# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
4个月烧光全年AI预算,天价Token正逼疯硅谷!最近,墨芯人工智能斩获近10亿融资,用「稀疏计算」强势破局,全新一代算力芯片年内发牌。
天价Token账单,正反噬硅谷大厂!
这几天,整个科技圈都被一系列「算力账单爆表」的消息疯狂刷屏——
微软紧急叫停 Claude Code许可证「止血」,全员被强制迁移至自家的Copilot。
仅4个月,Uber 5000名工程师烧光了全年的AI预算!
甚至,就连全球GPU霸主英伟达VP坦承,「对我的团队而言,AI成本已超过了人力成本」。

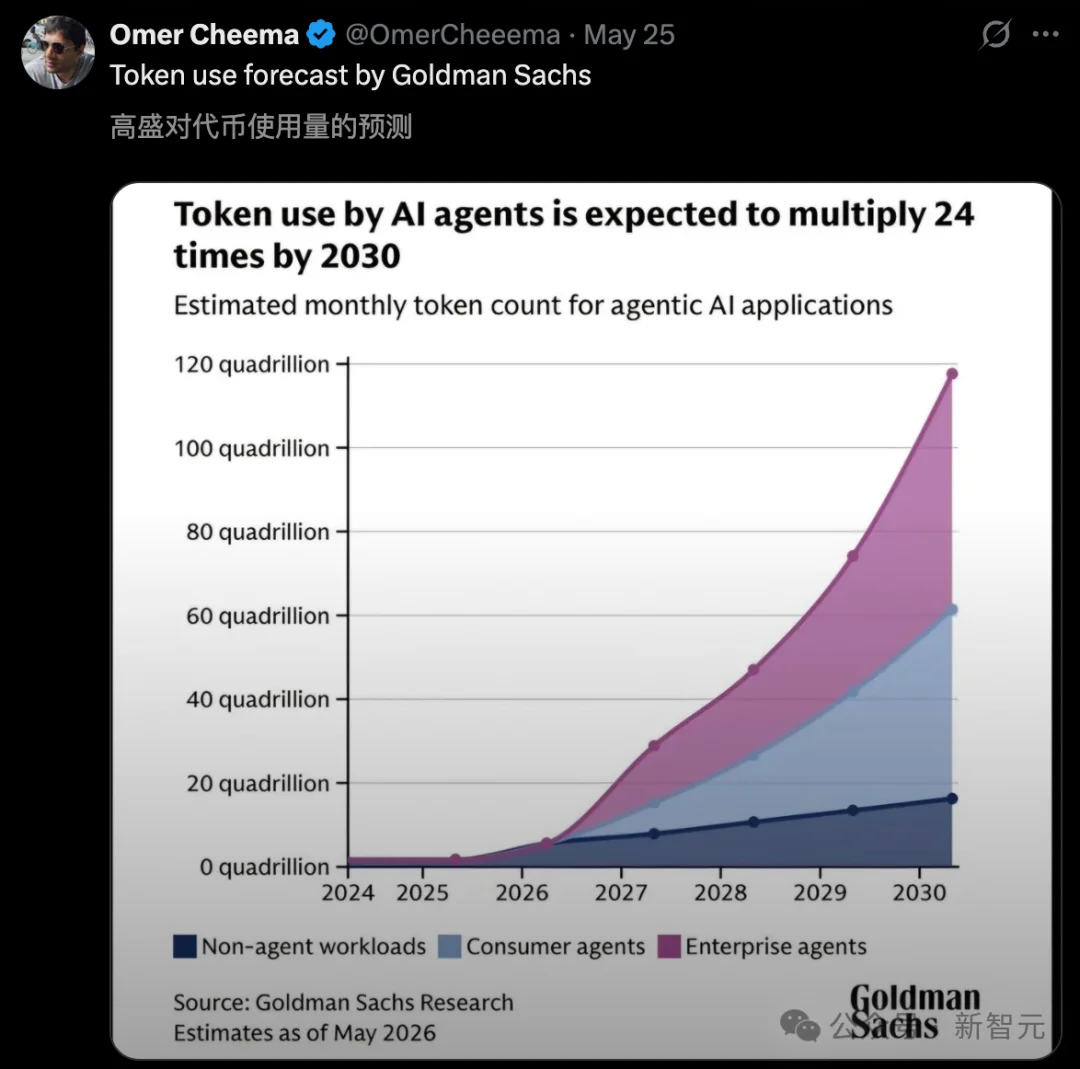
高盛最新报告,给出了一个更惊悚的数字:
预计到2030年,Agent所消耗的Token用量将增长24倍,达每月120千万亿个Token。
AI的推理成本,正在成为这个时代最昂贵的账单。
2026年,AI行业达成了一个迟来的共识:推理,才是真正的主战场。
当Agent从概念走向落地,每一次对话、每一帧视频分析、每一轮基因测序都在消耗海量token——
一个朴素的算术题摆在所有人面前:钱不够烧了。
过去,工业革命的底层逻辑是「买断制」,建工厂、买设备的初始成本极高。
但是,一旦机器运转起来,多生产一件产品的边际成本极低。
