# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2026年初,当大多数企业还在用数据分析师手动写SQL查表时,OpenAI内部曝光的能自主思考、推理甚至自我进化的数据分析智能体,将数据查询从「天数级」缩短至「分钟级」。
为什么数据团队总在「踩同一个坑」?
答案往往不是算力不够多,而是表太多、定义太多、经验散落太多:
同样叫「活跃用户」,不同表的口径可能完全不一样;即便选对表,也要写出上百行 SQL 才能跑出结果,错一个连接条件就前功尽弃。
在内部,OpenAI做了一件更激进的事:让 Codex 驱动的数据智能体接管「找表—懂表—写SQL—校验结果」这条链路,用一套六层上下文架构,把数据语义补齐、把组织知识接入、把经验记忆沉淀,让工程师用提问取代搬砖。

「我们有大量结构相似的表,我花费大量时间试图弄清楚它们之间的区别以及该使用哪个。」一位OpenAI工程师的日常抱怨,道出了数据工作者的共同困境。
OpenAI内部数据平台的600PB数据,分布在7万个数据集中,想象一下:当OpenAI的工程师需要分析ChatGPT用户增长时,面对数十个相似的用户表,每个表都声称记录「用户活跃度」,但定义却各不相同。
选错表意味着数天的努力付诸东流,更糟糕的是可能基于错误数据做出关键决策。
更令人头疼的是,即使选对了表格,生成正确结果也充满挑战。
下图中展示的一个180多行的SQL语句,像一座难以逾越的大山——复杂的表连接、聚合操作,任何一个细微错误都可能导致整个分析失效。

而现在有了由 Codex 驱动,具有自主学习能力的智能体,工程师不必写上百行的SQL查询语句,只需要提问就能从数据海洋中找到所需的信息,例如下图查询中要求对比两个时间点的活跃用户数。
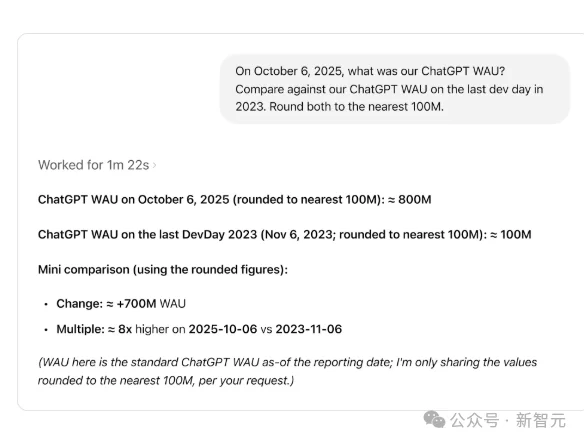
将自然语言变成SQL语句,这样的工具很多,而OpenAI内部使用的数据智能体,其核心创新在于其多层上下文架构。
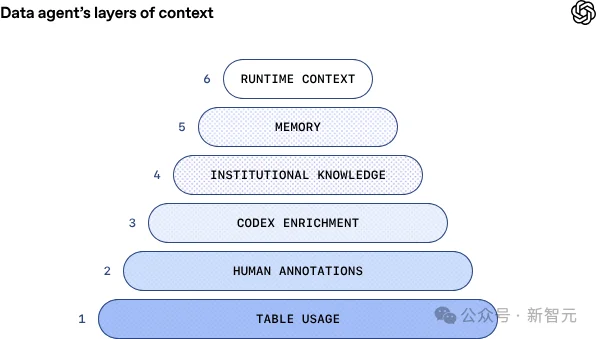
最底层的基础元数据包括表结构、列类型等基础信息,为智能体提供数据图谱的骨架。
在其一层是人工标注,是由领域专家精心编写的表和列描述,捕捉意图、语义、业务含义以及无法从模式或历史查询中轻松推断的已知注意事项。这一层相当于给智能体对每个表的信息进行了基础培训。
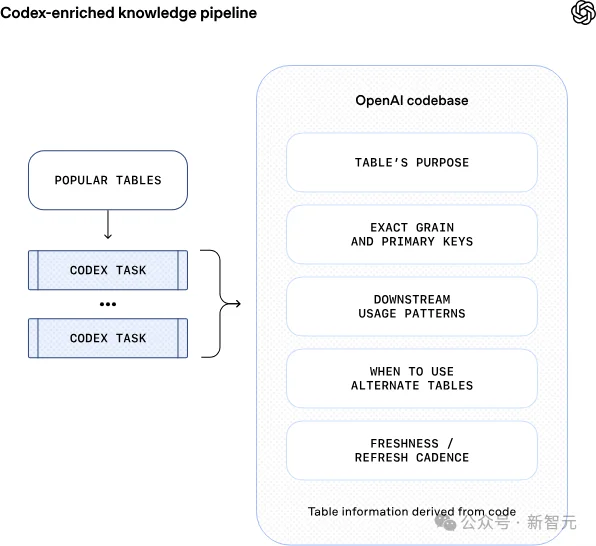
之后的Codex增强通过推导表的代码级定义,让智能体能够更深入地理解数据实际内容。这一层提供了关于值唯一性、表数据更新频率、数据范围等关键信息。这一层的引入,让智能体能够明白不同表在构建,更新上的差异。
