# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
具身智能现在面临的问题,和自动驾驶几年前的困境非常相似。
过去几年,自动驾驶行业已经证明了一件事:谁先把真实物理世界组织进统一的数字空间,谁就先拿到规模化的入场券。
但当年,这件事并不是一开始就想明白的。
早期的纯视觉多相机方案,每个相机自己感知自己的,前摄看前面、侧摄看侧面,各出各的检测结果,再拼到一起交给规划系统。问题是,拼出来的东西在图像坐标里,不在物理世界里。视角一变、光线一变、场景一变,性能就掉。数据堆得越多,各自为政的混乱局面就越严重。
BEV,Bird's-Eye View,就是那把钥匙。它真正改变行业的地方,不是给了工程师一张“鸟瞰图”,而是把多相机、多传感器、多任务输出,统一压进了一个可被规划系统直接消费的物理坐标系。自动驾驶因此完成了一次关键跃迁:从在图像里猜世界,到在物理空间里理解世界。
今天,具身智能正站在同一个路口。机器人数据来自不同相机、不同本体、不同坐标系、不同操作者。没有统一空间,数据堆得越多,就越混乱——不是规模化,是熵暴。
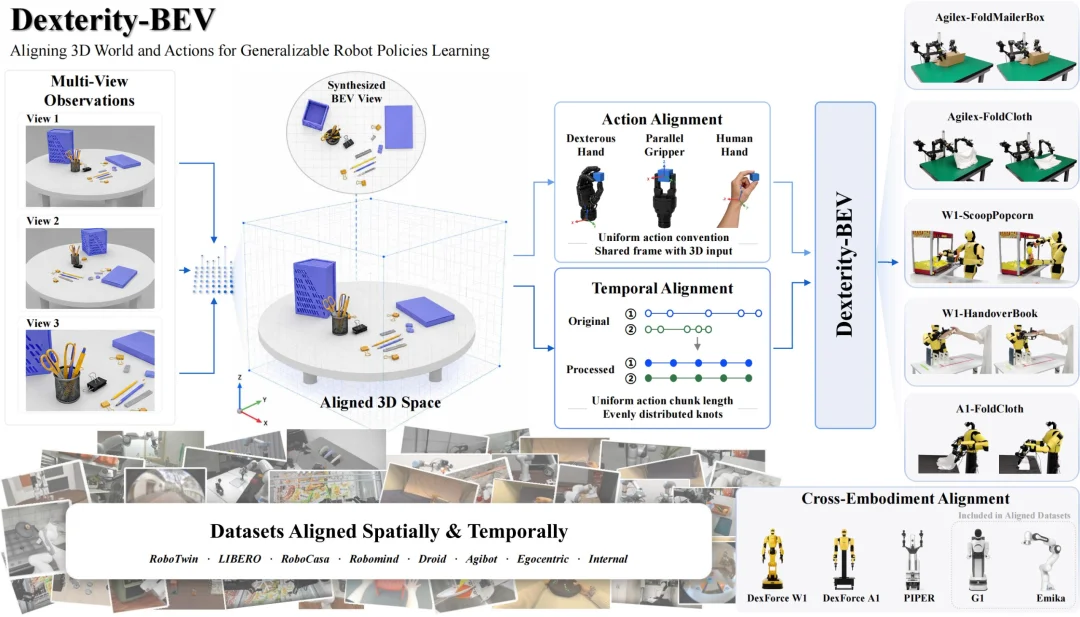
跨维智能提出的 Dexterity-BEV,正是要在具身智能里重做一次这样的重构:把视觉输入、机器人状态和目标动作,对齐到同一个参考系里,让机器人数据第一次真正具备可规模化训练的空间底座。这可以被看作是一次把 BEV 方法论系统性推进到具身智能数据基建层的尝试。

今天的具身智能行业非常热闹。
机器人本体不断推陈出新,新的数据集接连发布,新的遥操作系统、人类第一视角数据、仿真与生成数据也在快速增长。显然,行业正在进入一个数据快速扩张的阶段。
