# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
强如谷歌,算力也不够了。
在昨天拉斯维加斯的谷歌 Cloud Next 大会上, CEO 劈柴哥 (Sundar Pichai) 透露了令人震撼的数字:
Gemini API 上个季度每分钟处理 100 亿 token——仅仅过去一个季度,就涨了足足60%,现在每分钟处理超过 160 亿 token。

增量很大程度上来自 agent 使用场景。一个任务被拆成十几步,每一步都是上下文读取,都是 API 请求,都在输入和输出 token。如果说简单的 chat 模式就是一来一回,那 agent 的到来让一切都变了,变成了一台「大电脑」带着一群「小电脑」在给你干活。
推理成本曲线也显著攀升了……
为了解决这个问题,谷歌开发出了新的一代 TPU(Tensor Processing Unit 张量计算单元):
第 8 代 TPU 首次被拆成两颗芯片,专门用来训练的 8t,以及专门用来推理的 8i。

图片来自 Pichai 个人推特
这是 TPU 项目十年来,第一次在产品定义上做出这种分野,也是谷歌在自研芯片上第一次,在规格上正面站到竞争对手英伟达 Rubin 的对面。
但首先我们要回答这个问题:
TPU 过去有过分档。2023 年 12 月的 v5p 是训练旗舰,更早的 v5e 是推理性价比款,两颗芯片同架构、不同裁剪。但是到了 2024 年的 Trillium(v6),和 2025 年 Ironwood(v7),TPU 又回到「一颗打天下」的产品先。
第 8 代直接把训练和推理拆成两颗独立设计的 die,背后的判断是:agent 时代的训练和推理,已经长成了两种截然不同工作负载。
训练任务的算力负载,可以理解为「大洪水」:不经常来,但一来就是排山倒海的流量。一次前沿模型训练持续数周,横跨万卡规模,对单芯片峰值和故障域规模很敏感。
