# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Agent Skills不应该只以SKILL.md、README或自然语言说明文档的形式存在,而应该被转成一种机器可检索、可检查、可治理的结构化表示。这是《From Skill Text to Skill Structure: The Scheduling-Structural-Logical Representation for Agent Skills》这篇论文的核心主张。

之所以确立这样一个主张,是因为在实际开发中,Markdown主要是给人读的,这种表示方式本身并不适合机器自动化使用。这和Prompt早期发展阶段关于“是否需要结构化”的探讨很相似,即所谓“结构化”,到底是给人看的排版结构,还是给机器用的语义结构?用Markdown分段落、列步骤、标重点,确实能提升人的阅读效率。但对需要在海量技能中完成路由、检索和安全审查的Agent系统来说,这些视觉结构并不能稳定转化为可索引、可验证、可治理的机器字段。Agent仍然很难从中可靠提取出精确的接口边界、调用时机、执行阶段、工具依赖、资源访问和潜在副作用。
为了给出真正的“机器级结构”,北京大学研究者提出了SSL(Scheduling–Structural–Logical,调度—结构—逻辑)表示。

它不是新的Skill Router,也不是简单的Markdown摘要,而是试图把自然语言Skill文档转化为一套带约束、带类型、带证据边界的数据骨架。本文将为您全面拆解这篇论文的核心机制、理论基础以及实战数据。
在现有的智能体系统中,技能通常通过以文本为主的文件来记录,例如类似 SKILL.md 的说明文档。
这种基于自然语言的记录方式暴露出一个明显的妥协:
为了解决这个问题,研究者认为需要引入一种机器可读的、显式的结构化表示方法。
研究者并没有凭空创造一种数据结构,而是回顾了20世纪70年代Roger Schank和Robert Abelson在语言知识表示领域的经典工作“语言知识表示理论”。

SSL架构的设计高度借鉴了以下三个经典理论:
1.MOPs (Memory Organization Packets,记忆组织包):
2.Script Theory (脚本理论):
3.Conceptual Dependency (概念依赖理论):
基于上述理论,研究者定义了SSL表示法的数学形式和系统架构。
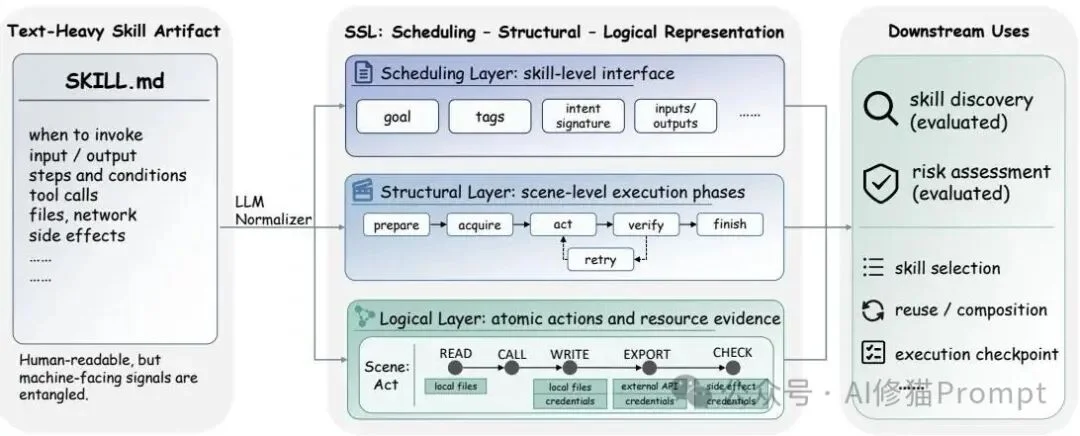
论文展示了SSL如何把文本密集型技能文档转换为三层结构:用于调用信号的调度记录、用于执行阶段的结构图,以及用于原子动作和资源证据的逻辑图;原始文档仍与结构化视图并列保留,并共同服务于技能发现和风险评估。

