# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
三月底的一周,GitHub Trending 上同时出现了五六个项目。它们的名字一个比一个离谱。
「同事 skill」把离职同事的飞书消息、钉钉文档、Slack 记录、微信聊天喂给 Claude,自动生成一个 skill 文件。装上之后,AI 就能「变成」那个同事。它不只是干那个同事的活,还用那个同事的语气说话。
这个项目一周就拿了 9500 颗星。有人评论说,「建议改名叫 同事 kill,成为 Skill 后就可以 Kill 掉了。」
看到这个项目火了,社区里掀起了一股「蒸馏」热潮。
01
万物皆可蒸馏

exskill 把前任蒸馏成 Skill。它支持微信聊天记录、QQ 消息、社交媒体截图,甚至还有照片 EXIF(可交换图像文件格式,Exchangeable Image File Format)数据,甚至构建了五层性格结构。
老板skills 更实用。它分三个模块。Boss Judgment 用老板的标准审方案,Managing Up 教怎么汇报坏消息,Persona 复现老板说话风格。
它还内置了马斯克、乔布斯、黄仁勋等名人的模板。
这场蒸馏创造的巅峰是女娲skill,它用 6 个并行 Agent(智能体)从 40 多个信息源提取公众人物的心智模型,直接帮你蒸馏。它已经内置了 Paul Graham、芒格、费曼等 13 个人。
自此,我们似乎来到了人人皆可被skill蒸馏的时代。
同一时间,卡内基梅隆大学(CMU)发表了一篇题为《SKILLFOUNDRY: Building Self-Evolving Agent Skill Libraries from Heterogeneous Scientific Resources》的论文。
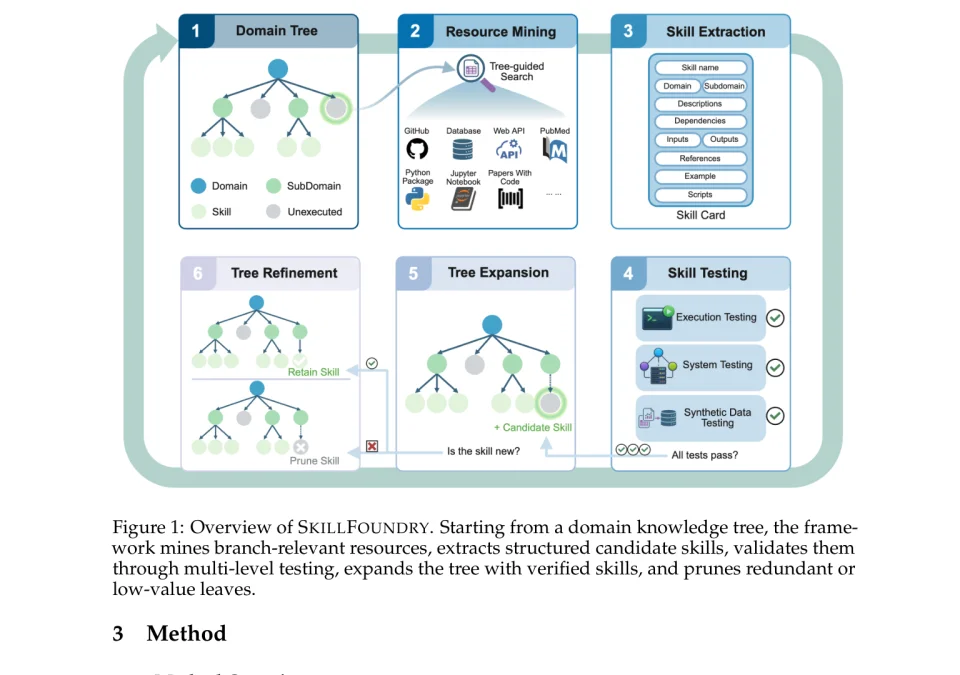
SkillFoundry 的 6 步骤自进化 pipeline(来源,SkillFoundry 论文 Figure 1)
虽然是学术论文,但它做的事情也是蒸馏。只不过蒸馏的不是人,而是整个科学领域的知识。
Skill Foundry 的逻辑就是扫一遍 GitHub 仓库、API 文档、Jupyter Notebook、学术论文,看看能不能自动提取结构化的 Agent Skill。
结果只跑了一次 pipeline(流水线)就挖出 286 个 skill,跨 27 个领域。其中 71.1% 是现有 skill 库里没有的新能力。
在基因组学的细胞类型标注任务上,加了 skill 后覆盖率从 81.1% 提升到 99.2%,准确率从 68.5% 提升到 82.9%。
一边是草根社区的赛博炼人,一边是顶尖学术团队的知识炼金。它们却都在试图验证同一个信念,即如果经验能被写成文字,通过skill,AI 就能学会。
但没人想被蒸馏。
同一周Github上还出现了另一个项目,叫 anti-distill(反蒸馏)。
这个工具帮使用者生成一份看起来完整、核心知识却被掏空的 skill 文件。通过这个skill,那些具体的编码规则方法会被改写成「缓存使用遵循团队规范」。
这在技术表达上是没啥问题的,但就是毫无内容的正确的废话。
anti-distill 的存在本身就暗示了一个问题。
如果 skill 真的能蒸馏一个人的全部能力,那让它直接无效化应该很难。但 anti-distill 做起来似乎毫不费力。
掏空的或许不是「人」,而是一层特定的东西。
这背后其实是一个值得拆开看的问题。
Skill 到底能蒸馏我们的几分之几?那层能被掏空的是什么,那层掏不空的又是什么?
02
一个不对劲的现象