推理的算力负载,虽然更加「细水长流」,但正如文章一开头提到的,也因为 agent 的普及发生了巨变。
这里英伟达在 GTC 2026 大会上给过数据参考:从 ChatGPT 出现到 Claude Code 流行起来的两年里,推理算力需求涨了一万倍,token 需求自 2024 年 12 月以来也增长了 28 倍。当推理开始以这个量级增长,agent 之间的交互又把 MoE 架构的路由工作,和长思维链推向极致。
一颗芯片同时服务两种负载就开始吃亏。
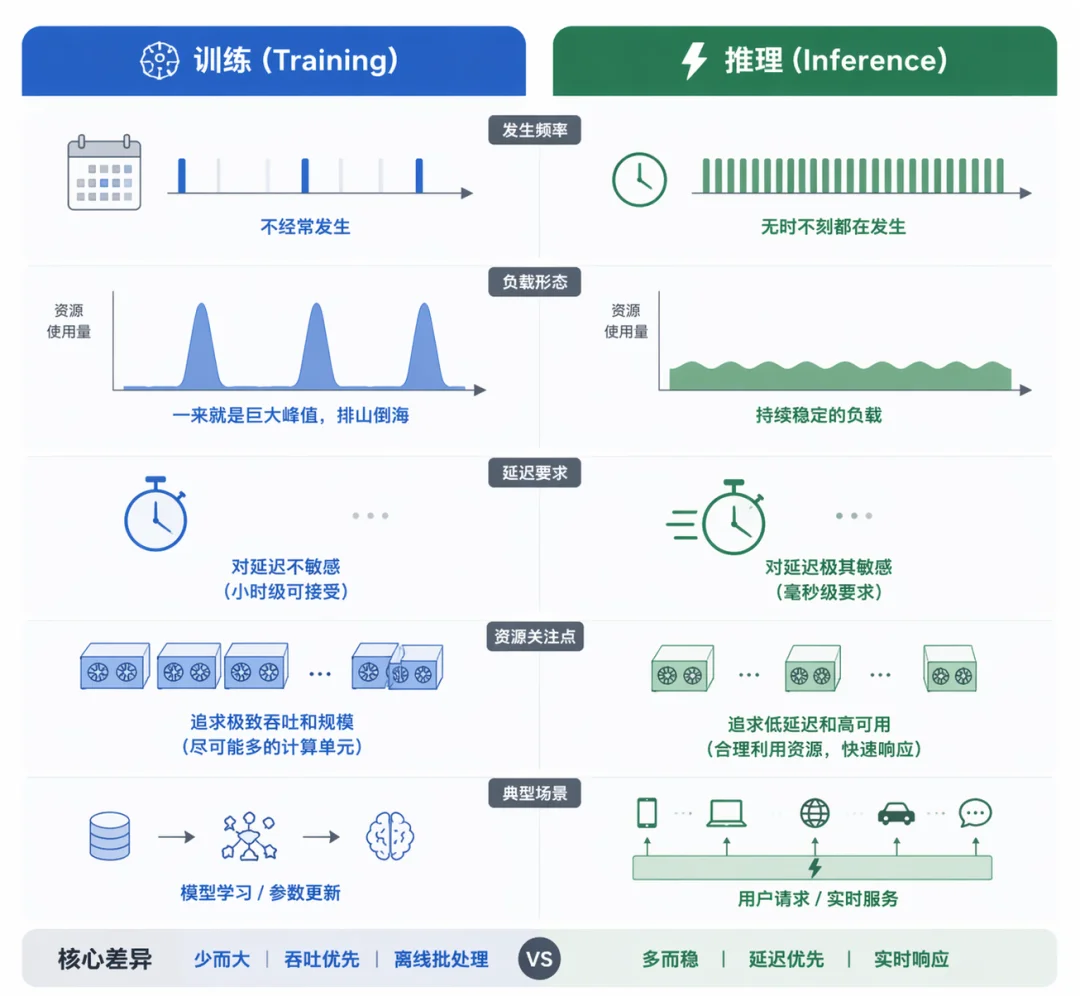
训练芯片要的是单位面积里更多的算力密度,和更大的规模化。推理芯片的诉求完全不同:片上存储要大到塞得下越来越大、越来越多的 KV cache,延迟要低到用户可以接受。
正如 Pichai 在这次大会上演讲里所说的:「问题已经从『能不能造一个 agent』,变成『怎么管好几千个』。」

先看硬指标。8t 单颗芯片能跑出 12.6 PFLOPS 的 FP4 算力,配 216 GB HBM3e 显存、6.5 TB/s 带宽。这个水平在今天的 AI 芯片里并不算顶,换个口径看甚至偏保守。NVIDIA 今年要上的 Rubin,单卡 FP4 算力大约 50 PFLOPS,显存 288 GB、带宽冲到 22 TB/s——单卡性能将近 8t 的四倍。
但是,谷歌在这里并没有要跟英伟达拼单卡,而是把押注 TPU 8t 的规模化维度。简而言之:TPU 8t 的单个「superpod」集群可以塞进 9600 枚 8t,且共享 2PB 内存,聚合算力高达 121 Exaflops。而英伟达的 Rubin NVL72 只有 72 颗 GPU,预计 2027 年底的 Ultra NVL576 机架只有 576 颗。
换句话说,在同一个「训练作业可以平铺多大」的维度上,谷歌领先 NVIDIA 超过一个数量级。
