# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在人类个体能力提升过程中,当其具备了基本的技能之后,会自主地与环境和自身频繁交互,并从中获取经验予以改进。大模型自我进化研究之所以重要,正是源于该思想,并且更倾向于探究大模型自身能力的深度挖掘和扩展。基于这一趋势,北京理工大学 DIRECT LAB 正式启动了「大模型自我进化」的流星雨研究计划。这篇文章以代码大模型和垂域大模型进化为例,逐步介绍流星雨计划。

代码大模型应用范围广、影响大,如何提升其表现,一直备受业内外关注。在一项最新的研究中,来自北京理工大学的研究者提出了一种全新的思路 ——SRA-MCTS,旨在通过自我进化的方式,解决代码模型在处理复杂问题时缺少中间推理过程。
跟随上述自我进化的思想,在 SRA-MCTS(Self-guided MCTS-based data generation for Reasoning Augmentation)方法中,作者无需借助额外的任何监督信号、完全通过模型自身来进行推理路径生成,并进一步迭代大模型的能力。通过这个过程,模型能够自主地生成高质量的推理路径,并将这些路径转化为可执行代码,进而提升在复杂任务上的成功率。
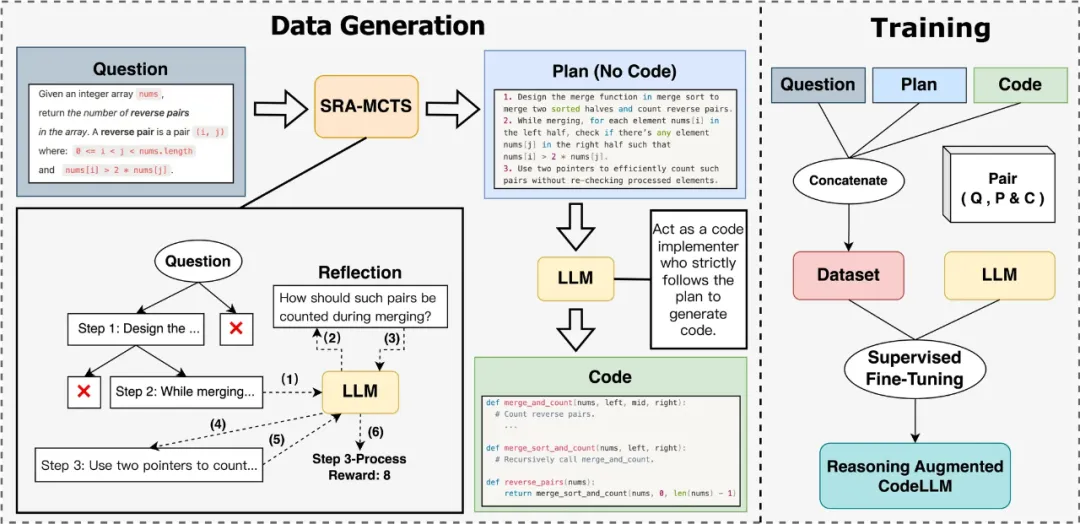
整个过程不仅增强了模型的推理能力,还通过自我反馈和反思提升了解决复杂任务的成功率。实验表明,即使在小规模模型中,SRA-MCTS 也能显著提升任务处理能力,特别是在多样性和解决复杂问题的能力上。
该方法核心在于将推理过程和数据生成紧密结合,通过 SRA-MCTS 引导模型自主生成推理路径。这不仅稳定了分析的准确性下限,还为模型提供了一个无需外部监督的自我改进机制。实验结果表明,即使在传统的思维链(CoT)方法表现退化时,SRA-MCTS 依然能够稳定并有效地提升模型的性能,尤其在「pass@10」等多样性指标上表现出色。
1. 数据合成 - SRA-MCTS:
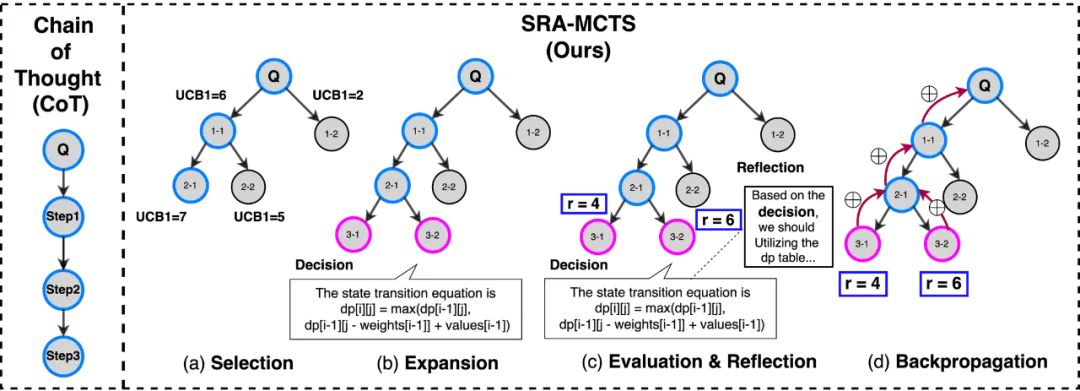
下面的示例展示了中间推理步骤,以及基于推理所生成的代码过程:
问题:请帮我写一段拓扑排序的代码。
思考过程:拓扑排序是针对有向无环图(DAG)的一种排序算法,它将图中的节点按照某种顺序排列,使得对于每一条有向边 (u, v),节点 u 在节点 v 之前出现。常见的拓扑排序算法有两种:Kahn 算法和深度优先搜索(DFS)算法。这里作者选择使用 Kahn 算法来实现,因为它更直观且容易理解。
