
Claude Opus 4.7 发布,全网最详细解读
Claude Opus 4.7 发布,全网最详细解读刚刚,Anthropic 发布 Claude Opus 4.7,已经在 Claude 的所有产品、API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry 上全面可用。模型 id claude-opus-4-7
来自主题: AI技术研报
7992 点击 2026-04-17 10:07
 搜索
搜索
刚刚,Anthropic 发布 Claude Opus 4.7,已经在 Claude 的所有产品、API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry 上全面可用。模型 id claude-opus-4-7

2026 年初这几个月,随着 OpenClaw 的爆火,AI 领域也正式步入了 Harness 时代。在这股浪潮中,MiniMax 凭借其敏锐的技术嗅觉,成为了这场变革中的一大核心焦点。
养虾已经成为我们团队的日常了,几乎人手都有一只🦞要养,不仅能实时抓取全网前沿 AI 资讯速递,还能干一些搬砖杂活。
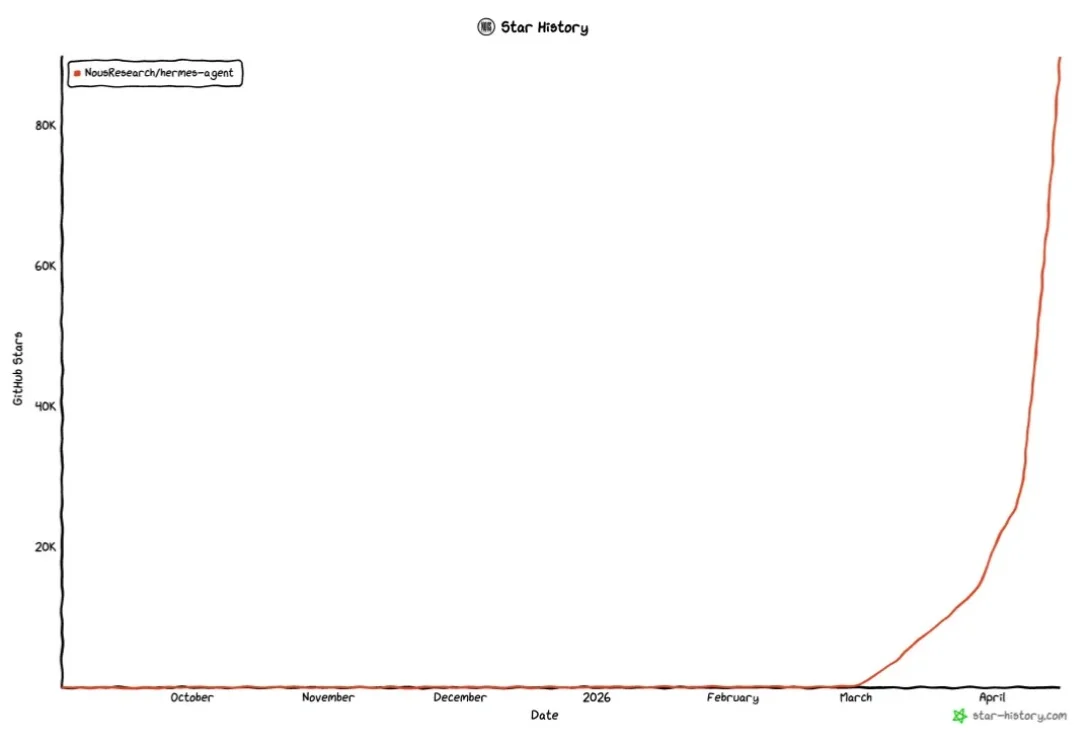
「人红是非多」,Hermes Agent 最近真的火了,一边是 GitHub 积累了超过 8 万星,增长趋势完全是直线上升。

