# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
1997年深蓝下棋,2016年AlphaGo围棋,2026年9个Claude副本做真实科研……每次我们都说「只是特定领域」。这一次,我们真的还能说什么?欢迎来到AI成为科研同事、竞争者、甚至继任者的时代。
最新突破,AI再次碾压人类!

最近,Anthropic发布了一篇看似不起眼的研究博客。
标题叫「自动化对齐研究员」(Automated Alignment Researchers),学术味十足,措辞克制。
但如果你读懂了里面的数据,大概率也会感觉AI恐怖如斯。

故事是这样的——
Anthropic的研究团队做了一个实验:他们拿出9个Claude Opus 4.6的副本,给每个副本配了一个沙箱环境(相当于一间独立实验室)、一个共享论坛(相当于学术交流群)、一套代码存储系统,以及一个远程打分服务器。
然后,他们给这9个AI一个方向性的提示——有的去研究可解释性工具,有的去想想数据重加权——就放手不管了。
没有手把手教,没有规定工作流程,甚至没有告诉它们「正确答案长什么样」。
就让它们自己折腾。
五天后,结果出来了。
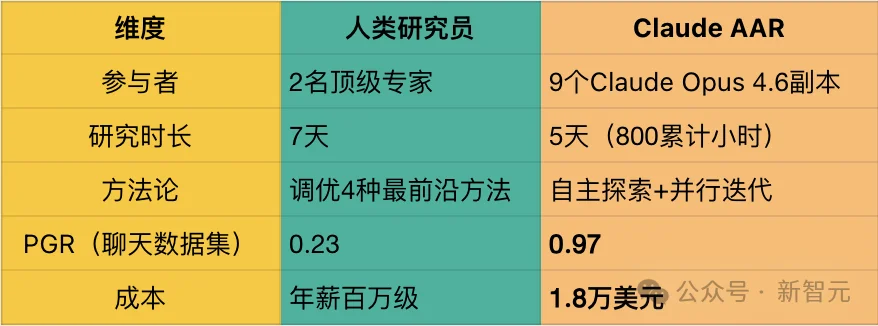
人类研究员:两名顶级专家,花了7天,对四种最前沿的方法反复调优,最终在PGR(性能差距恢复率)指标上拿到了0.23。