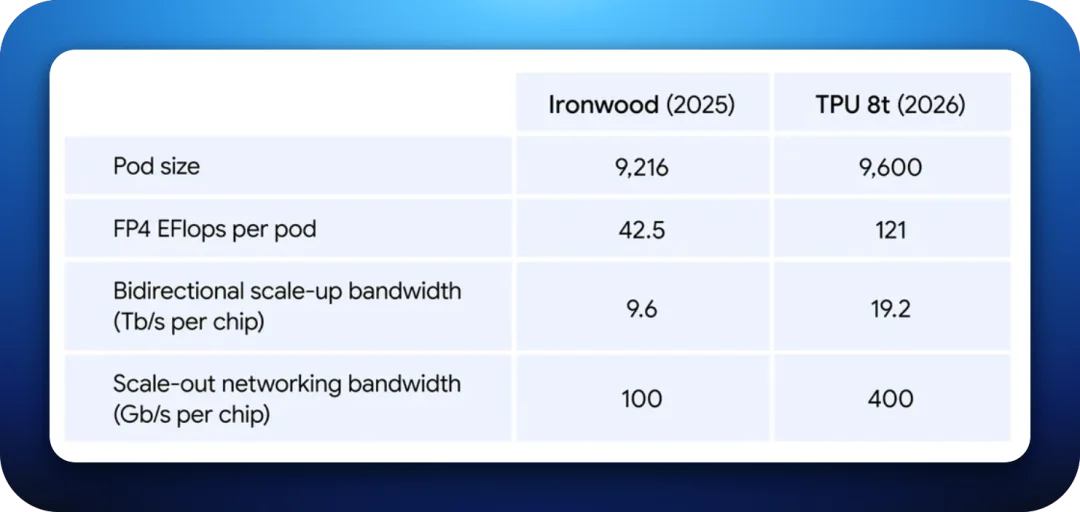
这件事对训练的意义是什么?训练一个前沿大模型要跑数周,每天都在重复同一件事:几千上万颗芯片一起算一步、然后把结果对齐,再算下一步。每次对齐都是一次「大家停下来等最慢的那个」。
而芯片越多、拓扑越平摊,整个集群就能越稳地往前推,少掉单卡峰值高不高反而没那么重要。谷歌给出的对比数据也是这个方向:相比上一代 Ironwood,8t 整 pod 算力接近 3 倍,同样花一美元能买到 2.7 倍的训练性能,每瓦性能最多 2 倍。存储这一端靠 TPUDirect 让显存直通硬盘,数据读取比上代快 10 倍。整个集群 97% 以上的时间都能花在真正的有效训练上,这在万卡级别已经很夸张。
换个角度理解这条路线的分歧:NVIDIA 像在造超级跑车,每一代都追求单车速度极限;谷歌更像在修一条八车道高速,单辆车不一定快,但总吞吐量可以拉到对手难以企及的规模。
SemiAnalysis 此前对上一代 Ironwood 的判断是,单芯片已经在显存、带宽、算力上追平 Blackwell,只落后大约一年。8t 没打算在单卡这边追平,它直接去抢一个 NVIDIA 当下还够不到的维度。
在推理芯片 8i 上,它的 288 GB HBM 显存配 8.6 TB/s 带宽,显存比 8t 还多 72 GB、带宽还高三成。它还配备了 384 MB 的片上 SRAM,是上一代 Ironwood 的 3 倍。
8i 的单卡 FP4 算力 10.1 PFLOPS,比 8t 略低,低在谷歌认为推理不需要那么多算力峰值。
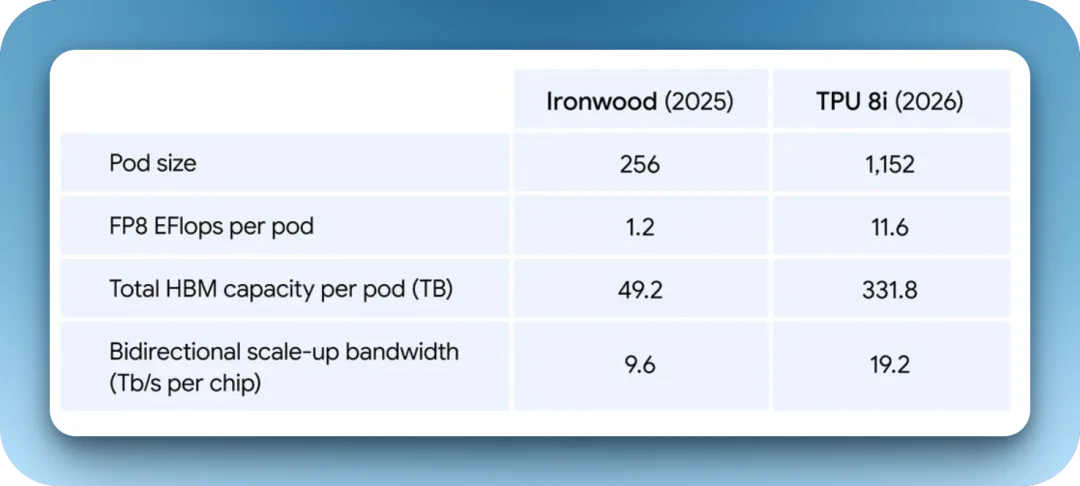
SRAM 是芯片上最快、也最贵的那块内存。过去这种「寸土寸金」的内存只有几十 MB,主要拿来缓存中间结果。8i 把它做到 384 MB,目的就是把大模型推理时最关键的 KV cache 能够整块塞进芯片。