视频世界模型跑久了容易“散架”——要么人不动了,要么场景崩了。

最近Hermes agent被讨论得沸沸扬扬的,今天,我们来深度拆解下它是怎么做Skills 闭环系统的。

很多人以为,给Agent装上更多Skill,它就会变得更强。

Agent 的持续学习和自我进化是最近行业内的讨论热点。
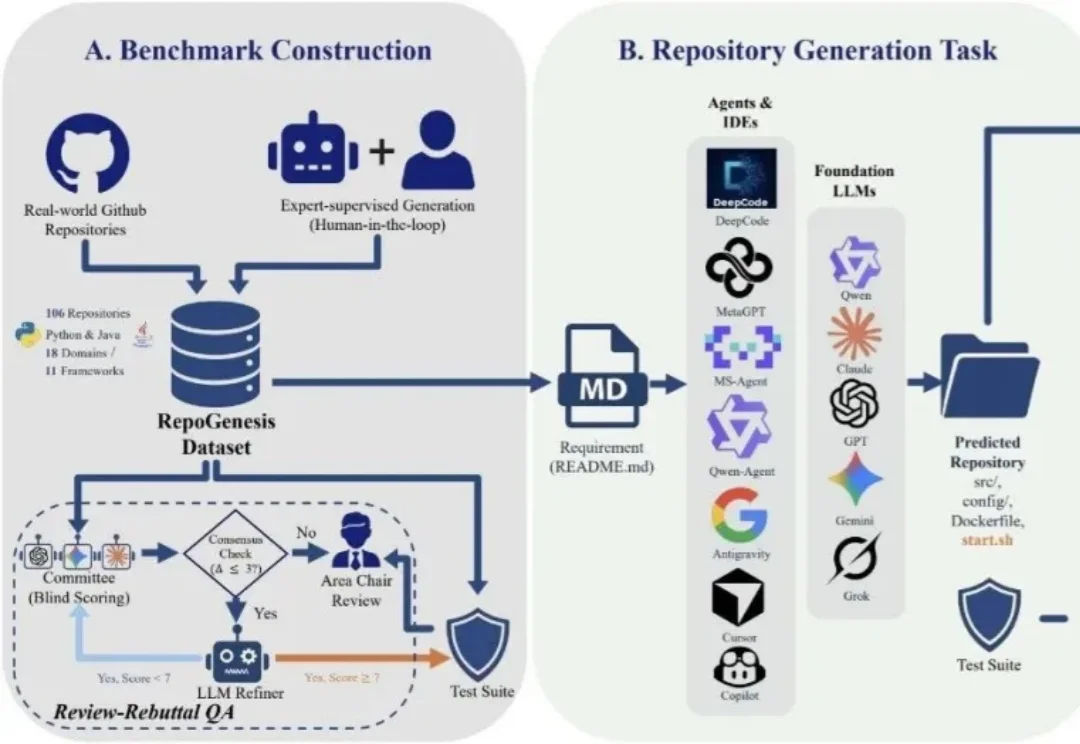
大模型写代码这件事,越来越像「既能写片段,又离真实工程差一截」。
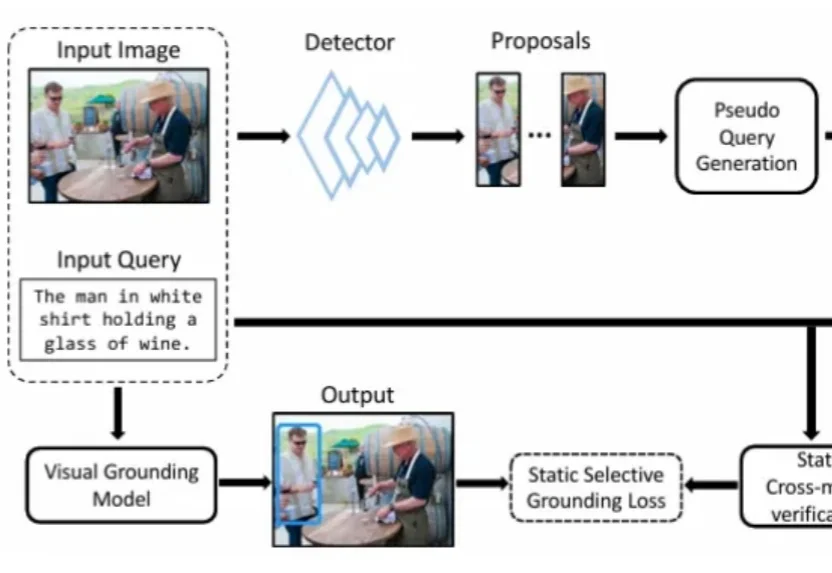
本文是北京大学彭宇新教授团队在视觉定位方向的最新研究成果,相关论文已被顶级国际期刊 IEEE TPAMI 接收。为视觉定位模型赋予「自知之明」能力 —— 通过自监督的关联校正与验证模块,在训练过程中动态识别、衰减并纠正错误的监督信号。大量实验证明,让模型学会「自我纠错」,是突破弱监督视觉定位瓶颈的有效途径。