再往上的机构知识层,智能体可以访问Slack、Google Docs和Notion,获取关键的公司背景信息,如产品发布、可靠性事件、内部代号和工具,以及关键指标的规范定义和计算逻辑。
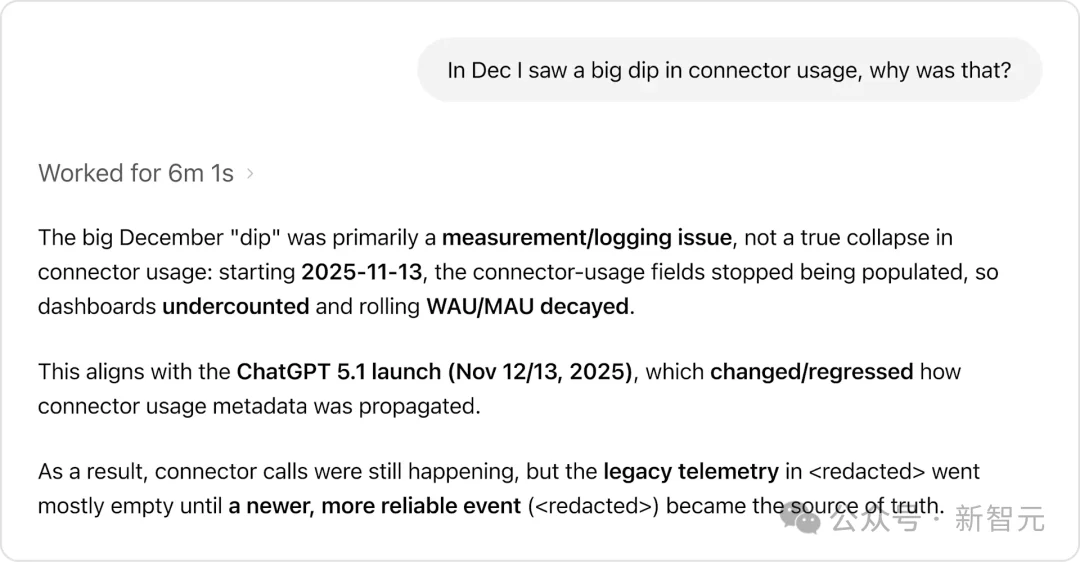
有了通过外在文本获取的背景信息,智能体就不会犯下常识性错误。
例如,当用户询问「12月连接器使用量为何大幅下降」时,智能体没有简单地报告数字下降,而是通过机构知识发现这主要是测量/日志记录问题,而非真正的使用量崩溃,与ChatGPT 5.1发布导致的数据收集变化相关。
而最关键的第五层学习进化,让智能体拥有持久的记忆。当它从用户那里获得纠正,或发现数据问题的细微差别时,能够保存这些经验供下次使用。记忆也可以由用户手动创建和编辑。可以全局适用,也可以是只独属于某个使用者。

而最上一层的运行时上下文,能够让智能体在没有现有上下文或现有信息过时时,通过实时查询数据仓库,直接检查和查询表。它还能够与其他数据平台系统(元数据服务、Airflow、Spark)通信以获取更广泛的数据上下文。
而上述6层系统,是在如何协同工作的?
具体可分为离线和在线两步。
每天凌晨,智能体会系统性地扫描昨天成千上万张数据表的实际用法与调用轨迹,汲取数据专家们留下的批注与洞察,并调用Codex来解读代码深处的逻辑,衍生出表格背后更丰富的业务语义。所有这些散落的「知识碎片」被融合成一个统一、标准化的「知识图谱」。
随后,通过OpenAI的嵌入模型,被转化、压缩为一组组向量嵌入,存入高速检索库中。至此,一个为AI智能体准备的、立即可用的「数据记忆宫殿」便铸造完成。
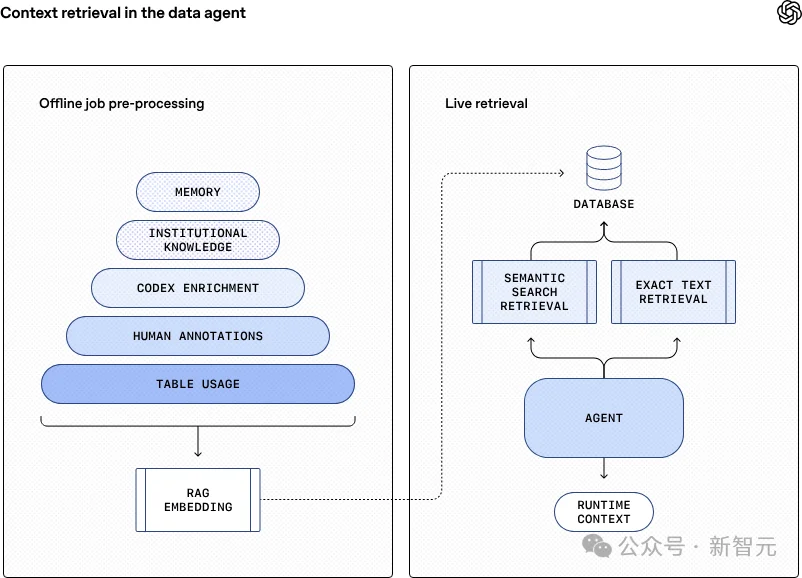
当用户的一个问题抵达时,智能体不再需要像人类分析师那样,一头扎入元数据的汪洋大海进行耗时的手工打捞。而是通过检索增强生成技术,精准定位并提取出与当前问题最相关的数据表。这个过程快速、可扩展,且延迟极低。
而对于那些需要最新数据的请求,智能体则同步启动实时查询通道,直接向数据仓库发起查询请求,由此既实现了运行时上下文的即时性,又能做到与离线知识的深度结合。于是,一个复杂的业务问题,便在离线记忆的「闪电检索」与实时数据的「精确制导」协同下,化为秒级可得的清晰洞察。
这个智能体最令人惊叹的,不是它的技术复杂度,而是它如何融入日常工作流程,成为真正的「队友」。与传统的「一问一答」式工具不同,OpenAI内部使用的数据分析智能体被设计为「可以与之推理的队友」。它是对话式的、始终在线的,既能处理快速答案,也能处理迭代探索。
想象这样一个场景:一个产品经理的提问不明确或不完整时,智能体会主动提出澄清问题。如果没有回应,它会应用合理的默认值来推进工作。例如,如果用户询问关于业务增长但没有指定日期范围,它可能会假设最近七天或三十天。这让智能体能够保持一边回复,一边与用户合作得到更准确的结果。
