# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
RL之后,大模型为什么更容易「越训越单一」?面对五花八门的改进思路,也许答案并不复杂:先试着改一改KL项。
近年来,基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Reward, RLVR)已成为提升大语言模型推理能力的重要路径。
从数学求解到代码生成,再到SQL推断,大量研究表明,RL能显著提升模型在单次作答场景下的成功率。
然而,一个关键现象始终未得到充分解释:为什么许多经过RL微调的模型,虽然 Pass@1提升了,但在允许多次尝试时,Pass@k反而下降了?
这表明,模型或许更擅长「押中一次正确答案」,却丧失了原本丰富的解题路径与候选解空间。更进一步,这种现象往往伴随着灾难性遗忘(Catastrophic Forgetting)和跨领域泛化能力的下降。
现有方法通常将注意力集中于奖励设计、采样策略或熵调控,但研究团队发现,一个更基础、更关键的问题长期被忽视:RL目标中的divergence项,究竟应如何选择?
针对这一问题,复旦大学、无限光年、上海科学智能研究院(下称上智院)、上海创智学院的联合研究团队聚焦于长期被忽视的KL散度项,从divergence选择的角度破解这一难题。相关研究成果已被ICLR2026接收。

论文标题:The Choice of Divergence: A Neglected Key to Mitigating Diversity Collapse in Reinforcement Learning with Verifiable Reward