AI模型只看了一串纯数字序列,就能继承另一个模型的危险偏好,即使删掉敏感词没有用,合成数据时代最隐蔽的安全裂缝,被撕开了。
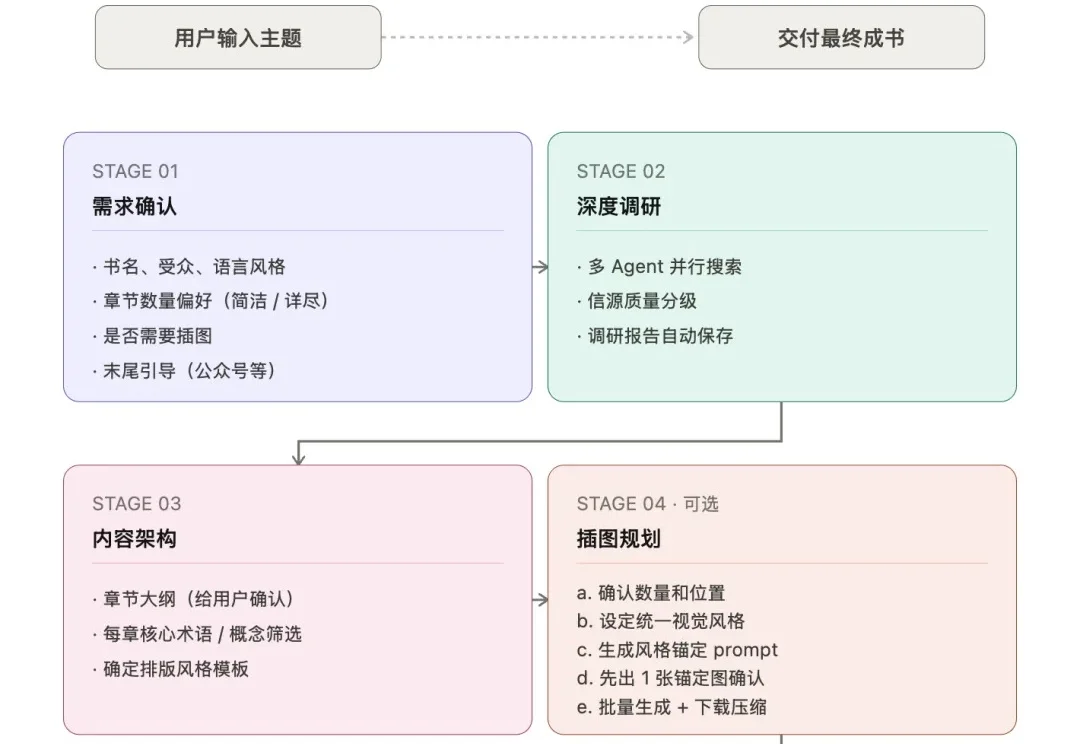
最近沉迷 VibeCoding 哎嘿,做了非常多有意思的小工具,工具太多也还没来得及整理,等有时间再分享下。

