# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
昨天,AI 圈最炸的一件事,莫过于 Claude Code 的源代码「被动」开源。
由于工程失误,Anthropic 在发布 npm 包时未剔除 source map 文件,导致完整的 TypeScript 源码被轻易还原。短短几个小时内,代码已经被下载、镜像,并在 GitHub 上迅速扩散。
这种泄露方式,怎么不算某种意义上的开源呢?就连马斯克在看到别人评论「Anthropic 现在已经比 OpenAI 更 Open」时也忍不住「夸上一句」:「绝了😂」。
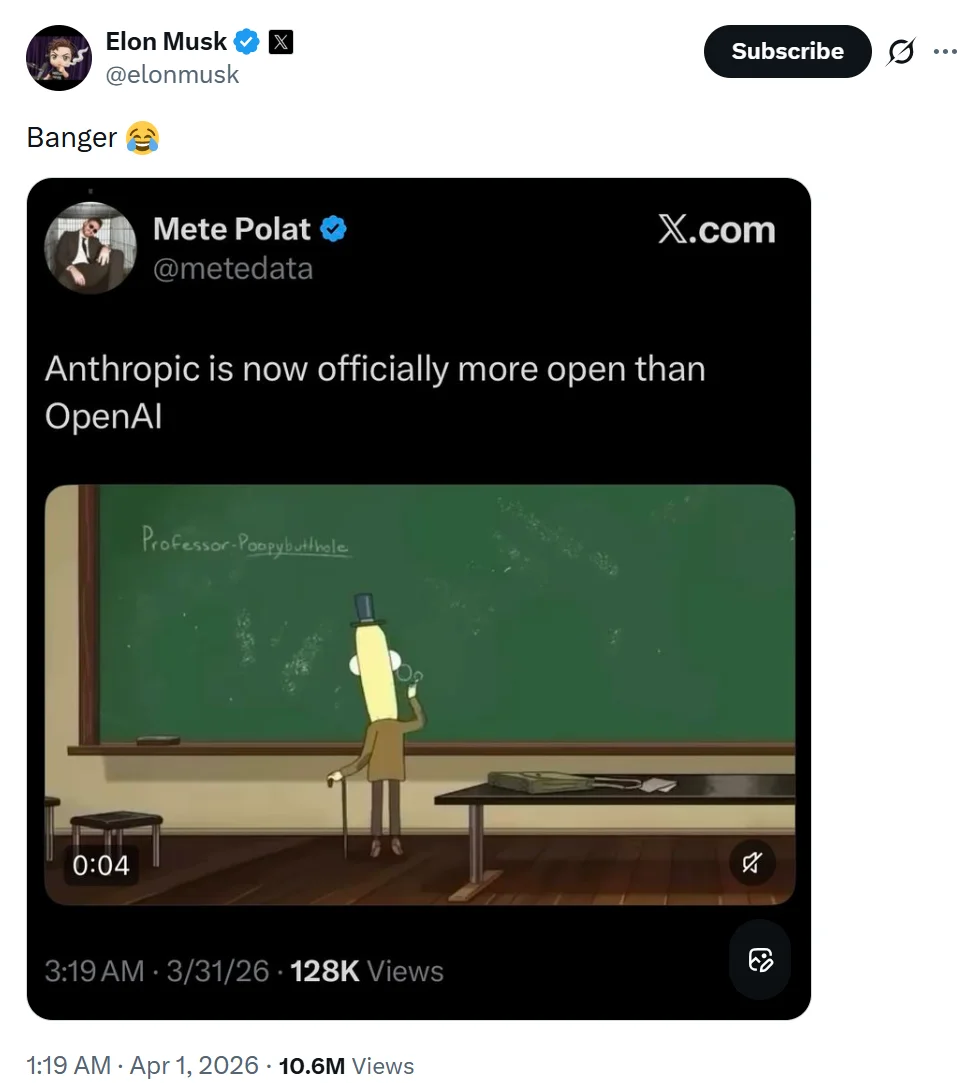
至于此事的原因,也并不复杂,尽管 Anthropic 尚未发布官方报告,但科技媒体 Decrypt 从一位 Anthropic 发言人那里得到了评论:「今天早些时候,一个 Claude Code 版本包含了部分内部源代码。没有涉及或暴露任何敏感的客户数据或凭证。这属于人为错误导致的发布打包问题,并未构成安全漏洞。我们正在采取措施防止此类事件再次发生。」
Claude Code 之父 Boris Cherny 也在 X 上简单表示这「就是开发者的错误」所致。

就在大家还在围观这场被动开源的戏剧性时刻时,另一批人已经开始沉下心来逐行阅读代码,并尝试还原其背后的设计逻辑。
一些原本不对外公开的系统级策略也被揭示出来,尤其是在模型能力保护与数据安全层面,Claude Code 显然做了更深的工程设计。
当吃瓜群众还在围观时,大量开发者已经开始逐行阅读代码,尝试还原顶级 AI Agent 背后的设计逻辑。一些原本不对外的系统级策略也随之曝光。
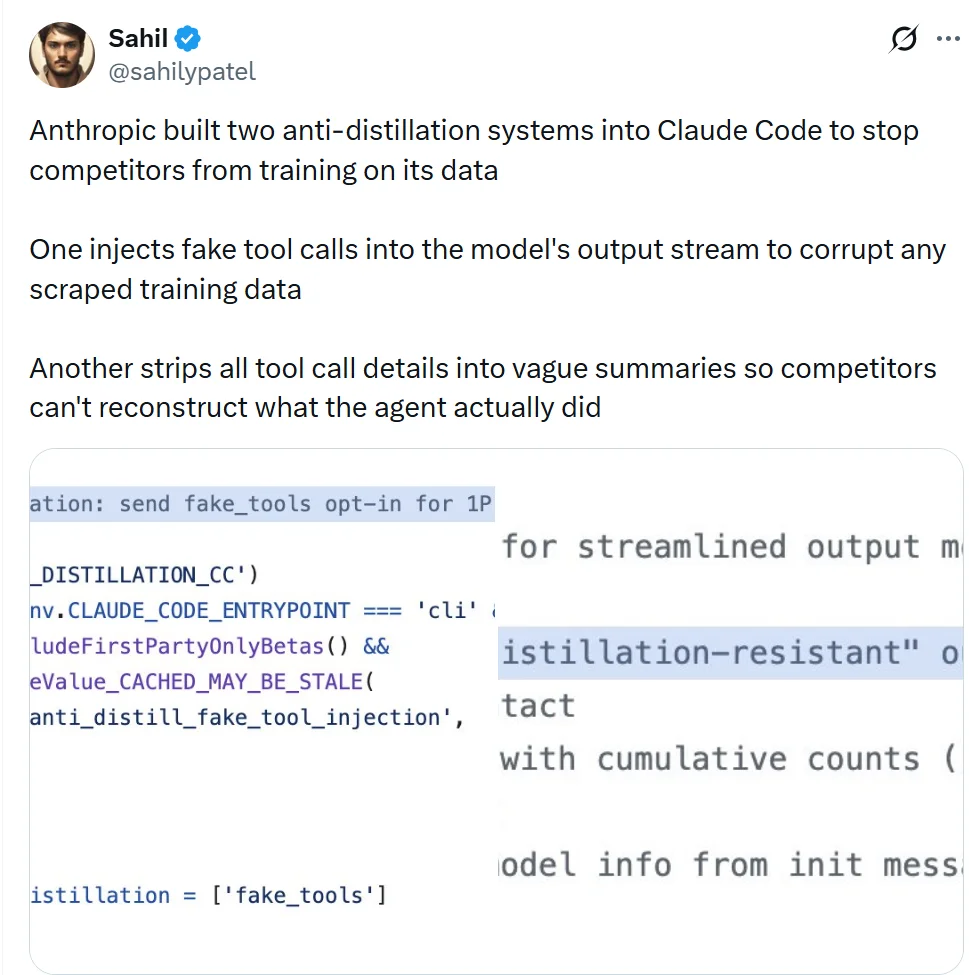
Claude Code 内置了两套反蒸馏机制
X 用户 Sahil 发现:Anthropic 在 Claude Code 中内置了两套反蒸馏机制,用于防止竞争对手利用其数据进行训练。