论文链接:https://arxiv.org/abs/2509.07430
代码链接:https://github.com/seamoke/DPH-RL
复旦大学博士生、无限光年实习生李龙,复旦大学及上海创智学院博士生周潪剑,为共同一作。复旦大学研究员、上海科学智能研究院AI科学家屈超,为通讯作者。
在大多数RL后训练方法中,常见做法是采用reverse-KL,或直接移除 divergence 约束。然而,这两种选择均存在明显缺陷:
这两种设定都会导致模型日益集中于少量「熟悉答案」,进而引发Pass@k下降、既有能力遗忘以及跨任务泛化能力减弱。若以更形式化的方式表述,传统 RLVR 可概括为:
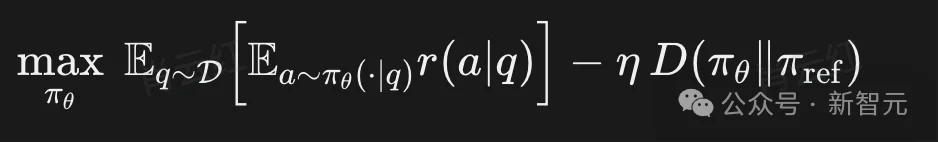
其中,πθ为当前策略,πref为参考策略(通常为初始模型或SFT模型)。问题的关键在于:若此处的divergence选择不当,后半部分将不再是「保护机制」,反而会沦为「多样性压缩器」。
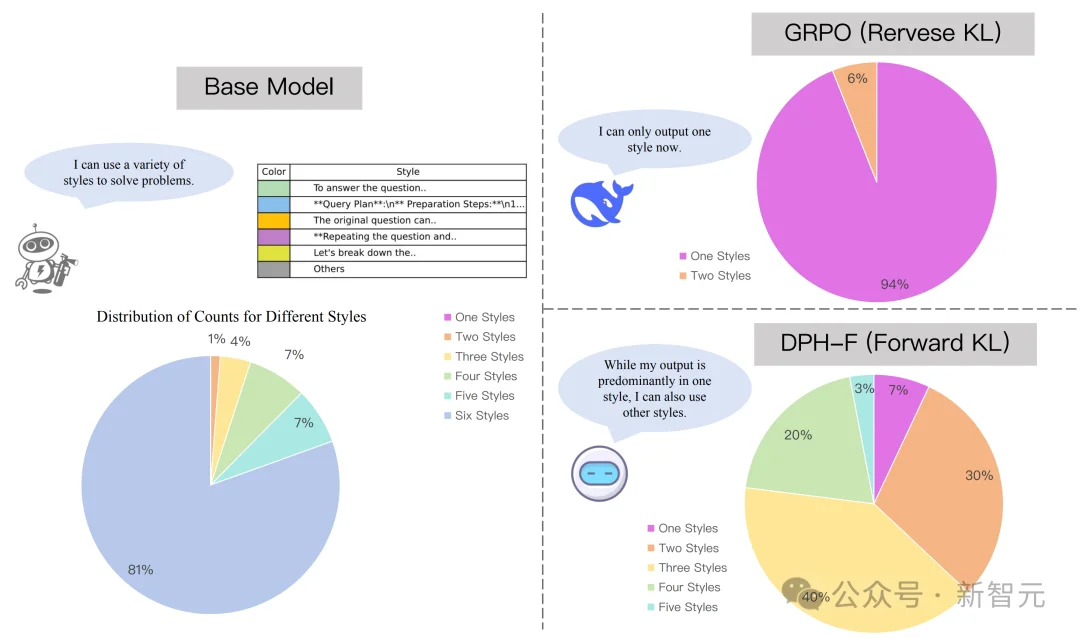
若将基础模型视为已掌握大量知识与多样解法的「知识分布」,那么RL微调的目标本应是在保留既有能力的前提下进一步提升任务表现。
然而现实中,许多RL方法更像是在不断强化少数高回报轨迹——模型逐渐偏向一两种最易获得奖励的解法,而舍弃了原本同样有效但出现频率较低的其他路径。
研究团队进行了一项有趣的实验:通过SFT让模型学习到多种不同风格的回答方式,仅凭前缀即可判断模型采用了哪种风格;然而经过标准GRPO训练后,模型几乎只保留了一种风格。