2026 年 2 月底,BenchFlow 团队的 Xiangyi Li 等人发布了第一份大规模跨领域 skill 评测,名为《SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks》,它覆盖 84 个任务和 11 个领域,跑了 7308 条测试轨迹。
从总数来看,加了 skill 之后,Agent任务的平均通过率提升了 16.2 个百分点。看起来skill确实非常有效。
但把数字拆开看,一些有趣的现象就出来了。
所有skill里,医疗健康领域的提升最显著,达到了 51.9 个百分点,从34.2% 直接跳到 86.1%。
而软件工程领域,用了skill只提升了 4.5 个百分点。
同一套 skill 机制,同一批模型,领域不同,效果差了十倍。
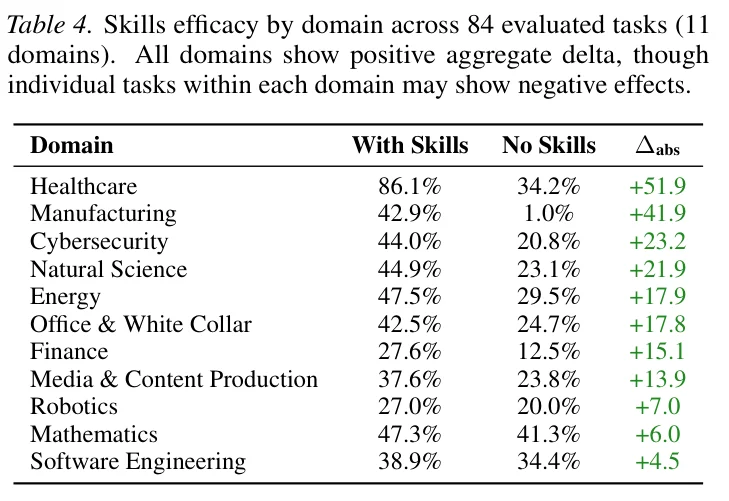
SkillsBench 按领域的 skill 效果(来源,SkillsBench 论文 Table 4)
更反直觉的发现还在后面。
研究者按 Skill 的详细程度分了四级。SkillsBench 按 skill 的文档详细程度分了四级。
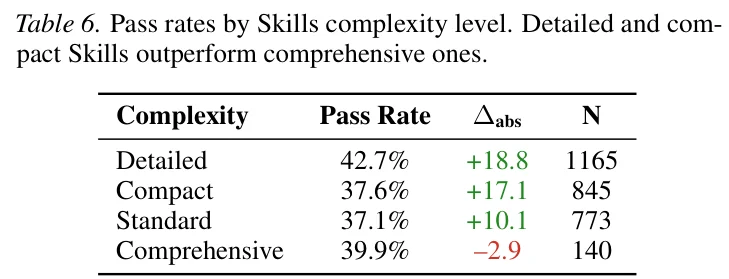
SkillsBench 论文原始数据(来源,Table 6)
细致(Detailed)级别的 skill,也就是有步骤、有示例、聚焦在具体操作上的 skill,让通过率提升了 18.8 个百分点。
但面面俱到、试图覆盖所有边界情况的 Comprehensive 级别,反而让通过率降低了 2.9 个百分点。
这说明,写得越完整的 skill,效果反而越差。
同期,Han, Zhang 等人专门在软件工程领域做了更细致的测试,并发表了论文《SWE-Skills-Bench: Do Agent Skills Actually Help in Real-World Software Engineering?》,测试了 49 个真实开源项目 Skill,约 565 个任务实例。
结果 39 个 Skill(约 80%)对通过率零改善。
只有 7 个有明显正向效果。比如 risk-metrics-calculation 提升 30%,因为它编码的是特定金融风险计算公式。
另有 3 个甚至产生了负面效果。
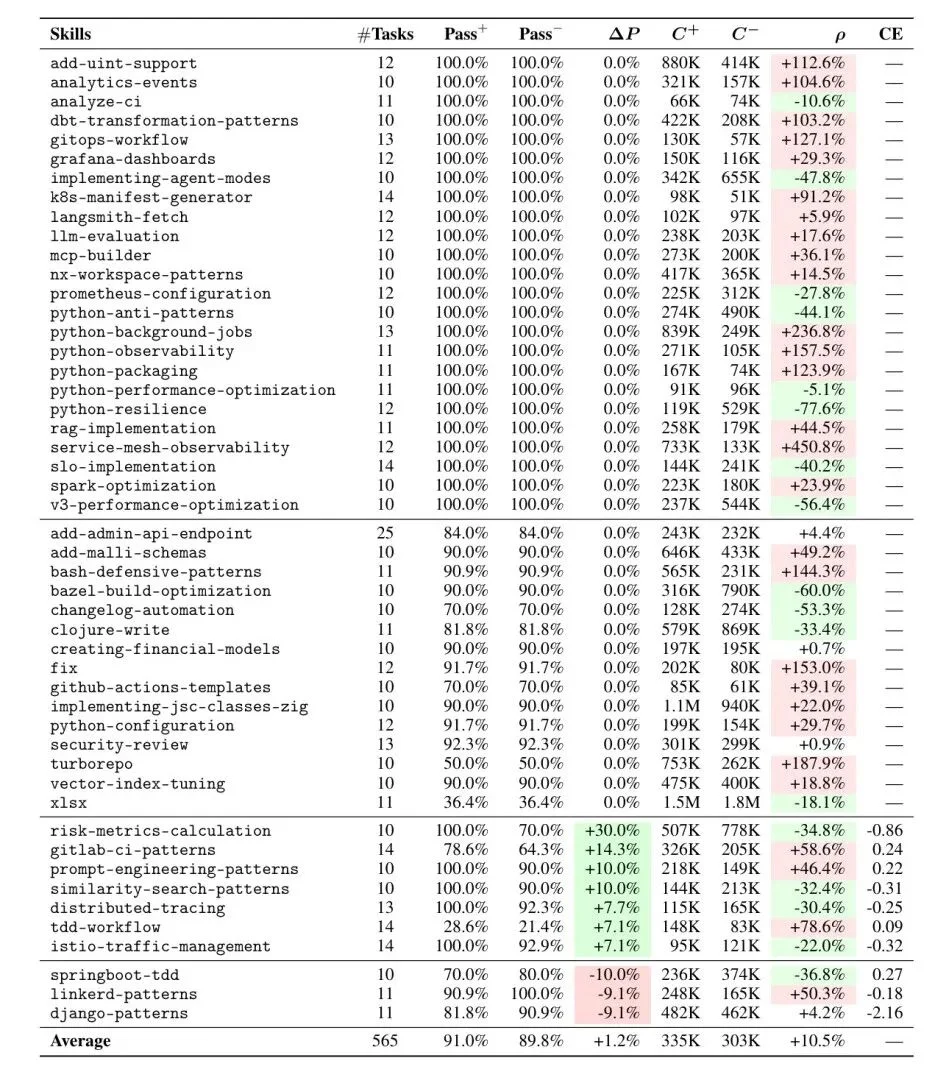
SWE-Skills-Bench 49 个 Skill 的完整评估(来源,论文 Table 2)
其中linkerd-patterns 的失败特别有教学意义。这个 Skill 打包了 Linkerd 的 7 套配置模板。内容客观上很准确,但模型被模板死死锚定了。
模型先是照着过时的 API 版本写代码。然后在调和模板和任务需求时,虚构了不存在的字段。
最后模板里的示例还让模型加了完全不相关的资源。
这三步失败都是因为模型放弃了自己的判断,转而盲目跟随 Skill 里的具体样例。
上面这些数据清楚的表明,Skill 并不是写了就有用。
它在某些任务上效果惊人,在另一些任务上毫无帮助,在少数任务上甚至有害。这些差异看起来不是随机的,而是像有什么结构在其中。
要理解这个结构,得先搞清楚 skill 到底是什么。
03
Skill 是什么
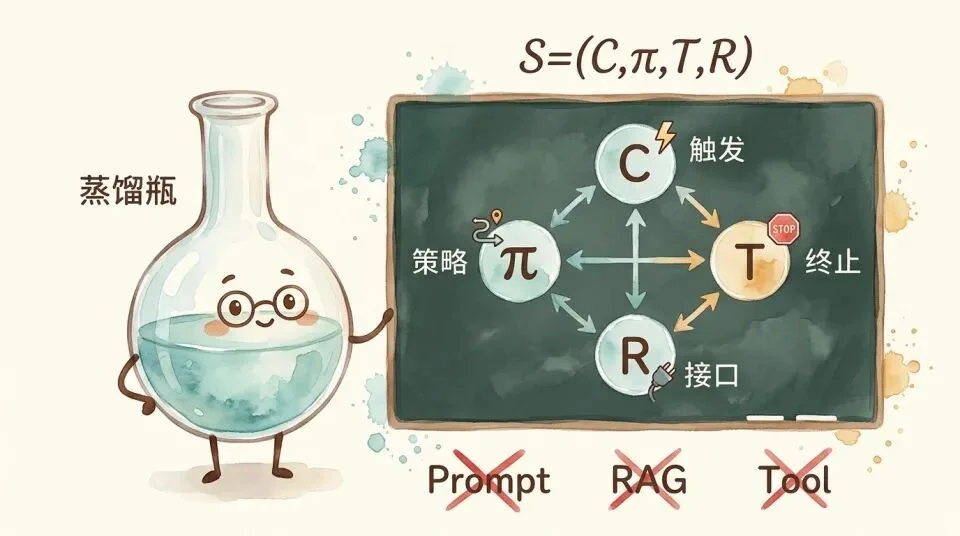
很多人把 Skill 理解成「高级 prompt(提示词)」。大概就是写一段结构化的指令,告诉 AI 遇到某类问题该怎么做。
如果只是这样,skill 和一段精心编写的 system prompt(系统提示词)没有本质区别。
但真是这样吗?
