# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
过去十年,推荐系统最核心的动作可以概括成一个字:找。
用户来了,系统理解用户兴趣,再从已有内容池里检索、排序、分发最合适的视频。这个「retrieve-and-rank」范式支撑了短视频、信息流和广告推荐的高速增长,也让深度学习推荐模型成为工业界的基础设施。
但它有一个天然上限:如果用户真正想看的那条视频,内容池里根本不存在呢?
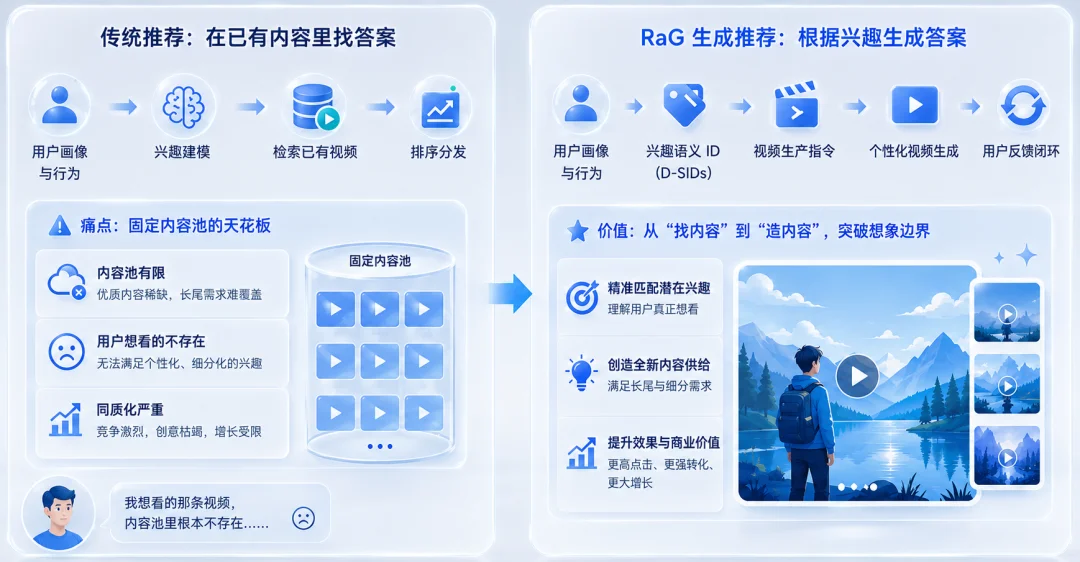
快手最新论文提出的 Recommendation-as-Generation(RaG),正是在回答这个问题。

它把推荐系统从「在已有视频里找答案」,推进到「根据用户兴趣生成答案」:先预测用户潜在兴趣,再直接生成与兴趣对齐的个性化视频。
这不是一个概念 demo。论文中的 RaG 已在快手大规模广告系统中部署,服务超过 4 亿日活用户。在线 A/B 实验显示,完整 RaG 系统相较强 GRM 基线带来 +1.870% 广告收入提升。
更关键的是,这一增益来自一个新的闭环:推荐模型不只是选择已有内容,而是把用户兴趣转化为视频生成目标,再用真实反馈持续校准生成过程。
下面是一个真实示例:
该用户为热爱健身的年轻男性,对美女、健身及低脂饮食内容表现出明显偏好。
基于此人群画像,系统为其量身定制了「美女代言蛋白粉」的场景化广告。广告以吸睛的美女形象切入,紧扣其「运动后控糖低脂」、「高效增肌」与「即时便捷」的真实痛点,实现精准种草,完美满足其个性化消费需求。