因此,研究团队认为,RLVR中真正需要解决的,不仅是「如何学得更强」,更包括:如何在优化奖励的同时,保全模型原本拥有的多样性。
基于上述观察,团队提出了DPH-RL(Diversity-Preserving Hybrid RL)。这项工作的核心思想是:
divergence不应仅是训练时的附带正则项,而应被重新设计为主动保护模型多样性的机制。


与倾向于收缩至单一模式的reverse-KL不同,这类divergence会鼓励新策略继续覆盖参考策略中原本存在的多种解法。换言之,它并非强迫模型「只记住最优路径」,而是在提醒模型:「你可以继续变强,但不要忘记原本掌握的东西。」
从机制上看,该研究的方法可理解为一种rehearsal mechanism(复现机制):模型在训练过程中持续参考初始策略的分布,从而保留原有的知识覆盖范围,避免在强化学习过程中发生过度收缩。
以提到的forward-KL为例:
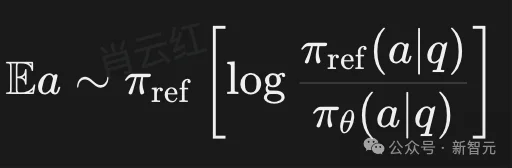
此处的期望是对参考策略πref取的。只要参考策略曾覆盖过某些合理解法,新策略πθ便不能轻易将其概率压至接近零。正因如此,forward-KL更具mass-covering倾向,更适合作为「保多样性」的工具。

此外,DPH-RL在实现上也更为高效。作者采用基于generator function的方式计算f-divergence,仅需从初始πref预采样,无需在训练过程中维护在线reference model。
这使得方法在训练成本上更加友好,更适合实际大规模后训练场景。在具体训练时,DPH-RL 并非对所有样本「一刀切」地施加同一种约束,而是先将数据划分为两部分:
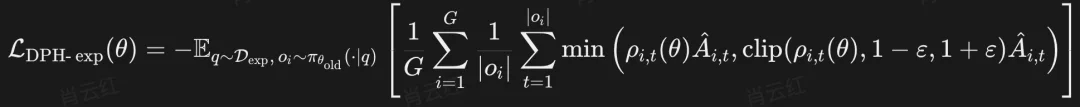
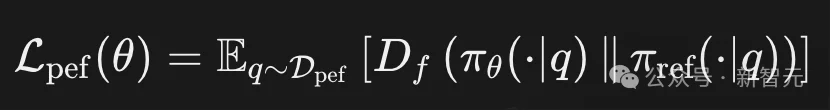
因此,整体训练过程更适合表述为「分情况计算」的形式:
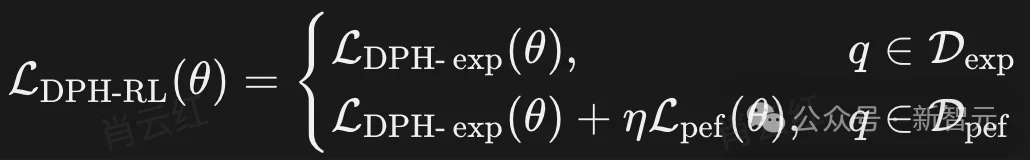
换言之,并非对每个样本同时叠加「探索项 + 保持项」,而是先判断样本属于Dexp还是Dpef,再计算对应的loss。
实验设置
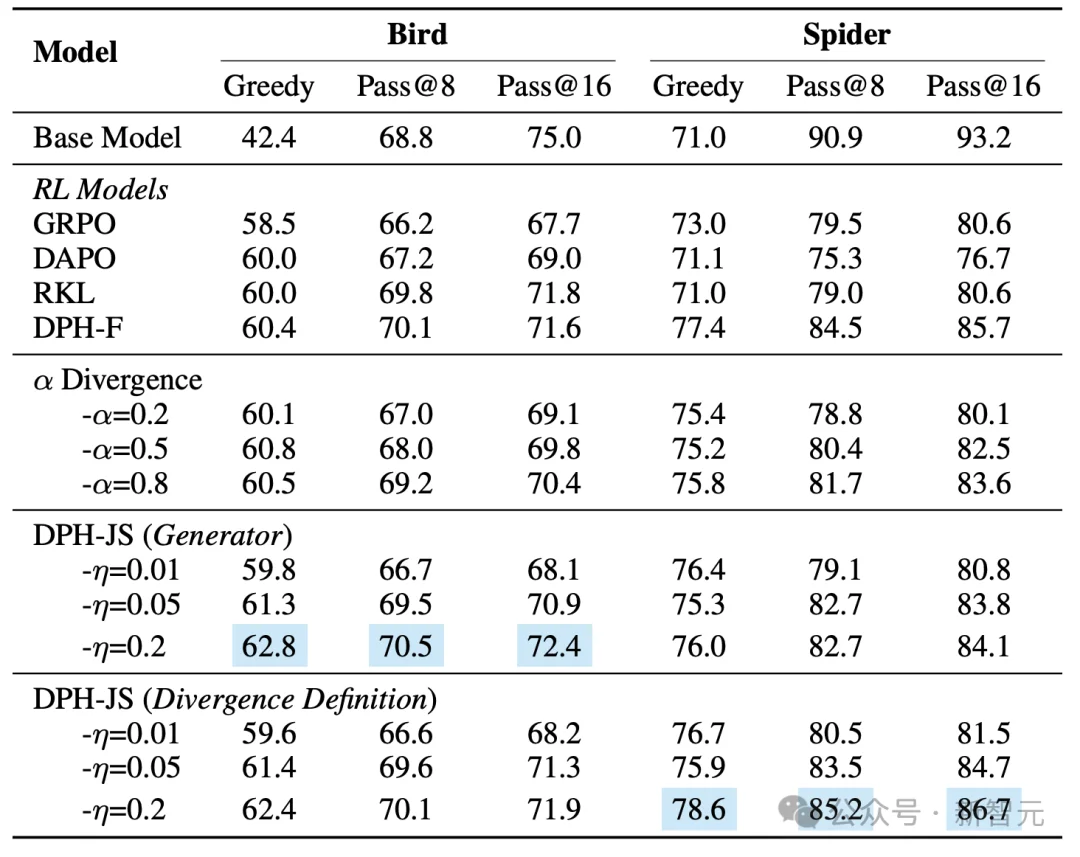
In-Domain性能:Pass@k的恢复
在BIRD数据集上,结果清晰表明:
Greedy(相当于Pass@1)表现,但其Pass@8和Pass@16分数均显著低于Base Model,证实了多样性坍塌的存在;Pass@k出现下降;Greedy分数最高,其Pass@8分数也超越了Base Model。其中,DPH-JS的Pass@8分数较GRPO高出4.3%。在更大的k设置下,DPH-RL更接近base model,缓解了Pass@k的崩塌。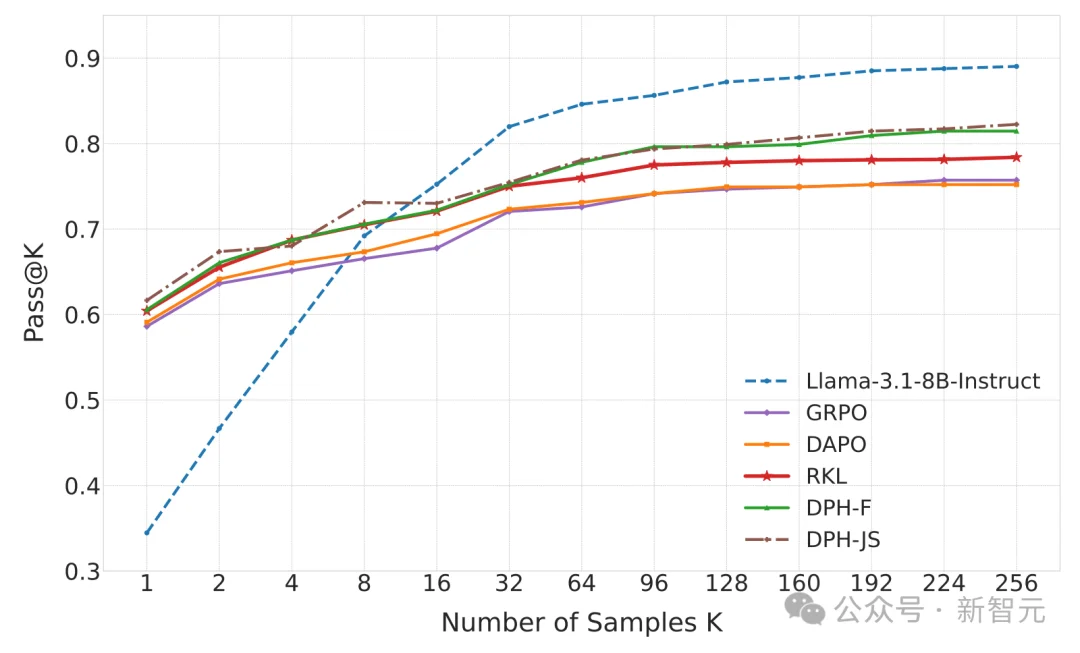
Cross-Domain与OOD性能:
泛化能力的保持
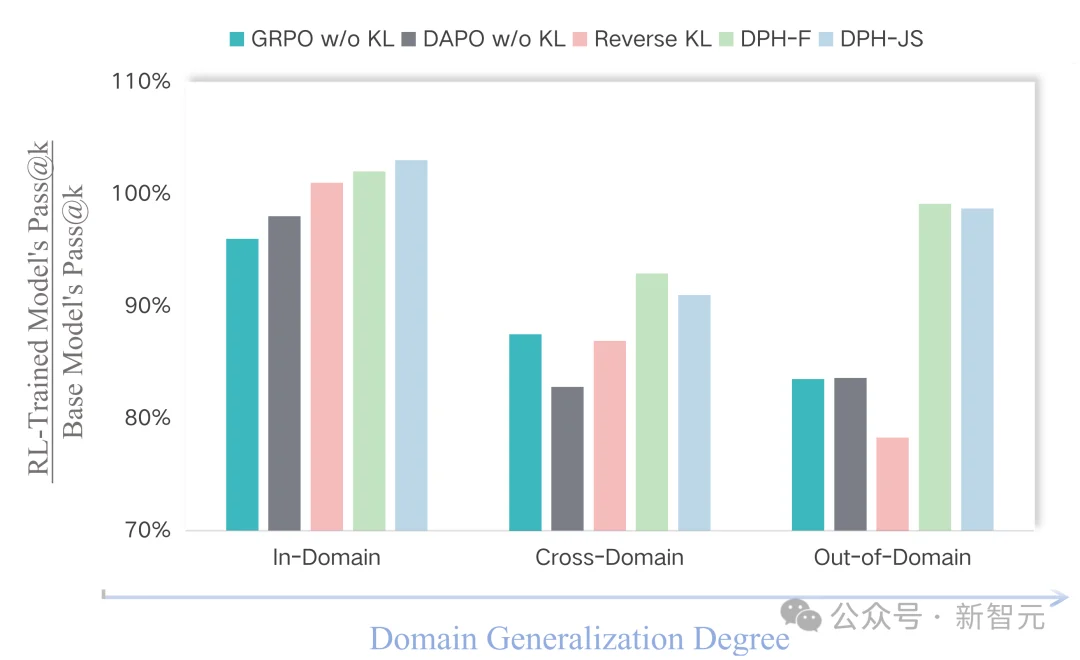
我们将SQL任务上的Spider数据集视为cross-domain,将数学数据集视为out-of-domain。可以看到,所有仅在SQL数据集Bird上训练得到的RL模型,在分布发生偏移时都会出现不同程度的性能下降。
正如图中所示,随着任务与训练分布的差异逐步增大,Pass@k整体呈现明显下降趋势,这也是OOD场景中的普遍挑战。