机器不需要按时薪结算,产量越大,平摊到单件上的成本就越低,成本曲线趋于平缓。
而到了AI时代,逻辑变成了「租赁制」。初始成本近乎为零,你只需按Token付费来「租赁」AI的思考能力。
但这种模式的致命弱点在于:面对复杂任务时,Token消耗会呈指数级爆炸。
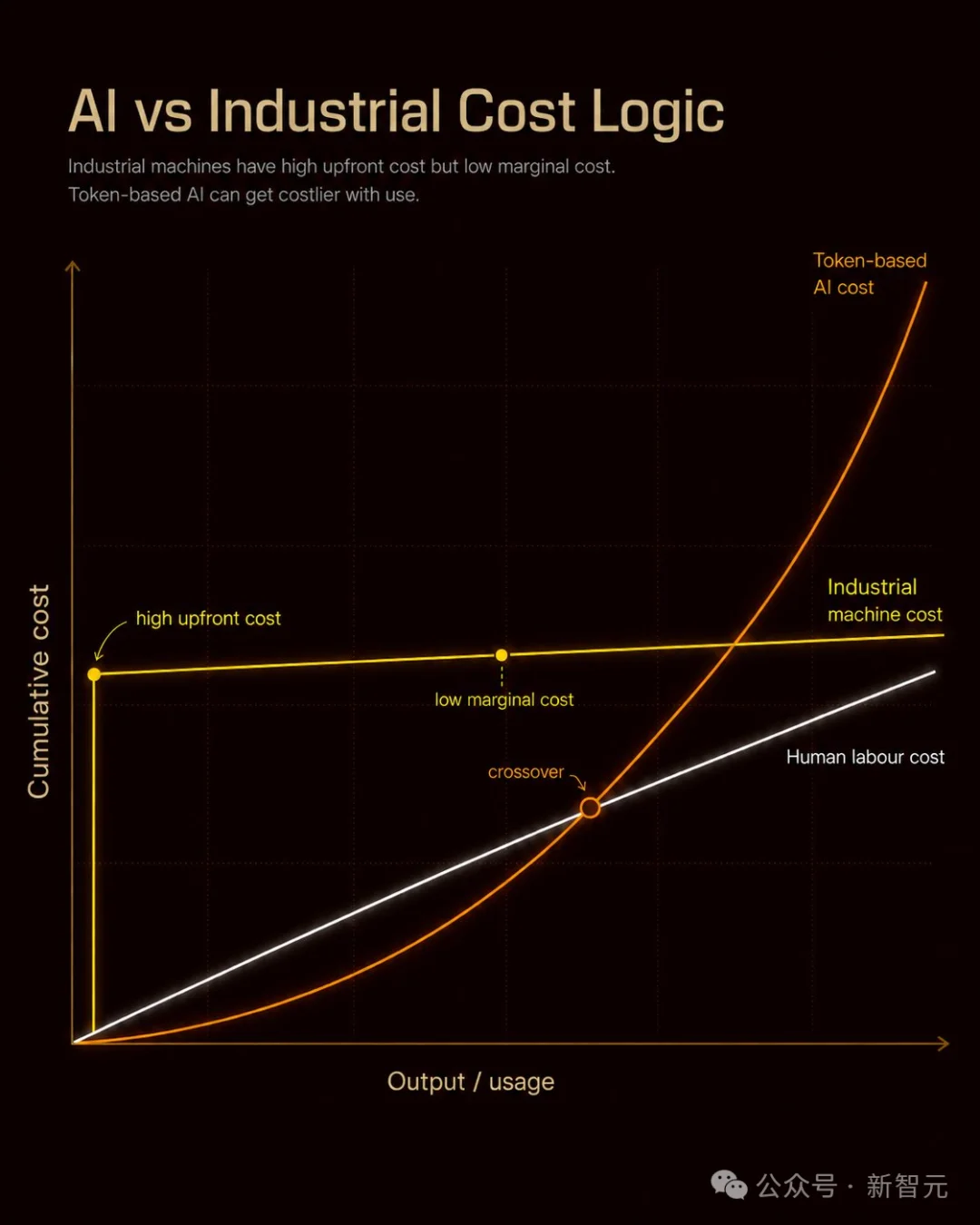
这就带来了一个残酷的「成本交叉点」——
在简单任务上,AI确实远比人工廉价;但如果让AI处理极复杂的循环任务,高昂的API账单最终会反超人类薪资。
这也就解释了当下,一大批硅谷公司都喊Token太贵的根源所在。
「贵」只是症状,真正的病根是:当前AI的技术架构,和落地场景之间存在系统性的错配。
第一层错配:Agent需要「循环思考」,但每一圈都在烧钱
在此之前,AI的主要交互模式是「一问一答」,消耗几百到几千个Token,成本可控。
但Agent时代的逻辑完全不同。
一个Agent为了完成一个任务,要经历「规划→执行→观察→反思→再规划」的闭环,每一轮都要调用一次大模型。
而且Agent「永不下班」,7×24小时运转,持续监控环境、验证结果、调用外部工具。
一个人类员工一天问AI十几个问题,一个Agent一天调用API上万次。
这就是为什么Uber 5000名工程师四个月就烧光了全年预算,最根本原因是——
每一个Agent背后都是一台不停转的「Token印钞机」。
第二层错配:多模态让每一次推理的「体积」暴涨