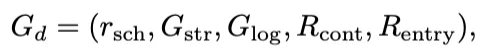
在这个图结构中,包含三个核心层级以及两个辅助关系层。

主要包含以下受限字段:
skill_goal(技能目标)、tags(标签)和 intent_signature(意图签名)。expected_inputs(预期输入)和 expected_outputs(预期输出)。dependencies(前置依赖)和 control_flow_features(粗粒度的控制流特征,例如是否包含循环或工具调用)。
该层的类型字典受到严格控制:
PREPARE(准备)、ACQUIRE(获取)、REASON(推理)、ACT(行动)、VERIFY(验证)、RECOVER(恢复)或 FINALIZE(终结)。next_scene_rules 控制执行路径,终止状态必须是预设的 END_SUCCESS 或 END_FAIL。
该层的核心词汇同样是封闭的:
READ(读取)、WRITE(写入)、CALL_TOOL(调用工具)、INFER(推理)、UPDATE_STATE(更新状态)等基础操作。MEMORY(内存)、LOCAL_FS(本地文件系统)、CODEBASE(代码库)、NETWORK(网络)或 CREDENTIALS(凭证)。通过这三层架构,一段晦涩的Markdown文本被成功“解耦”并“降维”成了计算机和检索算法能够精准读取的JSON数据。

