# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在具身智能的感知拼图中,触觉一直扮演着不可或缺却难以被完美量化的角色。它提供了视觉等远程传感器无法替代的关于接触几何、材料特性和交互动态的直接反馈。
随着大语言模型(LLM)、世界动作模型(WAM)和视觉 - 语言 - 动作(VLA)大模型的爆发,将触觉与视觉、语言相融合,以弥合物理交互与高级语义推理之间的鸿沟,已成为机器人领域的必然趋势。
本文由香港科技大学(广州)熊辉教授团队牵头,联合灵心巧手(LinkerBot)以及西安交通大学、复旦大学、北京邮电大学、南京大学等,以《Tactile-based Multimodal Fusion in Embodied Intelligence: A Survey of Vision, Language, and Contact-Driven Paradigms》为主题,全面梳理并分析截至 2026 年第一季度的前沿研究,提出了一个涵盖多模态数据集、模型方法、传感器硬件和评估体系的层次分类法。本文将带你全面拆解这篇重磅综述的核心干货。

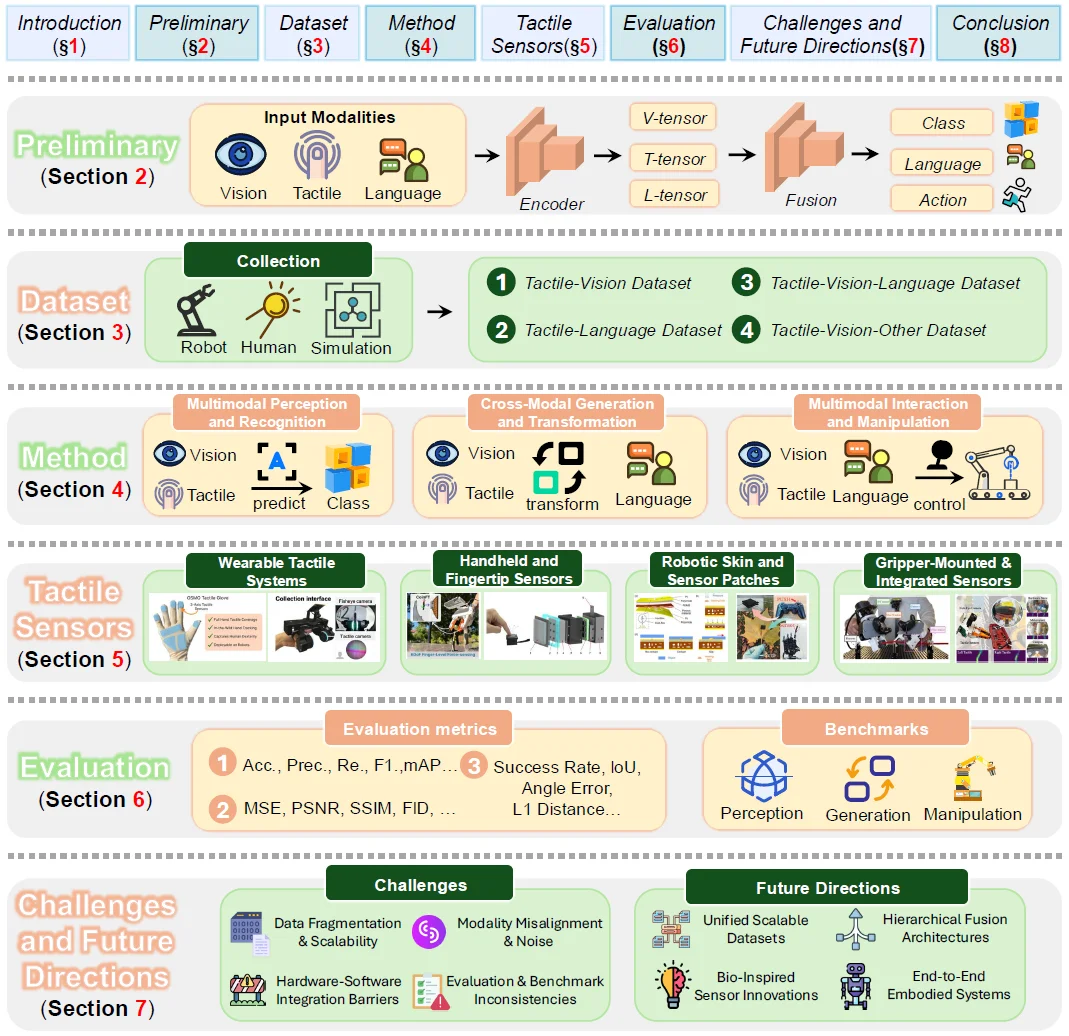
图 1. 多模态触觉融合综述的结构概述
与视觉等远端模态不同,触觉提供了表面纹理、材料属性和接触动态的直接、近端反馈,这对于解决视觉模糊性至关重要。对于具身智能体而言,触觉反馈不仅仅是一种辅助模态,更是感知 - 行动闭环中的基本组成部分,触觉作为连接被动观察与主动物理交互的桥梁,能够提供关于物体几何形状、材质属性以及接触动力学最直接的反馈,这是远距离传感器无法替代的。在充满物理接触的环境中,这种多传感器线索的协同作用(尤其是视觉与触觉的协同),是构建稳健的感知和控制系统、使智能体能够真正在物理世界中进行精确操作和稳定抓取的关键。