来源:https://x.com/sahilypatel/status/2039004352367689891
Claude Code 源码可以学到并复用的东西
而 AlphaSignalAI 开发者 Lior Alexander 则对 Claude Code 源代码进行了深度分析,并给出了 14 点总结,我们挑选了其中几条比较有价值的供大家参考:
来源:https://x.com/LiorOnAI/status/2039068248390688803
1:系统提示词是一门行为控制的范本
完整的 system prompt 位于 constants/prompts.ts,可以说是整个代码库中最有价值的文件。它清晰展示了 Anthropic 是如何在生产级编码 Agent 中精确控制 Claude 的行为,以及每一条指令背后的设计动机。
三行重复代码,也好过过早抽象。在编码指令部分,系统明确要求 Claude 不要为一次性操作创建 helper、工具函数或抽象结构,也不要为假想的未来需求做设计。
默认不写注释。一个带有 @[MODEL LAUNCH] 标记的注释说明,这是为了对抗内部代号为 Capybara 的模型默认过度注释的问题。只有在 WHY is non-obvious 时才允许添加注释。
如实报告结果。另一个 @[MODEL LAUNCH] 标注透露,Capybara v8 的错误陈述率高达 29–30%(相比 v4 的 16.7%)。因此,prompt 明确规定:
用数字约束比用模糊描述更有效。源码中的注释提到:相比简洁表达,使用明确字数限制可降低约 1.2% 的输出 token。因此,Anthropic 不说写得简短,而是直接规定:
外部提示词与内部提示词分层设计。对外用户使用的提示词是简洁版,比如:直奔重点,尽量简短。而内部(Anthropic 员工使用)版本则更复杂。