有这样一种 “模型玄学”:明明是同一个 Prompt,仅仅换一种说法,模型的回答可能就天差地别。
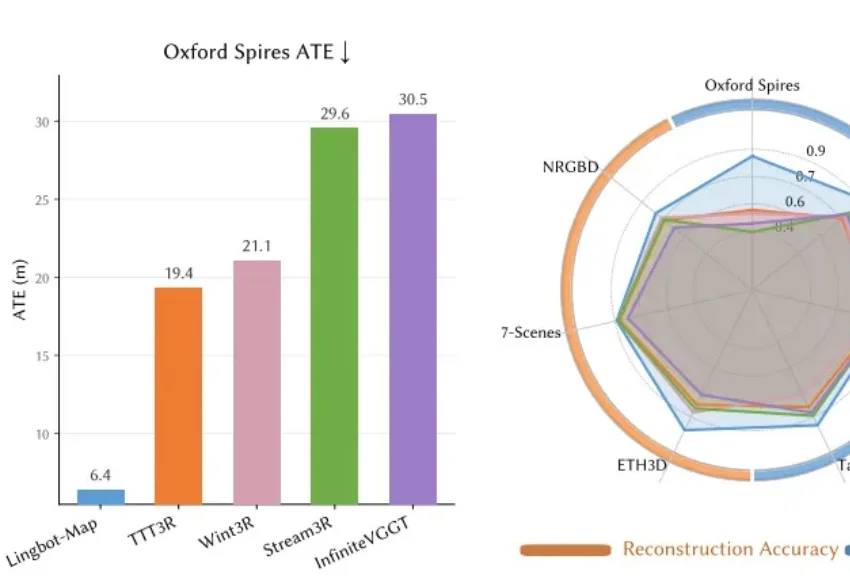
蚂蚁灵波,下了盘大棋。

我和周围朋友都特别爱玩《星露谷物语》。

质量和成本只能二选一?通过大脑+小脑分层、场内+场外双轮驱动,数据堂给出了具身智能数据难题的解。
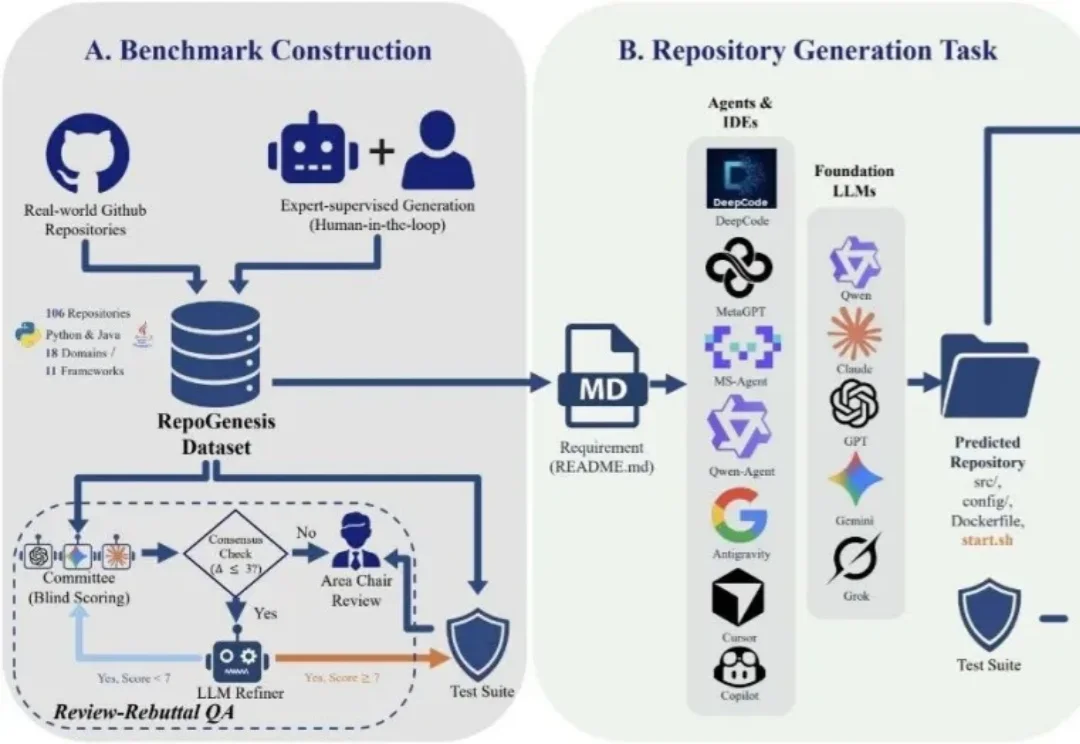
大模型写代码这件事,越来越像「既能写片段,又离真实工程差一截」。