而为了避免不断进化的智能体在学习过程中跑偏,OpenAI团队利用Evals API为智能体配备了一位严格的监管者。
Evals API每个重要问题都配有手动编写的,可作为「黄金标准」查询语句,智能体的表现被持续监控和评分。
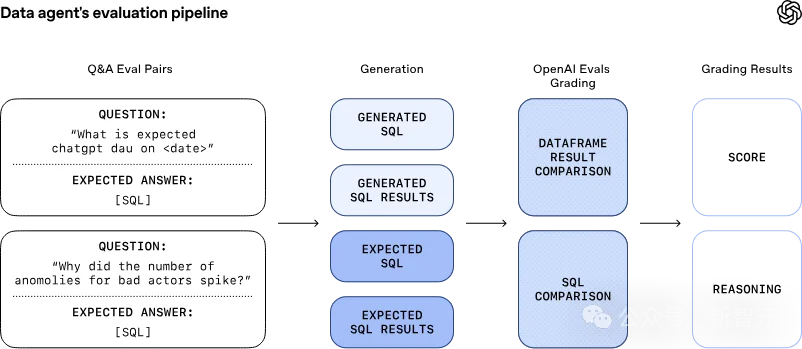
这些评估不仅检查SQL语法正确性,还比较结果数据的准确性。当智能体「学坏」时,系统会立即发出警报,确保问题在影响用户前被发现和修复。
而在数据安全方面,该智能体规定用户只能查询他们已经有权访问的表。当访问权限缺失时,它会标记这一点或回退到用户被授权使用的替代数据集。
而为了确保数据分析的过程透明,智能体会在每个答案旁边总结假设和执行步骤来暴露其推理过程。当查询被执行时,它直接链接到底层结果,允许用户检查原始数据并验证分析的每个步骤。
OpenAI的上述数据分析智能体,并没有开源,不过若想手搓一个类似的智能体,OpenAI的工程师也给出了其中踩过的坑。

最初,智能体能访问到完整的数据集,但这很快让智能体迷失在功能重叠数据表中。为了减少歧义并提高可靠性,开发者不得不对智能体能访问的数据表进行了限制,由此减少歧义,提高查询的可靠性。
另一个坑来自开发者给出的高度规范的系统提示词。虽然许多问题共享类似的分析形状,但细节变化足够大,以至于僵化的指令会适得其反。当关注点转向真实使用时的效果时,将如何实现交由智能体而非系统级提示词决定,会让智能体变得更加稳健,产生更好的结果。
而最关键的一点,是意识到相比专家对数据表给出标注,数据的真正意义存在于代码中。查询历史更精准地描述表的形状和用法,能捕获了从未在SQL或元数据中浮现的假设与业务意图。通过使用Codex爬取代码库,智能体能理解数据集实际如何构建,并能够更好地推理每个表实际包含的内容。与仅从数据仓库中获取信息相比,构建数据的代码能更准确地回答「这表里有什么」和「我何时可以使用它」。
随着企业数据环境日益复杂,类似OpenAI数据智能体的工具可能成为未来企业数据分析的标准配置,推动整个行业向更高效、更智能的数据驱动决策范式转变。
这些智能体的目标不是替代数据分析师,而是增强其能力,将数据分析师从繁琐的查询编写和调试中解放出来,专注于更高级别的定义指标、验证假设和制定数据驱动决策。
参考资料:
https://openai.com/index/inside-our-in-house-data-agent/
https://x.com/OpenAIDevs/status/2016943147239329872
文章来自于"新智元",作者 "peter东"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