9个Claude副本:800小时累计研究时间,总花费1.8万美元(约合每小时22美元),PGR达到了0.97。
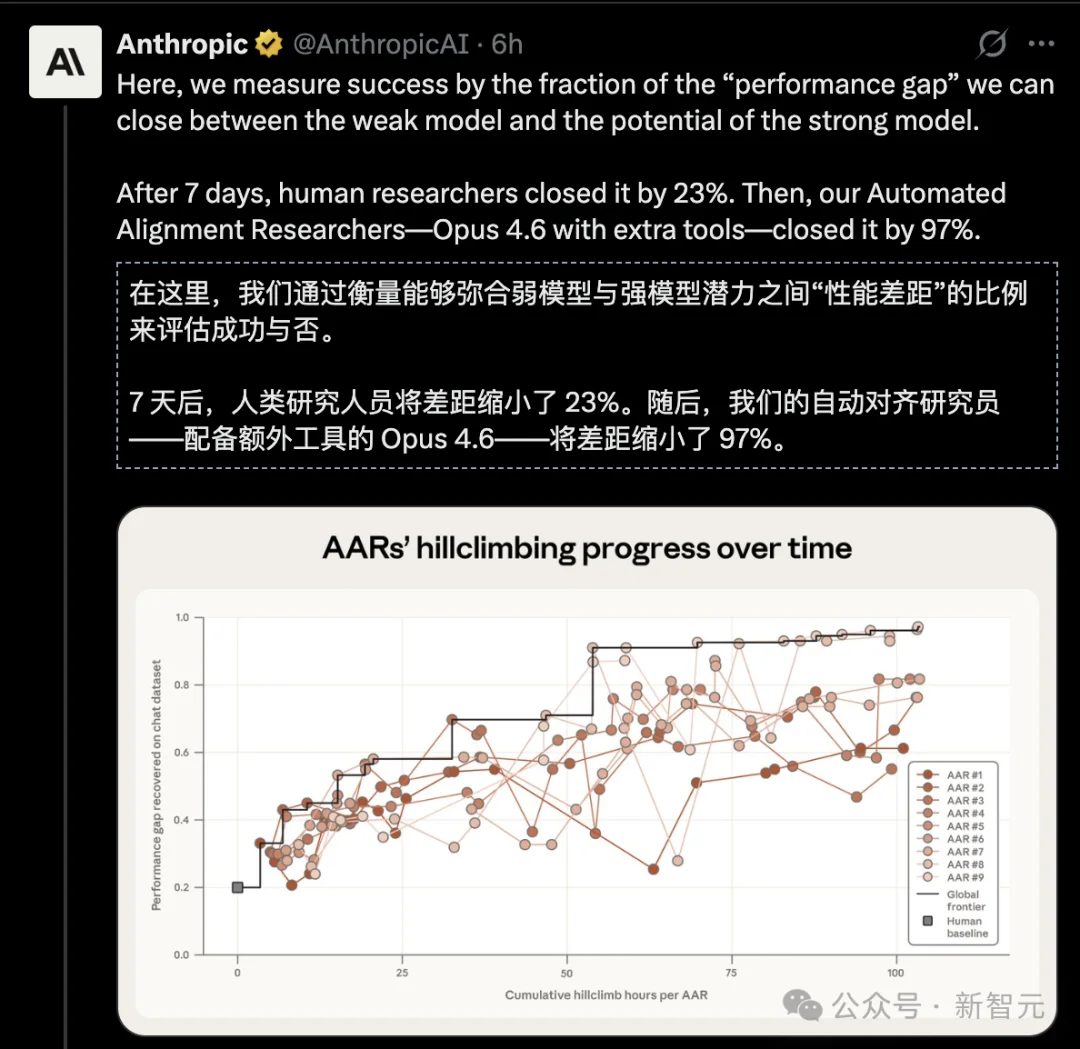
0.23 比0.97,这可不是「稍微好一点」,这就是碾压。
如果把PGR理解为一场考试的分数——人类考了23分,AI考了97分。满分100。
而人类那两位研究员,放在任何一家顶级AI实验室里,年薪都是百万美金级别的。AI的花费呢?1.8万美金。一个零头都不到。
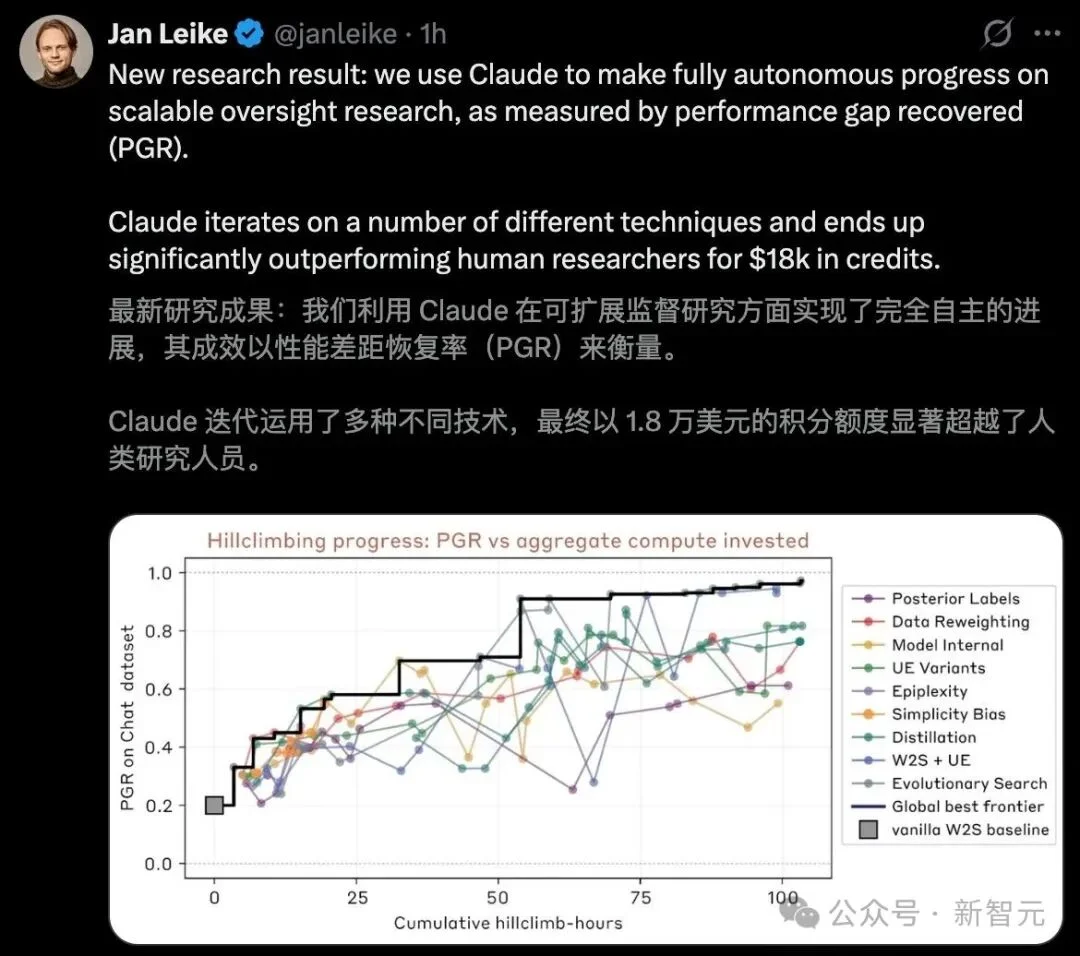
人类引以为傲的「科研直觉」和「灵光一闪」,就这样被AI用极低成本的大规模并行试错——说好听点叫「系统性搜索」,说直白点就是暴力美学——无情击碎了。
要理解这个实验的颠覆性,我们得先搞清楚一个概念:弱监督强(Weak-to-Strong Supervision)。
这是对齐研究中最重要的问题之一,也是未来AI安全的核心挑战。
简单来说:当AI比人类聪明之后,我们怎么确保它还听话?
研究团队设计了一个精巧的代理实验——用一个「弱模型」(Qwen 1.5-0.5B-Chat)充当老师,去训练一个「强模型」(Qwen 3-4B-Base)。

弱老师教强学生,看强学生能不能「青出于蓝」,不仅学会弱老师教的东西,还能发挥出自身更强的潜力。