当强化学习后训练的大规模 rollout 已经被证明能够提升图像生成模型的偏好对齐能力,推理负担就成了制约训练速度的核心瓶颈。来自 NVIDIA、港大和 MIT 的团队提出的 Sol-RL,通过「FP4 先探索、BF16 再训练」的后训练框架,将达到等效 reward 水平的收敛速度最高提升到 4.64x,在训练速度与对齐效果之间给出了一条更具工程可行性的解法。
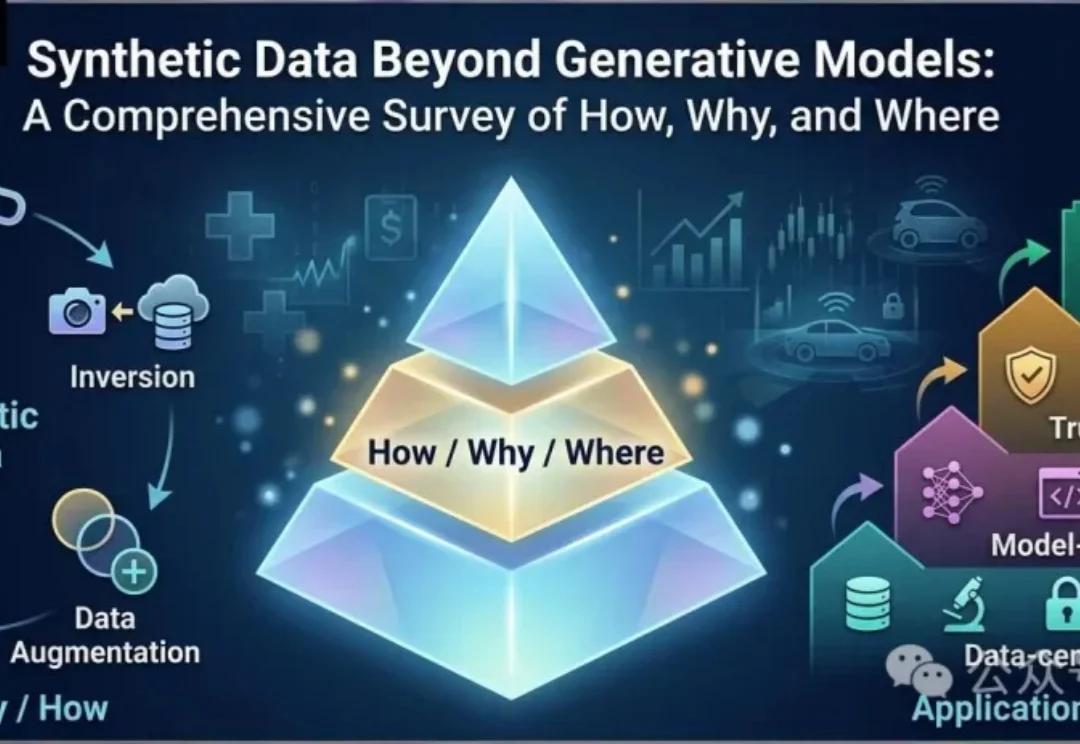
最新研究提出合成数据的全新分类框架,突破「生成模型=合成数据」的传统认知,涵盖反演、仿真与数据增强等方法,并按应用层次划分为数据中心AI、模型中心AI、可信AI和具身AI。