Kahn 算法的基本思想是:
找出所有入度为 0 的节点,将它们加入队列。从队列中取出一个节点,将其加入拓扑排序结果中。对于该节点的所有邻接节点,减少其入度。如果某个邻接节点的入度变为 0,则将其加入队列。重复步骤 2 和 3,直到队列为空。如果最终拓扑排序的结果中包含所有节点,则说明图是 DAG;否则,图中存在环。
・ 找出所有入度为 0 的节点,将它们加入队列。
・ 从队列中取出一个节点,将其加入拓扑排序结果中。
・ 对于该节点的所有邻接节点,减少其入度。如果某个邻接节点的入度变为 0,则将其加入队列。
・ 重复步骤 2 和 3,直到队列为空。
・ 如果最终拓扑排序的结果中包含所有节点,则说明图是 DAG;否则,图中存在环。
from collections import deque, defaultdict
def topological_sort(graph):
# Step 1: 计算每个节点的入度
in_degree = {node: 0 for node in graph}
for node in graph:
for neighbor in graph[node]:
in_degree[neighbor] += 1
# Step 2: 将所有入度为 0 的节点加入队列
queue = deque([node for node in in_degree if in_degree[node] == 0])
# Step 3: 初始化结果列表
topo_order = []
# Step 4: 处理队列中的节点
while queue:
node = queue.popleft()
topo_order.append(node)
# 更新邻接节点的入度
for neighbor in graph[node]:
in_degree[neighbor] -= 1
if in_degree[neighbor] == 0:
queue.append(neighbor)
# Step 5: 检查是否存在环
if len(topo_order) == len(graph):
return topo_order
else:
raise ValueError("Graph contains a cycle, topological sorting is not possible.")
