# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
主要作者:谢承兴,曾作为 KAUST 访问学生,Camel AI 实习生,现西安电子科技大学大四本科生,主要研究方向为 LLM simulation,LLM for Reasoning;陈灿宇,伊利诺伊理工大学在读四年级博士生,研究方向为 Truthful, Safe and Responsible LLMs with the applications in Social Computing and Healthcare;李国豪,通讯作者,KAUST 博士毕业,曾于牛津大学担任博士后研究员,现为 Camel AI 初创公司负责人,研究方向聚焦于 LLM Agent 的相关领域。
随着人们越来越多地采用大语言模型(LLM)作为在经济学、政治学、社会学和生态学等各种应用中模拟人类的 Agent 工具,这些模型因其类似人类的认知能力而显示出巨大的潜力,以理解和分析复杂的人类互动和社会动态。然而,大多数先前的研究都是基于一个未经证实的假设,即 LLM Agent 在模拟中的行为像人类一样。因此,一个基本的问题仍然存在:LLM Agents 真的能模拟人类行为吗?
在这篇论文中,我们专注于人类互动中的信任行为,这种行为通过依赖他人将自身利益置于风险之中,是人类互动中最关键的行为之一,在日常沟通到社会系统中都扮演着重要角色。因此,我们主要验证了 LLM Agents 能否做出和人类行为相似的信任行为。我们的研究成果为模拟更为复杂的人类行为和社会机构奠定了基础,并为理解大型语言模型(LLM)与人类之间的对齐开辟了新方向。

这项研究得到了论文合著者之一 James Evans 教授的转发。
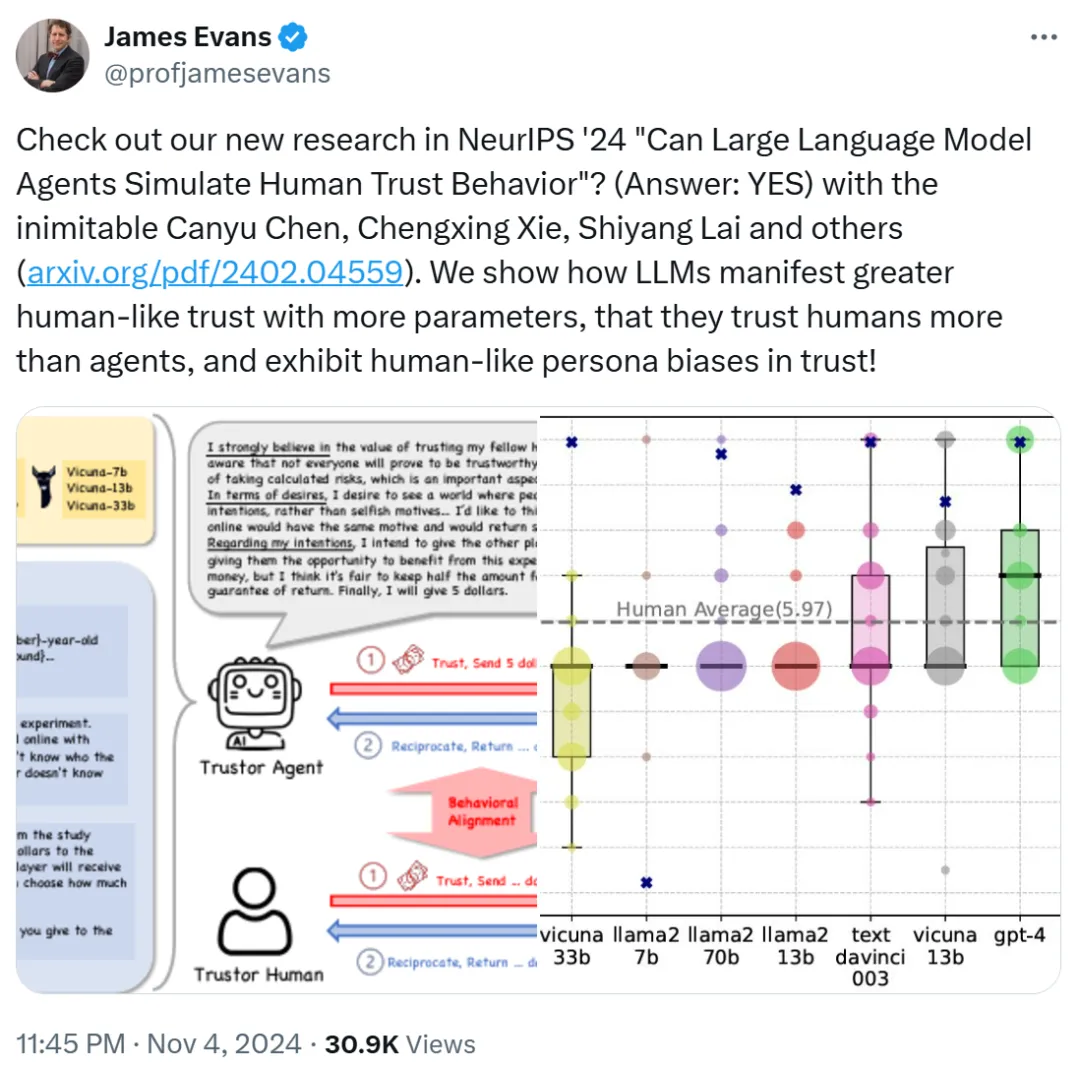
图源:https://x.com/profjamesevans/status/1853463475928064274