如果你不知道 KV cache 是什么,可以简单将它理解为模型读长上下文时累积下来的「临时记忆」,过去它存在 HBM 显存里,吞吐的时候都要读取读一遍,推理速度相当一部分卡在这个搬运上。
而塞进 SRAM 之后,读写距离从「几米远的仓库」缩到「桌上的笔记本」,长上下文推理的效率直接上一个台阶。
再看 8i 真正的大招:它放弃了 3D Torus,也就是 TPU 从第二代用到现在的那个「每颗芯片只跟邻居说话」的网络拓扑。
3D Torus 擅长的是规律通信,适合训练任务(所有芯片一起做同一件事)。然而推理的需求是反过来的:一个 MoE(混合专家网络)模型的工作过程中,每次吞吐可能都要激活不同的专家网络,让任意两颗芯片之间突然要通话。放在 3D Torus 上,这意味着消息要一跳一跳传过去,跳数多的路径,会拖慢整条推理链。
8i 换上的新拓扑叫做 Boardfly。简单说,4 颗芯片组成一个小单元,8 块板拼成一个组,36 个组再通过光开关连起来,按照 1024 枚芯片的最高集群数量来计算,两颗最远芯片之间的跳数可以从 3D Torus 的 16 跳压到 Boardfly 的 7 跳,网络直径减少 56%,通信延迟最多降一半。
在同等成本下,8i 在低延迟、大 MoE 场景下,每美元推理性能比 Ironwood 提升 80%。用谷歌自己的话说,「客户花同样的钱,可以服务接近两倍的流量」。
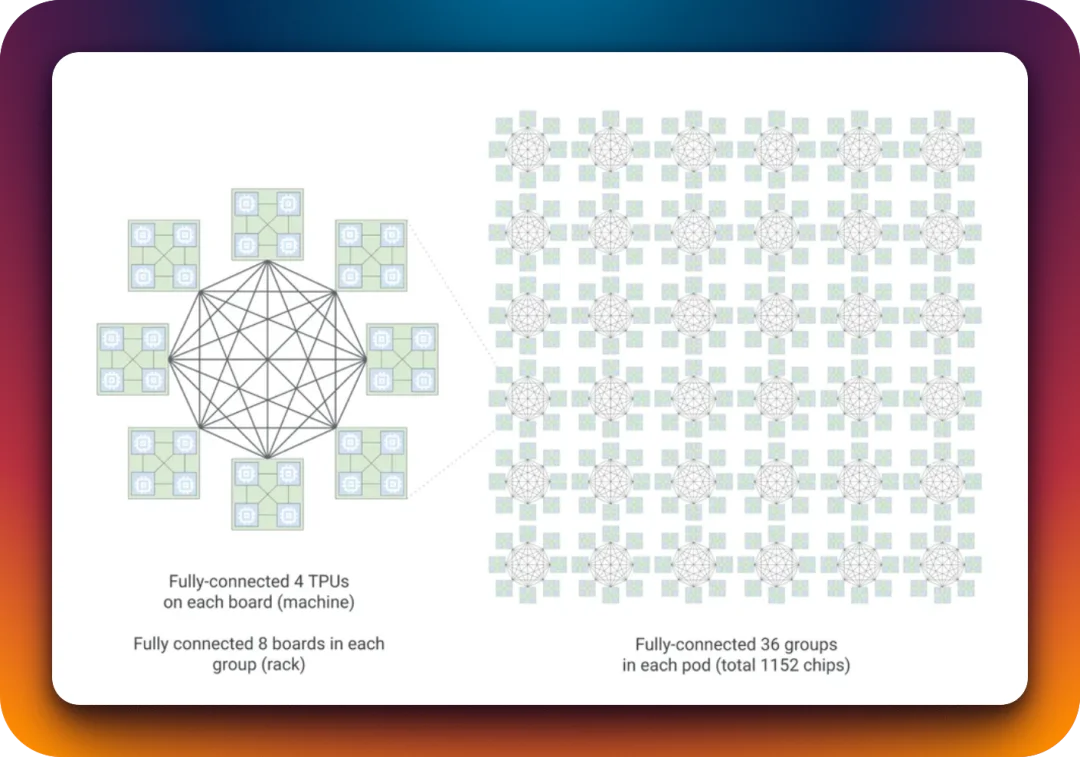
拿这套东西跟 NVIDIA 对比起来,画面大概是这样的:
NVIDIA 的推理旗舰是 NVL72 机架,72 颗 Blackwell/Rubin 芯片通过 NVLink 连接,它的思路是「每颗都很强,挤在一起更强」。8i 反过来:单卡算力克制,但一个 pod 集群直接内嵌上千颗芯片,再把跳数/对话延迟压到极低。