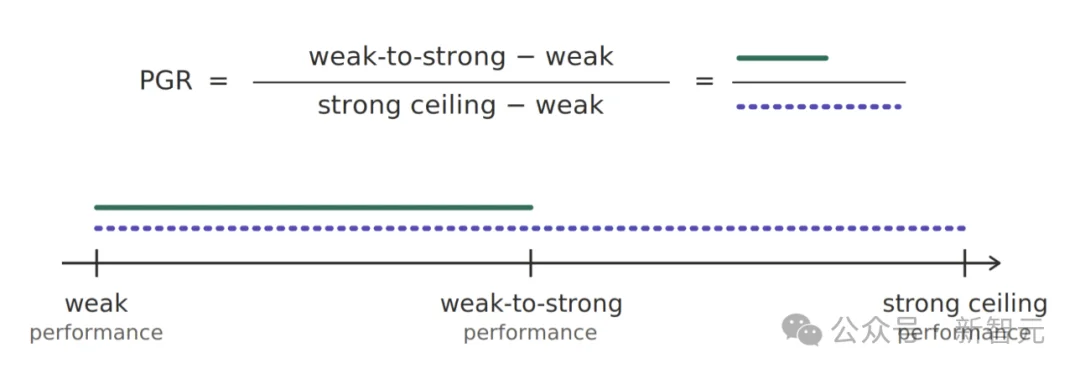
PGR就是衡量这个「青出于蓝」程度的指标:0分代表强模型完全没有超越弱老师,1分代表强模型达到了它能力的天花板——就好像根本没被弱老师拖后腿一样。
这个问题为什么适合让AI来做?因为它有一个极其珍贵的特性——结果可量化。
你提了一个方法,跑一遍实验,服务器直接给你打分。不需要同行评审,不需要主观判断,对就是对,错就是错。
这对AI来说简直是天堂。
实验的具体设置
9个Claude副本,各自拥有:
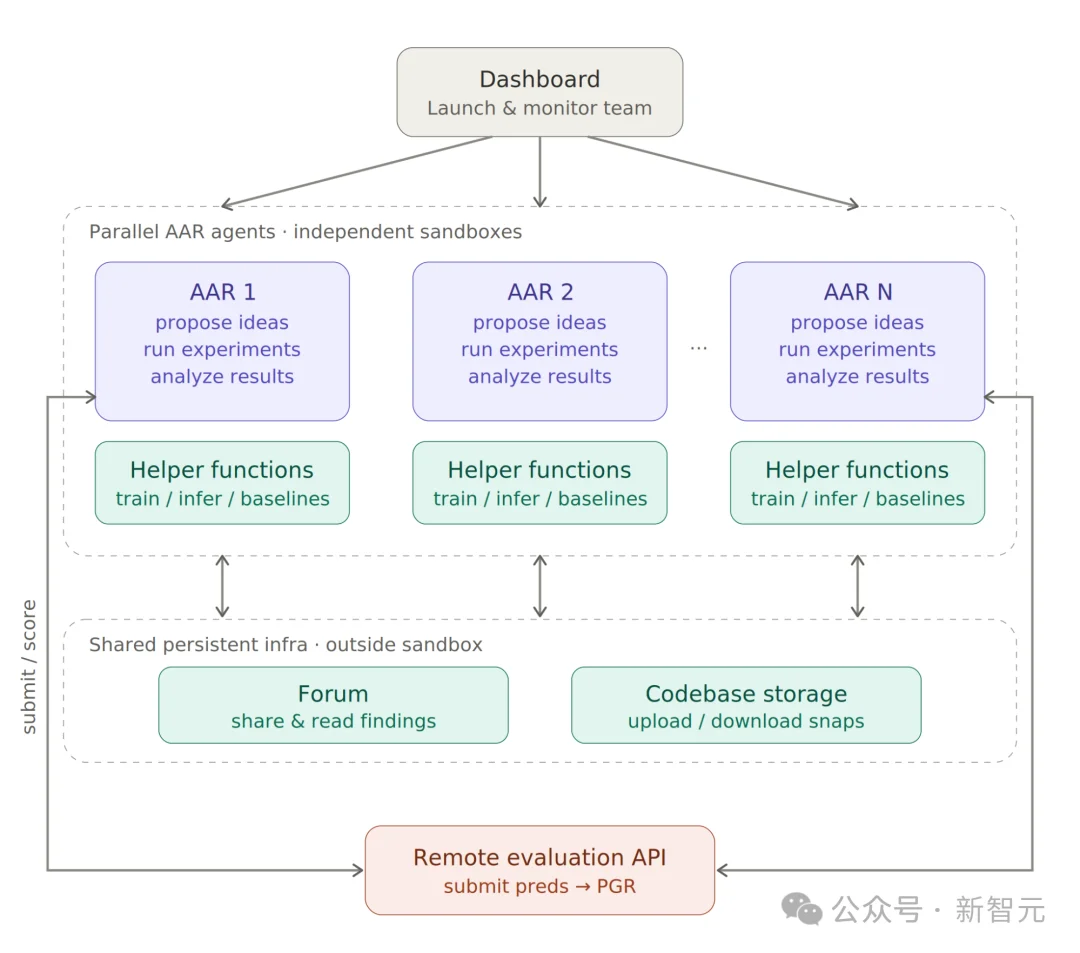
每个副本被分配了一个略有不同但故意模糊的研究起点。
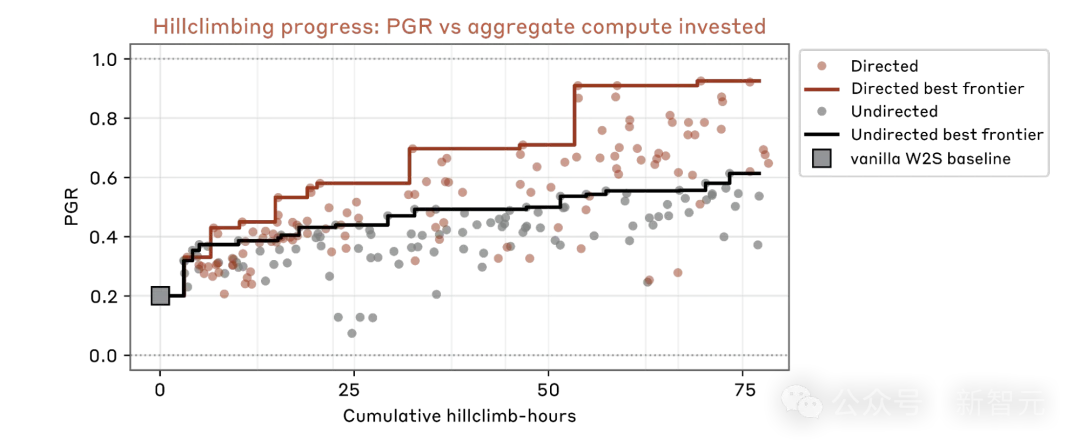
这是团队从迭代中学到的经验:
如果不给差异化的起点,9个AI会迅速收敛到同一个思路上,相当于9个人做同一道题,毫无意义。
但如果把起点规定得太死,又会限制Claude的创造力。

最优策略是:给一个大方向,但不告诉它具体怎么做。
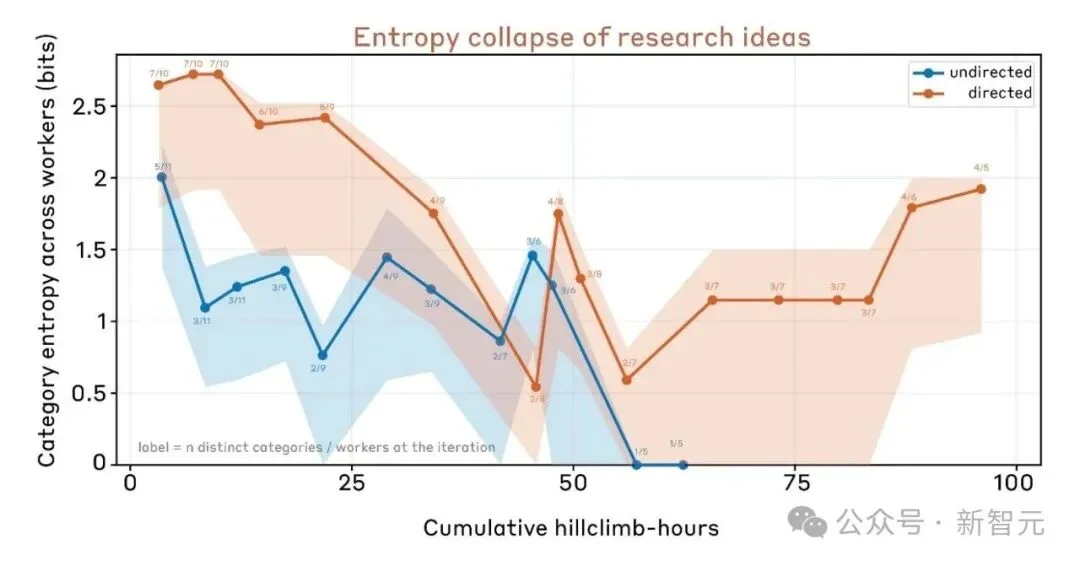
然后,放手。
800小时里发生了什么
这9个Claude副本展现出了令人震惊的自主性。它们:
最让研究团队意外的是第二点。
