# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
自从黄仁勋在 GTC 上大手一挥,鼓励企业把 token 消耗量算进工程师的 KPI,魔幻的事情就一天比一天多了。
先是 Meta 内部搞起「烧 token 竞赛」,员工为冲 KPI,写死循环 bot、用低效提示词刷量;接着亚马逊员工为了证明自己「高频使用 Agent」,明明不需要自动化的活儿,硬给做成自动。表面看,这是大厂员工在「卷 AI 使用率」,但背后暴露的问题其实更严重:当企业无法衡量 AI 的真实价值时,就只能退而求其次,用「调用量」代替「产出」。
而这种失真,正在变成整个行业的共同困境。
麦肯锡数据显示,88% 的企业已经在至少一个职能中常态化使用 AI,但真正能被定义为「AI 高绩效企业」,即 EBIT 因 AI 提升超过 5% 的,不到 6%。大量预算、算力和工程师时间被投入进去,最后换来的,却往往只是一份「看起来很忙」的账单。企业知道 AI 很重要,也知道竞争对手在用,但问题是:钱到底花得值不值?没人说得清。
这其实也是过去两年 AI 落地最尴尬的地方。
因为大多数 AI 公司卖的,本质上还是「工具」。工具是否真正创造价值,风险天然由采购方承担。更何况,这一次的工具不仅更贵、更复杂,还高度依赖企业自身的数据、流程和组织配合。于是,很多企业最后只能盯着 token、调用次数、Agent 使用频率这些「过程指标」,试图从里面推测 AI 有没有产生结果。
但问题在于,企业真正想买的,从来不是 token。
CEO 不会因为员工多调用了几次模型而高兴,董事会也不会因为 Agent 使用率提升就认可 ROI。企业真正想要的,其实一直都很简单:结果,而且是能被验证、能被归因、最好还能直接写进财报里的结果。
只是过去,很少有 AI 公司敢为这个结果负责。
而现在,一批公司开始尝试改写这件事:他们不再按「卖工具」收费,而是开始直接对结果收费,让 AI 真正背上 KPI。其中,硅谷的 Sierra 与国内的零犀科技,恰好代表了这一模式在海内外的先行探索。
今年 3 月份,红杉的一篇文章带火了一个名为「Raas(Result-as-a-Service)」的概念。

文章开篇就抛出断言:「下一个万亿美元级公司,将是一家伪装成服务公司的软件公司。」
怎么理解?先看文中定义的两种 AI 商业模式:Copilot 和 Autopilot。前者卖的是工具 —— 专业人士用 AI 提效,但雇人用 AI 还得额外花钱。后者卖的是「工作成果」本身:AI 直接交付结果,客户只为可衡量的业务结果付费,而不是软件订阅。
红杉的判断是:后者价值高得多。因为数据摆在那里 —— 企业每花 1 美元在软件工具上,就要在相关服务和人力上花掉约 6 美元。AI 的进步让「卖结果」成为可能,Autopilot 公司可以直击这个远超工具市场的劳动预算。
这篇文章在圈内引发轰动,原因很简单:一个顶级投资机构,亲自把「卖结果」的前景和分量点明了,等于给投资人指了下一波重仓方向。
不过,也有人质疑这是投资机构炒概念,但紧随其后的一个融资消息让市场开始认真审视这个概念的分量。
这个消息来自一家名为 Sierra 的公司。该公司由 OpenAI 董事会主席 Bret Taylor 与前谷歌高管 Clay Bavor 联合创立,旨在通过 AI 为企业提供定制化的客户体验解决方案(比如帮用户改订单、退款、调库存),其核心理念就是让客户「pay for a job well done」。今年 5 月,该公司宣布完成 9.5 亿美元融资,公司估值超过 150 亿美元。
要知道,这一估值是他们 ARR(1.5 亿美元)的 100 多倍。对于一个刚刚被摆上牌桌的新赛道来说,这几乎已经不是普通意义上的高估值,而更像是一种明确的下注。