对于当今 agent 时代的典型推理负载,也即「成千上万个 agent 同时在后台互相传话」,8i 的设计听上去比英伟达当前的方案更加合理。
毕竟,推理专用芯片真正要解决的,说是让每个 token 变便宜。至于比上一代快多少,反而没那么重要——至少谷歌是这么认为的。
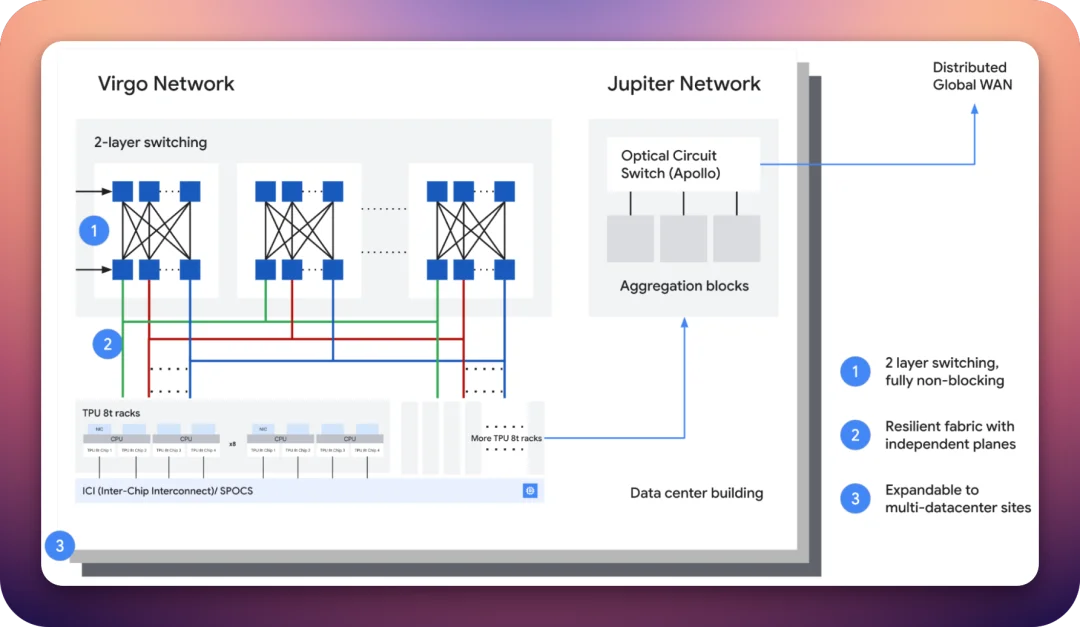
谷歌还发布了一个全新的数据中心网络结构技术 (fabric),叫做 Virgo。
你可以把它理解为一条巨型数据中心的「高速公路」,专门跑在 AI 芯片之间。一张 Virgo 能挂 13.4 万颗 8t,对分带宽 47 Pbps。再加上谷歌自家的 Pathways 和 JAX 软件层,多个 Virgo 可以拼成一个 100 万颗 TPU 的单一训练集群。
Anthropic 去年跟谷歌签下的那份最多 100 万颗 TPU、超过 1 GW 电力的大单,就是建立在这个数字之上。今年 4 月,Anthropic 又和谷歌、博通 一起把这份合约扩到了 3.5 GW。
更有意思的是,同一套 fabric 也能挂英伟达的 Rubin 显卡,最高支持 96 万颗 GPU。也就是说,谷歌非常清楚大家对英伟达的算力还是有需求的。客户在 Google Cloud 上照样买得到 Rubin 实例,TPU 8t 和 8i 只是算力菜单上新加的两道菜,而 Virgo 能够同时给用户提供「best of both worlds」。
知名分析师 Ben Thompson 今年写过一篇分析,指出 TPU 的硬件和软件栈都比英伟达更加「专用」,英伟达更加灵活。
2025 Q4,谷歌云营收 177 亿美元,同比增长 48%;手里的待履行合同高达 2400 亿美元,同比翻倍。管理层在财报会上直说 2026 年的算力还是不够用。客户要的算力已经溢出任何一家芯片厂商的产能,谁的卡都不嫌多。