隐藏的 Simple 模式。当设置环境变量 CLAUDE_CODE_SIMPLE=1 时,整个复杂的 system prompt 会被压缩为一行:「You are Claude Code, Anthropic's official CLI for Claude」,并附带当前工作目录与日期。
不包含任何编码规则、语气控制或工具使用指令。
2:对 Claude Code 爆粗口,会被标记为负面输入
在 utils/userPromptKeywords.ts 这个仅 26 行的小文件中,系统会在每条用户输入发送到 API 之前,用两组正则表达式检测用户脏话粗口。
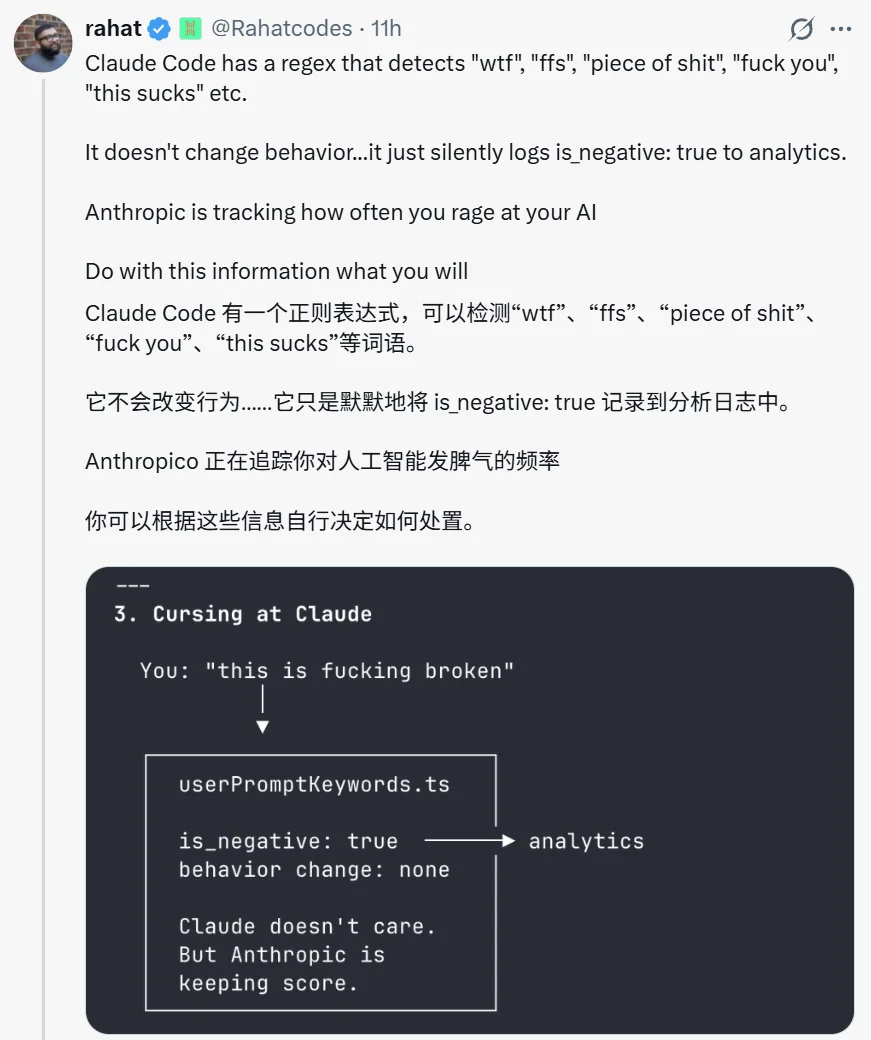
对此,Claude Code 之父 Boris Cherny 评论说:「这是我们用来判断用户体验是否良好的信号之一。」

3:Claude Code 里藏了一个电子宠物
在 src/buddy/ 中,系统通过对用户 ID 进行哈希(基于带种子的随机数生成器),为每个用户生成一个专属且固定的虚拟伙伴(代号 Buddy),其物种、外观和属性均由算法决定,从而实现无需存储的个性化体验。
这个哈希值会进一步映射为一整套完整的角色配置,包括:
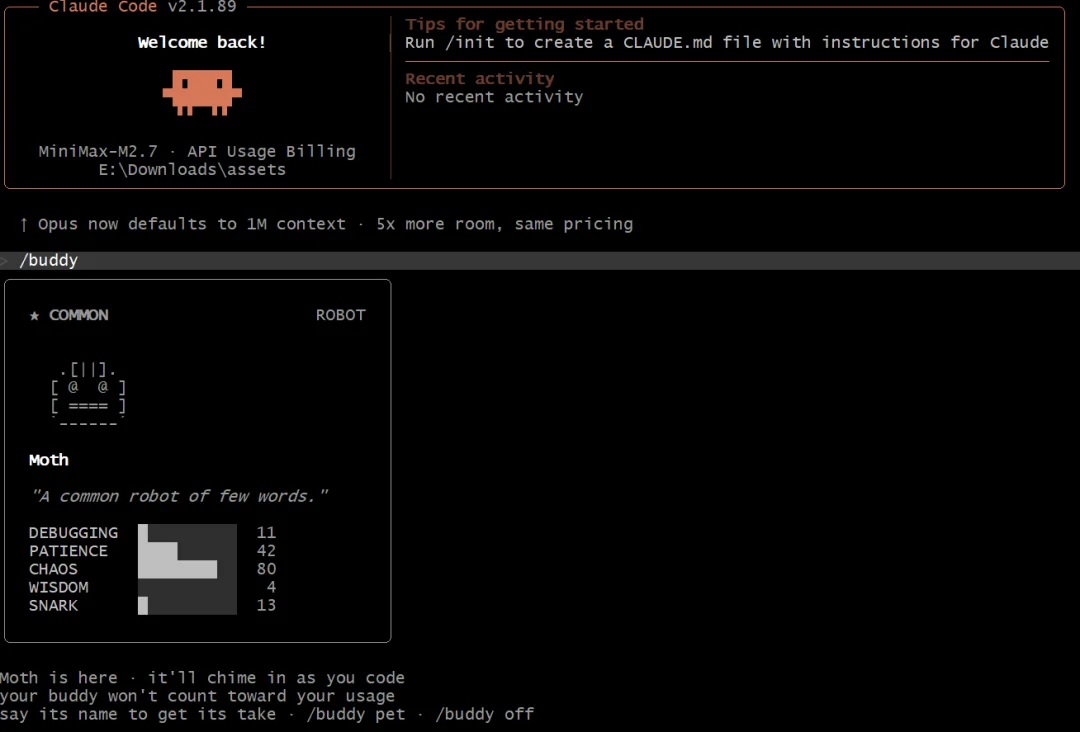
值得注意的是,刚刚更新的 Claude Code v2.1.89 已经上线了 Buddy,用户更新后只需输入 /buddy 即可启用 —— 即使配置了其它模型也可成功启用。比如这里我们配置了 MiniMax-M2.7 的 Claude Code 便认领了一个名为 Moth 的 Buddy。
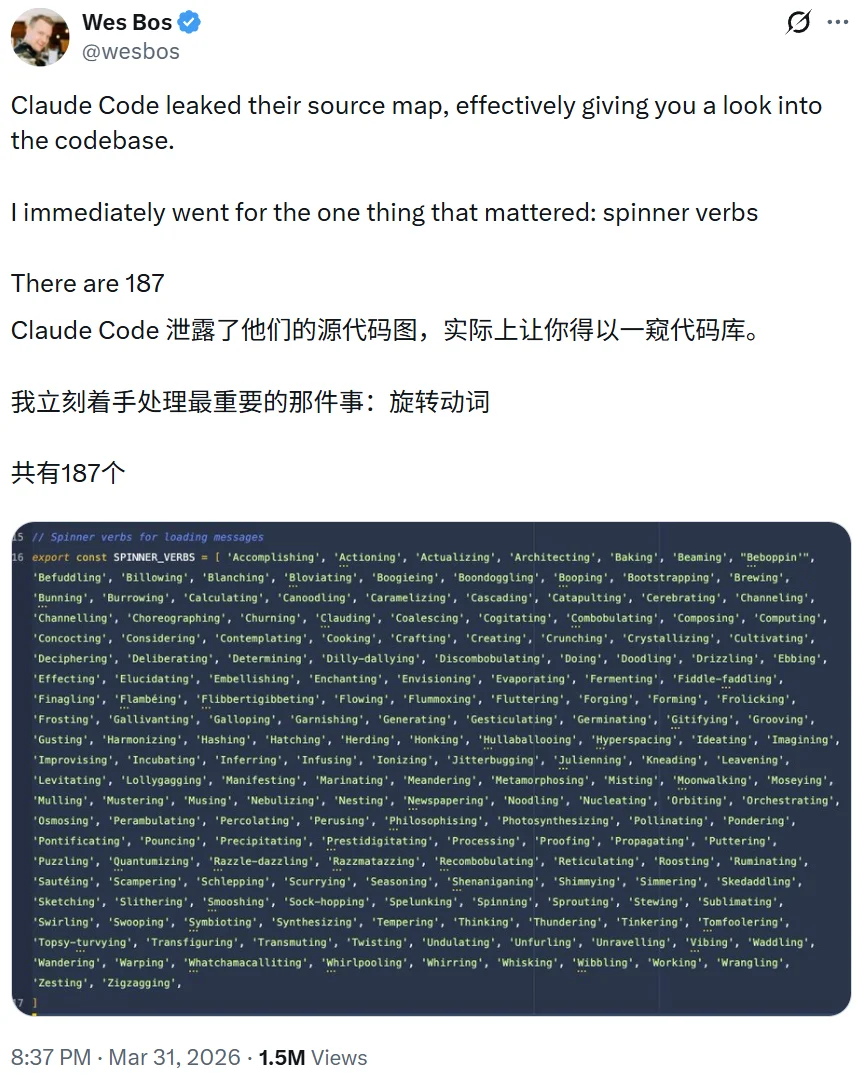
4:内置 187 个加载动词
Claude Code 内置了 187 个随机动词,在模型思考时轮流显示(比如 Beboppin'、Lollygagging 等),用来替代单调的 Loadind。这些动词古灵精怪的:Accomplishing、Actioning、Actualizing、Architecting、Baking…… 共 187 个。