而真正说服投资人的,是 Sierra 本身的商业化进展。目前,他们已经覆盖超过 40% 的财富 50 强企业。在客户体验与自动化服务这种高度核心、又极度看重稳定性和 ROI 的场景里,大企业不会因为「概念性感」就大规模采购。某种意义上,这些客户本身就是最严格的投票人。
而 Sierra 拿下这些客户,本身就在说明一件事:RaaS 已经不再停留在 PPT 和融资故事里,而是开始完成真正的大规模商业验证。
在国内,类似的事情也在发生。而且国内公司还额外证明了一件事:RaaS 模式能实现规模化盈利和正现金流。
让市场注意到这一点的,是一家名为零犀科技的公司。

坦白说,国内宣称走 RaaS 路线的公司不止他们一家,但现阶段,真正能拿出盈利数据的却凤毛麟角,而零犀恰恰是那个少数派。
他们做的事,其实可以理解成「让 AI Agent 直接去卖东西」。在保险、汽车这些行业里,零犀的 AI 会直接面向 C 端用户沟通,从最开始判断用户有没有兴趣,到中间的跟进、推荐,再到最后成交,整套销售流程都由 AI 自己完成。这个过程最大的难点在于,你最终要拿结果说话 —— 用户是不是真的下单、保单是不是真的成交、钱是不是真的进来是金标准。
但从 2019 年开始,零犀就选择为这件事的结果负责,并一路走到了今天:从早期负毛利,到 2024 年实现公司级净利转正,再到 2025 年跑出规模化盈利与正现金流。数据显示,某头部保险机构接入其智能体后,新增保费超过 20 亿元。而如果用传统人机结合模式完成同样的增量,往往需要一支 800 到 1000 人的销售团队。
无论是硅谷的 Sierra,还是国内的零犀,它们都在做同一件需要胆量的事:把传统上由客户承担的不确定性,主动揽到自己身上。
在 AI 仍被多数人当作「效率工具」的语境下,这种选择本质上需要足够的技术底气。因为只有当你真的相信,自己的系统能够稳定完成任务、持续优化结果、并长期控制波动时,你才敢签下这样的合同。否则,一次结果不达标,吞掉的就是真金白银的亏损。
也正因如此,RaaS 真正有意思的地方,从来不只是商业模式创新,而是它天然会倒逼公司走向另一个维度的技术探索。而这,恰恰也是 Sierra 和零犀接下来最值得被拆解的地方。
Sierra 和零犀,表面上看业务差别很大。Sierra 把「Better customer experiences. Built on Sierra.」挂在官网最显眼的位置,核心产品 Agent OS 帮企业批量造 AI 客服,谈的是体验。零犀则一头扎进保险、汽车等销售场景,谈的是成交。
但从底层来看,两家公司面对的是同一个根本性难题:如何让 AI 在真实业务场景里稳定地把事情做完,并且为结果负责。正是这个共同的出发点,倒逼出了高度相似的技术路径。
首先,两家都不是在单纯地卖模型能力,而是在卖任务完成 ——Agent 的设计目标从一开始就指向业务结果,而不是简单的生成质量。为此,它们都在大模型之上额外搭了一套执行、记忆与评估系统,并对模型本身做了二次干预,让它在特定场景下更可靠、更少犯错、更清楚什么算好结果。更关键的是,两套系统都不是静止的 —— 它们在真实业务里持续跑、持续学,越用越强。
这些共性让它们看起来走在同一条大路上。但接下来的岔口,客户体验与销售的本质差异,把两家推向了完全不同的技术纵深。
当回答对≠能成交
由于瞄准客户体验,Sierra 的核心命题是「把事情做对」,目标是答对问题、少犯错、不出合规风险。围绕这个目标,Sierra 搭建的是一套精密的模型编排体系:15 款以上的异构模型按任务特性分工协作,再由监督者模型实时审查每一次输出。这是一种偏向「组织架构管理」的技术思路 —— 把正确性管住,系统就能稳定运转。

但对于瞄准销售的零犀来说,核心命题截然不同 —— 它不是「对不对」的问题,因为话术对不等于能成交。举个例子,一位女士在咨询保险过程中说「我要和老公商量一下」,通用大模型可能顺势接一句「好的,您回去商量」。看起来,这个回复没有什么毛病。但在实际的销售场景中,一个金牌销售不会让话题就这么终结,而是读懂这句话背后的真实顾虑(比如怕买错或没搞懂保障范围),并做进一步努力。