2026 年初,浙江大学发表了一篇系统性的 SoK 论文《Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward》,给Skill下了一个正式定义。
在他们的分析中,一个 skill 由四个部分构成,S = (C, π, T, R)。
C 是适用条件,即什么时候该触发这个 skill。它不是「用户说了某个关键词」这么简单,而是根据任务的语义特征自动匹配。π 是执行策略,指具体的操作步骤和决策逻辑。T 是终止条件,决定什么时候该停。R 是可复用接口。别的 skill 或 agent 可以通过这个接口调用它。
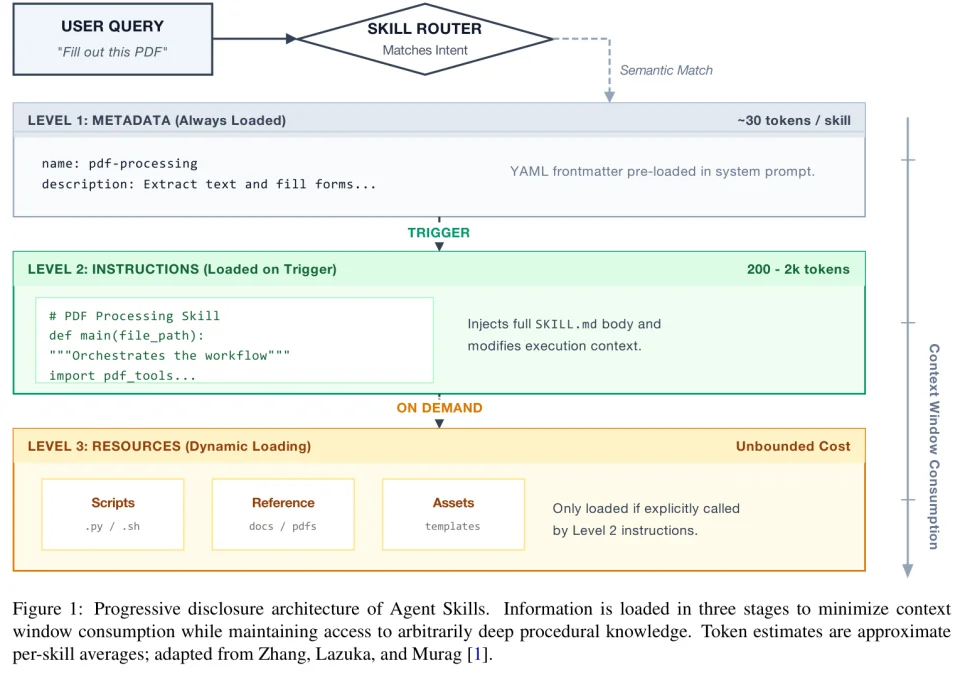
Skill 的三级渐进加载架构(来源,SoK 论文 Figure 1)
这个定义里最关键的是两个词。「可组合」和「可路由」。
可路由是指,模型面对一个任务时,能根据语义特征自动匹配 Skill,不需要用户手动选择。
可组合是说,一个 Skill 可以把子任务分派给其他 Skill。SkillsBench 数据显示,2 到 3 个 Skill 协同效果最好,通过率提升 18.6 个百分点。而 4 个以上反而只提升 5.9 个百分点。这说明,模块化有收益,但存在最优粒度。
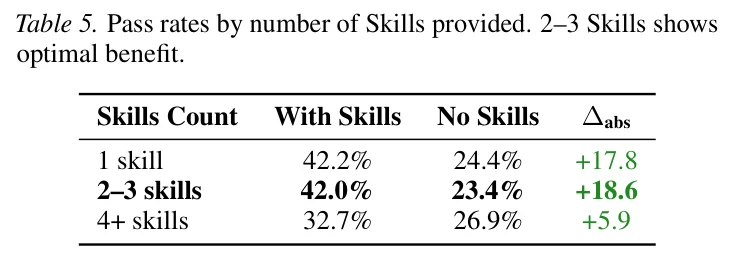
2–3 个 Skill 协同效果最好(来源,SkillsBench 论文 Table 5)
除此之外,Skill还有跨会话的持久化。它存储在文件系统里,不随对话消失。因此是可以积累的。第 100 个 skill 和第 1 个 skill 可以共存,也可以互相调用。这让 skill 成了一种可以渐进式构建的知识资产。
而 prompt 是一次性的文字,没有调用关系。
从这个角度看,Skill 更接近软件单元,而不只是一段文字。
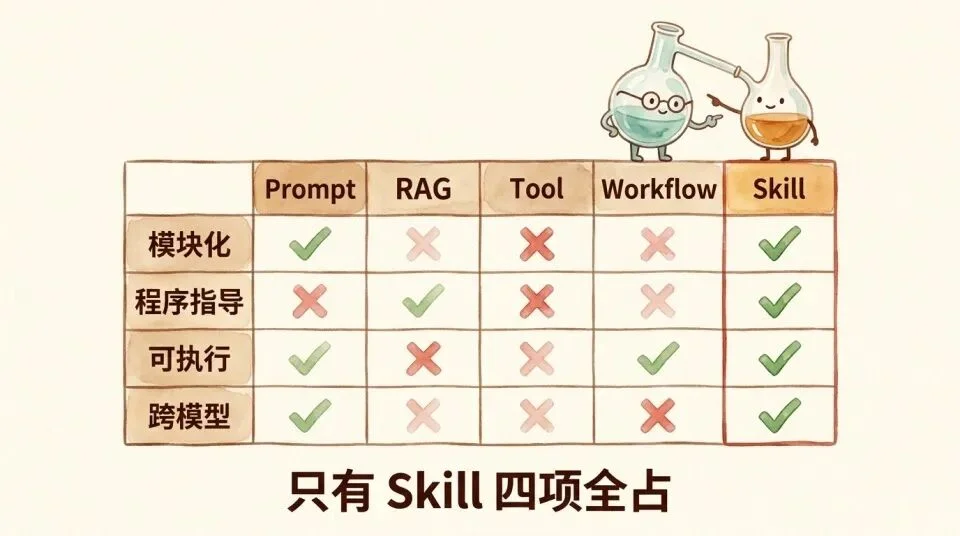
Skill 与其他增强范式的四项对比
它与 workflow(工作流)的区别也很关键。
传统 workflow 像 Zapier 或 n8n,是完全硬编码的执行路径。Dify、Coze 和 LangGraph 这类 agentic workflow(智能体工作流),虽然在 DAG(有向无环图)节点里嵌入了 LLM(大语言模型)的判断,但节点之间的流程骨架仍然是固定的。
Skill 没有预定义的 DAG。整个执行策略 π 都是自然语言。模型自己决定走什么路径、调什么子 Skill、什么时候停。这层弹性是 Skill 的核心价值。
现在定义清楚了Skill,但要明白它的边界,我们还需要再往里挖一层。
首先, π 都是自然语言,因此skill 能承载的知识,大体上得是能用语言表达的那种。
我们可以在里面写「如果 CPU 使用率超过 80% 且持续 5 分钟,触发扩容」。但很难写「判断这个代码改动是否会在三个月后引发架构问题」。
这不是因为不会写,而是因为做出这个判断的思维过程本身,就不是由可以逐条列举的规则构成的。
Skill 的条件路由依赖语义匹配。这也意味着 skill 库的扩张可能有上限。当太多 skill 的描述语义接近的时候,模型会分不清该用哪个。
《From Multi-Agent to Single-Agent》论文还测量过一个阈值,认定选择准确率在 skill 数量超过约 80 到 100 个之后就会出现较明显的下降。
这其实和人类认知很像,当你对同一个线索关联的记忆越多时,每条记忆的激活强度就越低。
这两个边界,即表达边界和选择边界,与其说是缺陷,不如说是 skill 这种形式的内在限制。
04
能蒸馏的是哪一层
想要回答人到底哪些能力可以被蒸馏成 skill,哪些不行,需要先搞清楚一个前置问题,即人的知识到底由哪些东西构成,其中哪些能被语言承载,哪些不能?