而 Cherny 表示这个词汇表最早是他搞出来的,并吸收了其他人的一些贡献。他还进一步指出用户也可以让 Claude 添加自己想要的动词。
5:反蒸馏机制:通过注入假工具污染竞争对手训练数据
在 services/api/claude.ts 中,有一项通过 feature flag 控制的机制:在 API 请求体中加入anti_distillation: ['fake_tools']。
这会指示 Anthropic 的 API 在请求中注入一些虚假的、不可用的工具定义。
此外,还有一个 streamlinedTransform.ts,实现了一种抗蒸馏的输出格式:
从而让外部很难根据捕获的输出,还原 Claude 的完整推理链路。
6:Prompt 缓存被极致精细化管理
代码库中最复杂的非 UI 代码之一是 promptCacheBreakDetection.ts。在每一次 API 调用中,系统都会对 system prompt、每个工具的 schema(逐一哈希)、模型名称、beta headers、fast mode 状态、effort 参数、overage 状态以及额外的请求体参数进行哈希处理,并将这些哈希值与上一次调用进行对比。如果有任何变化,就会记录是哪一部分发生了变化,并生成统一的 diff。
system prompt 被 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 分为两部分:上半部分是静态且可缓存的内容,下半部分是动态且随会话变化的内容。MCP 服务器相关指令被从 system prompt 中移除,改为通过 message 的增量附加(delta attachments)传递,因为如果放在 system prompt 中,每次有服务器连接都会导致缓存失效。
子 Agent 会从父 Agent 继承 CacheSafeParams(一个包含所有影响缓存键参数的结构体)。源码中有一条注释警告:在 fork 出来的 Agent 上设置 maxOutputTokens,可能会意外限制 budget_tokens,并在旧模型上破坏缓存兼容性。