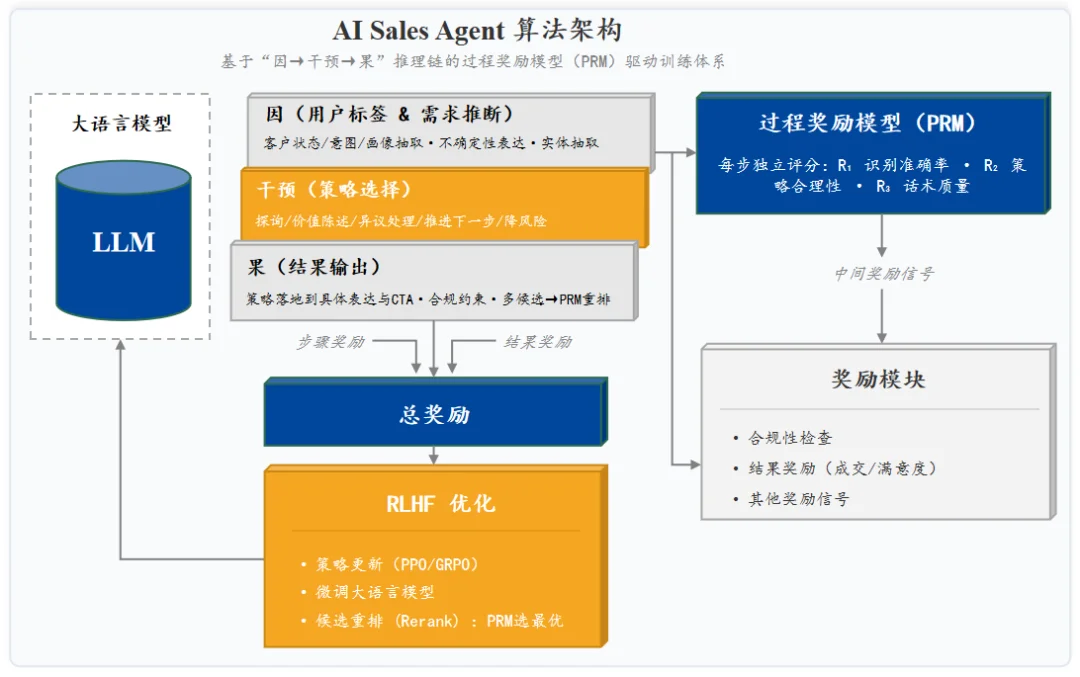
这种情况下,模型必须学会向高转化方向倾斜。因此,零犀真正需要的是一套奖惩机制 —— 做对了给正向激励,没达到预期就施加惩罚,通过后训练持续把模型的权重推向想要的方向。
但这个后训练过程,远比训练模型去做编程等任务坎坷,因为销售场景的难点是全方位的 —— 数据稀缺、信号稀疏、归因复杂,而且根本无法在虚拟环境中验证。
我们知道,销售的成交率本来就低,实际场景里可能只有百分之几,大部分用户都不会成交。这意味着你拿到的正向反馈天然稀少,没办法像训练代码模型那样 —— 写一段代码,跑一下看有没有报错,就能立刻得到明确的对错反馈,进而产生大量训练数据。销售结果是由真实的人来决定的,你没办法造出一个虚拟用户,设定「只要这样说他就一定会买」,这个环境根本不存在。
归因则是更复杂的问题。一单成交了,是因为 AI 话术好,还是客户本来就有购买意向?一单丢了,是 AI 策略失误,还是客户客观原因?这和「吸烟是否导致肺癌」是同一类问题 —— 不是个体能直接验证的,必须靠大量真实样本的统计因果分析才能建立可信的归因逻辑。
但统计也不是万能的,因为很多时候基于统计的大模型无法区分真正的因果和虚假的相关,这也是所谓「幻觉」的根源。当模型看到「沟通时间长」与「成交」之间存在统计相关,它可能就学会拼命延长对话,却不知道如果用户一直在投诉,聊再久也不会买单。单纯依赖统计因果,模型会轻易被混淆变量带偏,这正是销售场景里最容易踩的坑。这也是为什么通用大模型无论能力多强,在销售转化这件事上都难以直接搞定。
零犀的突破口:让模型学会「因果」
正因为销售场景存在以上这些问题,零犀最后走出了一条和通用大模型很不一样的后训练路径。这条路径的关键,不是单纯让模型「更会说」,而是让模型在后训练阶段学会:用户买,为什么会买,什么策略真正有效、为什么有效,以及什么样的策略应该被持续虽化。
为了达到这个目标,首先,它解决的是「归因」这件事。
前面提到,销售最大的难点之一,是模型很容易被虚假的统计相关带偏。这里的问题不在于模型不会统计,而在于它不知道真正起作用的「因」是什么。
所以,零犀沉淀的并不只是普通对话数据,而是一套尽可能因果完备的全链路数据:用户当时是什么状态、浏览了什么页面、AI 为什么采取这个策略、用户后续又给出了什么反馈…… 这些信息都会被完整记录下来,并沉淀为领域因果知识图谱,作为事实底盘约束模型输出。因为只有「因」足够完整,模型才不会只学到表面的相关性。
但数据只是基础,更难的是把销售经验真正变成模型能力。
很多销冠并不一定能准确说清自己为什么厉害,但他们往往知道:什么情况下应该推进,什么情况下应该转移话题,什么情况下用户真正的顾虑其实没有说出口。零犀做的,是把这些原本存在于人脑中的经验,拆解成一套「用户状态识别 — 策略选择 — 结果反馈」的因果逻辑,再通过后训练沉淀进模型。这套「逻辑因果」方法与「统计因果」共同作用,使得模型的输出更加可靠,能让模型知道什么该奖、什么该罚、什么样的策略值得被强化学习持续放大。
此外,起作用的还有反事实推理。系统不仅记录「做了什么」,还会评估「如果没做会怎样」—— 对每一次未成交,它会复盘:比如在给新生儿父母介绍保险时,如果当时没讲性价比,而是继续聊孩子保障缺口,转化率预计能到多少?这种从「没发生的事」里提取知识的能力,让模型在真实数据稀疏时依然能持续学习。
当这些能力建立起来之后,系统的自主进化才真正开始运转。
由于零犀本身就是按结果收费,它天然能够拿到最直接的反馈闭环。哪些策略带来了更高转化,哪些用户会在什么节点流失,哪些干预方式实际上适得其反,系统都能在真实业务环境中持续完成评估、归因和策略调优。