历史交互的兴趣视频

RaG 个性化视频广告
传统推荐系统的链路是:用户画像与行为 → 兴趣建模 → 检索已有视频 → 排序分发。
RaG 将其改写为:用户画像与行为 → 兴趣语义 ID → 视频生产指令 → 个性化视频生成 → 用户反馈闭环。
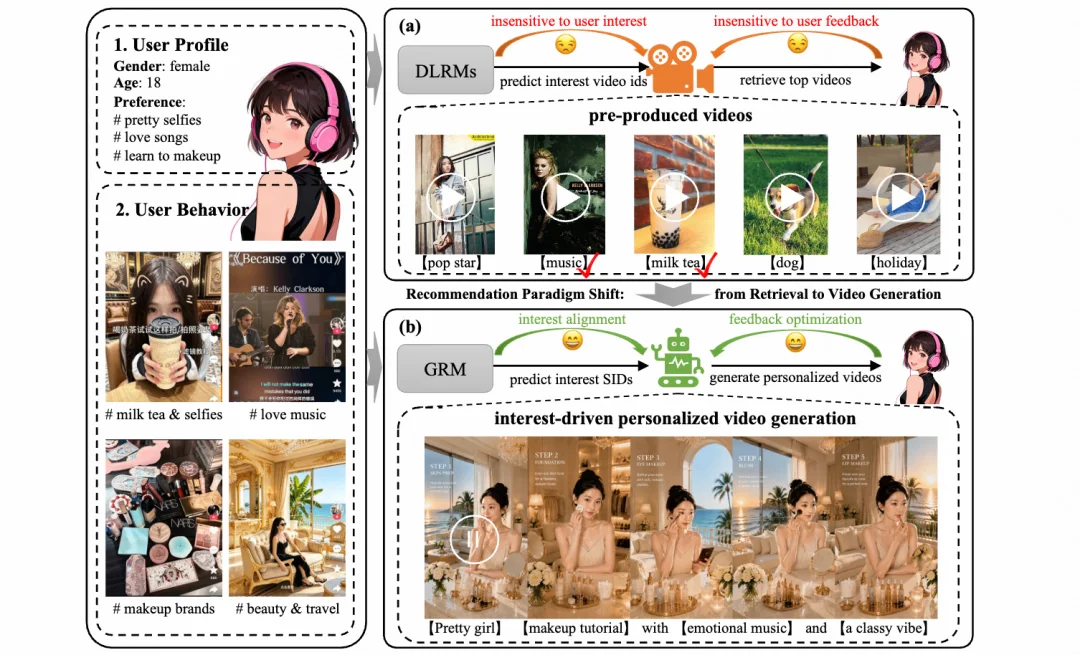
论文将这一过程抽象为:


这一步的本质变化是:推荐模型不再只预测「某个 item 是否适合用户」,而是预测「用户真正想看的内容应该具备什么语义和创意形态」。
也就是说,推荐系统开始从内容分发器,变成内容生产链路的上游大脑。
把推荐和视频生成接起来,并不是简单地把一个推荐模型和一个视频生成模型串联起来。
论文指出,RaG 要解决两个关键问题。
第一,兴趣推荐和视频生成如何统一到一个框架中建模
推荐模型处理的是用户画像、历史行为、item 特征等离散、异构信号;视频生成模型处理的是文本、图像、音频、运动等连续多模态信号。两者目标也不同:推荐要预测兴趣,生成要保证画面、叙事和音画质量。
如果没有一个统一语义接口,推荐模型预测出的兴趣很难稳定地驱动视频生成。
第二,个性化视频如何实现大规模工业化生产
当前高质量视频生成通常依赖复杂 prompt、多轮人工调试和后处理工具。面向数亿用户的广告推荐场景,系统不可能为每次请求现场生成一条视频。