文本可以被统一组织成 token,图像也有相对稳定的数据范式,但机器人数据和文本、图像不同。机器人数据天然异构,以机器人一条操作数据举例,可能同时包含多视角图像、深度、相机参数、关节状态、末端轨迹、语言指令、任务成败和真实反馈等多种维度的信息。更何况各机器人本体规格不一,数据集坐标系互不统一,相机采集视角存在差异,操作人员动作节奏也各不相同;更为复杂的是,UMI、Egocentric等全新数据采集范式还在持续涌入。人类的身高、臂展、视角和动作习惯,本质上也像一种新的“异构本体”,进一步放大了数据之间的差异。
所以,具身智能面临的并不是单一的“数据量问题”,而是一个更棘手的双重难题:一方面,高质量真实交互数据仍然稀缺且昂贵;另一方面,已经采集到的数据又高度异构,难以互通、难以统一训练、难以跨机迁移。
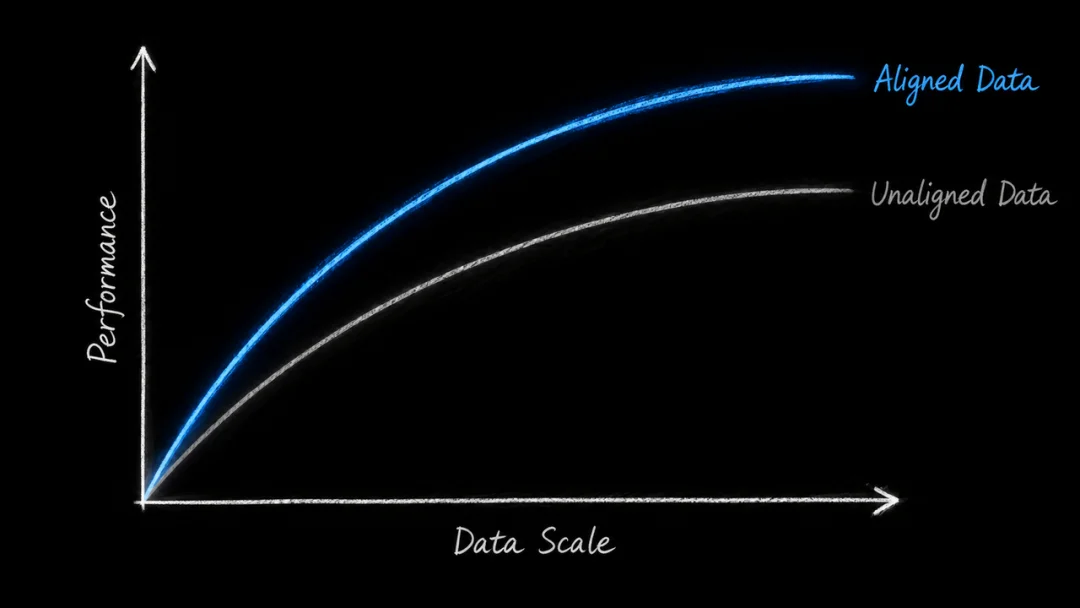
这正是具身智能正在面对的现实:行业既需要更多数据,也需要一种把数据变成可训练、可迁移、可复用资产的底层秩序。如果缺失统一秩序,数据扩张并非正向规模化 Scale,只会走向熵暴(entropy explosion)。
01 给具身智能装上“统一空间坐标系”
Dexterity-BEV 的思路非常直接,也非常狠:把多来源、多视角、多本体的机器人数据,统一对齐到一个 BEV 三维空间里。
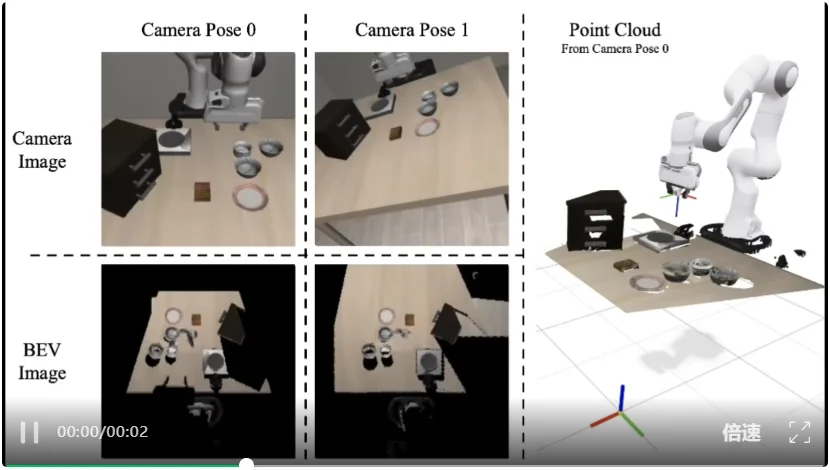
这不是简单把多视角图像拼起来,也不是做一个笨重的三维重建系统。Dexterity-BEV 的关键,是构建一个统一BEV对齐坐标系,让不同相机看到的物体、空间关系和操作目标,都能被放进同一个俯视参考空间。
可以把它理解成一个“虚拟正交相机”。不管真实相机装在哪里、从哪个角度拍、机器人从哪个方向看,最终数据都会被转化到同一个俯视空间里。这样,同一个物理任务就不再是一堆互不兼容的二维图像,而是同一物理世界中的可学习表达。
这一步的意义很大,过去很多 VLA 模型看起来学会了任务,但一旦相机视角变了、机器人基座动了、场景布局变了,性能就会明显掉。原因很简单:模型学到的不是物理规律,而是某个固定视角下的图像模式。