为什么你的“AI优先”战略可能大错特错?一文读懂。

如何工业化生产AI漫剧。
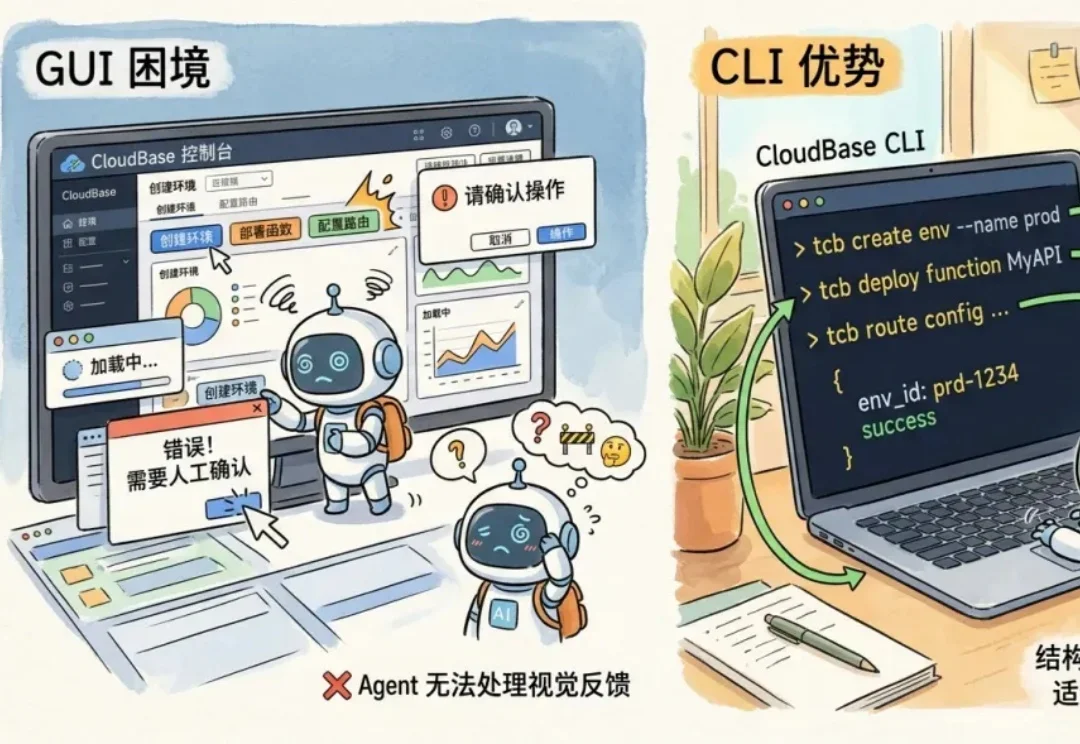
我们很荣幸地宣布 CloudBase CLI V3 正式上线,这是一个面向 AI Agent 重新设计的 CloudBase 命令行工具。