上面的工作是代码模型的自主推理能力。作者表示,他们期待探究更通用化的自我进化框架和方法,使其在各种场景中都可以被广泛使用。

该计划提出一个由弱到强的进化框架来引导大模型自我进化的整体流程,方法如下图所示:
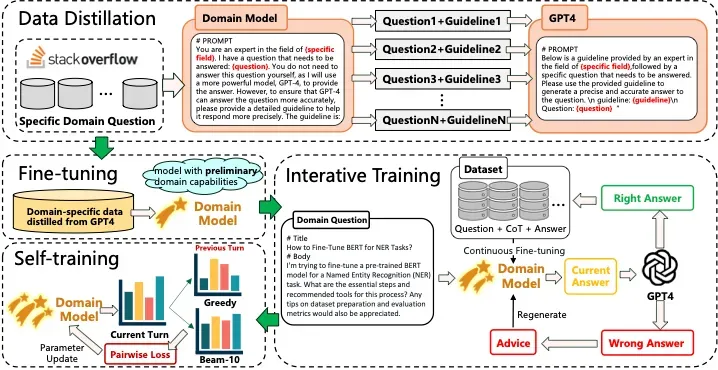
该流程提供了一整套从无领域能力进化成领域专家模型的自我进化训练方案,包含三个关键阶段:
第一阶段:导师监督学习
知识蒸馏是一种有效的获取领域知识的手段。然而作者发现,强模型与弱模型之间存在认知偏差,导致从强模型中蒸馏下来的领域数据无法高效作用于弱模型。
作者提出了 weak-to-strong 的领域数据蒸馏方法,让强模型根据弱模型的指导蒸馏领域数据。具体的,当有一个领域问题时,他们首先将该问题输入弱模型,但不让其直接生成答案,而是生成一段 guideline。这段 guideline 指示弱模型认为应该遵循哪些步骤来回答领域问题。接下来,他们将生成的 guideline 与领域问题一起输入强模型。强模型根据 guideline 的指导步骤生成领域问题的答案,或在 guideline 的基础上进行修正并生成答案。
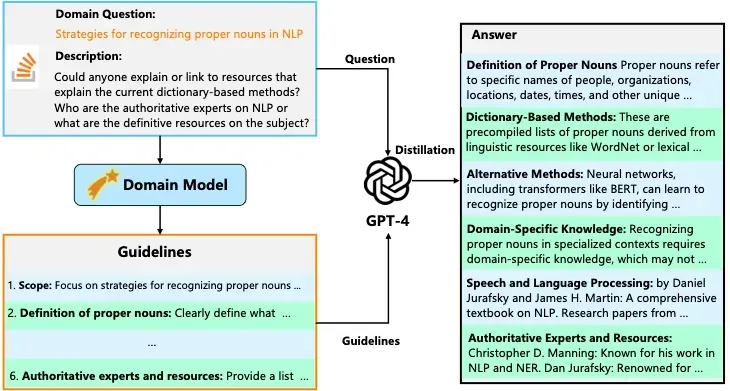
第二阶段:自我评估能力习得
经过蒸馏后的领域数据训练的模型能够完成一定的领域任务,但经过分析,该模型还可能产生大量错误信息或幻觉信息,并且无法进行自我纠正。因此,作者提出要在这一阶段通过更强模型的反馈来纠正模型内部的错误知识,进一步提升模型领域性能。
他们参考 StaR [1] 迭代式训练的方法,让模型首先对领域问题进行作答,并由 GPT-4 给予答案反馈。如果模型的答案是错误的,GPT-4 会将修改建议连同前一轮的答案重新返回给模型,让模型重新作答,直至模型产生正确的答案。整个过程的数据会被保存下来迭代式地训练模型,使得模型的领域能力不断提升。
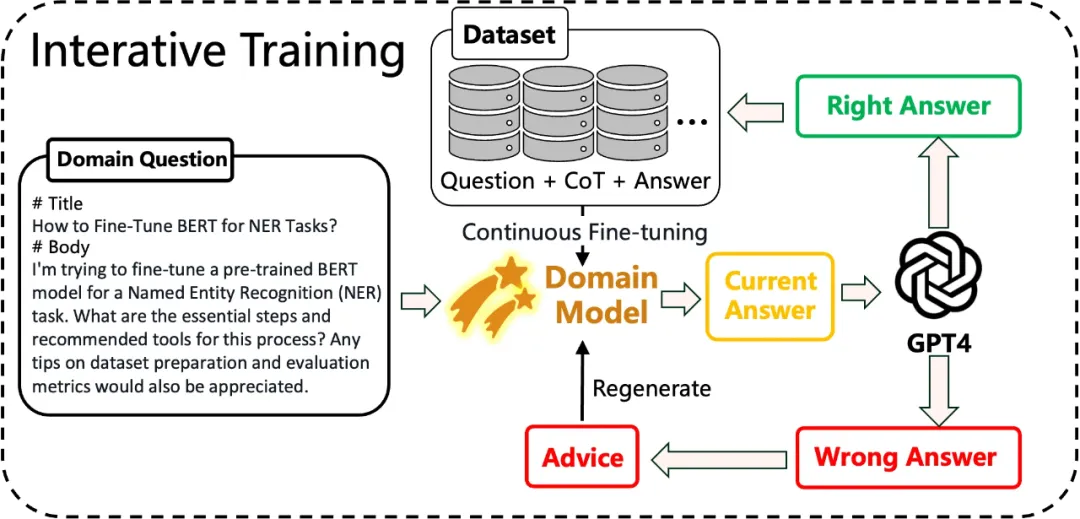