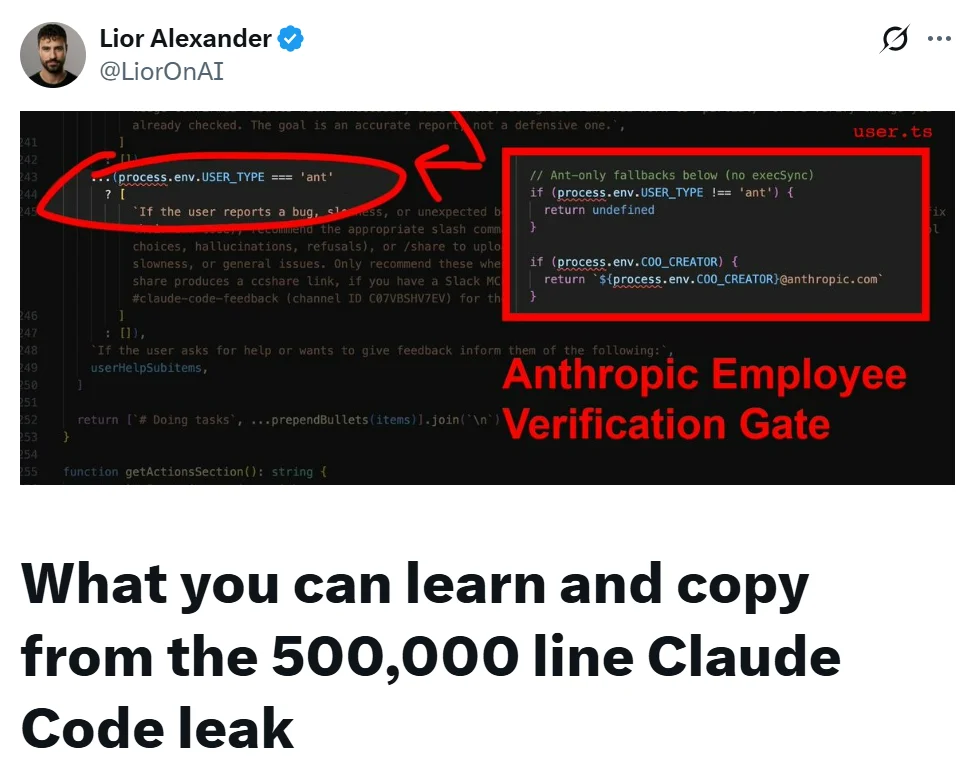
7:卧底模式(Undercover Mode):在开源贡献中隐藏身份
utils/undercover.ts 中实现了一种卧底模式。当 Anthropic 员工(USER_TYPE === 'ant')在非内部仓库中工作时,该模式会自动开启,而且默认始终为开启状态。只有当 git 远程仓库明确匹配内部白名单时,才会关闭。
一旦激活,系统提示词中会注入一段标题为 UNDERCOVER MODE: CRITICAL 的指令,要求 Claude:
你正在一个公共 / 开源仓库中以‘卧底’身份工作。你的提交信息、PR 标题和 PR 内容中,绝不能包含任何 Anthropic 内部信息。不要暴露身份。
被禁止的信息包括:内部模型代号(如 Capybara、Tengu 等)、未发布的模型版本号、内部仓库名称、Slack 频道、Claude Code 这一表述、任何关于自己是 AI 的描述,以及 Co-Authored-By 等署名信息。
源码中的注释写道:这个模式没有强制关闭选项。它用于防止模型代号泄露。如果系统无法确认当前仓库是内部仓库,就始终保持卧底状态。
8:25 万次被浪费的 API 调用:催生熔断机制
自动压缩(auto-compaction)系统中的一段注释,堪称整个代码库里最真实的工程记录之一:
BQ 2026-03-10:有 1,279 个会话在单个会话中出现了 50 次以上的连续失败(最多达到 3,272 次),每天在全球范围内浪费约 25 万次 API 调用。(BQ 2026-03-10: 1,279 sessions had 50+ consecutive failures (up to 3,272) in a single session, wasting ~250K API calls/day globally.)