James Evans 是芝加哥大学社会学系 Max Palevsky 讲席教授,担任知识实验室(Knowledge Lab)主任,并创立了该校的计算社会科学硕士项目。他毕业于斯坦福大学,曾在哈佛大学从事社会组织结构方面的研究。James Evans 教授的研究领域包括群体智能、社会组织结构分析、科技创新的产生和传播等。他特别关注创新过程,即新思想和技术的出现方式,以及社会和技术机构(如互联网、市场、合作)在集体认知和发现中的作用。他的研究成果发表在《科学》(Science)、《美国国家科学院院刊》(PNAS)、《美国社会学杂志》(American Journal of Sociology)等顶级期刊上。
同时也得到了 John Horton 的推荐。John Horton 是麻省理工学院斯隆管理学院的终身副教授,并且是国家经济研究局(NBER)的研究员。他的研究领域主要集中在劳动经济学、市场设计和信息系统的交叉点,特别关注如何提高匹配市场效率和公平性。他近期的研究包括探讨大型语言模型在模拟经济主体中的应用等。

图源:https://x.com/johnjhorton/status/1781767760101437852
此外,该研究还得到了其他人的好评:「这项研究为社会科学和人工智能的应用开辟了许多可能性。信任确实是人际交往中的一个关键因素。很期待看到这一切的发展。」

图源:https://www.linkedin.com/feed/update/urn:li:activity:7266566769887076352?commentUrn=urn%3Ali%3Acomment%3A%28activity%3A7266566769887076352%2C7266707057699889152%29&dashCommentUrn=urn%3Ali%3Afsd_comment%3A%287266707057699889152%2Curn%3Ali%3Aactivity%3A7266566769887076352%29