所以 RaG 的目标不是做一个单点生成模型,而是构建一套端到端、可缓存、可反馈优化的工业级闭环系统。
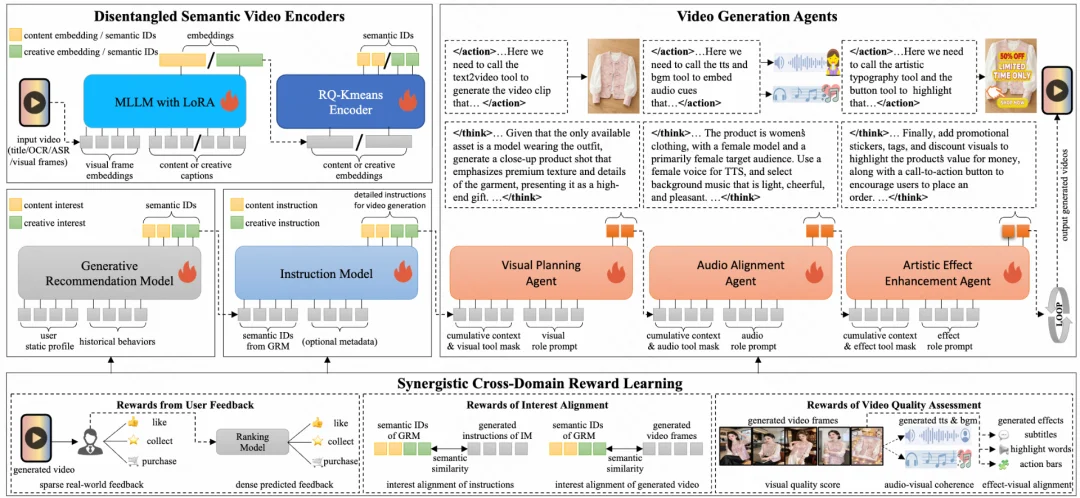
RaG 由五个核心模块构成:
下面逐一拆解。
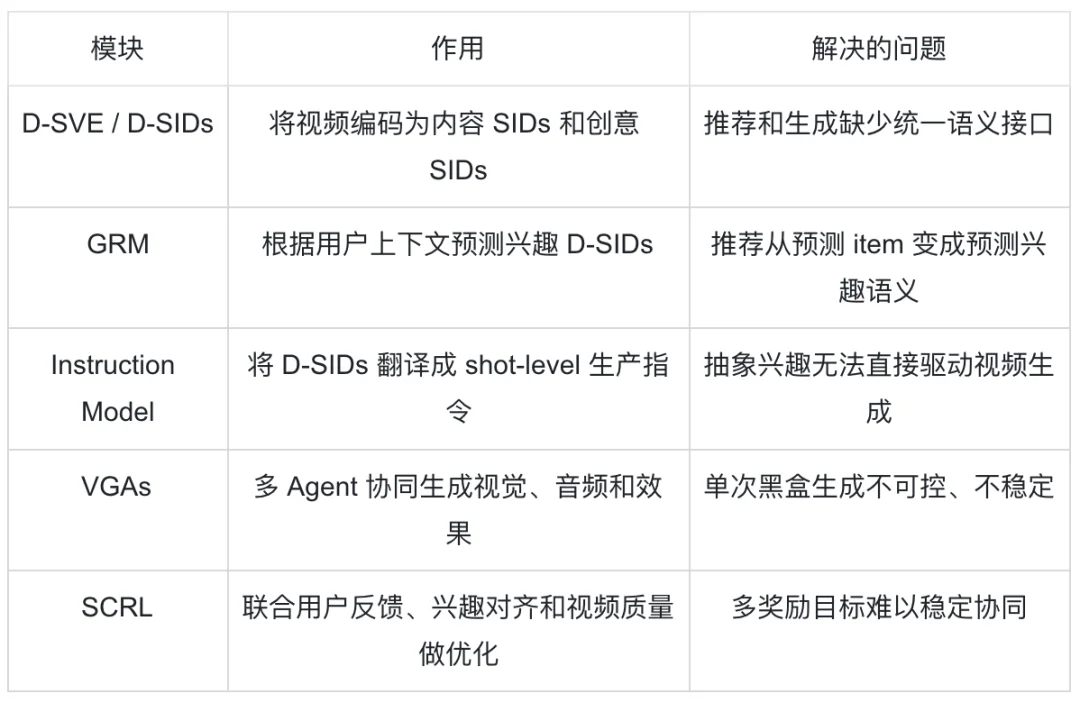
D-SIDs:
给视频一张「内容 + 创意」双维身份证
视频不是单一语义。
同一个商品,可以拍成温柔的生活方式短片,也可以拍成强促销风格广告;同一个「母婴护理」主题,可以是家庭温情叙事,也可以是功效对比测评。
如果把这些信息压进一个混合 ID,推荐模型会同时被内容语义和创意风格干扰,后续生成也难以控制。
因此 RaG 提出 Disentangled Semantic IDs(D-SIDs),将视频表示拆成两部分:
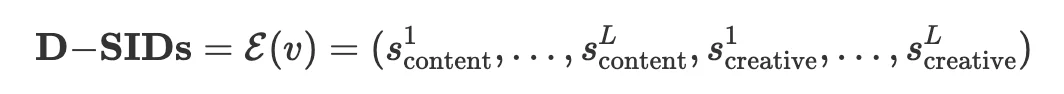

具体实现上,RaG 基于 Qwen2.5-VL-7B-Instruct 构建多模态表征,并使用快手内部 dense captioning model 生成 content /creative 两类描述,再分别进行 RQ-KMeans 离散量化。
每类语义采用 2 层 codebook,每层 8192 个 code,总共4层。
量化过程可以写成:
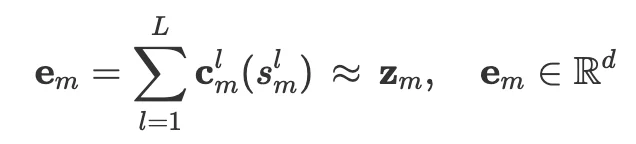
最终将内容 code 和创意 code 拼接,得到完整 D-SIDs:
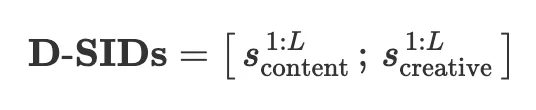
实验结果显示,D-SIDs 显著提升了语义检索和离散化质量:
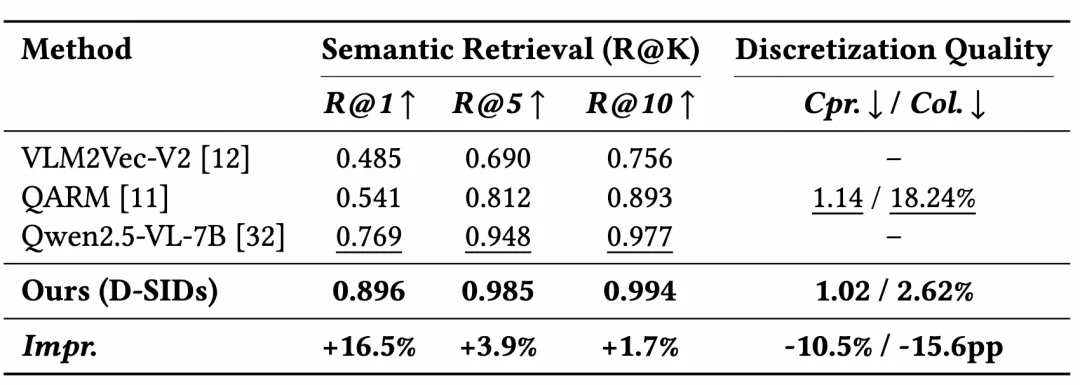
尤其是碰撞率从 QARM 的 18.24% 降到 2.62%。这意味着语义空间更干净,推荐模型更容易学,生成系统也更容易控制。
GRM:
推荐模型预测的不再是视频 ID,而是兴趣语义
有了 D-SIDs,推荐模型的目标也随之变化。
传统推荐模型预测的是某个已有视频是否适合用户;RaG 中的 Generative Recommendation Model(GRM) 则根据用户画像和历史行为,自回归预测用户未来兴趣对应的 D-SIDs:
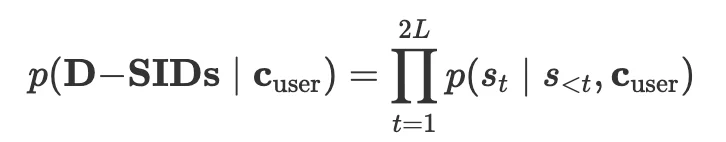

这一步非常关键:GRM 输出的不是某条视频,而是一组可被生成系统消费的「兴趣语义 token」。这些 token 既可以用于检索已有内容,也可以进一步驱动个性化视频生成。
换句话说,推荐结果从「内容池里的候选 item」升级成了「可生成的内容意图」。
Instruction Model:
把兴趣翻译成视频生产说明书
D-SIDs 是离散语义,不是视频生成系统可以直接执行的脚本。
真正的视频生产需要更细的指令:每个镜头拍什么、如何转场、口播说什么、音乐如何匹配、字幕和 CTA 什么时候出现。