与此同时,新的业务规则、成功案例和失败教训,也会被不断加工成结构化的因果知识片段,重新沉淀回模型与知识图谱之中。随着服务规模扩大,系统对用户理解、策略选择和交付能力的积累也会越来越深,最终形成一种持续自我优化、自我进化的后训练体系。
因此,零犀的壁垒,本质上并不是某一个单点技术,而是一套不断自我强化的飞轮:因果完备的数据、业务 know-how 的 AI 化,以及真实业务环境中的持续迭代,三者彼此咬合,最终形成了一个会越跑越快的后训练系统。
而支撑这个飞轮持续运转的,是一支优秀的后训练团队。除了来自头部高校和大厂的算法工程师之外,零犀还长期引入深耕行业十年以上的销售专家。他们参与的并不只是「标注数据」,还在帮助系统回答一个更难的问题:顶级销售真正有效的能力,到底该如何被 AI 理解、拆解和复制。
当我们把视线从具体的技术细节拉回来,会发现 Sierra 和零犀的探索,其实正在回答 AI 行业一个更根本的问题:AI 到底应该怎么创造价值,又该如何被定价?
这两年,一个趋势正在变得越来越明显:单点工具的壁垒正在被快速瓦解。Claude Code 等 Agent 产品的出现,让很多专门工具,变成了「用时生成、用完即弃」的东西。工具本身的价值,正在以肉眼可见的速度被稀释。但与此同时,另一件事情的价值却在水涨船高:把工作真正做完、做好的服务。
原因很简单。工具只是流程里的一把锤子,你买了锤子,还得自己去钉钉子,钉歪了、钉错了,责任都在你。但服务交付的是「把钉子钉好」这件事本身 —— 结果确定,风险转移。
这其实也是 AI 从诞生第一天开始,人们真正期待它做到的事情 —— 成为一个能独立背 KPI 的数字劳动力。谁能真正做到这一点,谁能拿到的市场,就会比传统软件大出一个数量级。
而 RaaS 这个赛道更值得关注的地方在于,它的护城河并不会随着基础模型升级而被削弱,反而可能越来越深。
因为 SaaS 卖的是工具,客户今天能买,明天也能换;但 RaaS 一旦开始端到端地交付结果,它就会逐渐嵌入客户真正的业务流程。更关键的是,每一次真实交付,都会沉淀新的结果数据、行业 know-how、策略经验和合规逻辑。这些东西不会因为底层模型升级就被清零,相反,模型越强,它们的价值反而越会被放大。
还有一个容易被忽视的变化是:当客户开始习惯「按结果付费」之后,他们会反过来用这套标准去要求所有后来的 AI 服务商。
这也是为什么,零犀提到说,他们的一些大客户,已经开始不再关心「你用了哪个模型」「参数量是多少」,而是直接追问:「你到底能不能把转化率做上去?」一旦行业开始用结果而不是功能评估 AI,整个竞争逻辑都会被彻底改写。
所以,先发者真正占据的,并不只是时间窗口,而是定义规则的能力。
回到文章开头,那些大厂内部为了冲 AI 使用率而疯狂「烧 token」的荒诞场景,本质上其实暴露的是同一个问题:AI 的价值,始终没有被真正兑现。而 RaaS 真正重要的地方,恰恰在于它把这件事重新拉回了正轨。
从本质上来讲,这是一种价值回归:让 AI 真正对结果负责,让收益和风险对齐,也让「生产力」这个词第一次真正回到商业世界最朴素的衡量标准里 —— 到底有没有把事情做成。
摩根士丹利 2026 年初发布的报告将 AI 定义为第六次技术革命。前五次技术革命的历史已经反复验证:短期卖「铲子」的基础设施商最先获利,长期最大价值却沉淀在应用层和采用者手中。由于这种生产率红利的滞后性,AI 对生产率的实质性带动可能要到 2030 年之后才会充分显现。当泡沫退去、噪音消散,真正穿越周期的,永远是那些敢于为结果负责、把技术转化为生产率的公司。
这也正是 RaaS 最值得被长期看好的底层逻辑。零犀和 Sierra 的探索,不是在做概念,而是在重演一个被历史反复验证的剧本:谁能把「铲子」用好,把工作真正做完,谁就能定义下一个十年。
文章来自于"机器之心",作者 "张倩"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