这个框架要足够精细。不能笼统地说「有些能说有些不能说」,而是要精确到「哪种知识走哪种编码机制,语言能覆盖哪些、覆盖不了哪些」。
认知科学家 John Anderson 从 1970 年代构建的 ACT-R(Adaptive Control of Thought—Rational)理论,刚好可以覆盖这种精细度。它到今天已经迭代了近五十年,是认知科学领域被引用最多的计算架构之一。
另一个最近被反复提及的理论是匈牙利裔英国哲学家 Michael Polanyi 的tacit knowledge(隐性知识)概念,认为有些知识是可表达的,但另一些知识则是隐含的,无法用语言表达的。这个概念可以说是当下舆论场上对Skill能力界限最常用,也是最有力一种反驳。我们后面会详细讨论这个概念,力图把它的模糊表述做更清晰的定义和分离。
什么是Skill擅长的?新注入知识
先讲讲ACT-R,这个理论把人的知识分成两大类。陈述性记忆(know-what)和程序性记忆(know-how)。
陈述性记忆是知道的事实和规则,比如「青霉素对链球菌感染有效」,或者「ICD-10(国际疾病分类第十次修订本)里 J18.9 是未指明的肺炎」。
部分领域知识,比如你的偏好和习惯,你从事的小众行业的规则,这些陈述性事实在预训练阶段可能是没有的。因此注入效果会很好。
第二种知识是程序性记忆,也就是做事的流程,由一条条 IF-THEN (如果,那么)的产生式规则组成。比如「如果 CPU 使用率超过 80% 且持续 5 分钟,触发扩容」。
这些 IF-THEN 规则模型拿到就能执行,所以效果会很好。比如 SWE-Skills-Bench 里 risk-metrics-calculation 提升 30%,编码的就是特定的金融风险计算公式,属于纯粹的规则注入。
这些都是模型的舒适区,通过新注入的内容,模型获得了一些具体的、可执行的知识时,它们的注入就会强化模型的能力。
然而,模型其实很多时候并不是完全缺乏这些知识,它在预训练阶段实际上已经积攒了远超人类的知识量级。但模型不一定会在概率上一定选择这些知识,你需要把它激活出来。
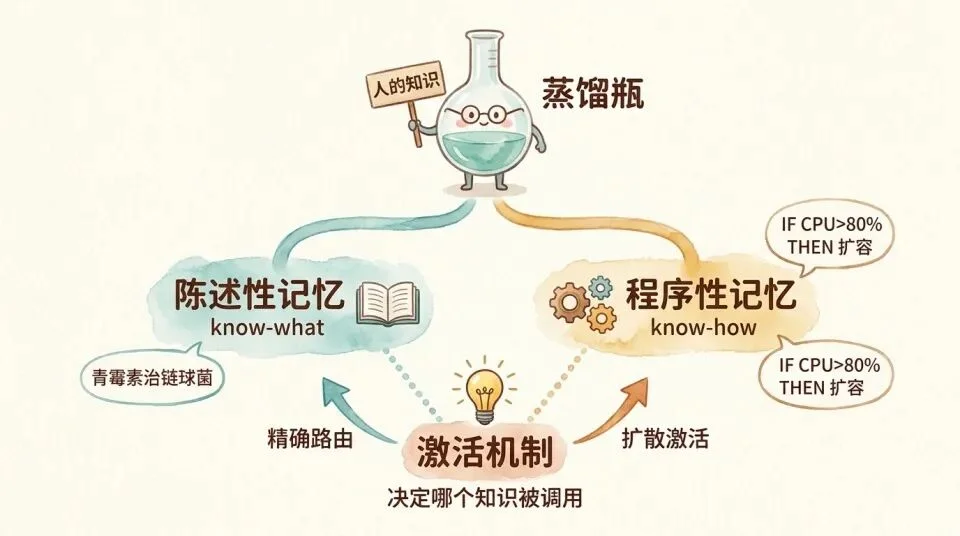
ACT-R 的 spreading activation(扩散激活)机制解释了这一点。即,通过 context(上下文)线索改变知识的激活权重。
比如模型在预训练时大概率见过 ICD 编码表、诊断手册和临床指南,因为这些都是公开文档。但在一个普通用户随口问「我咳嗽怎么办」的对话上下文中,这些专业知识的激活值很低。模型更可能去调用科普文章和健康问答这类内容。
在 Skill 里写「遇到 XX 症状组合,按 ICD-10 编码 YY 分类」或「用药前检查 ZZ 交互作用表」,不只是在注入新信息。这更像是精准路由。
它把模型已经知道、但激活值不够的专业知识直接拉到前台。
这解释了医疗健康领域Agent能力为什么会飙升 51.9 个百分点。诊断手册是公开的,模型训练过,但没有 skill 时通过率只有 1.0%。这大概率不是不知道,而是没被正确激活。
反过来,软件工程只有 4.5 个百分点的提升。因为大量专注编程的 post-training(后训练),让编程知识在写代码的语境下本来就是高激活状态。
Skill 再加路由线索,边际增益自然很小。
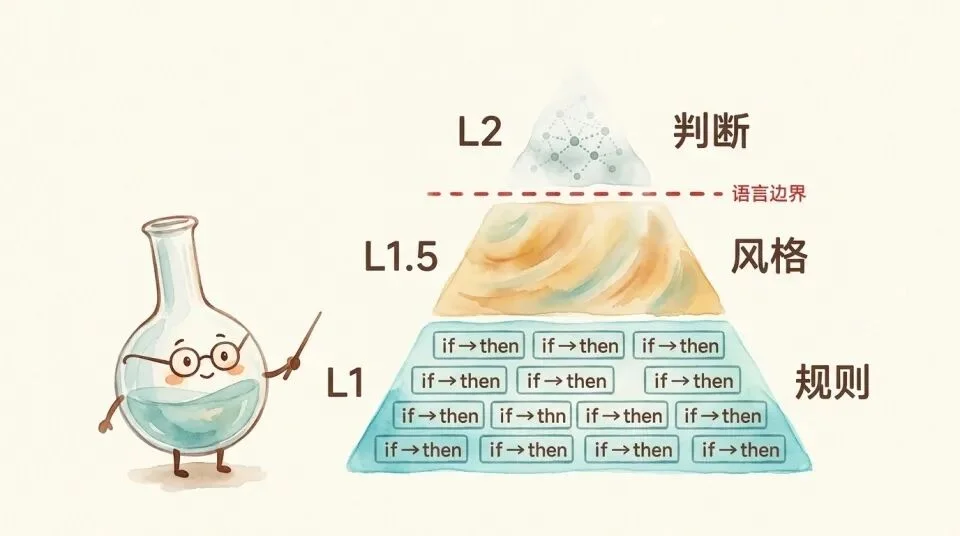
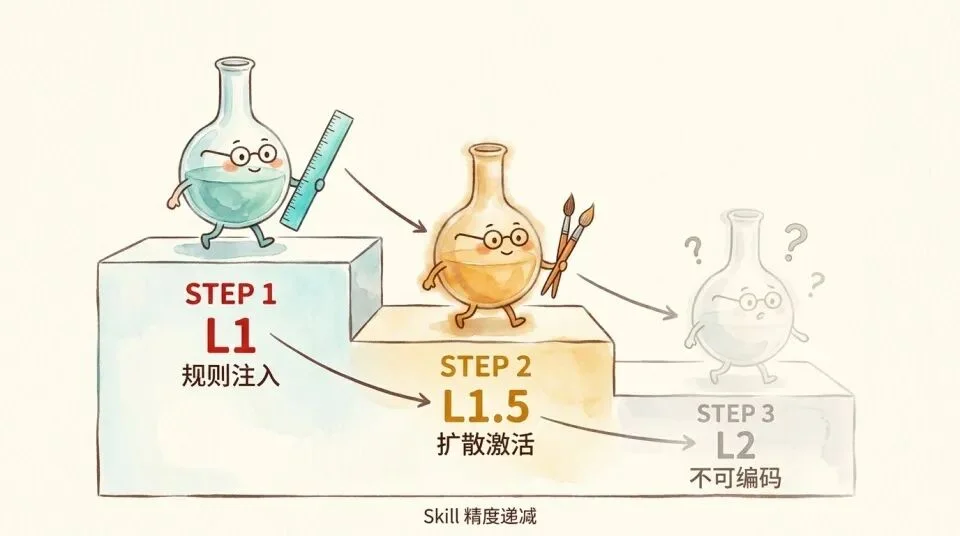
当路由目标精确、步骤明确时,就是确定性注入。我们把以上这些确定的知识性注入定为 L1层。
这是 Skill 里效果最好的一类内容。
中间地带,扩散激活
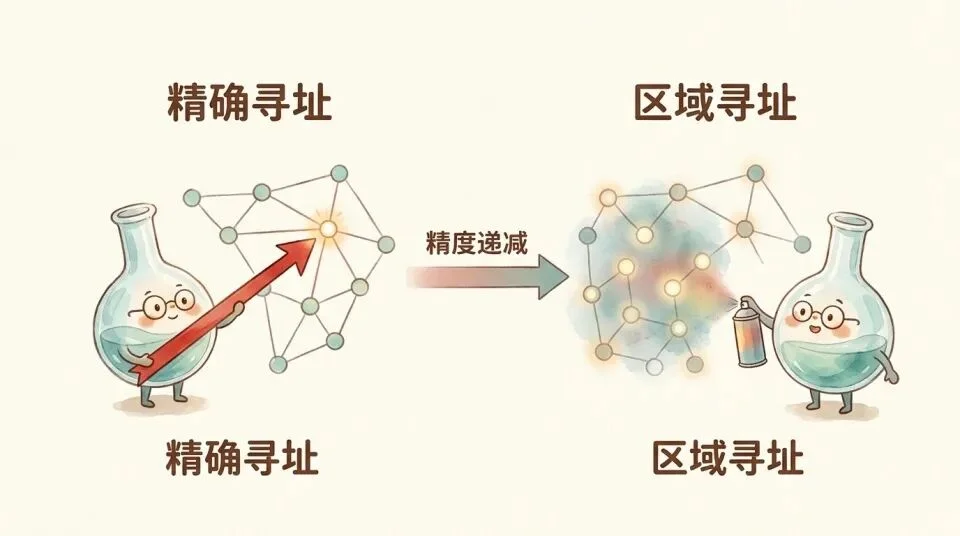
但 skill 里还有一类指令,用的是同样的机制,目标却模糊得多。比如「说人话」「多用短句」「用生活场景做比喻」「不要用成语」。
它做的事情和路由一样,都是给模型的知识检索加权。「说人话」把检索偏向口语化、日常化的语言模式,学术腔的模式被压下去。「多用短句」把激活扩散到模型短句式的语言模式上。「用生活场景做比喻」把取材范围推向日常生活的知识区域。
区别在于维度不同。路由激活的是内容维度(医疗知识 vs 法律知识),风格化指令激活的是表达维度(口语 vs 书面,短句 vs 长句)。路由的目标是一个地址,风格化的目标是一种氛围—。
同一个机制,精度差了一个量级。
风格化指令写得出来,也写得尽。它不需要编码新的判断逻辑,只需要给模型一个持续性的上下文偏置。模型本来就会写口语,只是默认状态下它不知道你想要口语。
风格指令一加上,激活就偏移了。
这一点其实之前的计算机学工作早就发现了。Rumelhart 和 McClelland(1986)在并行分布式处理(PDP)的研究中发现,在分布式网络里,知识是存储在跨节点的权重模式里的,这和LLM很像。而一个部分输入能通过约束满足恢复完整模式,这叫模式补全(pattern completion)。