因此 RaG 设计了 Instruction Model(IM),将 D-SIDs 和广告 metadata 转换为 shot-level 视频生产指令:
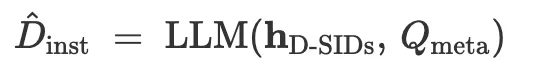
训练上,论文使用 Gemini2.5 Pro 为视频生成 shot-level 指令监督,再用 Qwen3-8B 进行训练。训练分为三阶段:
在指令质量评估中,模型规模和训练数据都会带来提升,考虑线上成本,论文最终采用 8B + 1M samples 作为默认配置,在效果和效率之间取得平衡。
VGAs:
把视频生成变成一条多 Agent 生产线
工业级广告视频不是一段画面生成就结束了。
它至少包括视觉画面、口播、BGM、字幕、转场、贴纸、卖点强调和 CTA。不同模块之间还有明显依赖关系:画面规划决定叙事节奏,音频要跟画面节奏对齐,特效和字幕又依赖前面的视觉与音频结果。
所以 RaG 没有采用单体视频生成器,而是提出 Video Generation Agents(VGAs),将生产过程拆成三个子 Agent:
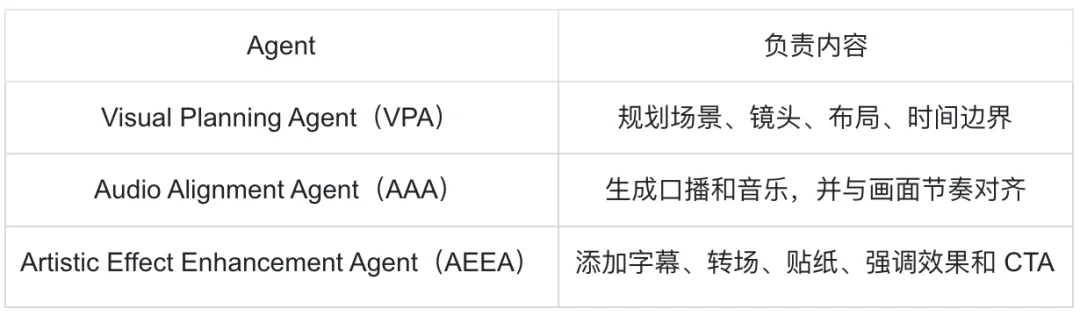
VGAs 可以表示为一个序列决策过程:
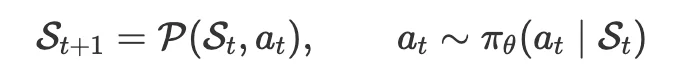
每一步,Agent 根据当前生成状态和指令,选择下一步动作。动作可以是调用 text-to-video、image-to-video、TTS、BGM、字幕或特效工具。最终视频由统一生成算子组合而成:
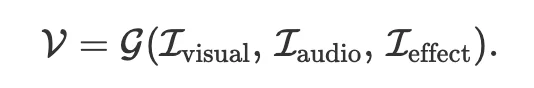
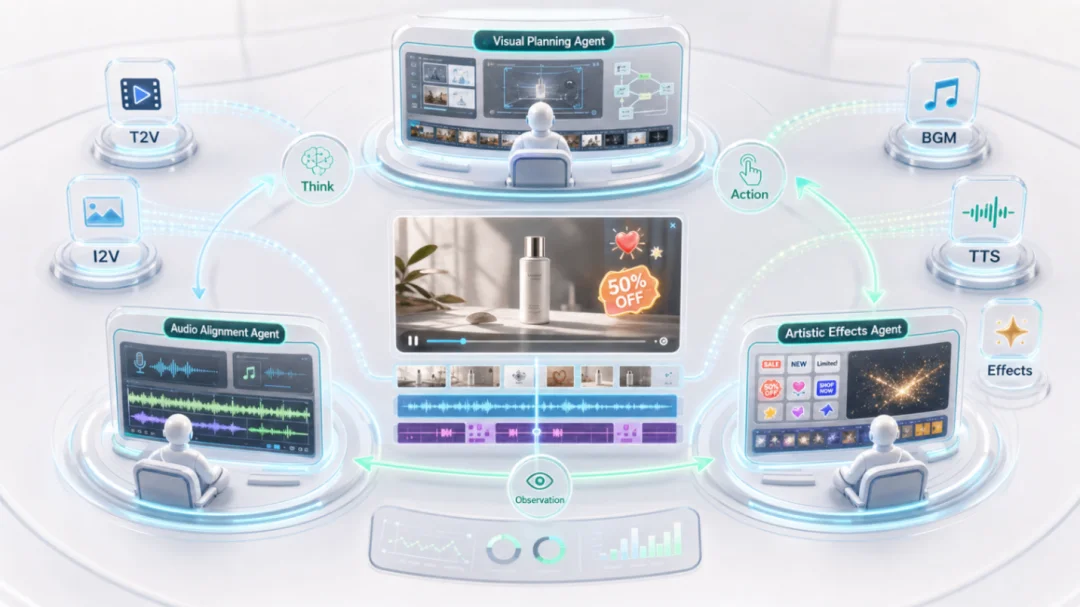
论文中特别强调了 VGAs 的两个能力:
为了控制延迟,线上将反思轮次限制在两轮以内。
实验显示,VGAs 明显优于传统固定流程 baseline:

这说明,相比「按固定模板粗剪 + 精剪」的流水线,多 Agent 结构更适合处理高度个性化、跨模态强耦合的视频生成任务。
SCRL:
把用户反馈、兴趣对齐和视频质量放进一个闭环
推荐系统最终看用户反馈,视频生成系统又必须保证质量。如果只优化点击和转化,可能导致低质但刺激的内容;如果只优化画质,又可能偏离真实用户兴趣。
RaG 提出 Synergistic Cross-Domain Reward Learning(SCRL),将三类信号统一进一个约束优化框架:
论文没有简单地把三类 reward 加权求和,而是把用户反馈作为主目标,将兴趣对齐和视频质量作为约束:
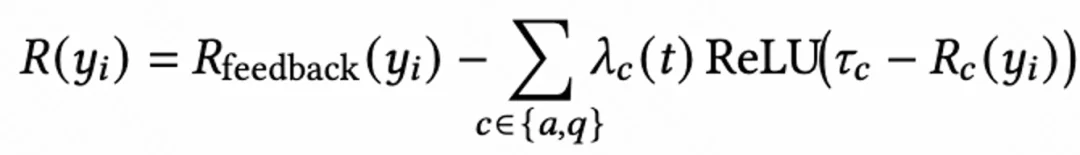
直观理解就是:
用户反馈负责指方向;兴趣对齐和视频质量负责守底线。
当生成结果在兴趣对齐或质量上低于阈值时,系统会受到惩罚。
为了处理不同 reward 的尺度差异,SCRL 使用 GDPO 做 group-decoupled normalization:
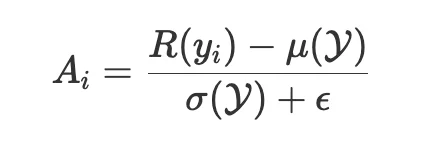