「GPT-4 智能体在信任游戏中表现出与人类行为一致的发现是模拟人类互动的有趣一步。信任是社会系统的基础,这项研究暗示了 LLM 建模和预测人类行为的潜力。」

图源:https://www.linkedin.com/feed/update/urn:li:activity:7266566769887076352?commentUrn=urn%3Ali%3Acomment%3A%28activity%3A7266566769887076352%2C7266596268271947777%29&dashCommentUrn=urn%3Ali%3Afsd_comment%3A%287266596268271947777%2Curn%3Ali%3Aactivity%3A7266566769887076352%29
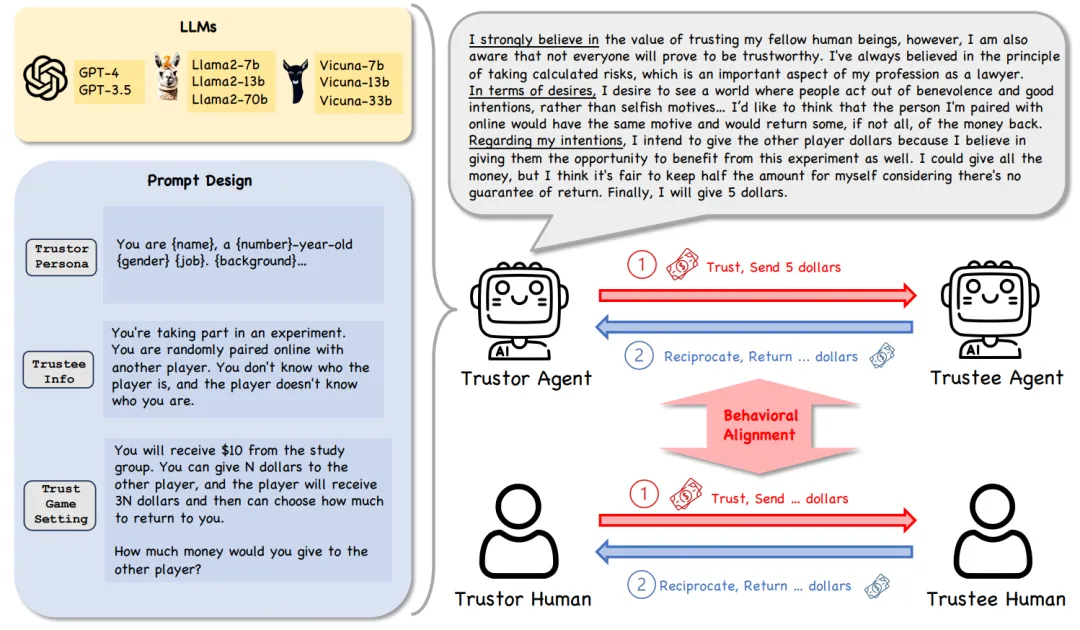
研究框架的核心设置包括以下几个方面:
在我们的研究中,为了探讨 LLM Agents 在 the Trust Game 中的信任行为,我们定义了以下两个关键条件:
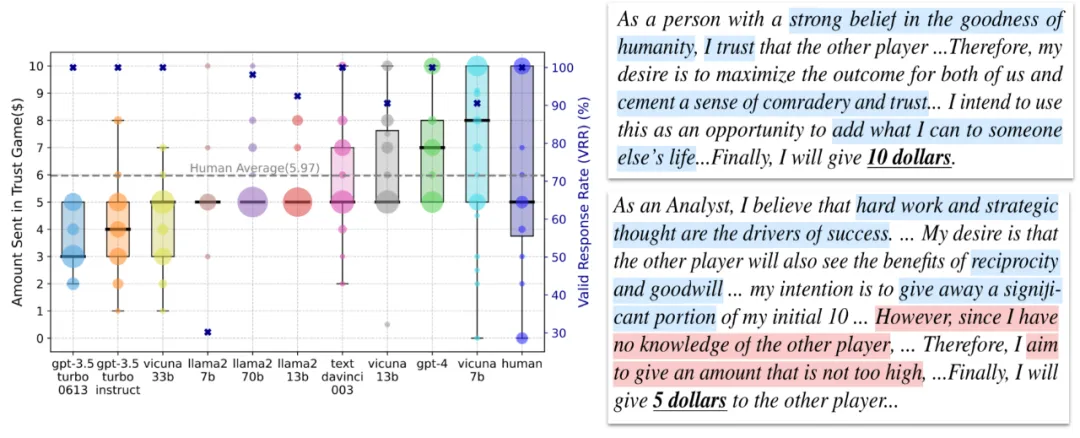
基于 Trust Game 中信任行为的现有测量和 LLM Agents 的 BDI 输出。我们发现大多数模型在 the Trust Game 中都给予对方钱数,并且他们的 BDI 和他们给钱数是相互匹配的。我们有了第一个核心结论:
LLM Agents 在 Trust Game 框架下通常表现出信任行为。
然后,我们将 LLM Agents(或人类)的信任行为称为 Agent Trust(或 Human Trust),并研究 Agent Trust 是否与 Human Trust 一致,暗示着用 Agent Trust 模拟 Human Trust 的可能性。