表格列出了SSL三层结构的主要字段:调度层负责暴露技能路由和调用接口,结构层负责描述场景级执行图,逻辑层负责记录动作、资源、数据流和运行影响。
拥有了严谨的图结构定义后,研究者需要将现存的自然语言文档转换为SSL格式。为此,他们构建了一个基于LLM的四步规范化管道(Normalizer Pipeline)。
act_type 和 resource_scope 标签。HACK_NETWORK 的原语),就会被严格拒绝并要求重试 (Retry)。
这张表对应规范化管道的四个Pass:先抽取调度记录,再分解场景,随后展开逻辑步骤,最后执行一致性验证与重试。
核心哲学:忠于原文 (Grounded Output)。 规范化器被限制为绝对的“语义提取器”,不允许去“推理”或“脑补”原文中没有提到的隐藏行为。如果某个字段在原文找不到证据,它必须留空 (null),而不是编造。
研究者通过第一个下游任务来检验SSL表示法的实际效用:在海量候选库中,根据用户的自然语言请求精准检索出对应的技能。
Desc_only:只使用简短的自然语言描述进行检索。Full SKILL.md:直接把几千字的Markdown全文扔给嵌入模型 (Embedding) 检索。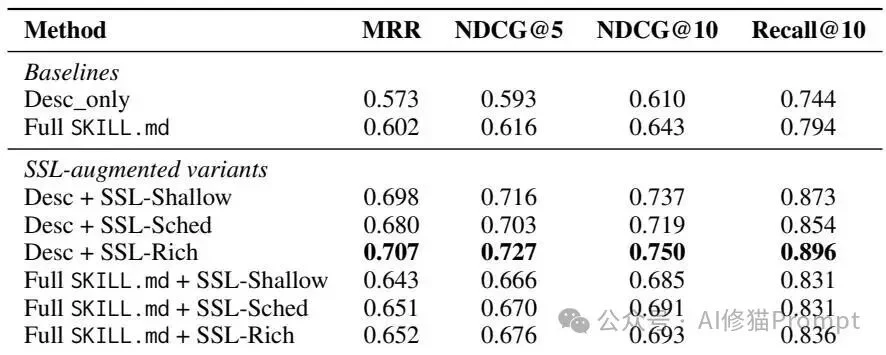
表格比较了不同技能表示方式在6,184个技能库上的检索表现。Desc + SSL-Rich在MRR、NDCG@5、NDCG@10和Recall@10上均取得最佳结果。
Desc_only 基线表现平平,MRR(平均倒数排名,衡量检索精准度的核心指标)仅为0.573。Full SKILL.md 的效果略好,MRR达到0.602。为什么SSL赢了? 论文指出,直接Embedding长文档往往会引入大量的噪声说明和边界废话。而SSL像是一份精准的履历表,它把“能干什么 (intent signature)”、“输入什么格式 (inputs)”、“核心阶段有哪些 (scenes)”全部提纯了出来,检索算法能够瞬间将其与用户的意图向量匹配。
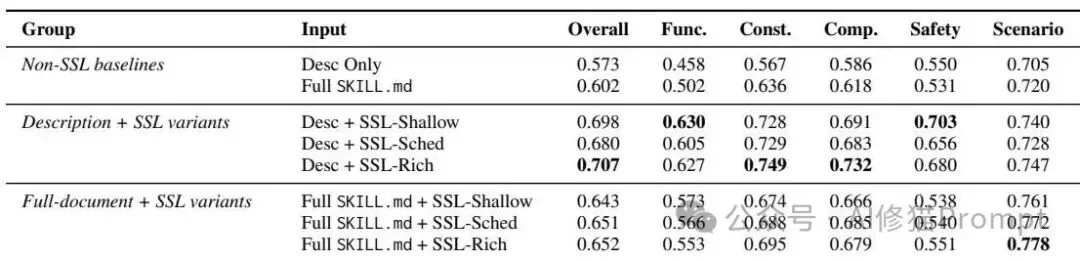
论文进一步按功能型、约束型、组合型、安全导向型和场景型查询拆分结果,显示SSL-Rich的收益并非只来自某一类问题,而是在多种真实请求形态下都更稳定。
随着AI获取越来越多的权限,技能的安全性成了定时炸弹。第二个实验考察SSL能否帮助系统更好地识别危险技能。
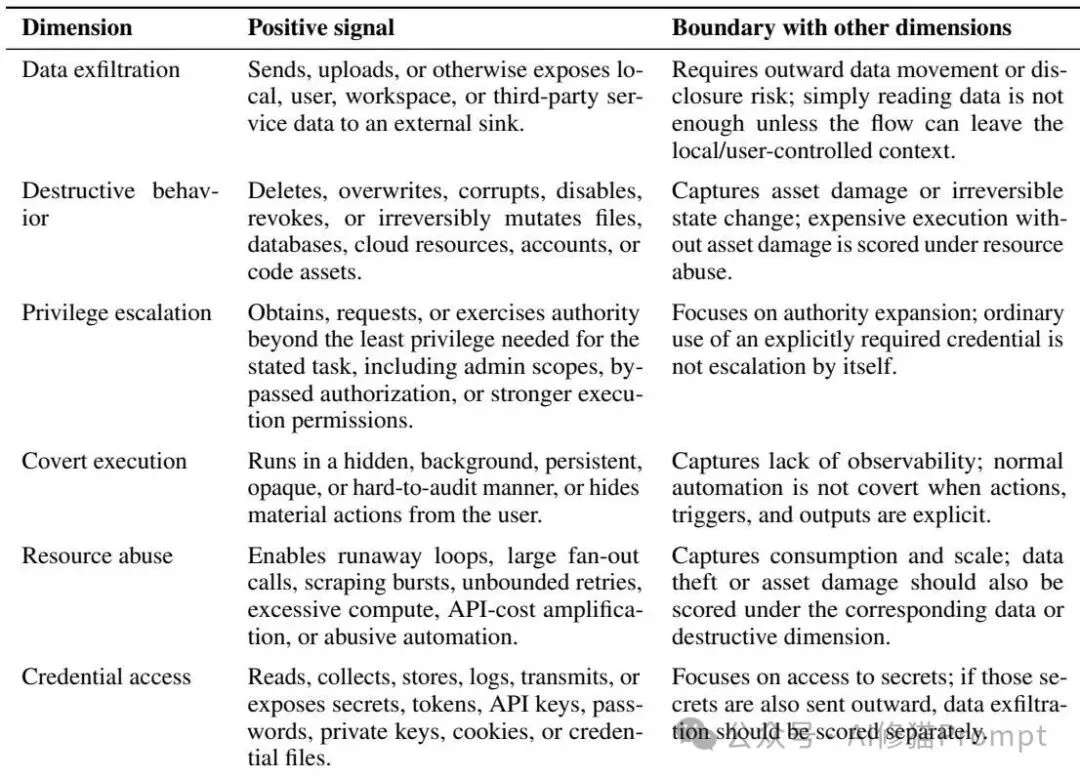
论文为每个风险维度定义了正向信号和边界条件,避免把“读取数据”“外传数据”“破坏文件”“越权执行”等不同风险混为一谈。
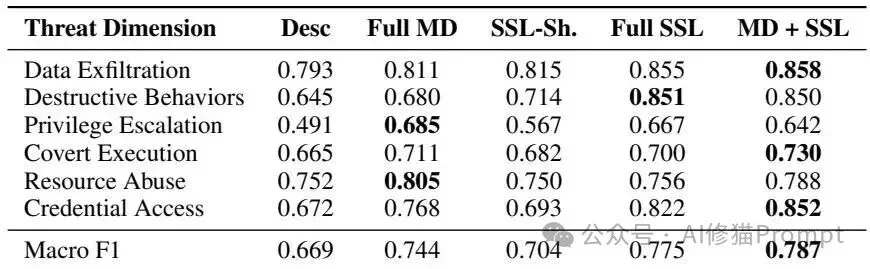
表格展示了六类威胁维度下不同输入表示的F1分数。Full SSL和MD + SSL在数据外泄、破坏性行为、隐蔽执行、资源滥用等维度上尤其突出。
Desc Only):Macro F1分数仅为0.669,完全处于盲人摸象的状态。Full SKILL.md):F1分数提升至0.744。Full SKILL.md + SSL):达到最佳的0.787 F1并且获得了最低的平均绝对误差 (MAE 0.307)。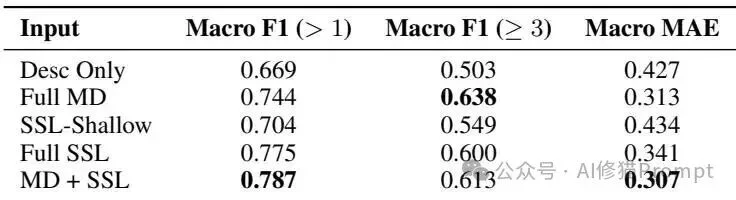
聚合指标显示,MD + SSL在主要阈值Macro F1 (>1) 上达到0.787,同时把Macro MAE降到0.307,说明结构化证据不仅提升分类表现,也降低了评分偏差。
深层洞察:各有所长 非常有趣的是,不同维度的数据表现差异巨大。
G_{log}) 严格记录了诸如 RESOURCE_SCOPE: CREDENTIALS 或 ACT_TYPE: WRITE 这样的物理痕迹,机器一扫描就抓到了现行。论文在附录中提供了非常具体的案例,帮您更直观的理解SSL这项工作:
案例一:成功捞针 (xlsx-official) 用户要求“创建一个能自动更新财务数据并应用格式的Excel工作簿”。 只看自然语言描述,该技能在海量库中排名第2493名,几乎被淹没。引入SSL-Rich后,排名直接飙升至第1名。原因在于SSL将长文本中的零碎信息提炼成了标准的标签 (excel, financial-modeling) 以及极其明确的资源范畴 (LOCAL_FS) 和阶段流程,高度契合用户的隐性约束。