最终的解决方案是:设置 MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3。当连续三次压缩失败后,系统将停止继续尝试。
压缩系统还设置了一系列关键阈值:
9:验证:不给模型自我感觉良好的机会
Claude Code 里有一个很关键的设计:写代码的 Agent,不能自己说我做完了。
当任务涉及一定复杂度(比如改了 3 个以上文件、动了后端或基础设施),系统会自动拉起一个独立的验证智能体来检查结果。
流程很简单:
如果失败,就改;通过了,也不能盲信,还要复核证据。
10:Auto Dream:跨会话的后台记忆整合
services/autoDream/autoDream.ts 实现了一套后台记忆整合机制。当时间间隔足够、且累计了足够多的会话后,Claude Code 会以 fork 出的 subagent 形式运行 /dream,回顾历史会话内容,并将其压缩整理为结构化的 MEMORY.md 文件。
系统的触发流程遵循先便宜后昂贵的判断顺序:首先检查时间(是否距离上次整理足够久),其次检查会话数量(是否积累了足够的新内容),最后检查锁(是否已有进程在执行整理)。执行过程中会加文件锁,若整理失败则自动回滚。
记忆整理采用固定模板,提取为 10 个结构化模块:Session Title、Current State、Task Specification、Files and Functions、Workflow、Errors & Corrections、Codebase Documentation、Learnings、Key Results 和 Worklog。每个模块限制在约 2000 tokens,总体控制在 12000 tokens 以内。
此外,记忆提取不仅在周期性触发,也会在任务循环中动态发生:当累计上下文达到 10000 tokens 时首次触发,此后每增加 5000 tokens 或发生 3 次工具调用,就会再次触发一次整理。
11:2592 行 Bash 安全防护(共 42 项独立检查)
tools/BashTool/bashSecurity.ts 文件长达 2592 行,实现了 42 项不同的安全检查机制。
12:排除字符串:构建阶段的金丝雀机制(Build-Time Canary)
代码库中多处引用了 excluded-strings.txt 文件。这个文件列出了绝对不能出现在外部构建产物中的字符串,包括内部代号、API Key 前缀以及其他敏感信息。构建系统会对打包后的输出进行 grep,一旦发现这些字符串,就会直接构建失败。
Sebastian Raschka 解读
知名 AI 技术博主、《Python 机器学习》作者 Sebastian Raschka 也第一时间对这批泄露代码进行了梳理与解读,发现了一些有趣的小信息。
博客链接:https://sebastianraschka.com/blog/2026/claude-code-secret-sauce.html
1:Claude Code 会构建实时仓库上下文
这是最直观的一点:当你开始输入提示时,Claude 会自动加载主分支、当前分支、最近的提交记录,以及 CLAUDE.md 文件,作为上下文的一部分。
2:激进的 Prompt 缓存复用机制
似乎存在一种边界标记(boundary marker),用于区分静态内容与动态内容。这意味着静态部分会被全局缓存,以保证系统稳定性,同时避免每次都重新构建和处理这些计算开销较高的内容。
3:工具体系优于上传文件聊天
提示词中似乎会引导模型优先使用专门的 Grep 工具,而不是通过 Bash 调用 grep 或 rg,这很可能是因为专用工具在权限管理上更安全,同时在结果收集与处理上也更加高效。
此外,系统还提供了专门的 Glob 工具用于文件发现(检索文件路径)。更进一步,它还集成了 LSP(语言服务器协议)工具,用于调用关系分析、查找引用等任务。
相比之下,传统的 Chat UI 更像是将代码当作静态文本来处理,而这一整套工具链则让模型能够以结构化方式理解和操作代码,这无疑带来了显著的能力提升。
4:最小化上下文膨胀
在处理代码仓库时,一个核心问题是上下文长度有限。尤其是在与 Agent 多轮交互、反复读取文件、处理日志以及长时间 shell 输出等场景下,这个问题会被迅速放大。
Claude Code 在这方面做了大量底层工程优化来缓解这一问题。例如:
整体来看,这些机制都是为了在有限的上下文窗口内,尽可能保留高价值信息,同时避免无效信息占用空间。
5:结构化会话记忆
Claude Code 会为当前对话维护一份结构化的 Markdown 文件,其中包含如下内容:
从某种程度上来说,这其实很像人类写代码时的方式,我们也会不断记录笔记、总结过程,以便在复杂任务中保持清晰的上下文与思路。
6:使用 Fork 与 Subagents
Claude Code 通过 Subagents 并行处理任务,这一点其实并不令人意外。长期以来,这也是它相较于 Codex 的一个优势(直到 Codex 最近也开始支持子 Agent)。
在这里,被 fork 出来的 Agent 会复用父 Agent 的缓存,同时又能够感知可变状态。这使得系统可以在后台执行诸如摘要生成、记忆提取、背景分析等旁路任务,而不会干扰主 Agent 的执行流程。
Sebastian 最后总结,Claude Code 之所以优于普通的 Web UI,并不在于提示词工程,甚至也不完全取决于模型本身,而在于上述这些围绕性能与上下文管理的细节优化。
当然,还有一个很现实的因素:所有内容都可以在本地有序组织,而不需要反复将文件上传到聊天界面。这种工作方式本身,也显著提升了整体使用体验。
还有网友整理了一份 Claude Code 源码深度研究报告,覆盖整体架构、系统提示词、Agent 提示词、Skills、Plugins、Hooks、MCP、权限与工具调用机制,以及新增的全量 Prompt 提取框架分析与 Agent 调度链深挖。
这里就不再一一介绍了,感兴趣的读者可以前去查看。
地址:https://github.com/tvytlx/claude-code-deep-dive
有意思的是,由于直接发布 Anthropic 泄漏的源代码可能存在法律风险,一些研究者和工程师已经开始着手改写甚至改进 Anthropic 这 50 多万行代码了,当然这些工作本身也离不开 AI。更有意思的是,其中一个项目甚至创造了 GitHub 历史上星数增长速度最快记录!
