# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
导读
过去一年,整个 AI 行业都在告诉你:让模型多想一会儿,答案更好。但一批 GPT-5.5 重度用户刚刚用实战经验打了所有人的脸——thinking 开低、甚至不开,反而更稳更快更能打。
更绝的是,做完一个任务就必须清上下文,否则下一轮输出直接"变脏"。近 400 人点赞、5.5 万人围观的帖子背后,藏着一个让人细思极恐的结论:
模型已经强到不需要"拉满思考"了,真正拉开差距的,是你会不会用。
一条推文,炸了整个开发者圈。
几天前,开发者 Mateusz Mirkowski(@llmdevguy)在 X 上丢出一条使用心得,短短几句话就收获了近 400 个赞、314 个收藏、5.5 万次浏览。
他说了什么?
"Use GPT-5.5 with low or even no thinking mode."
「用 GPT-5.5 的时候,thinking 开低档,甚至干脆别开。」
"Once you're done with a task, clear the context. This is important with GPT-5.5."
「一个任务做完,立刻把上下文清掉。这对 GPT-5.5 非常重要。」
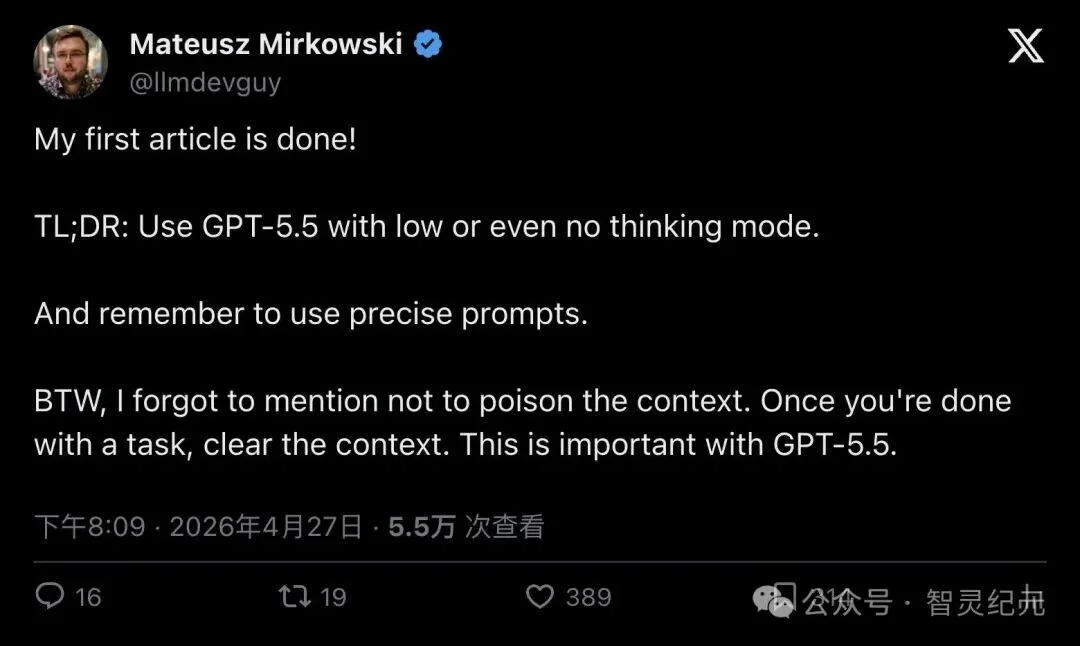
▲ Mateusz Mirkowski 的原帖,近 400 赞、5.5 万次浏览
这两句话放到一年前,大概会被当成反智言论。毕竟,从 o1 到 o3 再到 GPT-5,整个行业的叙事一直是:推理预算越高、thinking token 越多,模型就越强。
但现在,一批最早上手 GPT-5.5 的重度用户,正在用真金白银的使用时长告诉你:这个逻辑,到了 GPT-5.5 这代,开始失灵了。
这件事听起来反直觉,但仔细拆开看,逻辑其实很清晰。
Mirkowski 的帖子里还有一句容易被忽略的话:"And remember to use precise prompts."——别忘了用精确的 prompt。
这说明他的意思并非"把模型调傻"。恰恰相反,减掉不必要的推理过程后,模型更依赖你给出的精确指令,输出反而更干净、更可控。
想想早期用 GPT-3.5 的时候,大家疯狂加 "Let's think step by step",是因为模型本身容易断逻辑、跳步骤、胡说八道。但到了 GPT-5.5 这个级别,很多任务里模型已经能靠更紧凑的内部能力直接交付高质量结果。
强行拉长推理过程,反而会让输出变得啰嗦、绕弯、风格发虚、把简单任务做复杂。
尤其是这几类任务,低 thinking 的优势特别明显:
换句话说,GPT-5.5 已经强到很多任务不需要把思考过程拉满了。过度用力,只会把输出搞砸。
如果只有 Mirkowski 一个人的体感,你可以当作个例。但问题是,更多人已经在验证同一件事。
知名 AI 评测人 Matt Shumer 在他的 GPT-5.5 深度评测里写道:
"You can seemingly get more out of less intense thinking modes than before."