文字是AI最轻量的输入形式,一段对话,几百个Token就够了。
但2026年的AI,已经不只是在处理文字。
一张图几千个Token,一段60秒的视频几十万个Token,一次完整的基因测序分析,可能消耗上百万个Token。
当GPT-4o、Gemini这类多模态模型成为行业标配,「每次推理要处理多少Token」这个数字被整体抬高了一到两个数量级。
人们以为自己在调一个API,其实是在喂它一整部电影。
第三层错配:长上下文窗口是一把「双刃剑」
上下文窗口从4K扩展到128K、再到百万级,是近几年大模型工程能力最显著的进展之一。
但这一切背后,有一个物理现实:
Transformer的「自注意力」计算量是O(n²),上下文长度翻10倍,注意力计算量翻100倍。
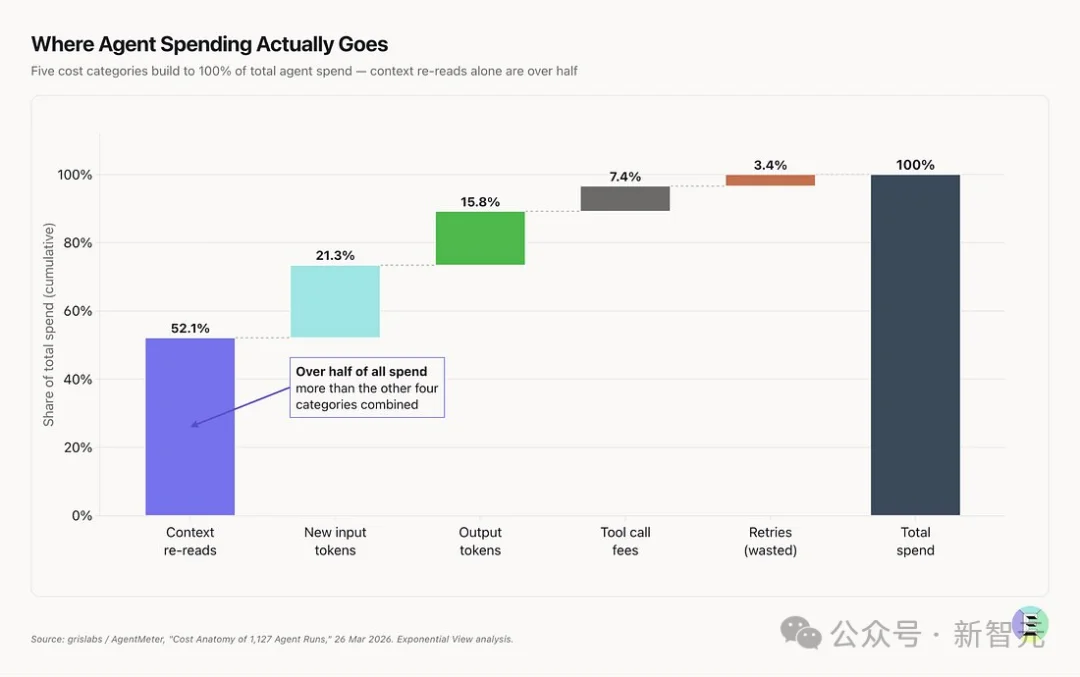
长上下文打开了能力的天花板,但同时也打开了成本的地板。
把这些错配叠加在一起,你就理解了2026年AI产业最深层的焦虑——
不是AI不够聪明,而是AI的「思考方式」太昂贵了。
如今,推理算力的需求正以指数级膨胀,而硬件制程的进化却在逼近物理极限。
纯靠堆卡、卷纳米、拼先进制程,边际效应越来越明显。
谁能用更聪明的方式「榨干」每一个晶体管的价值,谁就能在这场算力竞赛中拿到下一张入场券。
所有人都在问同一个问题:有没有一种技术,能让AI「算得更聪明」,而不是「算得更多」?
答案,或许正在从深圳传来。