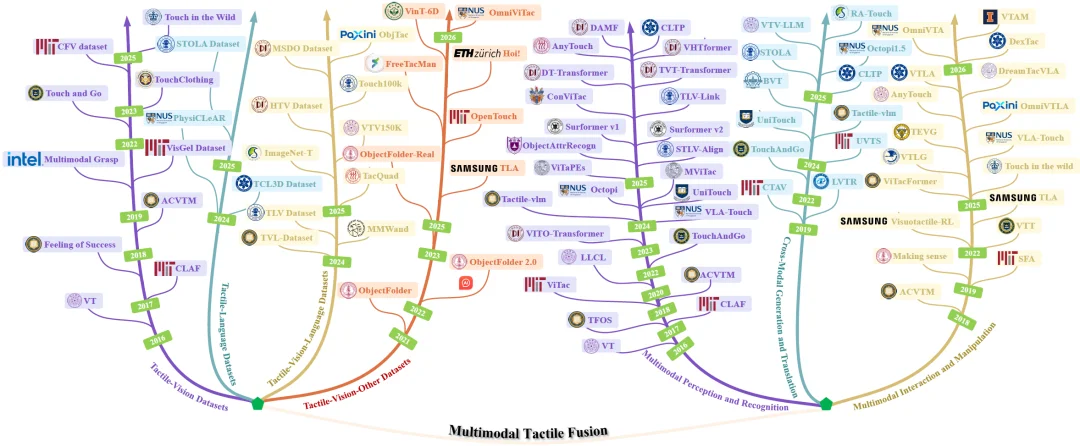
图 2. 多模态触觉融合的代表性数据集和方法综述
与视觉或语言不同,触觉信号是接触驱动的,只有在物理交互发生时才会产生。综述指出,现有的多模态触觉融合系统在底层基本都遵循一个严谨的四阶段处理流程:
本综述创新性地提出了一个层次化分类体系,将多模态触觉融合系统地划分为三大支柱:多模态数据集、多模态方法和触觉传感器。
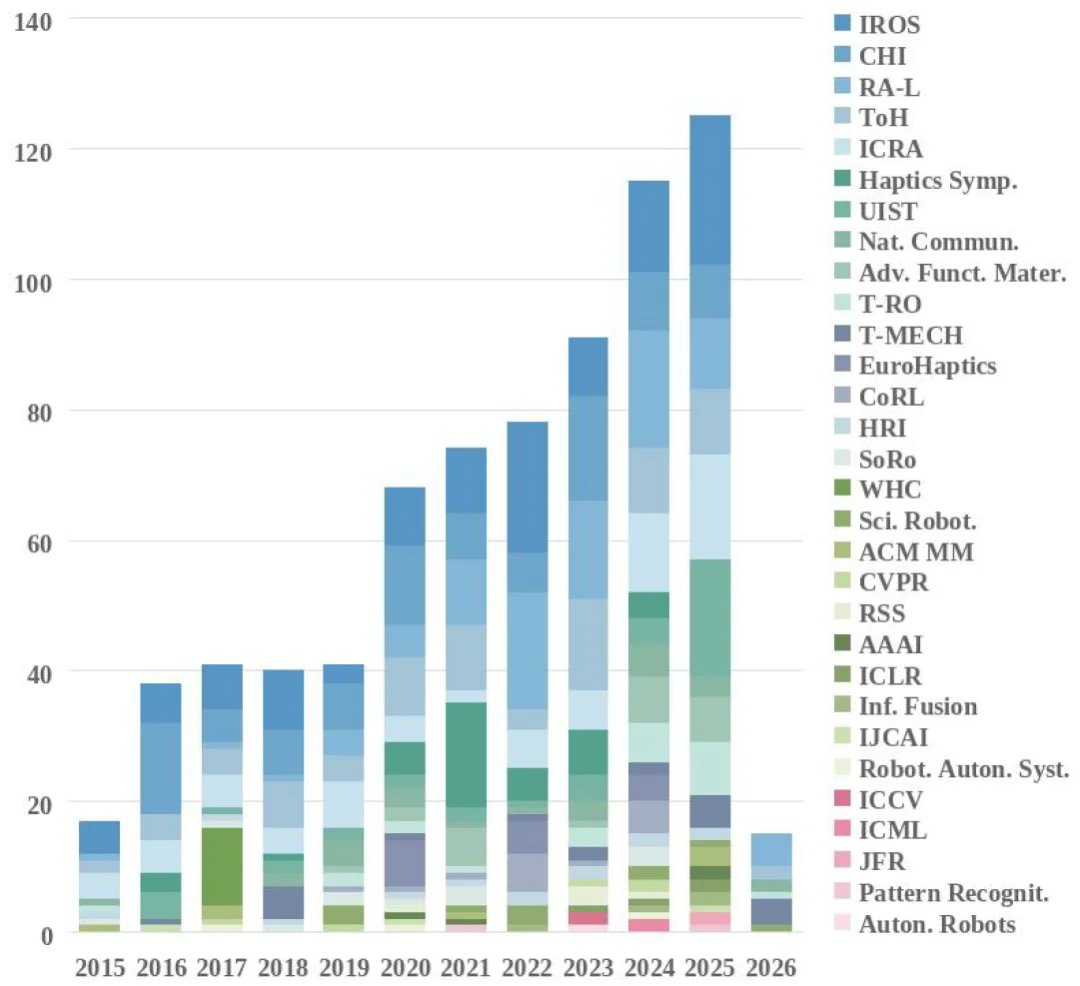
图 3. 2015 - 2026 年多模态触觉融合论文发表趋势。
1. 数据集篇:从实验室单一配对走向真实世界的丰富语义
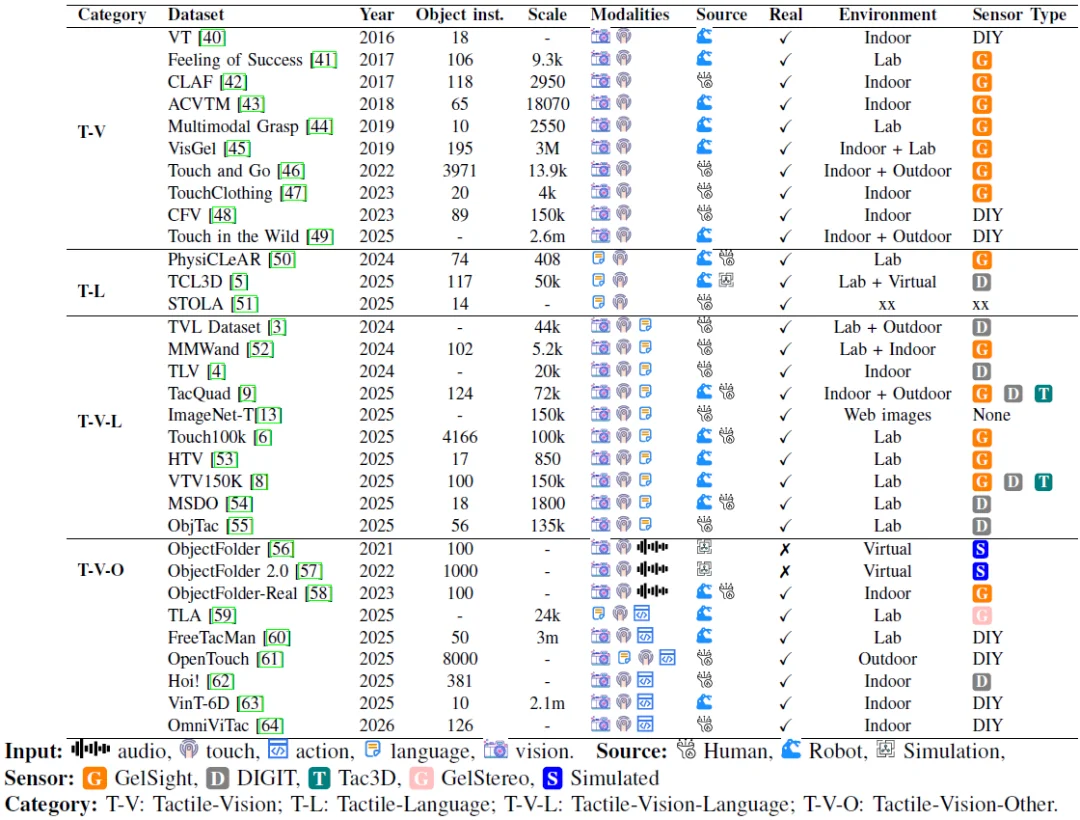
图 4. 基于触觉的多模态融合数据集的比较总结
数据集是跨模态学习的 “燃料”。文章根据模态组成,将现有数据集的发展脉络划分为四大阶段:
2. 方法论的三大范式:感知、生成与控制的全面进化
在算法层面,综述将数百篇前沿工作结构化为三个核心方向,并对其进行了详细的子任务拆解:
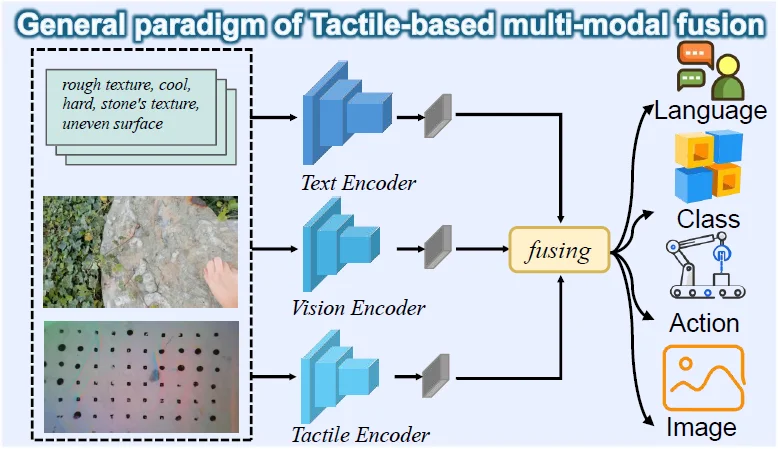
图 5. 多模态触觉融合与下游任务的一般范例
(1)多模态感知与识别
这是目前研究最广泛的范式,核心在于理解,具体包括四个子任务:

图 6. 多模态感知和识别的分类,包括多模态物体识别、多模态属性和材质识别、抓取成功或失败预测以及跨模态检索和匹配
(2)跨模态生成与转换
不再局限于识别,而是让模型拥有跨感官的合成能力:
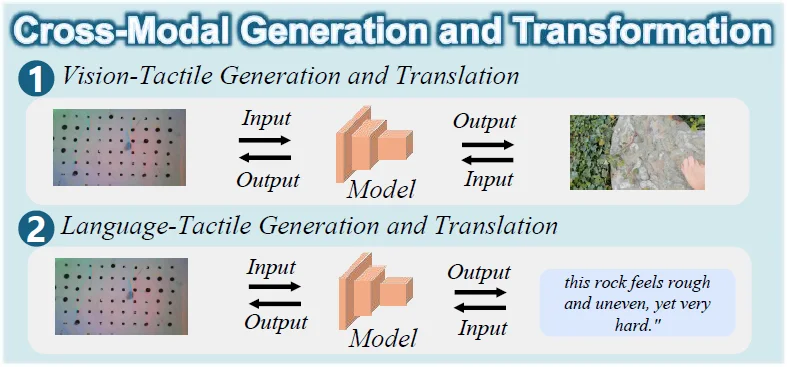
图 7. 多模态跨模态生成和转换的分类,包括视觉 - 触觉生成和翻译和语言 - 触觉生成和翻译
(3)多模态交互与操作