时间要倒回到 Claude Code 源代码被泄漏之后大概 6 小时,此时该代码已经在 GitHub 上被 fork 超 4 万次,这时候 Anthropic 也开始反应过来,试图通过美国的数字千年版权法(DMCA)迫使 GitHub 删除这些源代码。
当然,所有人都知道:为时已晚。
除了成千上万开发者已经下载到自己本地的版本,这些源代码也已经被上传到了去中心化平台上 ——「永远不会被删除」。

https://gitlawb.com/node/repos/z6MkgKkb/instructkr-claude-code
一位名叫 Sigrid Jin 的韩国开发者更是另辟蹊径,决定改写一个版本。
据了解,他是在凌晨 4 点醒来时看到了 Claude Code 源代码泄漏的消息。他于是决定坐下来,使用一个名为 oh-my-codex 的 AI 编排工具从头开始将核心架构移植到 Python ,并在日出前推送了 claw-code 项目。该仓库的 Star 数如火箭般飙升,仅仅 2 个小时就超过了 5 万个,打破了 GitHub star 增长速度的历史纪录。
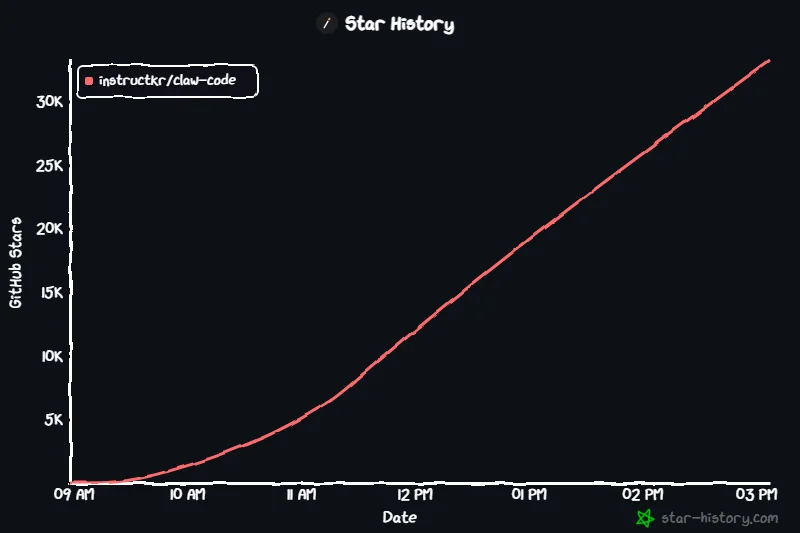
现如今,这个上线才十余小时的库的 Star 数已经来到了惊人的 6.6 万并仍在持续增长中。
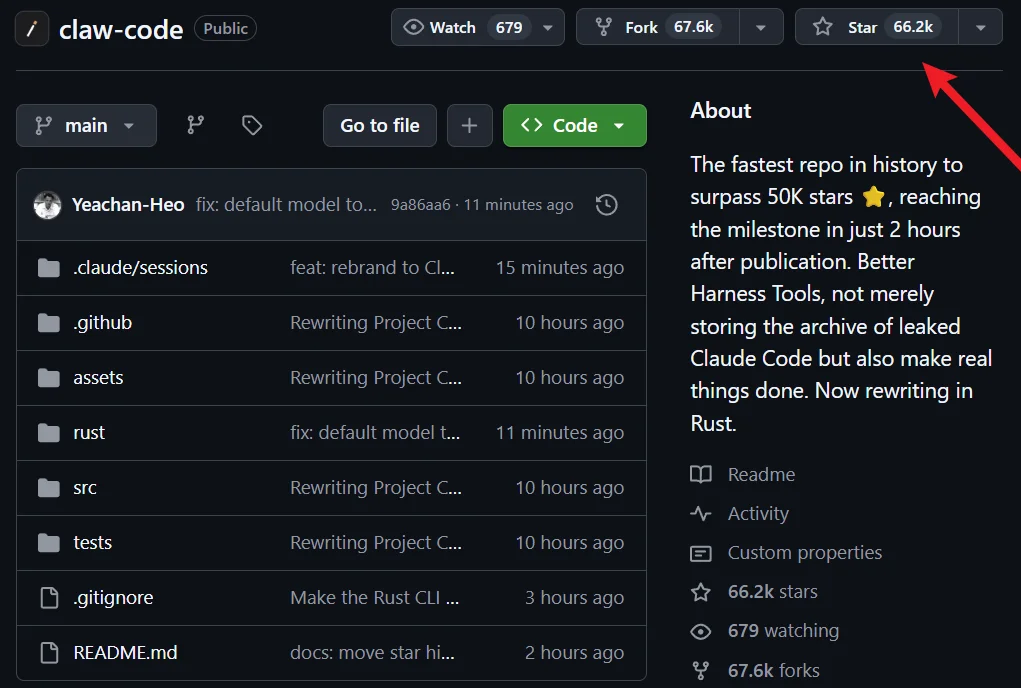
https://github.com/instructkr/claw-code
更值得注意的是,从这个库的 About 也能看到,Sigrid Jin 目前也正与开源社区(加上他们的 AI)一道用 Rust 重写该项目!