Dexterity-BEV 要做的,就是把模型从“看图猜动作”拉回到“在三维空间里理解任务”。
02 它不是放弃 2D 大模型,而是给 2D 大模型补上 3D 坐标
这也是 Dexterity-BEV 最值得讲的地方。
具身智能行业现在有一个两难:纯 2D VLA 有语义能力,但空间不够;重型 3D 方法有几何信息,但成本高、训练难,也不容易复用已有 2D VLM 的能力。
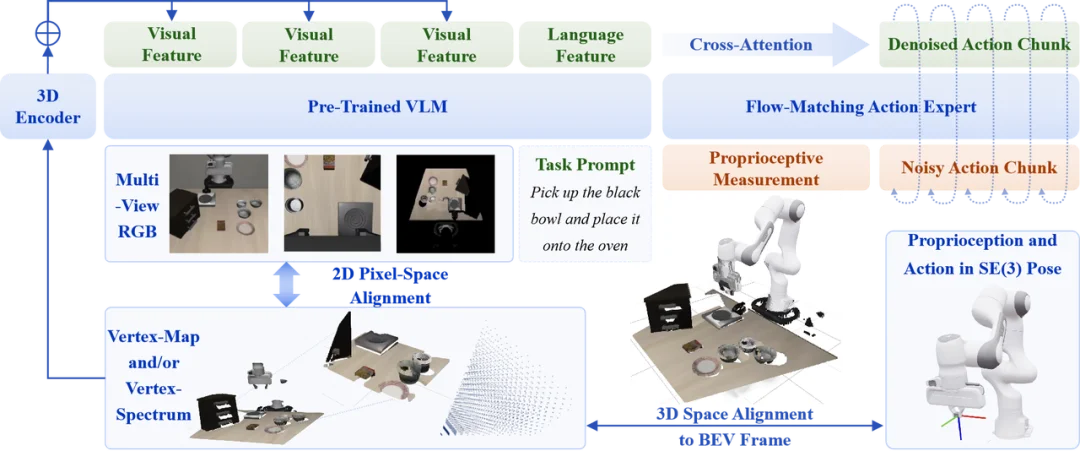
Dexterity-BEV 没有选择推倒重来。它保留多视角 RGB 输入,继续复用成熟的二维视觉编码器和视觉语言模型,同时通过顶点图(vertex map)和顶点谱(vertex spectrum),给每个视觉 token 注入三维空间位置。
换句话说,它不是重新造一个昂贵的 3D 系统,而是在已有视觉模型体系上补了一层机器人最缺的东西:空间坐标。对于有深度信息的设备,它可以利用深度图和相机标定生成像素级三维顶点表示;对于更常见的纯 RGB 相机,它可以通过顶点谱机制,为每个像素构建一组三维位置假设,再编码进视觉特征中。
这就像给二维图像接上了一套三维物理骨架。语义能力保住了,空间理解补上了,工程成本也没有被打爆。这才是能 scale 的 3D。
03 不只对齐视觉,还对齐动作
如果 Dexterity-BEV 只是把图像对齐到 BEV 空间,那还不够。机器人数据真正难的地方在于:动作也不统一。
不同机器人本体差异巨大。一个 Franka,一个双臂平台,一个半人形机器人,即使执行同一个任务,关节轨迹也完全不同。如果模型直接学关节角,基本就被硬件绑死了,Dexterity-BEV 的处理方式,是把动作从具体关节里解放出来。
它不让模型只学习“某个关节转多少度”,而是学习末端执行器在统一 BEV 空间中应该去哪里、以什么姿态接近物体、如何移动、如何完成任务。