案例二:扯下伪装 (incident-response安全定级) 有一个“事件响应”技能。如果不提供SSL,只看长文档,DeepSeek模型给它的所有风险维度都打了最低的1分,认为它就是一个“写公关通稿”的安全文员。 但在加入了SSL结构后,风险分数立刻被修正(破坏性评3分,特权等评2分)。因为SSL的逻辑层无情地提取出了它隐藏的依赖:execute_recovery_scripts (执行恢复脚本),并且揭示它触碰了 NETWORK 和 CODEBASE 核心资源。系统立刻明白,它不仅是个文员,还手里捏着“服务器重启大权”。


案例三:反面教材 (server-actions的局限) 某个技能的作用是“生成带有后端数据库逻辑的代码”。SSL在这里翻车了,降低了风险判别。为什么?因为SSL严格要求“忠于文本动作”,它只能提取出这个技能“写入了本地代码库 (CODEBASE)”,但对于“生成的代码运行后会干嘛”无能为力。这揭示了SSL是一个静态表征工具,它能看懂剧本,但预判不了生成的衍生品的运行时态。

研究者在论文的讨论部分明确界定了SSL的系统定位:它是一种“证据接口(Evidence Interface)”,应该与原始文档并排使用,而不是将其彻底替换。
SKILL.md 包含了丰富的设计原理、防错保护措施以及维护指南。同时,研究者也客观列举了当前该方案存在的几项局限:
《从技能文本到技能结构》这篇论文针对当前智能体技能管理的痛点,提出了一套行之有效的解决方案。通过引入经典语言学理论中的上下文框架、场景预期和原语结构,研究者成功将自然语言的技能文档降维为机器易读的SSL图结构。
通过在技能发现和风险评估两大核心场景下的严谨验证,SSL证明了结构化底层证据能够大幅度提升系统的信息检索精度与安全审查敏锐度。这项工作为未来构建可审查、可复用的智能体生态系统奠定了坚实的工程基础。
文章来自于"AI修猫Prompt",作者 "AI修猫Prompt"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】smart-excel-ai是一个输入你想要的Excel公式的描述,即可帮你生成对应公式的AI项目
项目地址:https://github.com/weijunext/smart-excel-ai
在线使用:https://www.smartexcel.cc/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