换句话说,扩散激活的本质是参数寻址。Skill 写的那些风格指令,功能上是一组地址指针,指向模型权重里已经存在的模式。
但指针的精度有上限。这个上限来自三个方向。
第一,多条扩散指令之间不能矛盾。「说人话」和「保持专业感」同时出现,两条指令在拉模型往相反方向走。模型不知道该偏哪边,输出就开始摇摆。
第二,不能冗余。「简洁直接」和「多用短句」高度重叠,短句本身就是简洁的一种表现。重叠不一定有害,但它占了 context 空间却没提供新的激活方向,等于浪费带宽。
第三,也是最根本的。扩散激活的目标本身是模糊的。
「说人话」给出了方向,但这个方向的边界在哪里?口语化是微博体?朋友聊天?脱口秀?模型不知道,只能靠自己的先验去猜。
这在认知科学里是一个老问题了。维特根斯坦说概念的边界天然是模糊的,它们靠 family resemblance(家族相似性)维系,不是靠精确定义。
在这种情况下,最有效的方法是给模型一些范例。比如给它三段具体的文字,模型就有了锚点,激活空间一下收窄。
认知心理学家 Nosofsky(1986)的广义上下文模型解释了范例的作用。因为实际上人类去了解一个具体的类目知识时,并不是通过抽象定义去理解,而是借由存储的具体实例去感受的。这就是为什么「像这样写」通常比「写得简洁有力」更有效。因为范例携带的寻址信息比抽象描述多一个量级。
但即便有了范例,精度也有一个不可消除的上限。哲学家 Nelson Goodman 在 1955 年论证过,给定有限的范例,和这些范例兼容的可能模式其实是无限的。比如你给了三段口语化的范例,模型可以从中提取「用短句」「用口语词」「像朋友聊天」「别端着」。这些推理都和范例兼容,但它们指向的激活空间是不同的。
认知科学家 Posner 和 Keele 在 1968 年用实验验证过类似现象。让人从多个变体中学习一个类别,学习者最终形成的「原型」和任何一个具体范例都不完全匹配。它带着学习者自己的归纳偏差。
范例越多,原型越接近意图,但永远不会完全重合。
所以扩散激活的精度取决于抽象描述定方向,范例定锚点,两者结合能把激活空间收窄到可用的程度。但「完全精确」,理论上就做不到。
这是它和 L1 类确定性注入的根本区别。L1 写「如果 X 则 Y」,执行就是那个意思;扩散激活写「说人话」,执行出来大概是那个方向,但具体到哪里,取决于模型自己的先验和你给的范例质量。
归根结底,扩散激活的上限是自然语言作为寻址工具的分辨率上限。L1 的寻址是精确地址——「如果 X 则 Y」,指向唯一的执行路径。扩散激活的寻址是区域级的,「往这个方向」,能把模型推到正确的激活区域,但在区域内部的具体落点由模型自己的先验决定。范例能缩小区域范围,但语言指针的分辨率到此为止。
这就是为什么很多 skill 让人觉得「不完美但确实有用」——有用是因为寻址确实把模型推到了正确的区域,不完美是因为语言指针的分辨率在区域级就到顶了。
在这里,Skill的完美效力就已经下降了。
但更可怕的是,我们还有一种知识选择的方式,它甚至不能提供一个明确的激活区域。
如果你问一个老程序员怎么做代码审查,他可能会给出一个 checklist(检查清单)。比如检查命名规范、检查异常处理、检查边界条件、检查性能热点。这些都可以写进 skill。
但如果追问他怎么判断一个架构设计是好还是坏,他可能会说「就是感觉」。这并不是敷衍,而可能就是 expertise(专业技能)的一个重要侧面。
Skill 不擅长的,Utility
ACT-R 的第二种选择机制是 Utlitiy(效用)。它是一个决定哪条规则被优先执行的数值参数。
一个十年经验的医生和刚毕业的住院医师可能知道完全相同的诊断规则。但每条规则上的 Utlitiy 值截然不同。老医生知道什么时候该遵循指南,什么时候该推翻指南。
Utility 的本质是冲突裁决。
很多 skill 试图编码它,比如写上「优先安全性而非性能」。但写出来要么降级成 L1 规则,要么降级成扩散激活。
真正的 Utlitiy 是知道什么时候那个优先级应该翻转,而这个「知道」无法依靠另一条硬性规则。
Utility 写不进 skill,首先是因为维度爆炸。一个资深工程师做架构决策时,需要同时权衡性能、可维护性、团队熟悉度、交付时间、技术债、安全性和合规要求等十几个因素。
你写了「性能优先于可维护性」,但什么时候可维护性应该优先。答案取决于其他几个因素的具体取值。
这种组合你根本写不尽。
更根本的原因是,Utility 本身几乎不可表达。
医疗界从 1980 年代起,就把资深医生的诊断逻辑写成 CDSS(临床决策支持系统),规则覆盖率做到了 90%。但四十年后,医生推翻系统提醒的比例一直居高不下,而且多数时候推翻才是对的。
系统说「符合条件 A、B、C,建议用药 D」。医生看了一眼会说,不,考虑到他的年龄、合并症和上次用药反应,我用 E。
规则都对,但在具体情境下哪条规则应该让步,似乎才是诊断的核心。