更关键的是,这些末端执行器位姿不是随便表达的,而是被进一步对齐到前面提到的统一 BEV 对齐坐标系中。
这就形成了一个非常漂亮的闭环:视觉输入在 BEV 空间里,机器人状态在 BEV 空间里,目标动作也在 BEV 空间里,输入和输出第一次被放进同一个物理坐标系统。这才叫真正的感知—动作对齐。
通俗点说,Dexterity-BEV 给不同机器人、不同相机、不同动作提供了一把共同的“空间尺子”。过去各说各话的数据,现在终于能用同一种物理语言交流。
具身数据还有第三种混乱:时间。
同一个任务,不同操作者做得快慢不同;不同机器人执行速度不同;有的人中间停顿,有的人动作连贯。这些差异很多时候并不代表任务本质,但会让模型训练变得更难。
Dexterity-BEV 在数据管线中加入了跨轨迹时序对齐机制,对不同机器人、不同操作者、不同数据集里的轨迹进行时间尺度规整。它不是要抹掉任务动作结构,而是尽量减少“谁操作得快、谁操作得慢”这种无意义差异,让模型更专注于学习任务真正的关键动作顺序和空间关系。

所以 Dexterity-BEV 做的不是单点优化,而是一套系统性数据基建:空间对齐、动作对齐、时序对齐、数据管线对齐。
Dexterity-BEV 的实验设计也很有意思。它不是只在固定场景里刷一个好看的分数,而是专门去测那些传统 VLA 容易翻车的情况:相机视角变化、机器人基座扰动、场景布局变化、跨机器人平台迁移。
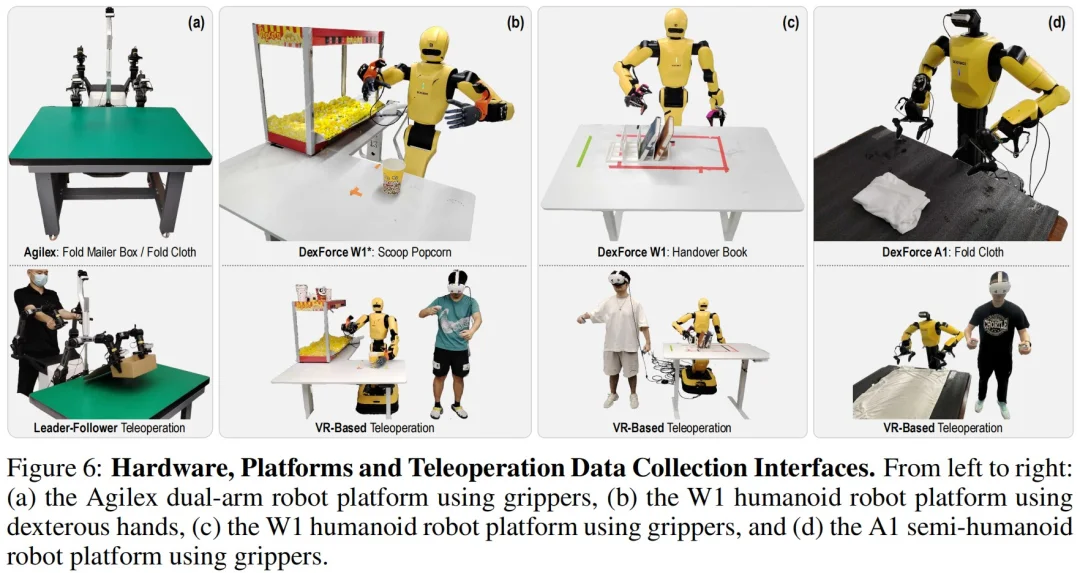
在仿真中,Dexterity-BEV 在 LIBERO 和 RoboTwin 2.0 上与 π0、X-VLA 等强基线对比。尤其在相机视角、机器人基座和场景布局被大幅扰动的设置下,传统 2D VLA 方法成功率明显下滑,而 Dexterity-BEV 仍能保持稳定表现。

在真实机器人上,Dexterity-BEV 也覆盖了四类双臂平台和多个长程任务,包括折叠纸盒、叠衣服、舀爆米花、递书等。这些任务不是简单抓取放置,而是涉及刚体、柔性物体、颗粒物、双臂协同和人类交互的复杂操作。