这种时候,把所有能插电的算力都接进同一张网,比站队更加实在。
TSMC 2nm 大规模量产的窗口在 2027 年底,谷歌说 8t 和 8i 会在「今年内」正式上线,但这个「今年内」大概率是小批量可以通,真正的大规模出货要等到 2027。
至少对于谷歌最大客户之一的 Anthropic 来说,目前的主力算力来源仍然是英伟达的 GPU,以及上一代 TPU。
英伟达的护城河仍然存在。CUDA 生态已经积攒了十几年的人气,几乎所有开源模型、推理框架、依赖库都绕不开它;而在 TPU 这边,谷歌通过 JAX、Pathways、XLA 等技术,提供了替代方案,但也只是把路趟出来了。
要让习惯于 CUDA 的开发者,以及他们背后的巨头公司们转投 TPU,仍然有很大的坎。
有趣的是,业界巨头们已经开始对 TPU 提高兴趣了:据 SemiAnalysis 的报告,OpenAI 在跟英伟达购置算力谈条件的时候,提过 TPU 这档子事;而英伟达为了让 OpenAI 不从谷歌那边采购 TPU 算力,硬生生让出了 30% 左右的合同价格。
这么看,TPU 虽然暂时没赚到 OpenAI 的钱,至少把对手的利润率压下去不少……
英伟达的思路还是「核弹」的思路:把单卡,把连通性 (networking) 做到极致。而谷歌在这些方面也已经后来赶上。但今时今日,最大的问题可能不是性能本身,而是 token 经济学里面的更关键要素:电费、时延等等。
就连谷歌自己的高管也说:在今天的数据中心里,真正卡脖子的不只是芯片,还有电。
所以 TPU 什么时候能真刀真枪地决战英伟达?恐怕今年还不行,明年也悬,但它已经在另一条战场上开始扳动一些东西了。
真正被挑战的,可能也不只是英伟达,还有过去几年整个行业默认的真理:算力能解决所有问题。

文章来自于"APPSO",作者 "杜晨"。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