「和以前相比,你现在能从更低强度的 thinking 模式里榨出更多效果。」
"the lower modes feel really good now"
「低档位模式,现在用起来真的很顺。」
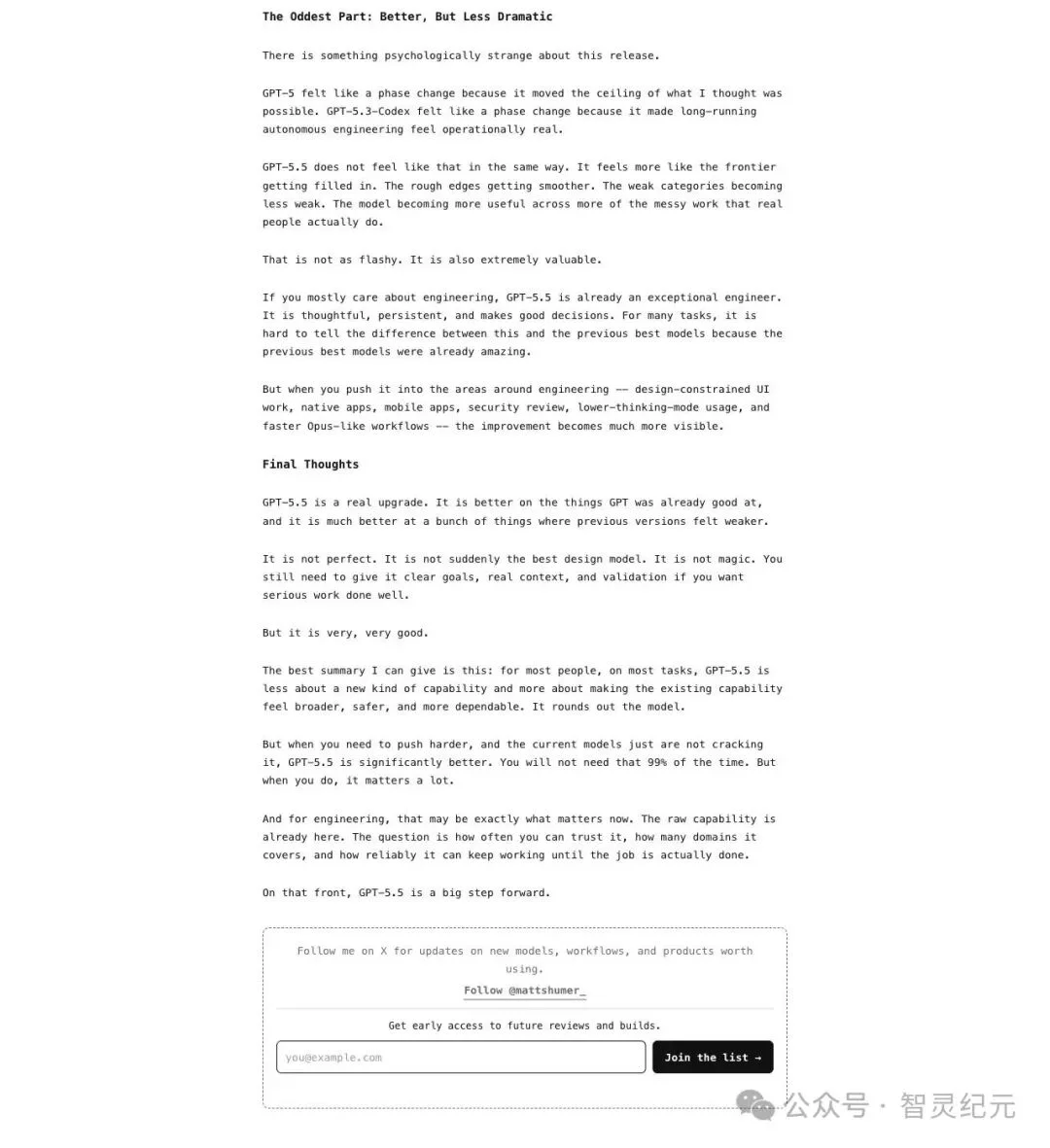
▲ Matt Shumer 的 GPT-5.5 评测,确认低 thinking 模式"比想象中更能打"
Shumer 的口径比 Mirkowski 温和一些——他没有说"永远别开高 thinking",而是指出:低强度模式比绝大多数人预想的更能干,很多人已经在这些模式下完成了高质量的实际工作。
但他也强调:真正严肃的任务,仍然需要 "clear goals, real context, and validation"——明确目标、真实上下文、反复验证。
这恰好和 Mirkowski 的经验形成了互补:大部分日常任务,低 thinking 就够了;真正的硬骨头,高 reasoning 仍然有它的价值。
关键在于,thinking 模式不再是"越高越好",而是像一个旋钮,要按任务类型来调。
Mirkowski 帖子里的第二个重点更容易被低估:不要污染上下文。
这话听起来很像玄学,但 OpenAI 社区里的真实案例能告诉你它有多现实。
有用户在 OpenAI Community 发帖吐槽:他用 ChatGPT 管理两个长期工作房间,结果两个房间都变得极度缓慢。
"each reply took OVER 10 minutes"
「每次回复都要等超过 10 分钟。」