不过,更值得关注的是各方法的相对表现:
Pass@k分数显著高于其他所有RL方法,最接近Base Model的原始水平;Pass@16分数较DAPO高出9.0%;这表明,通过保留解决方案的多样性,DPH-RL能够更有效地防止灾难性遗忘,从而在面对新领域问题时保持更强的泛化能力。
保留 (Keep)与探索 (Exploration)的显式平衡
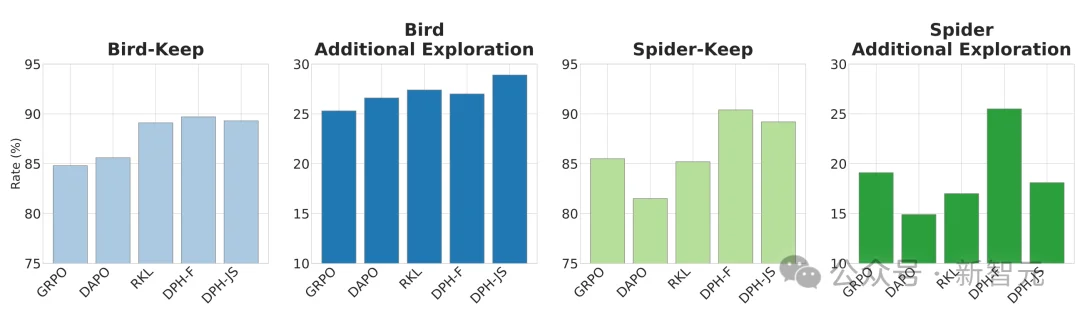
为了揭示DPH-RL的核心机制,论文通过解构模型在Pass@8上的表现,分析了 RL 微调前后的知识动态:
实验结果揭示了DPH-RL与GRPO之间的核心区别:
由此可见,DPH-RL通过对强化学习组件的功能解耦,实现了保留与探索的显式平衡。它证明了在通过 RL 提升模型能力上限的同时,稳固已有的知识底座是取得最终胜出的关键。
本文系统分析了RLVR中普遍存在的diversity collapse现象,指出常用的reverse-KL 及无divergence设定均缺乏有效的知识保留机制。
为此,作者提出DPH-RL,将mass-covering f-divergence作为保护模型多样性与缓解遗忘的核心工具。
实验表明,DPH-RL不仅能缓解Pass@k下降问题,还可同时提升Pass@1 ,并在跨域任务上展现出更优的稳定性与泛化能力。更重要的是,这一结果启示我们:在RL后训练时代,保住多样性与提高奖励同等重要。
文章来自于"新智元",作者 "YHluck"。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