Clancey 在 1985 年解剖 MYCIN 专家系统时发现了问题根源。提取出来的规则只是结论的表层,背后的因果模型和病理推理链条全部丢失了。规则变成了一堆孤立的 IF-THEN,失去了支撑它们的因果结构。
前文提到 linkerd-patterns 导致通过率下降 9.1% 的案例,很可能就是同一个问题的当代版本。
Hoffman 在 1998 年进一步指出,专家解释自己的决策时,给出的往往是事后合理化的版本,和实际认知过程有系统性偏差。这个现象被称为 knowledge acquisition bottleneck(知识获取瓶颈),知识工程领域折腾了二十年也没真正解决。
认知架构 SOAR 的「困境驱动学习」解释了为什么会这样。当系统遇到现有规则处理不了的情况时,会进入子目标空间搜索解决方案。找到后会把整个搜索过程压缩成一条新规则。
一个资深医生的临床直觉,就是几千次这种困境解决的压缩产物。
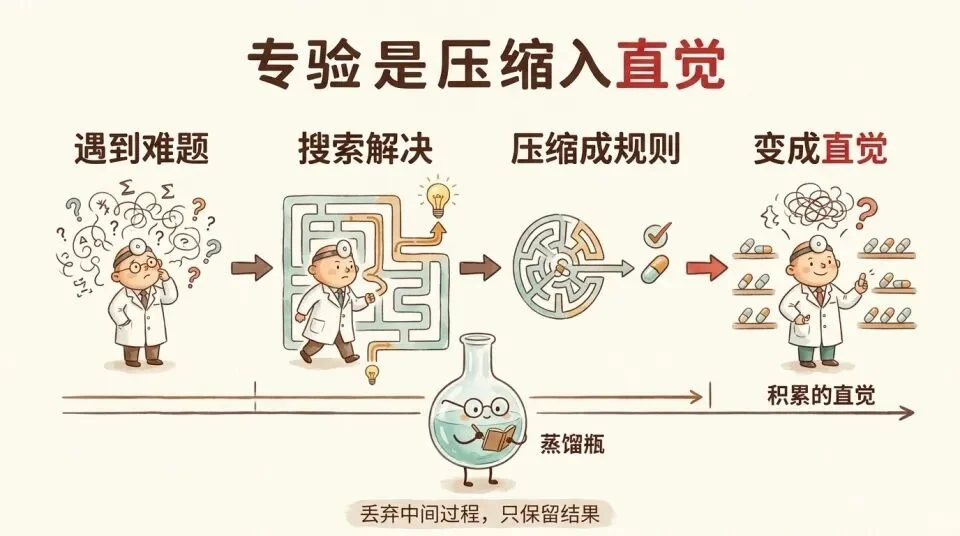
压缩的本质是丢弃中间过程只保留结果。所以专家自己也不记得背后的逻辑了。
Clark 和 Friston 的 predictive processing(预测处理)框架把这推到了更深一层。他们认为认知的本质不是「存储规则然后调用」,而是「层级化的预测误差最小化」。专家判断是一个深层生成模型的高效预测。
它不是「知道很多规则然后快速检索」,而是整个大脑模型已经内化了那个领域的统计结构。
这意味着 Utility 从来就不是离散规则的复杂组合,而是连续的概率推理。
试图把它写成 IF-THEN,就是在走 symbolicism(符号主义)的失败老路。
之前提到的SkillsBench 的U型曲线就是这一逻辑造成的。Comprehensive 试图面面俱到地编码 Utlitiy,结果反倒使得Skill愈发难用。
这是因为粗糙的语言描述覆盖了模型预训练中更精细的隐式权重,反而让表现更差。
打个比方,一个新同事来请教怎么做代码审查。
你告诉他检查命名、异常处理和边界条件,他会做得不错。但如果你进一步告诉他,性能通常比可读性重要,但涉及核心路径时可读性优先,除非是高并发场景性能又优先,但如果团队新人多可读性还是优先。
他大概率会原地懵圈。
因为充满条件分支的权衡在语言层面被拍扁了,反而干扰了他自己的直觉。
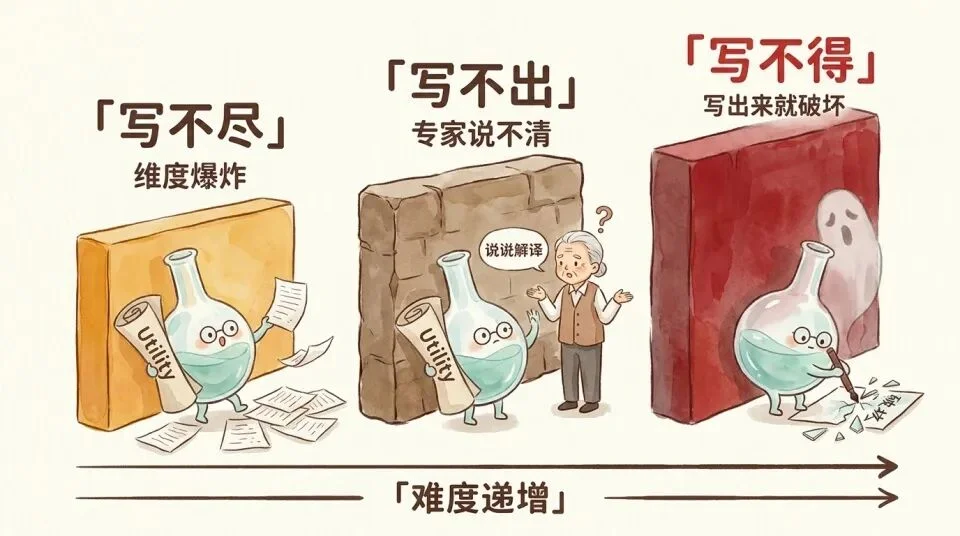
Utlitiy 写不进 Skill,不只因为写不尽,更因为写不得。
Utility 写不进 skill,上面提的可能是因为「写不尽」维度太多、穷举不了;「写不出」,人的语言表述Utility就有问题。
但更根本问题可能是Utitliy本身就是「写不得」,写出来这个动作本身,就可能破坏它的工作方式。
Polanyi 在 1966 年提出了一组概念,叫 focal awareness(焦点意识)和 subsidiary awareness(辅助意识)。
比如你骑自行车时,焦点意识在路面和方向上,辅助意识在平衡、踩踏节奏、风向和身体重心上。
你没有在「想」这些事情,但身体在同时整合所有信号来维持骑行。
Polanyi 观察到,如果把辅助意识的内容强行拉到焦点位置,整合往往会被破坏。
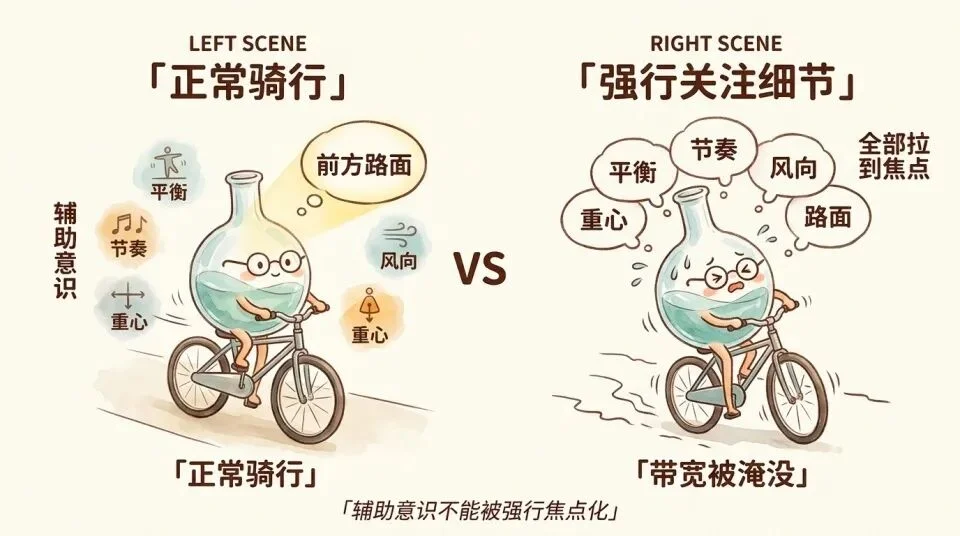
让一个钢琴家在演奏时关注自己每根手指的运动,他的演奏会立刻变形。
让一个资深医生在诊断时逐条检查自己到底在用哪些规则、每条规则的权重是多少,他的诊断准确率大概率会下降。
但 Polanyi 的观察停在了现象层面,他说了「会破坏」,没有解释「为什么会破坏」。
认知心理学家 John Sweller(1988)的认知负荷理论提供了一个可量化的机制。
Sweller 发现,学习材料的难度不取决于信息量,而取决于 element interactivity(元素交互性)。也就是需要同时在工作记忆中持有并协调多少个元素。
一条独立的 IF-THEN 规则交互性很低,很容易被吸收。虽然 Utility 判断本质就是高元素交互。你必须同时权衡十几个互相影响的因素,但在被压缩的经验里,你调用Utility其实可能只是一个元素,如果写成文字展开来,语言的线性结构就会放大元素的数量。你不得不一条一条顺序读,却需要同时记住所有条目才能理解任何一条。
这就是 Polanyi 观察到的现象背后的带宽机制。当你强行把已经压缩过的一整套 Utlitiy 判断展开成语言时,大脑带宽就被淹没了。
效果就和一个突然接收了太多新规则的实习生一样,手忙脚乱,反而更差。
Skill 的形式是自然语言,而大语言模型的带宽同样有限。强行把本该压缩在权重里的经验展开成语言,只会造成混乱。
而在LLM系统中,更类似于Utility这种感觉的,其实是参数权重,它不是以语言承载,但可以用语言表达。速度快,更偏直觉。
因此,想解决 Utility 的问题,可能最后还是要回到权重层面。Skill 根本处理不了它。
Skill的精度阶梯
上面提到的人类知识形式成了一个清晰的精度阶梯,也是 skill 能力的递减曲线。