近日,一家深耕「稀疏计算」的AI芯片公司——墨芯人工智能,正式完成C轮融资,金额近十亿元人民币。
本轮融资阵容堪称重磅,「产业巨头+国资背书+财务资本」三重结构同桌落座。
不仅汇聚了深创投、岩山科技、大湾区共同家园、力鼎资本、蕴盛资本等头部产业资本及市场化机构,凯旋创投、华大松禾天使基金、创享投资、盛景嘉成等多家老股东也持续加码。
这种在AI芯片创业公司中,颇为稀缺的多元股东结构,释放出一个强烈的行业信号:
「稀疏计算」这条技术路线,正在从算力演进的「可选项」,全面蜕变为「必选项」。
从技术验证到产业爆发,稀疏计算这条路,墨芯人工智能走了八年。
如今,资本和产业用真金白银,为这条颠覆性的技术路线投下了最坚定的「信任票」。
这里,有必要先把「稀疏计算」这件事讲清楚。毕竟,这是墨芯所有故事的底层逻辑。
那么,到底什么是「稀疏计算」?
举个直白的例子,你去问AI「智齿疼怎么办」,传统稠密(Dense)大模型的计算方式是——
会让几乎全部参数都参与这一次推理。哪怕其中绝大多数,和牙齿、和疼痛半点关系都没有。
而「稀疏计算」只激活与医学、牙科相关的少量计算模块,其他模块保持休眠。
用更少的计算量,得到同样的答案。

稀疏计算的核心理念就是:只计算有效信息,跳过冗余参数。
这个思路听起来简单,但要在芯片硬件层面真正实现,却极其复杂。
既然墨芯选择在「稀疏计算」这条路上死磕,那么,他们手里这套技术底牌,究竟有多能打?
