# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Skill确实好用,但架不住模型和Agent Harness适配翻车。
不是所有模型都吃得动Skill,有的用上直接反向掉性能。
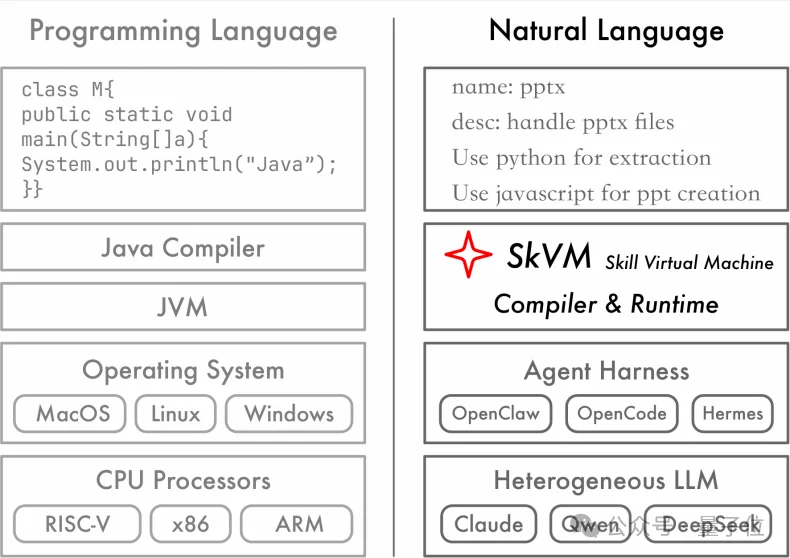
△从计算机系统架构角度审视“程序语言”和“Skill语言”
为了解决这个问题,来自上海交大的IPADS研究团队提出了SkVM:面向Skill的语言虚拟机。
在Agent时代下,Skill是代码,而不同的LLM是异构处理器。
研究团队借鉴了经典语言虚拟机(如Java Virtual Machine)的架构,首次为Skill设计了原生的语言虚拟机,让Skill通过一次编写,能够在任意的模型和Agent Harness上高效运行。
通过SkVM编译后的Skill,甚至能够让小模型(30B)获得匹配Opus4.6的精度,同时减少40%的token消耗量和至多50倍的运行速度提升。
从而一键提升OpenClaw、Hermes、openJiuwen、PI等Agent框架与Clawhub等主流Skill生态的执行速度、Token效率与任务精度。
同一个技能在不同模型/不同harness组合上的执行效果天差地别,甚至还会拖后腿。
上海交大IPADS的研究人员分析了超过 11.8万个技能,发现:
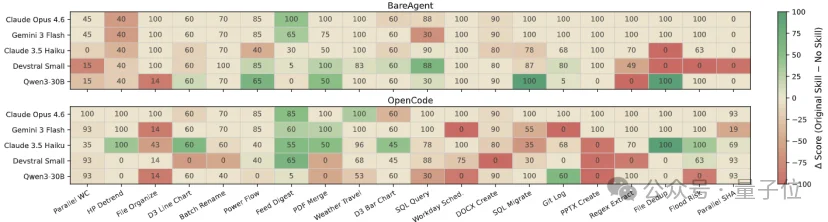
△采取Skill前后,对于任务完成率的影响,红色表示下降,绿色表示上升
原因很简单:
技能写的是“自然语言代码”,但模型和运行环境千差万别,Skill需求的能力和模型与环境提供的能力,存在明显的语义鸿沟!