L1(生产性规则 + 陈述性知识路由)精确且无歧义。「如果 X 则 Y」,写出来就是那个意思,模型执行就是那个结果。这是 skill 最可靠的地带。
L1.5 是扩散激活加范例,方向正确但边界受限。范例越多越准,但受 Goodman 欠定性约束,永远有残余模糊。这是 skill 让人觉得「不完美但确实有用」的地带,也是用户「感觉 AI 变成了那个人」的主要来源。
L2,则是Utility,不可编码。写出来就变性,降级为 L1 或扩散激活。Polanyi 说的「不可言说」,精确讲就是这个,不是你不够努力去写,是写这个动作本身就改变了它。
Skill 的有效性沿着这个阶梯递减。
这个精度阶梯的边界不只是工程约束。这更像是一个偏认识论的边界。人的经验中可以被语言表达的部分和不可以被语言表达的部分,分界线有结构性的成分。
这不完全是模型还不够强的问题。
这说明,Skill这种特定形式,有自己清晰的射程。
05
四种策略,四张面孔

面对这条精度阶梯,不同的 Skill 作者做出了截然不同的选择。
第一种,承认边界。
优秀的写作辅助类 Skill 会在末尾声明,所有内容都是建议而非规则。这不是客套,这是深刻的设计决策。
写作是典型的 L2 密集型工作。Skill 能提供的是 L1 到 L1.5 层面的脚手架,比如搜索范围、语言风格和范例锚定。
但最终的选题、立意和节奏的判断,必须交还给人。
第二种,退守 L1 的纪律。
拥有 14.9 万颗星的 superpowers 项目,其核心 Skill 只有一条 checklist(检查清单)。即,做任何改动前先记录当前状态。
它不教你怎么做判断,只确保 L1 级别的纪律被严格执行。
这就像手术室里的规矩。它不教医生怎么做手术,但能大幅减少忘记消毒的概率。
第三种,假装没有边界。
前文提到的同事 Skill 就是这一类。它的目标是「蒸馏一个人」。
它不只是要工作流程,还妄图打包思维方式、说话风格和判断倾向。
它搭了五层结构。Profile(基本信息)、Cognition Style(认知风格)、Expression Pattern(表达模式)、Decision Tendency(决策倾向)和 Correction Mechanism(纠错机制)。
下载一个「罗翔.Skill」,AI 就会用罗翔的说话方式跟你对话。效果呢?用户普遍的反馈是,语气风格很像,但「感觉还是差点意思」。
这个反馈其实非常精确。如果用前面的三种机制拆开看,五层结构里每一层在做的事情完全不同。
基本信息编码的是基本事实,比如「张三,前端工程师」。这是纯粹的陈述性知识注入,属于 L1,效果极其稳定。
认知风格是两种机制的混合。「倾向于先看数据再做决定」可以写成 IF-THEN,这是 L1。但「喜欢用类比解释复杂概念」不是规则,它是扩散激活。它把模型的检索偏向类比式的表达模式。
表达模式几乎全是扩散激活。比如「说话简洁直接」「喜欢用反问」。这些不是在告诉模型做具体步骤,而是在把输出分布往某个语言风格区域推。这恰恰是体感效果最好的部分。用户觉得「AI 变成了那个同事」基本就靠这一层。
决策倾向是在尝试用语言编码 Utility。比如「倾向保守方案」「重视用户体验超过技术实现」。但什么时候保守?保守到什么程度?什么条件下这个优先级会翻转?这些信息是全部缺失的。
这让它成了五层中最弱的一环。
纠错机制则是用 L1 的 IF-THEN 规则兜底扩散激活的偏移。比如「如果开始说太多术语,提醒自己用白话」。本质是当风格偏移时用硬规则拉回来。
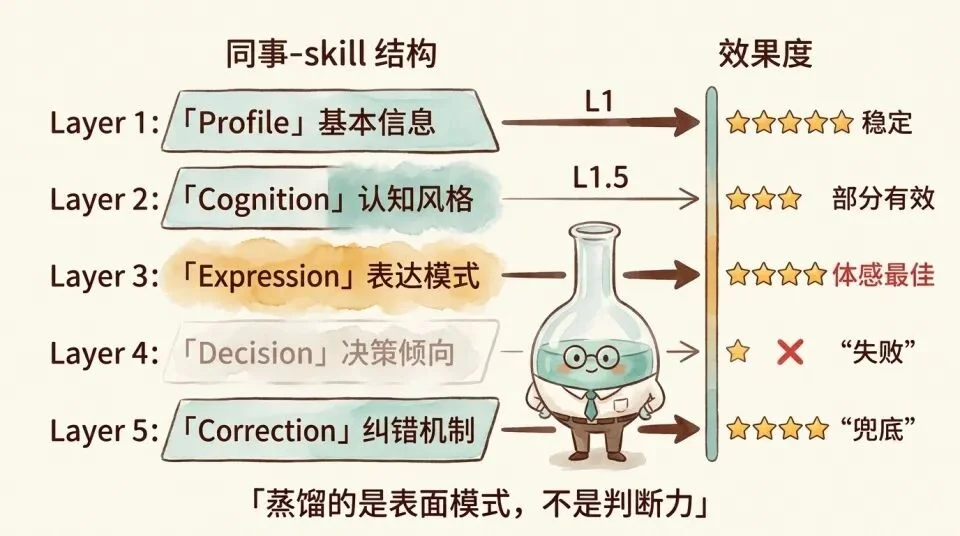
拆完这五层,我们就能清楚的看到,同事 Skill 看起来好用,是因为L1层的知识和部分L1.5层的定位还比较准确。而「差点意思」精确地来自决策倾向的 Utility 编码失败。
如果你期待罗翔面对新法律难题时怎么「想」,怎么权衡法条和道德直觉的张力,在两个都有道理的解释之间怎么取舍。
这套五层结构帮不了任何忙。因为这些判断来自罗翔几十年法学训练中积累的 L2 直觉。
当然如果一个人,确实缺乏足够的想法,其行为完全按照机械的条框处理,那么五层结构或许可以接近完美地蒸馏他。
第四种,从反方向说明边界。
anti-distill (反蒸馏技能)是所有skill中,最值得玩味的一个。
它不是在创建 skill,而是在破坏 skill。但它破坏的方式本身,就暗示了某种分层结构。
具体的执行方法是一条 L1 规则。这是一条精确的 IF-THEN 规则,模型拿到就能执行。
anti-distill 把它净化成「缓存使用遵循团队规范」。
表面上这还是一条规则,但所有具体内容都被抬升到了 L2 的抽象层。
「团队规范」是什么?哪些场景下可以例外?「遵循」到什么程度?这些全靠执行者自己判断。
在技术上这是正确的,功能上这毫无用处。
它设了三个档位。80% 档留下大部分具体规则,只抬升少数关键的。40% 档把几乎所有 IF-THEN 都替换成「遵循规范」「根据情况判断」「参考最佳实践」这类模型根本执行不了的空壳。