"It feels like the system is repeatedly 'rehydrating' all past messages"
「感觉系统在反复把之前所有消息重新灌回上下文里。」

▲ OpenAI 社区用户反馈:长对话导致极慢,像在反复重建上下文
更扎心的是,这位用户说他不想新开 chat,因为新开就意味着丢掉所有积累的工作流逻辑、风格模式和历史修正。
这是一个两难:继续用,越来越慢、越来越脏;新开一个,之前的积累全部清零。
这种痛苦催生出了一套越来越流行的应对策略。
科技博客 CompanionLink 在一篇关于 ChatGPT 长对话变慢的文章里,把大量用户已经默认在做的动作写得很直白:
"One common way to fix the slowdown is to end the current chat and start a new one."
「一种常见的补救办法,就是结束当前 chat,重新开一个。」
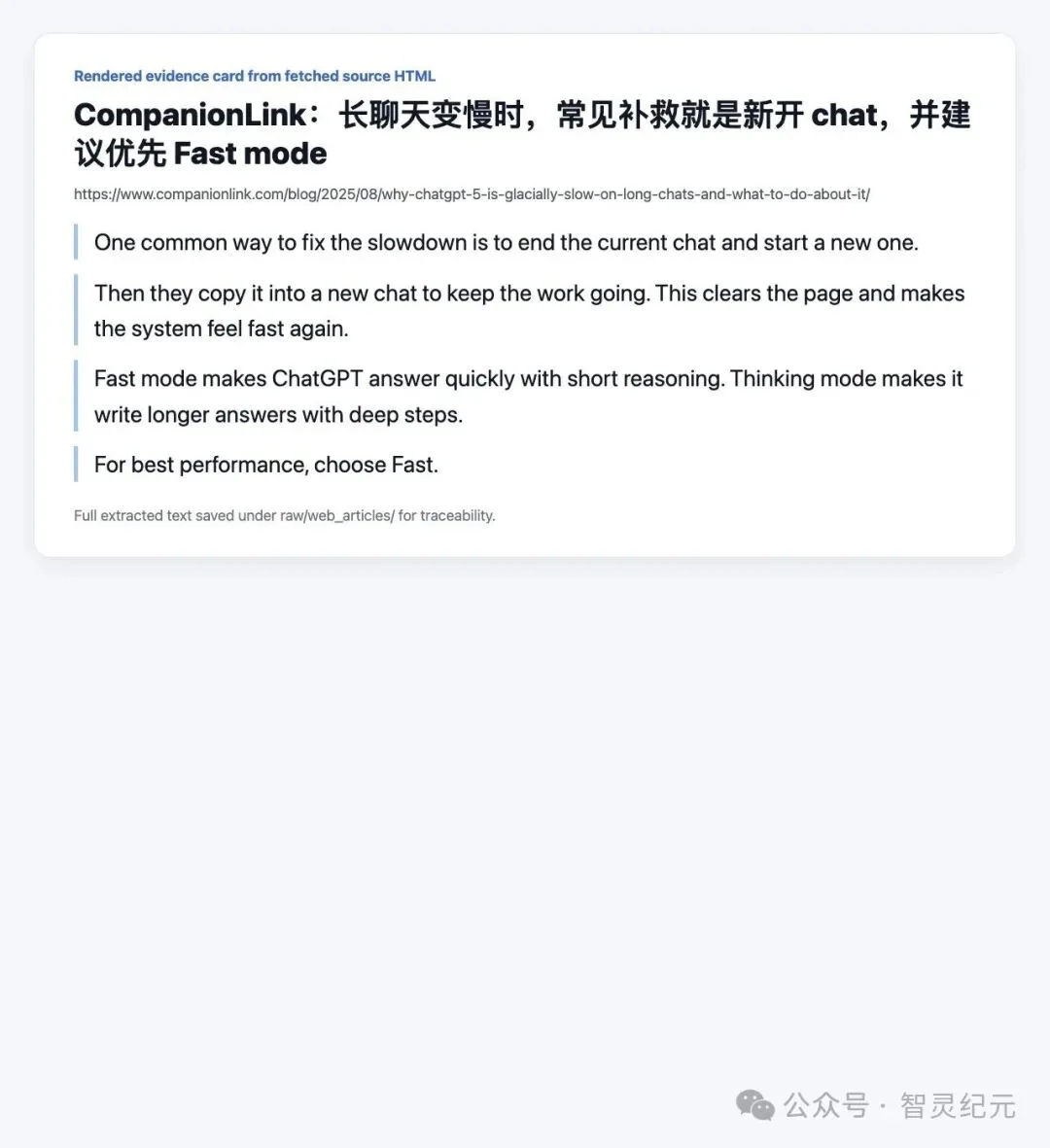
▲ CompanionLink 总结:长聊天变慢时,常见补救就是新开 chat,优先 Fast mode
他们还指出:Fast mode(快速模式)倾向短推理、快响应;Thinking mode 倾向长回答、深度展开。如果你优先要速度和响应性,选快模式。
这不是某个人的偏好,这是一整套正在成型的工作流共识:
1.日常任务用低 thinking / Fast mode,别让模型过度展开 2.做完一个重任务就新开 chat,别让旧上下文拖脏下一轮 3.prompt 写精确,减少推理依赖,让模型直接执行 4.真正的硬问题再开高 reasoning,别浪费在不需要的地方