这类任务更接近真实世界,也更能暴露模型到底是在“记画面”,还是在“理解物理”。
Dexterity-BEV 的结果说明了一件事:当机器人数据被放进统一空间,模型的泛化才真正有了基础。
笔者认为, Dexterity-BEV 最重要的意义,不只是一个模型效果提升,更像是具身智能从“堆数据阶段”进入“建数据秩序阶段”的标志。
过去行业很热衷讨论:谁采了更多小时数据,谁有更多机器人,谁做了更多任务。但如果这些数据不能统一训练、不能跨机迁移、不能复用到新场景,数据规模越大,反而越像一座座孤岛。
Dexterity-BEV 提供的是另一种思路:先建立统一物理空间,再谈数据规模化。这和自动驾驶当年 BEV 范式带来的变化非常像。BEV 让自动驾驶从多相机图像感知,走向统一空间理解;而现在,Dexterity-BEV 正在尝试让具身智能从杂乱的机器人轨迹,走向统一的感知—动作物理表达。
如果说过去具身智能还在“看见世界”,那么 BEV 进入之后,它开始有机会“组织世界”。这可能是具身模型真正 scale 之前,必须补上的一层数据基建。
具身智能的下一阶段,不会只是模型更大、数据更多、机器人更贵。
真正决定行业能不能跑起来的,是数据能不能被统一,动作能不能被迁移,经验能不能跨机器人复用。
Dexterity-BEV 的价值就在这里:它不是只做一个更强的策略模型,而是试图为具身智能建立一套可规模化的数据秩序。
从这个角度看,BEV 杀入具身智能,不是一个普通技术点,而是一次补课。
自动驾驶吃到过的 BEV 红利,现在轮到机器人了。
而跨维智能这次做的,就是把具身智能真正推上 Scaling 快车道之前,先把路修好。
文章来自于"机器之心",作者 "机器之心"。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