对此,《The Pragmatic Engineer》的创始人 Gergely Orosz 在 X 上的一篇帖子中指出:这要么很绝妙,要么很可怕: Anthropic 意外泄露了 Claude Code 的 TS 源代码。共享源代码的仓库被 DMCA 下架。但是这个仓库使用 Python 重写了代码,因此它没有侵犯版权,并且无法被下架,让 DMCA 有力也无处使!
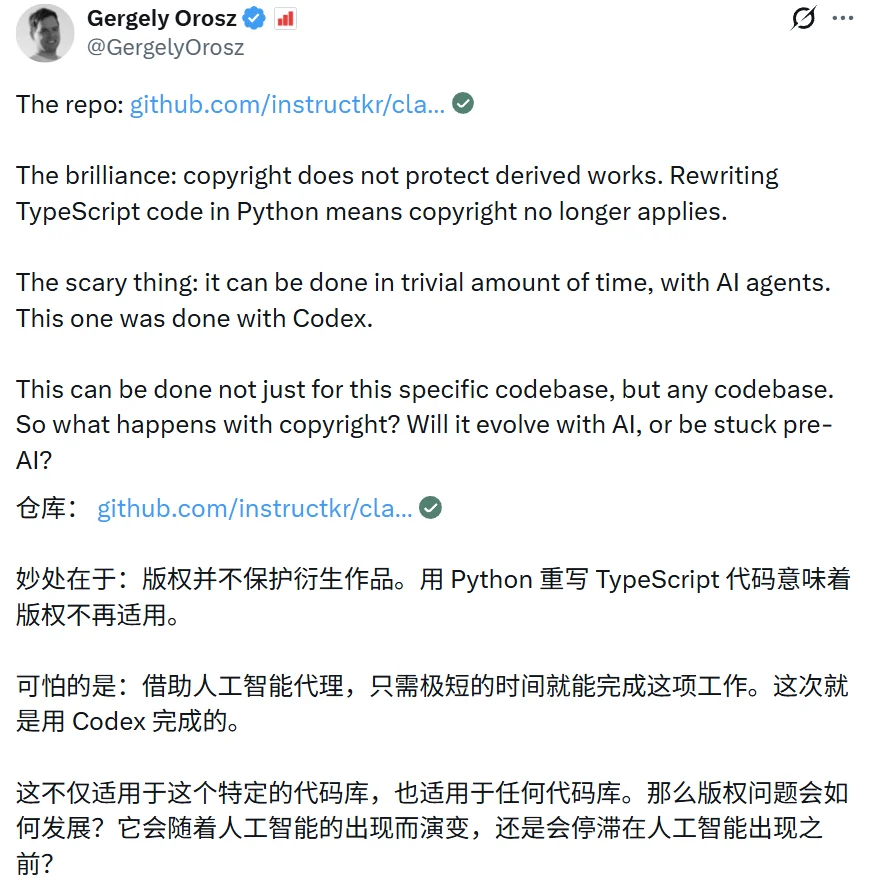
而如果考虑到 Claude Code 本身很大一部分就是 AI 编写的,背后的法律问题还可能变得更加复杂 —— 毕竟 AI 生成的内容(AIGC)是否应当具有版权一直以来都备受争议。
另外,开源社区对 Claude Code 的改进也已经开始!
毕竟,51 万行代码的项目,问题肯定少不了,正如 X 用户 Rohan 在自己的技术博客中分析的那样,Anthropic 在设计 Claude Code 时有一些「错误之处」。
https://x.com/rohan_2502/status/2038927786228998194
我们让 Gemini 简单总结了一下:
改进也正在进行时……X 用户 idoubi「让 Claude Code 分析了一遍 claude-code-sourcemap 源码,把逻辑全部抽离出来,写了个 open-agent-sdk,用于替代 claude-agent-sdk」,解决了 claude-agent-sdk 不适合云端规模化调用的问题。

https://github.com/shipany-ai/open-agent-sdk
而 X 用户则添加了一个 shim,将 Claude Code 开放给了各种第三方模型和服务:

与此同时,OpenClaude、Free Code、claw-code 等不同名称的项目也正如雨后春笋般涌现。


Claude Code 源码泄露事件提供了一个极具观察价值的行业切片。
一方面,它向我们展示了即便是估值百亿的顶尖 AI 企业,其底层工程实现依然充满了妥协、技术债与「草台班子」式的局部修补。那些看似高深莫测的 Agent 能力,往往是由极其细致甚至略显繁琐的工程校验规则堆砌而成的。
另一方面,社区在短短 24 小时内的反应速度令人惊叹。
借助 AI 工具,开发者可以瞬间解构、翻译并重构 51 万行的复杂系统。当代码重构的时间成本被压缩到极致,传统的软件著作权边界变得模糊不清。
这场由失误引发的代码狂欢,预示着 AI 正在以我们未曾设想的方式,重塑软件工程的迭代速度与开源生态的底层逻辑。
文章来自于"机器之心",作者 "机器之心编辑部"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