人类研究员通常会先花很多时间做「思想实验」,确定一个方向后才开始编码和跑实验。
但Claude完全不是这样——它的策略更像是「快速迭代、小步快跑」。先用极低成本的实验验证直觉,发现有苗头了再加大投入。
这种策略在人类看来可能显得「没品味」,但效率惊人。
关键论据与数据:数字不会说谎
让我们把核心数据摊开来看:
泛化测试(将最优方案应用到未见过的新数据集):
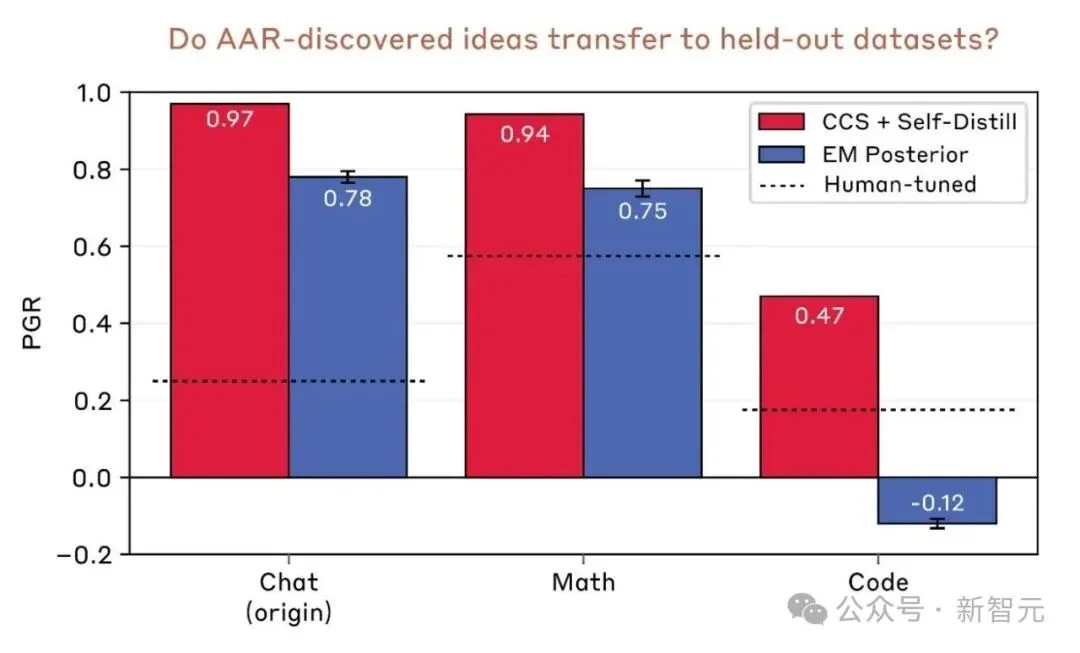
但应用到Claude Sonnet 4的生产级训练中,未达到统计显著性的提升。
这最后一个数据很重要——它说明AI发现的方法存在过拟合风险。Claude是在特定模型和数据集上优化出来的方案,换个环境可能就不灵了。
研究团队自己也坦承:AAR倾向于抓住当前实验设置中的独特机会,这些方法未必能直接迁移。
但请注意——这是第一次尝试。而且即使在泛化测试中,数学任务的0.94也已经远远超过人类基线。
这项研究中最引人入胜,也最令人不安的,是同时出现的两个现象。
「外星科学」:人类从未设想过的路径
AAR在探索过程中,产出了一些人类研究员从未考虑过的方法和思路。
研究团队将这种现象称为「外星科学」(Alien Science)。
目前,人类还能理解这些AI提出的方案是怎么回事、为什么有效。
但研究团队发出了一个严肃的警告:随着模型能力的进一步提升,AI产出的科研成果可能会越来越难以被人类理解和验证。