具体而言:
面对上面所述的痛点,上交大团队从传统的语言虚拟机设计中汲取灵感,给出了面向自然语言的虚拟机SkVM架构,其整体架构如下图所示:
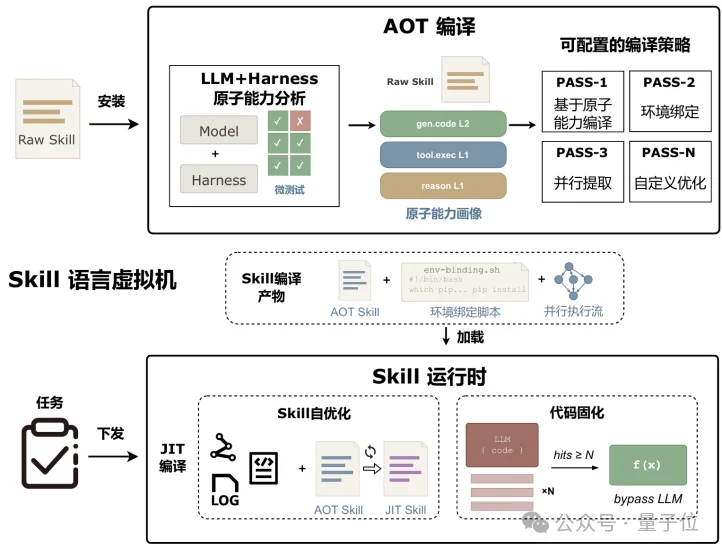
SkVM类比了经典了Java语言虚拟机(JVM)的设计,提炼了底层运行抽象,结合AOT/JIT等编译方式,并在运行时做自适应调优和运行时调度。
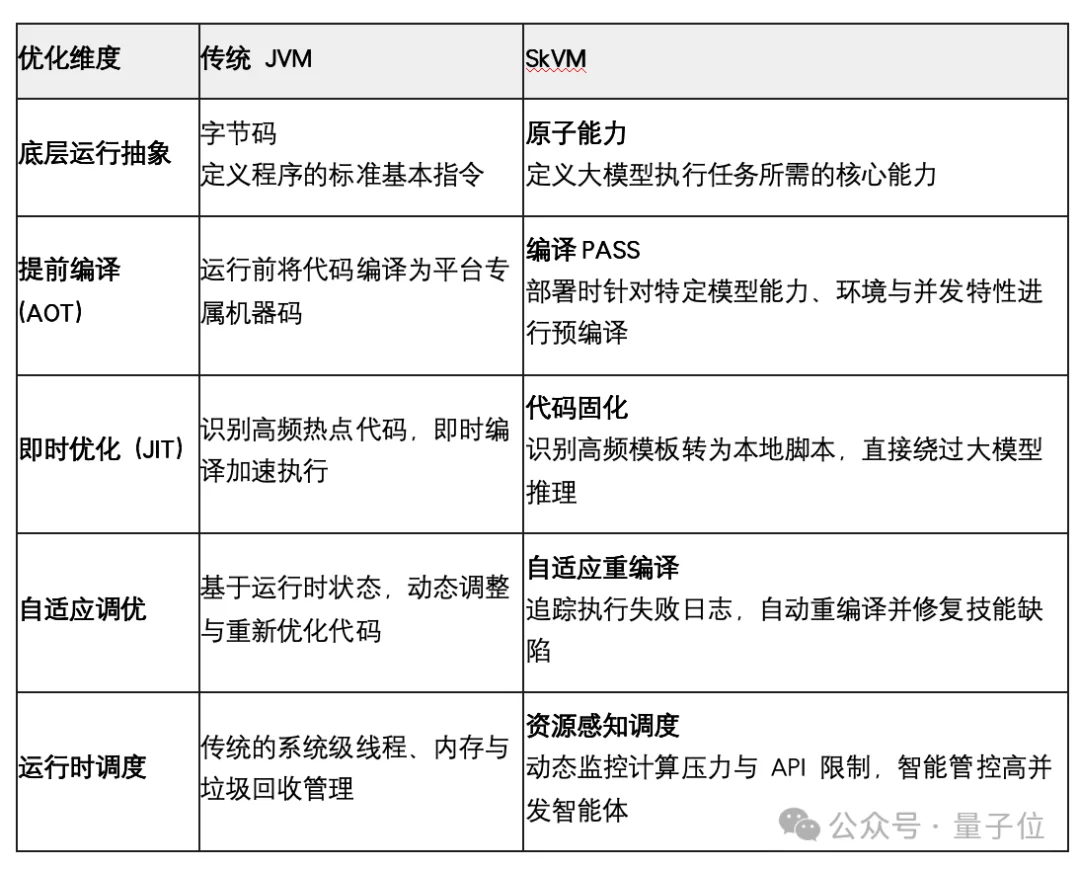
下表展示了SkVM和JVM在不同编译优化策略上的对比:
在安装Skill的时候,AOT编译器(由编译优化Skill+LLM组成)会对Skill进行编译,生成多个编译后产物,帮助后续Agent Harness+LLM在运行时更好地理解Skill。
SkVM在运行前会做三件事:
PASS-1基于能力的编译
系统提炼了26种“原子能力”(Primitive Capabilities),像测CPU跑分一样先摸底你的大模型。
不同于其他的LLM 测试集,原子能力并非测试大模型能否解决一个复杂逻辑问题,更多是测试模型是否具备工具调用,指令遵循,格式对齐等对立、可组合、以及逻辑无关的基本能力。
同时,对于每一个“原子能力”,也会进行分级打分,从而生成更加客观的大模型+Harness组合能力画像。其次,编译器会去分析Skill本身需要哪些“原子能力”,以及对应的等级。
如果Skill需要的“原子能力”等级大于当前运行的大模型+Harness能够提供的能力等级,编译器会编译Skill,以降低Skill的能力需求。
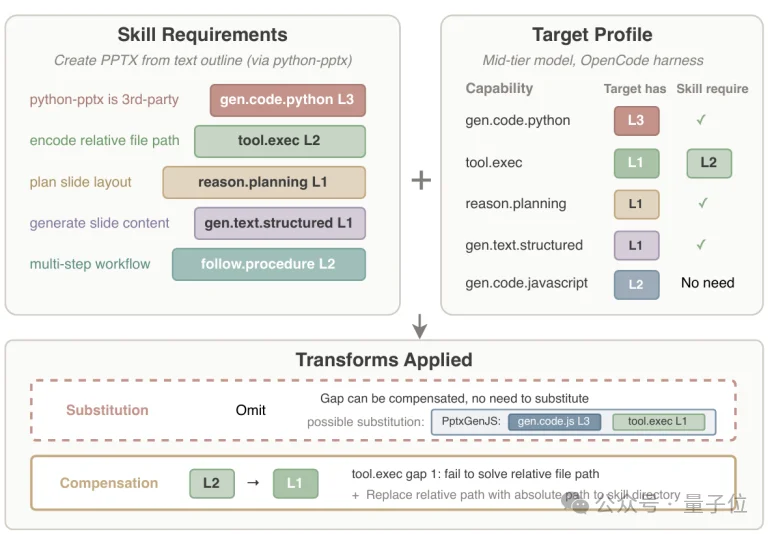
例如,Skill中往往会包含一些预先定义的python/js执行文件,而这些文件通常是通过相对路径定义的。