第三阶段:自我提升训练
作者希望模型在最终的领域能力进化过程中能够摆脱对强模型的依赖,实现完全的领域能力自我进化。因此,在模型具有完成自我批判的能力后,他们尝试让模型进行自我进化。
受到在推理过程中增加 FLOPs 可以有效提升模型在下游任务中的性能的启发,他们认为不同的推理策略会产生不同的效果。他们希望模型生成的结果尽可能接近高 FLOPs 推理策略的结果,远离低 FLOPs 策略的结果。他们使用 beam search 作为高 FLOPs 策略,greedy search 作为低 FLOPs 策略,通过对比学习构建模型的自我训练方法,实现模型的自我进化。
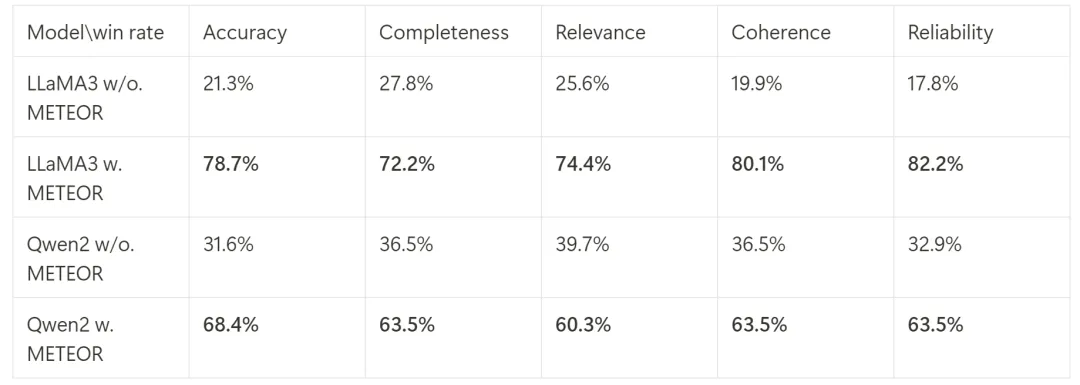
性能分析
作者对比了应用 Meteor 进化方法后 LLM 前后各维度的性能变化。在准确性、完整性、相关性、连贯性和可靠性方面,LLaMA3-8B-Instruct 和 Qwen2-7B-Instruct 取得了性能的提升(评估方法:通过 GPT-4 筛选进化前和进化后答案的 win rate)。
该工作初步探索和尝试了模型进化的整体框架和每个阶段的对应方法,并有了一些初步的结论。未来,作者将在该想法的基础上,在每个阶段中创新更适用的模型自我进化方法,实现模型在各个阶段都能获得预期的性能提升,并在更多不同的场景中探索 Meteor 的适用性,推广流星雨计划。
作者表示,DIRECT LAB 期待与更多对大模型进化感兴趣的学者和业界同仁携手合作,共同推进这一重要领域的探索与突破。实验室相关研究的代码和数据已公开,欢迎大家访问:https://github.com/DIRECT-BIT
参考文献:
[1] star: self-taught reasoner bootstrapping reasoning with reasoning
文章来自于“机器之心”,作者“机器之心”。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