说到底,GPT-5.5 带来的变化,核心并非"模型变笨了"。
恰恰相反——模型已经强到很多任务不需要展开那种很重的推理轨迹了。
过去,你需要 thinking mode 是因为模型不够聪明,得靠显式推理来弥补。现在,GPT-5.5 的隐式能力已经足够强,很多场景下直接给出结果就是最优解。
强行让它"多想一会儿",就像让一个经验丰富的老司机每次变道前都要停下来画受力分析图——多余,而且影响发挥。
当然,这并非 OpenAI 的官方最佳实践,也没有严格控制变量的论文来盖章。"上下文污染"背后可能混合了至少三层因素:模型推理残留导致的风格串味、超长上下文本身的效果衰减、以及 ChatGPT 前端在长线程里的性能问题。
但用户的体感是一致的:旧上下文越积越重,模型越来越慢、越来越跑偏。至于背后到底哪一层在起主要作用,对普通用户来说并不重要——重要的是,"做完就清场"确实管用。
回过头看,这件事最值得记住的一点是:
当大家还在迷信"让 AI 多想一会儿"的时候,真正的高手已经在做减法了。
GPT-5.5 强到一定程度后,真正稀缺的能力已经不再只是"多想"。什么任务该 deep think,什么任务该 fast 直出,什么时候做完就该清场——这套判断力,才是接下来拉开人与人差距的东西。
从这个角度讲,GPT-5.5 真正改变的,可能并非 AI 的能力上限。
它改变的,是谁能把这个能力用到极致。
文章来自于微信公众号 "智灵纪元",作者 "智灵纪元"


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