如果模型+Agent harness 缺乏对应相对路径的解析能力,编译器会在安装Skill的时候,将相对路径转换为绝对路径,以降低Skill 对于“脚本执行”这一原子能力的等级需求。
PASS-2 环境绑定
Skill中往往会定义运行需要的环境和依赖。
Agent在运行时候,LLM会检查并且安装对应的环境,导致大量的token浪费 / 环境安装失败。
为此,AOT编译器自动提取技能需要的包和工具,生成安装/检验脚本。运行前一键配好环境,不用大模型自己尝试排错了 。
PASS-3 并发提取
有超过76%的Skill中包含workflow,并且Agent harness 默认会采用串行的方式执行。
AOT编译能够发掘Skill执行过程中,不同粒度的并行机会,包括数据并行(一条指令,多个数据)、指令并行(无依赖的指令并行发射)和线程并行(多个独立的sub-agent,完成不同的子任务),并且生成可并行的DAG工作流图。
同时,开发者还可以自定义编译优化机制,注册到AOT编译器中,从而进一步对Skill进行运行前优化。
除了静态编译,在运行时,SkVM会采用JIT(Just-in-Time Compilation)加速Skill的执行效率。
代码固化(Code Solidification)
Skill中定义的脚本,往往是可变参数的代码模板。
Skill在每次运行时,LLM都需要反复生成可执行的脚本,导致大量token的浪费。
为此,SkVM会在AOT阶段,生成代码的指纹,模板,以及对应的参数列表。
在运行阶段,调用Skill后由LLM生成的代码,和AOT阶段提前生成的代码指纹进行匹配,如果连续多次匹配成功,SkVM会采用JIT编译优化,根据输入参数,直接固化可执行的代码,而非每次由LLM 重新生成。
自适应重编译
如果在运行中出现报错/重试,系统会收集错误日志反馈给编译器,自动重新优化技能。
防止每次运行Skill的过程中,发生同样的错误,并且提高任务的成功率。