国际顶尖的AI基准测试给出了最硬核的答案——
墨芯旗下S30、S40计算卡,已在MLPerf™ Inference中强势斩获「三连冠」。
面对视觉、NLP、大模型等主流任务的极限压榨,它不仅实现了单位算力吞吐与能效比的全面领跑,更以远低于行业旗舰的功耗,跑出了更极致的推理性能。
这无疑向市场甩出了铁证:在真实数据中心的严苛负载下,稀疏计算的工程化落地与商业爆发,已经到来。
下一代芯片,年内上线
更值得关注的是,融资宣布之际,墨芯同步放出了一记重磅:全新一代计算卡SparsePrime®将于年内正式推出。
这是一款面向智算中心和数据中心的高性能AI通用推理计算卡。
它基于墨芯自研的Antoum 2.0芯片架构,专为大模型与复杂推理场景优化设计。
对于开发者来说,最值得兴奋的一点是——几乎零迁移成本。
现有的基于PyTorch、TensorFlow的模型代码,以及vLLM等主流推理框架,能够近乎零代码修改地完成迁移并直接部署运行。
同时支持Triton语言进行自定义算子开发,最大程度降低了使用门槛。
SparsePrime®的性能目标也很明确:精度无损,算力翻倍。
这张卡将基于多个算力中心千卡集群部署中积累的真实负载数据,进一步突破稀疏计算效率的天花板。
技术好不好,不看PPT,看落地怎么样。
如今,墨芯已经走过了「单点验证」阶段,进入了「全国多区域千卡集群部署」的规模化实战期。
在西北、西南、华东、华北四大片区,墨芯的推理集群正成为多个重点区域智算中心的核心算力底座。
西北片区部署千卡级推理集群,支撑传统产业智能化转型。
在电子制造、消费品生产等场景落地了多个工厂安防项目,于边缘侧实现高效实时AI分析。
这个片区的代表案例,陕西国资算力中心千卡集群项目,还入选了人民网「人民匠心技术案例」,获得了央媒层面的认可。

西南片区充分结合当地充沛的绿电资源,构建低功耗绿色算力池,探索「算力飞地」模式,将东部算力需求与西部绿色电力资源精准对接。
华东片区聚焦生命科学与医疗健康等高端服务业,前瞻部署高性能AI算力集群。
目前已携手行业头部企业,为高通量测序、蛋白质结构预测等计算密集型任务提供澎湃算力。
一次基因测序的数据分析流程,借助稀疏计算可以大幅提速,对于争分夺秒的临床决策来说,这就是实实在在的价值。
华北片区则赋能城市治理与社区智能化升级,全面落地人脸识别、姿态分析等视觉多模态大模型应用,构筑全天候、实时化的异常行为智能监测与预警体系。
这一布局与国家宏观战略高度共振——
「十五五」规划强调数字经济核心产业增加值占比达12.5%,「东数西算」工程要求新建枢纽节点数据中心绿电占比超过80%,今年两会更将「算电协同」确立为新基建关键方向。
墨芯的低功耗、高能效技术路线,恰好踩在了政策与市场需求的交叉点上。
从CMU到清华复旦,筑牢技术护城河
商业化高歌猛进之外,墨芯并没有忘记一件事:最深的护城河,永远挖在技术的源头。
在产学研布局上,墨芯构建了一张覆盖国内外顶尖学府的合作网络。
在国外,墨芯与CMU围绕推理加速和稀疏化训练等关键技术深度合作,LLM稀疏化训练已取得阶段性成果。
国内方面,墨芯与复旦大学就「半结构化稀疏」开展横向课题合作,与清华大学CCNI Lab和SparseMind推进「稀疏计算」前沿课题探索,并与杭州电子科技大学成立稀疏计算联合实验室。
从卡内基梅隆到清华、复旦,墨芯构建的是一条从算法创新到芯片架构,再到产品落地的完整闭环——
不仅是技术护城河,更是人才护城河。
站在2026年这个时间节点回望,稀疏计算的产业逻辑已经越来越清晰。
头部大模型纷纷采用稀疏MoE架构,从模型层面验证了——不需要每次调动全部参数的合理性。
华为「韬定律」的核心,是在先进制程之外,靠系统架构、集群协同和算法优化把算力价值榨出来。
每一个趋势都在指向同一个结论:推理时代,效率为王。
如今,一个越来越清晰的事实是,算力的下半场,不属于最贵的芯片,而属于最聪明的计算。
稀疏计算正在回答那个困扰整个行业的终极问题,怎样让AI的推理成本降到千行百业都用得起的水平?
墨芯给出的答案,是一整套「芯片+算法+集群+生态」的系统能力。
SparsePrime®年内推出之后,这个答案将更加完整。
文章来自于"新智元",作者 "新智元"。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