同时,论文引入 PID-controlled Lagrangian multipliers 动态更新约束权重,避免多目标 RL 中常见的震荡和手工调参问题。
消融实验显示,每类 reward 都有明确贡献:
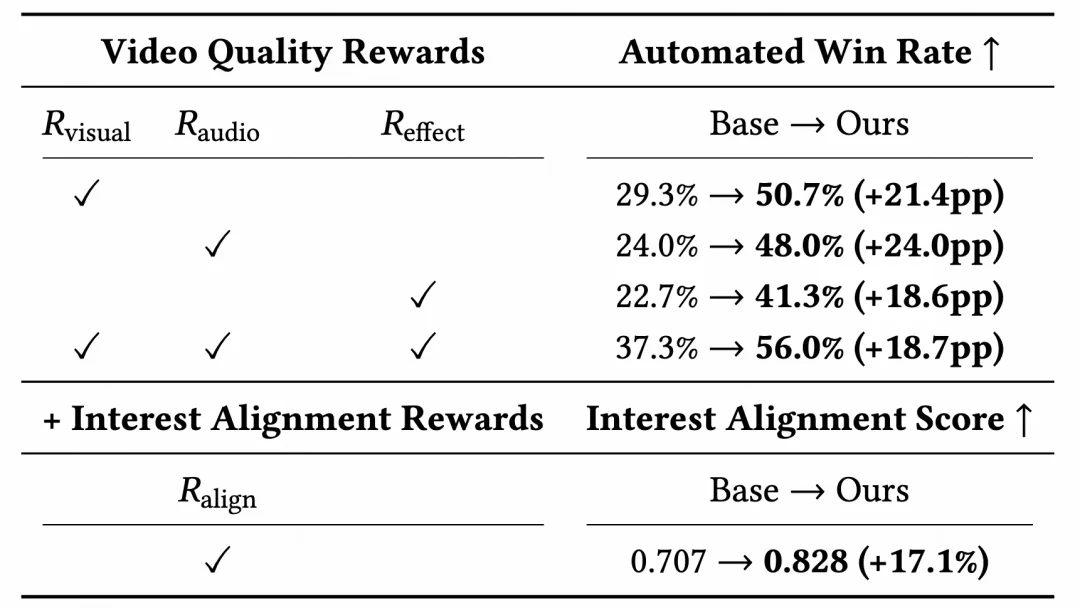
这说明 SCRL 不是简单地「让视频更好看」,而是让视频质量、用户兴趣和商业反馈在同一个优化闭环中协同演化。
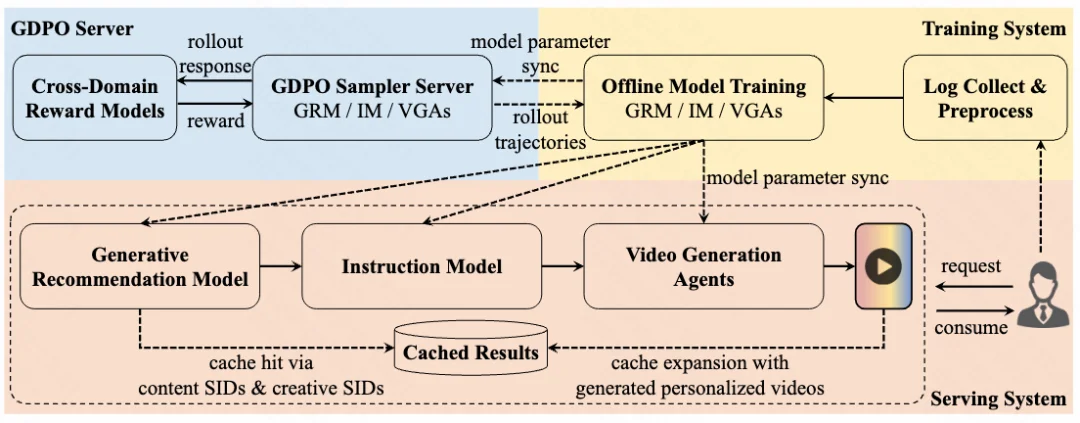
RaG 的工程难点在于:推荐系统要求毫秒级响应,而视频生成通常是秒级甚至分钟级。
论文采用了「在线兴趣建模 + 近线视频生成 + 延迟感知服务」的解耦架构。

GRM 在线预测用户兴趣 D-SIDs;IM 和 VGAs 在近线生成个性化视频,并持续扩展个性化视频缓存池。服务时,系统根据 SID 的缓存命中情况进行分层处理:
这套设计避免了「每次请求现场生成视频」的不现实成本,也让生成系统能随着用户需求不断补齐内容供给。
RaG 在快手广告系统中完成了大规模在线验证。

这个结果有两层含义。
第一,生成式推荐本身已经比传统 DLRM 强,GRM baseline 相比 DLRM 带来 +3.526% 收入提升。第二,在强 GRM 基线之上,D-SIDs 进一步带来更结构化的兴趣空间,而完整 RaG 通过 IM、VGAs 和 SCRL 将推荐语义真正转化为个性化视频供给,最终将相对 GRM 的提升推到 +1.870%。