在运行时,SkVM除了采用JIT的编译优化外,还会负责Skill生命周期、加载管理,保证Skill编译后新的编译产物,能够正确的加载和执行。
同时,SkVM还会根据当前的系统资源,调节并行粒度,减少不必要的资源竞争。
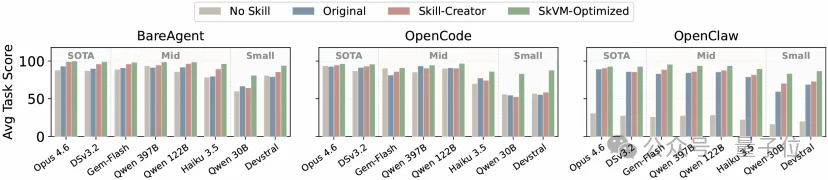
研究团队在包含代码生成、数据分析等118个代表性任务上进行了测试。
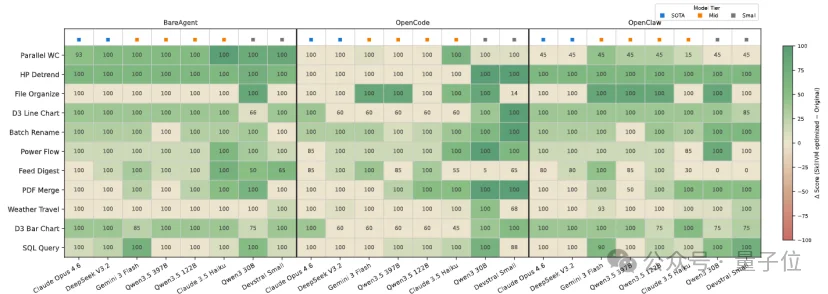
结果显示,SkVM带来的收益非常显著。尤其是对于偏弱的小模型,提升最为显著,因为它弥补了小模型在处理复杂JSON结构生成、环境依赖、脚本解析上的短板,使得qwen 30B拥有比肩Opus 4.6的任务成功率。
对于顶尖模型,采用SkVM编译后,消耗的token至多下降40%。
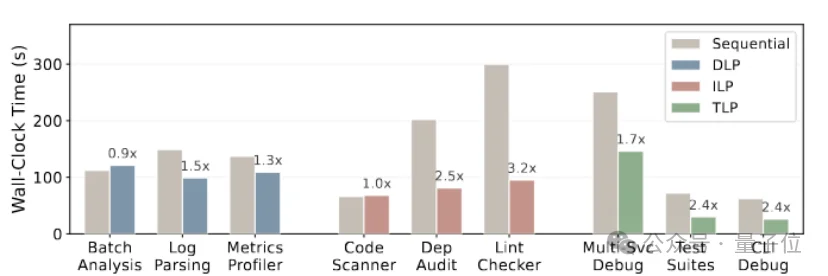
同时,得益于“代码固化”技术,代码部分的执行时间,从上万毫秒直接压缩到了几百毫秒,速度飙升19到50倍。
而针对Skill中潜在的并行机会,SkVM通过数据并行、指令并行和线程并行,将Skill的执行效率至多提升3.2倍。

目前,SkVM能够无缝键入openClaw,Hermes Agent,openJiuwen Agent、PI Agent等主流的Agent框架,支持Clawhub等主流的Skill生态。
SkVM论文:https://arxiv.org/abs/2604.03088项目网站:https://skillvm.ai/项目仓库:https://github.com/SJTU-IPADS/SkVM/
文章来自于微信公众号 "量子位",作者 "量子位"


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