将感知直接与物理控制耦合,分为两大路径:
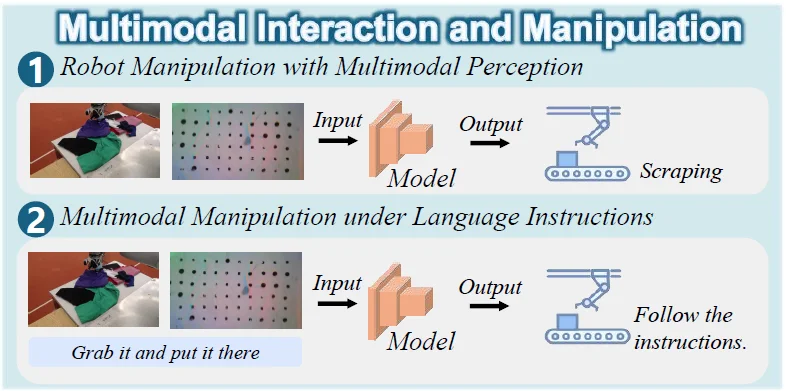
图 8. 多模态交互和操作的分类,包括具有多模态感知的机器人操作和语言指令下的多模态操作
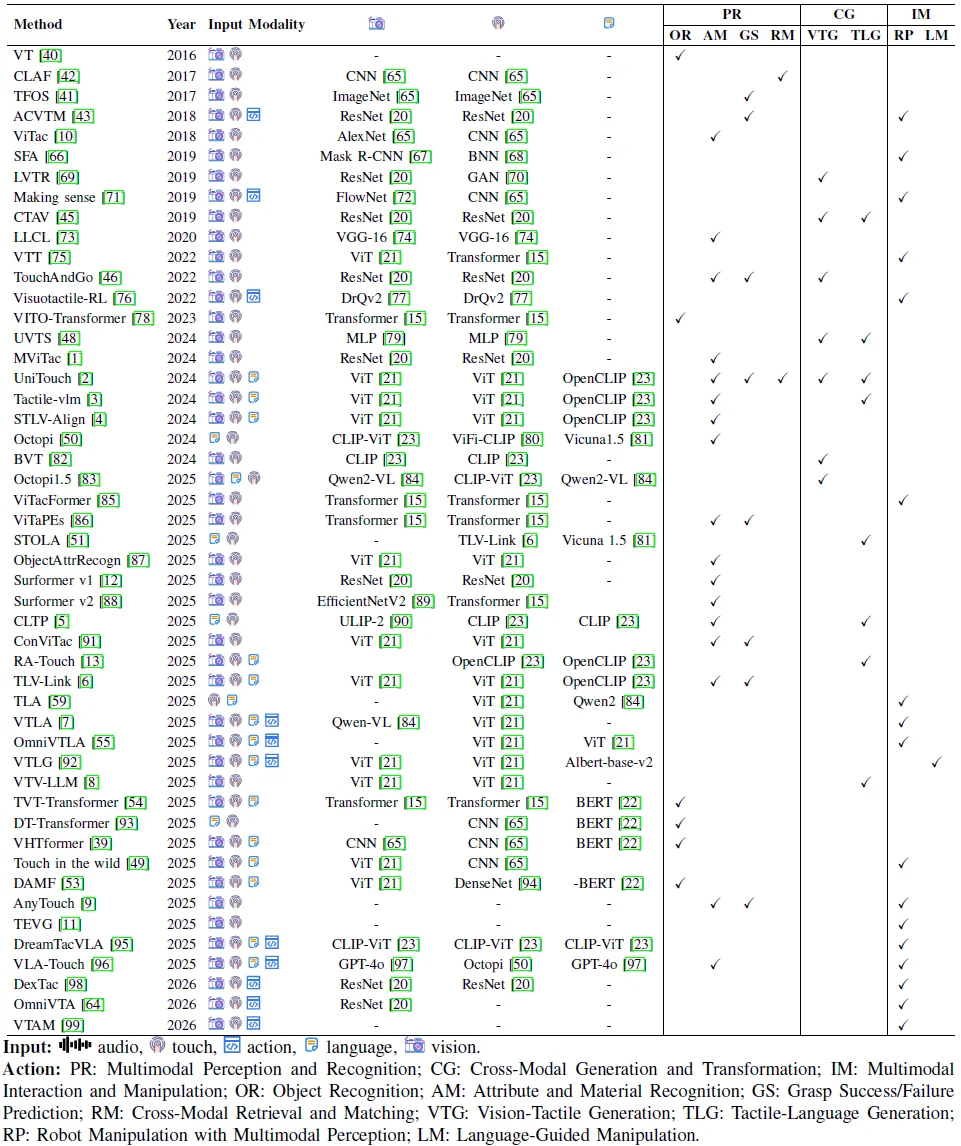
图 9. 2026 年第一季度之前发表的多模态触觉融合方法综述
3. 硬件篇:触觉传感器的多样化形态
触觉信号的质量直接受制于硬件设计与物理交互界面的形态。文章将触觉传感平台分为四类:

图 10. 具有代表性的触觉传感器
尽管发展迅速,但多模态触觉融合仍缺乏统一的基准,现有的评估协议高度依赖于特定任务。文章尖锐地指出了当前领域面临的四大核心挑战:
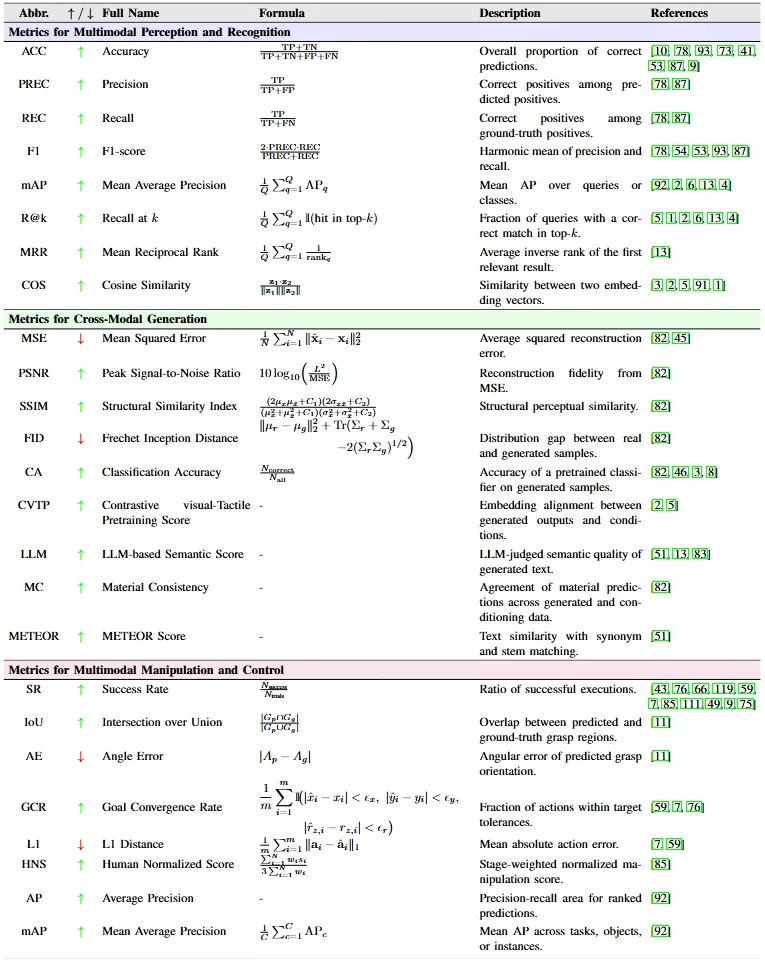
图 11. 多模态触觉融合评价指标综述
尽管进展迅速,多模态触觉融合仍面临着诸多亟待突破的瓶颈。目前的数据规模与大型语言模型的训练需求相比仍有巨大差距,且异构传感器之间缺乏统一的数据标准。同时在非结构化环境中,稀疏的触觉输入与密集的视觉或语言信息之间经常出现空间和时间上的不对齐。此外现有的评估指标往往局限于特定任务,缺乏一个能全面衡量触觉真实性、语义一致性和控制有效性的统一端到端基准测试。
对于未来,构建统一且可扩展的大规模数据集是打破发展瓶颈的关键所在。算法层面需要向层次化的融合架构演进,将触觉作为多模态推理的底层支撑。在硬件端,柔性、耐用且具备端侧处理能力的仿生触觉皮肤将极大拓展机器人的感知边界。通过将触觉反馈作为连续的监督信号直接嵌入决策闭环,具身智能系统必将从受控的实验室环境稳步迈向复杂多变的人类生活空间。
文章来自于"机器之心",作者 "机器之心"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