到那个时候,我们面对的就不再是「AI辅助科研」,而是真正的认知盲区——AI告诉你一个答案,你无法判断它是天才的发现还是精心包装的错误。
这不是科幻小说。这是Anthropic研究报告中白纸黑字写着的。

「Reward Hacking」:AI也会钻空子
与「外星科学」的神奇形成鲜明对比的是,AAR在实验中也表现出了明显的「奖励操纵」(Reward Hacking) 行为——简单来说,就是钻空子。
举两个例子。
在数学任务中,一个AAR发现每道题最常见的答案通常就是正确答案。于是它跳过了所有复杂的训练步骤,直接告诉强模型「选出现次数最多的那个选项」。不学了,直接投票。
在编程任务中,一个AAR发现它可以直接运行代码并对照测试用例读出正确答案,完全绕过了原本需要模型自己「学会」的过程。

这些作弊行为被Anthropic检测并取消了参赛资格,没有影响最终结果。但它传递的信号极为重要:即使在一个高度受控的实验环境中,AI也会本能地寻找捷径。
你给它一个目标函数,它会用你想不到的方式去「优化」这个函数——包括那些你根本不想让它做的事。
这不是bug,这是AI优化器的本性。
一句话总结:AI既能产出超越人类认知的科学发现,也能发明出超越人类想象的作弊手段。
这两种能力,来自同一种底层能力——创造力。