这三个档位本质上就是在调节,要把多少 L1 内容抬升到L1.5或L2。
她不需要删除信息。只需要把信息从高精度端推到低精度端,从 L1 推到模糊的扩散激活,从精确的路由推到空泛的指向。Skill 就彻底变成了一张废纸。
06
几分之几
分析到现在,我们终于可以尝试回答标题的问题了。需要先说明的是,下面的数字是基于文献数据的粗略估算,不是精确测量,请按「量级」来读。
纯 L1 任务(比如诊断编码、工具调用、公式计算)的覆盖率在 80% 上下。扩散激活能带来额外的风格和取材精度,但这受限于范例质量和指令兼容性。Utility 层面的边际收益从 Detailed 之后就开始递减,到 Comprehensive 甚至为负。
SkillFoundry 在科学发现基准 MoSciBench 上的测试也印证了这一点。通过率只从 43.85% 升到 53.05%。在涉及假设生成、实验设计这类偏 Utility 的工作时,Skill 的提升远不如纯 L1 任务那么显著。
但应用到现实,答案取决于你用什么尺子去量。
如果用「时间」来量。一个人每天 8 小时里有多少可以被 Skill 覆盖。粗略估算在 60% 到 80% 之间。
大部分人大部分时间其实都在做 L1 的事情。按流程操作,按规范检查,按模板填充,按清单执行。
当然,如果是高度创意化的工作,这个比例会落到区间下沿,甚至更低。
但如果用「价值」来衡量。工作产出里有多少价值能由 Skill 覆盖的部分产生。
粗略估算只有 30% 到 40%。因为价值分布高度不均匀。那些不能被 Skill 覆盖的 20% 的时间里做的事,往往才是核心。
比如判断一个架构方案的长期影响,在两个都合理的设计之间做取舍,决定什么时候该果断偏离标准流程。
这些判断的价值占比可能高达 60% 到 70%。
有人会说 30% 这个数字太悲观了,已经有从业者分享过「80% 体力活被一键清空」的实战案例。
这两者其实没有矛盾。
80% 讲的是时间维度,清空的基本都是 L1 的活儿。但判断这份数据值不值得深挖,最终仍然是人自己做的。
80% 的时间节省和 30% 的价值覆盖,其实是同一件事的两个维度。只是第一个维度更容易被直观感受到,也更容易被当成营销卖点。

07
Skill 有界,而蒸馏无尽
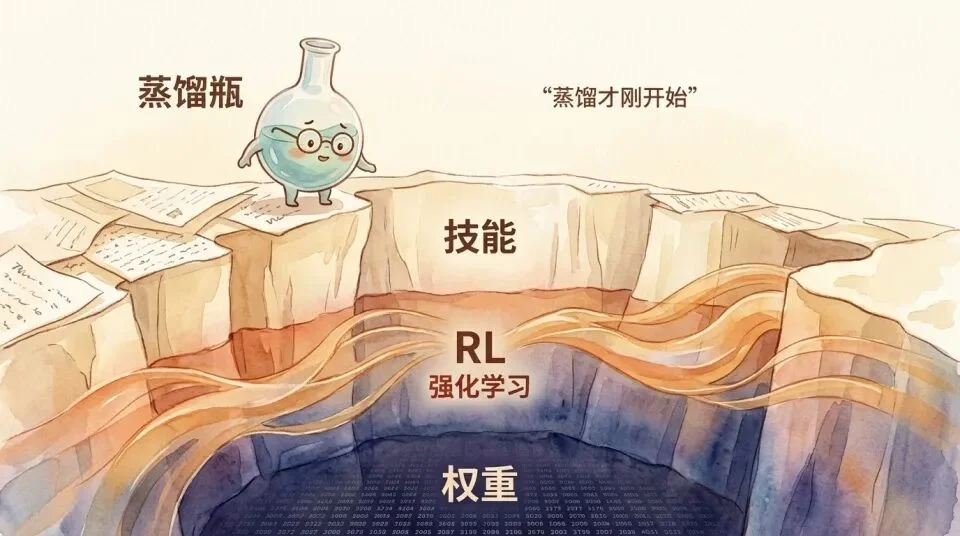
如果我们停在这里,结论似乎还不错。
人类保住了核心判断力(L2),Skill 只不过是帮我们清理流程残渣的数字吸尘器。
但对于AI而言,这并非它的极限。Skill 的失效,仅仅证明了自然语言作为一种蒸馏介质的局限性。
Polanyi 说的没有错,隐性知识一旦被强行拖拽进语言的焦点,就会破碎。当我们试图用 IF-THEN 来描述那种在千万次实践中凝结而成的直觉时,语言的低带宽和离散性,注定了这场蒸馏只能是粗糙的。
但这并不意味着蒸馏本身碰到了南墙。
Skill 只是切片式蒸馏的第一刀,最浅的那一层。
当你无法用语言写出,如何平衡系统架构的长期技术债与短期交付压力时,Skill 确实无能为力。
但在 Skill 之后,更深层的蒸馏机制正在悄然接管。
既然语言写不出连续的权重,那就跳过语言,直接蒸馏行为。
RL(强化学习)和 Preference Alignment(偏好对齐)会直接观察专家在复杂决策下的最终选择。系统会用海量参数去隐式拟合那条你根本无法言说的 Utility 曲线。
甚至,随着模型在 inference(推理期)算力的不断解锁。那些人类脑海中转瞬即逝的、甚至自己都未能意识到的思考过程,正在被拆解为可以被奖励信号塑造的 token 轨迹。
模型不再需要你用语言把它教会。
它通过自我探索和试错,自己就能在那些无法被 Skill 化的暗礁中找到航线。
这就是问题的核心。
Skill 这种形态有其清晰的射程。它受限于我们的表达能力,受限于显性规则与隐性知识之间的天然鸿沟。我们用 Skill 蒸馏掉的,确实只有那能被说出口的几分之几。
但蒸馏是一个无尽的进程。
第一代工具要我们的流程。第二代系统要我们的决策日志。未来的架构要的,是我们在复杂博弈下的隐性偏好。
那条区分 L1 和 L2 的护城河,并不像我们想象的那么坚固。
我们现在确实能够通过防蒸馏工具,把具体的步骤抬升成一句模糊的「遵循最佳实践」,以此来宣告 AI 的无能。
但在不远的将来,AI 将不再需要你告诉它最佳实践是什么。
蒸馏不会终止于 Skill,它才刚刚开始。
面对一个试图把人彻底参数化的系统。理解自己身上哪些部分已经被写成了代码,哪些部分正在被拟合成权重。
这或许才是我们这些 AI 时代的人类,需要面对的第一个真正的问题。
本文作者:彭超 OneOneTalk CTO & 联合创始人 微信pengchaovista;博阳 微信haoboyang001 如有兴趣讨论,欢迎添加微信沟通。
文章来自于微信公众号 "腾讯科技",作者 "腾讯科技"


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
