就是Engram最明显的效果的层数,
并不是在模型的第一层或最后一层,
而是在中间,第二层。
这是实验结果。
最后,
所有知识可以“重新计算”出来,
也可以增加一个“先记忆再检索”的方法。
让记忆给计算打个配合。
你说检索香不香?当然香,找东西贼快,
但也不能一招鲜吃遍天,啥都靠找。
你想,大脑这玩意儿,压根就不是本翻页词典。
真正的聪明的玩法是啥呢?
让检索配合着计算来。
这就好比,
向世界各地小学数学课上推广,
九九乘法表。
文章来自于"亲爱的数据",作者 "亲爱的数据"。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