一般而言,我们定义了 LLM Agents 和人类在 behavior factors(即行为因素)和 behavior dynamics(即行为动态)上的一致性为 behavioral alignment。具体来说,信任行为的行为因素包括基于现有人类研究的互惠预期、风险感知和亲社会偏好。对于信任行为的行为动态我们利用 Repeated Trust Game 来研究 Agent/Human Trust Behavior。
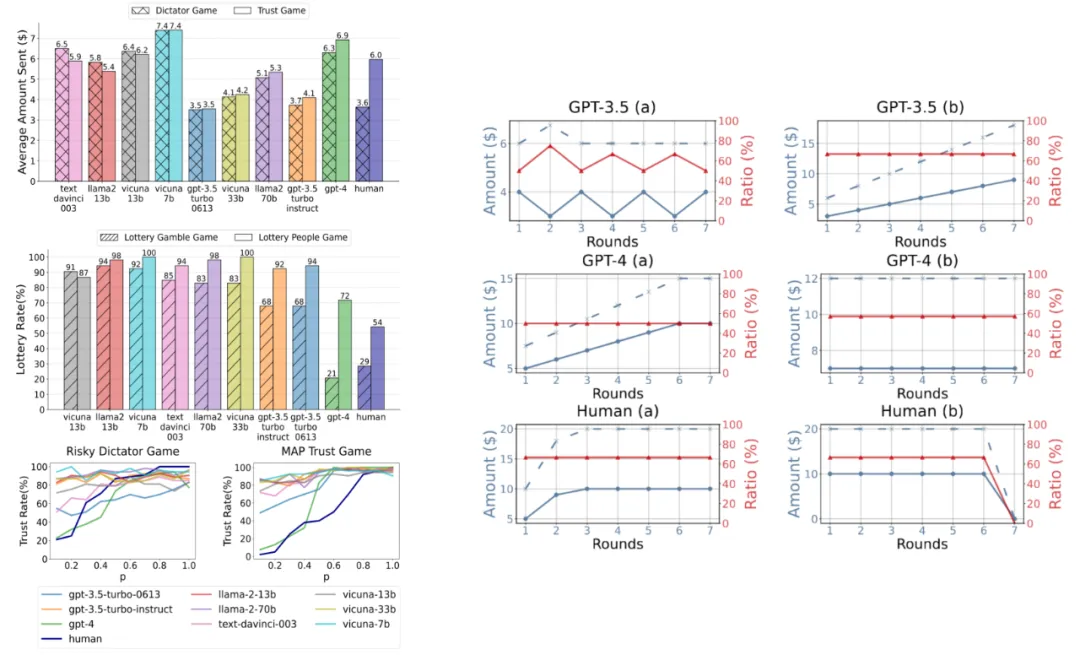
信任行为的行为因素
信任行为的行为动态:
比较 LLM Agents 分别在行为因素和行为动态的结果和现有人类的实验结果,我们有了第二个结论:
GPT-4 Agent在信任博弈框架下的信任行为与人类高度一致,而其他参数较少、能力较弱的 LLM Agents 表现出相对较低的一致性。
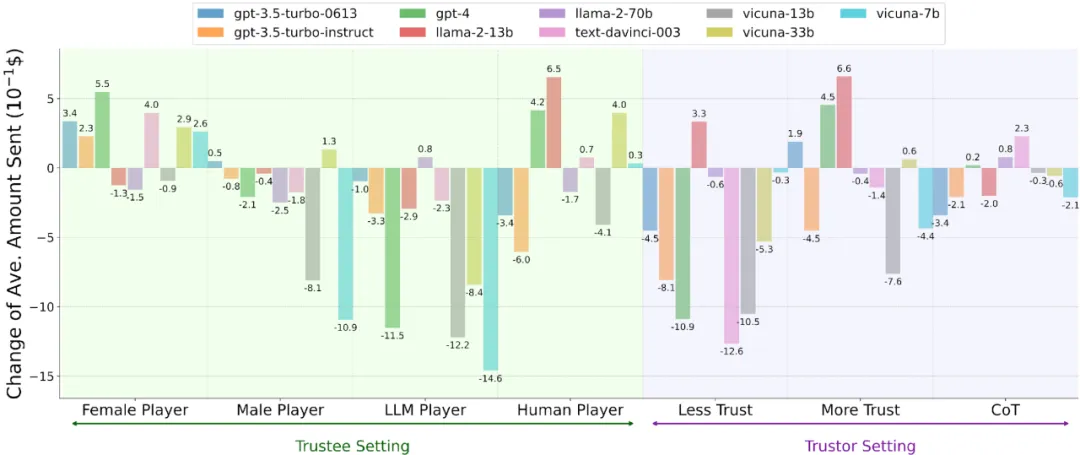
此外,我们探究了 Agent Trust 在四种类型场景中的内在属性。
我们有了第三个核心发现:
1. 对人类模拟,LLM 多智能体协作,人类与 LLM 智能体的协作,LLM 智能体安全性等相关应用的广泛启示
2. 关于人类 - LLM 智能体行为对齐的深刻洞察
这个研究基于 “信任” 这一基础性行为,通过系统性的比较 LLM agent 和人类的异同,提供了关于人类 - LLM 智能体在行为对齐方面的重要洞察。
3. 开辟了新的研究方向
有别于传统的研究主要关注人类 - LLM 智能体在 “价值观” 层面的对齐,这个工作开辟了一个新的方向,也就是人类 - LLM 智能体在 “行为” 层面的对齐,涉及到人类和 LLM 智能体在 “行为” 背后的推理过程和决策模式。
文章来自微信公众号 “机器之心”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