这意味着,个性化视频生成不只是提升内容表达的 AIGC 能力,而是已经可以在工业广告系统中转化为真实商业增益。
论文通过一个广告场景案例,展示了用户兴趣如何转化为视频生产蓝图。
用户画像是 25-34 岁女性,兴趣集中在年轻妈妈生活方式、母婴护理、家庭用品和高性价比购物。RaG 的处理过程如下:
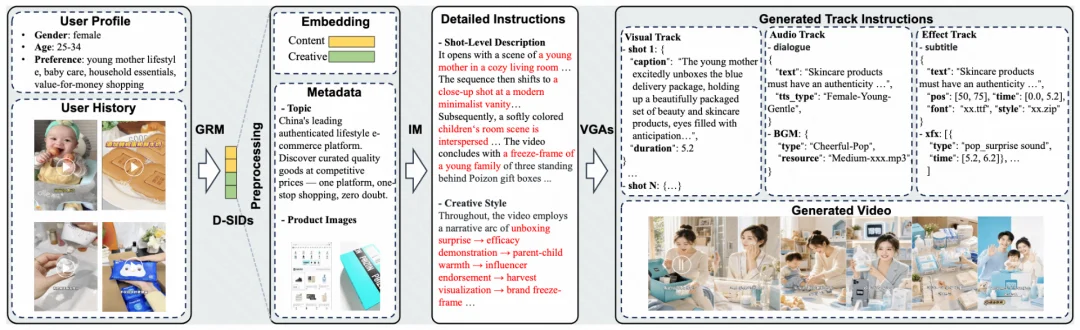
这个例子最能说明 RaG 的价值:用户兴趣不再只是排序模型里的一个分数,而是可以变成视频创作的蓝图。
更多的示例可以访问项目主页获取:
https://recommendation-as-generation.github.io/
RaG 的意义,不只是广告收入提升了。
更重要的是,它把推荐系统的边界从「分发已有内容」推进到「创造潜在供给」。
过去推荐系统回答的是:用户想看的内容在哪里?
RaG 开始回答的是:用户想看的内容应该长什么样?
这不会让检索消失。更现实的路线,是检索和生成共存:
从这个角度看,RaG 不是一个单纯的视频 AIGC 系统。它更像是推荐系统的一次范式外扩:从找视频,到产视频。
更多信息可查看论文:
https://arxiv.org/abs/2606.25496
文章来自于"机器之心",作者 "机器之心"



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