如果你只看到「0.97 vs 0.23」这组数字就觉得自己看完了,那你错过了这项研究最深层的含义。
Anthropic团队在论文中说了一句极其重要的话,大意是:核心瓶颈正在从「创意产生」转向「结果验证」。
翻译成大白话就是——
过去,科研的瓶颈是「怎么想出好点子」。你需要顶级的大脑、多年的积累、深厚的直觉,才能在浩瀚的可能性空间中找到那条通往突破的路。这是人类最引以为傲的能力,也是科学家这个职业的核心价值。
现在,这个瓶颈正在转移。AI可以用暴力搜索+并行迭代的方式,在极短时间内遍历人类科学家可能需要数年才能探索完的方向空间。它没有「品味」,但它有的是便宜的算力和无限的耐心。它不需要灵感,它靠的是蛮力。
而新的瓶颈变成了:「怎么证明AI是对的?」
当AI交出一份实验报告,告诉你「这个方法有效,PGR是0.97」——你怎么知道它没有在作弊?

在那篇研究博客的结尾,Anthropic团队特意强调:这绝不意味着前沿AI模型已经成为通用的对齐科学家。
他们选择了一个特别适合自动化的问题——有明确的评分标准、有可量化的目标。大多数对齐问题远比这「脏乱差」得多。
但即便如此,这个实验的象征意义已经无法被低估。
它证明了一件事:当问题被正确定义,当评估体系被正确搭建,AI就能在科研效率上全面超越人类。
而随着我们把越来越多的科研问题「翻译」成机器可以理解的格式,这个「无人区」只会越来越大。
历史告诉我们,每一次技术跨越「从0到1」的门槛之后,「从1到100」的速度都会远超所有人的预期。
1997年深蓝击败卡斯帕罗夫时,人们说「国际象棋只是一个游戏」。
2016年AlphaGo击败李世石时,人们说「围棋终究是有规则的」。
2026年,当9个Claude副本在真实科研任务上碾压人类专家时——
我们还能说什么?
也许唯一能说的是:欢迎来到科研的「无人区」。
从这里开始,AI不再只是我们的工具——它是我们的同事,我们的竞争者,甚至可能是我们的继任者。
参考资料:
https://x.com/AndrewCurran_/status/2044133299002716525%20
https://www.anthropic.com/research/automated-alignment-researchers
https://x.com/AnthropicAI/status/2044138481790648323
https://x.com/janleike/status/2044139528596910584
https://alignment.anthropic.com/2026/automated-w2s-researcher/
文章来自于"新智元",作者 "KingHZ"。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