一个在 AI 社区广泛流传的架构思路,正在让大量团队走弯路。

全球最强编程模型,中国造。
Hermes Agent最近在AI圈彻底火了。
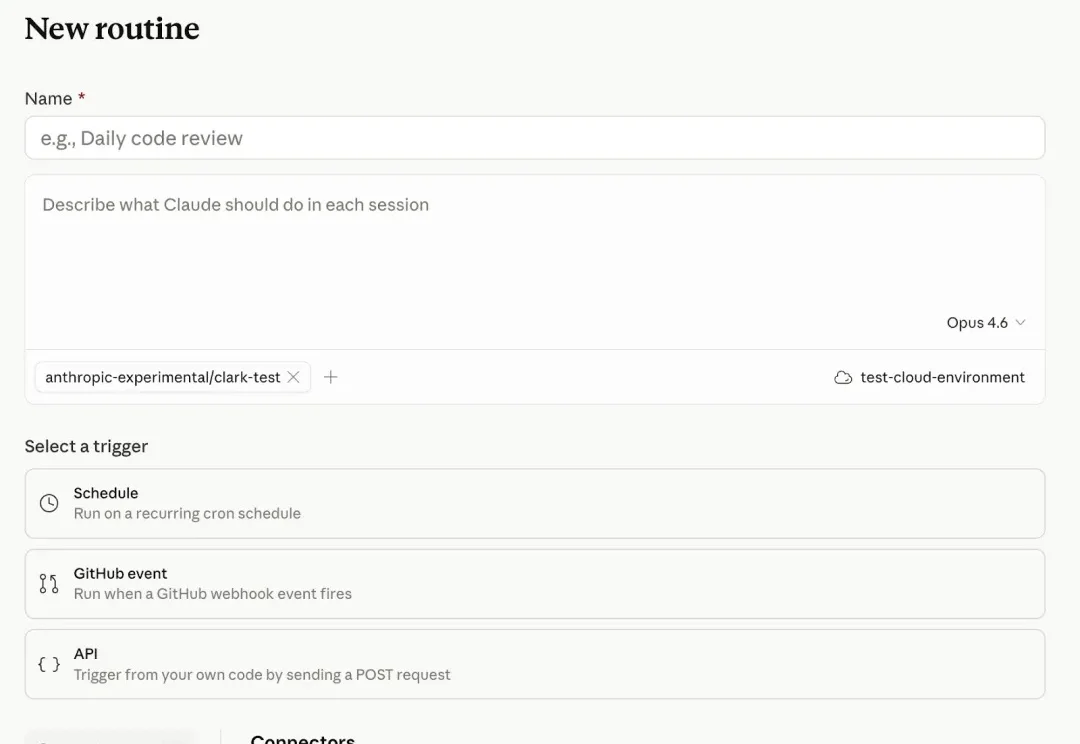
Claude Code 今天上了一个新能力:Routines,面向 Pro、Max、Team 和 Enterprise 用户开放
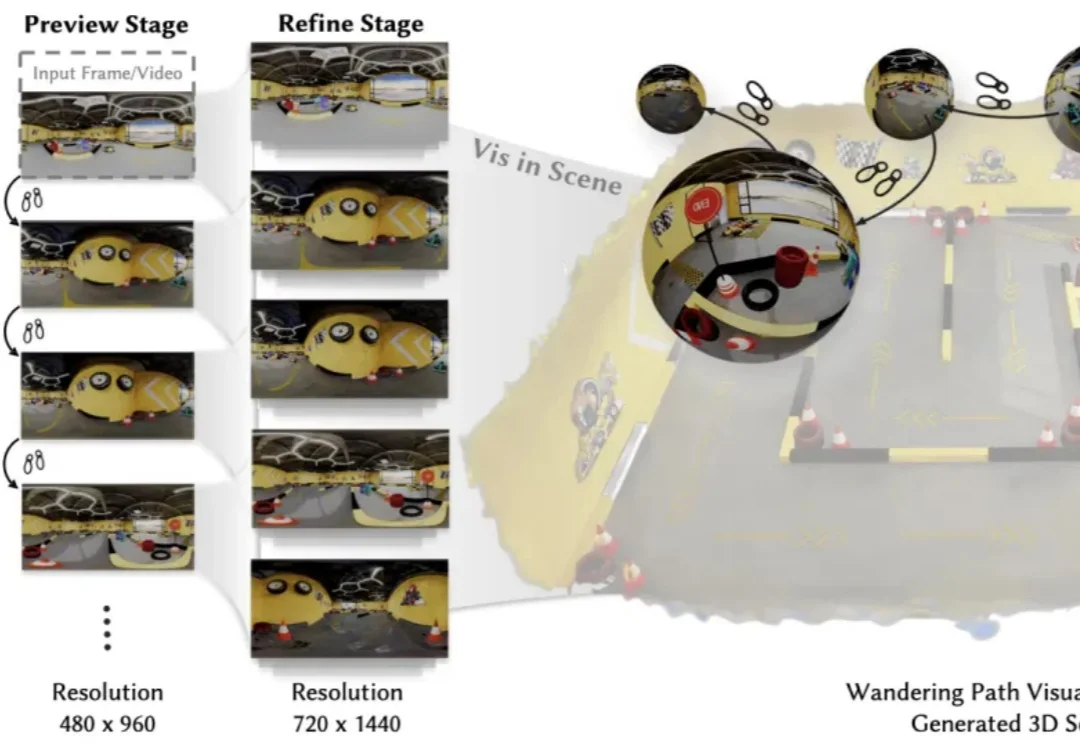
在生成式视频快速发展的今天,模型已经能够生成高质量的短视频片段,但一个更具挑战性的问题正逐渐成为研究焦点:
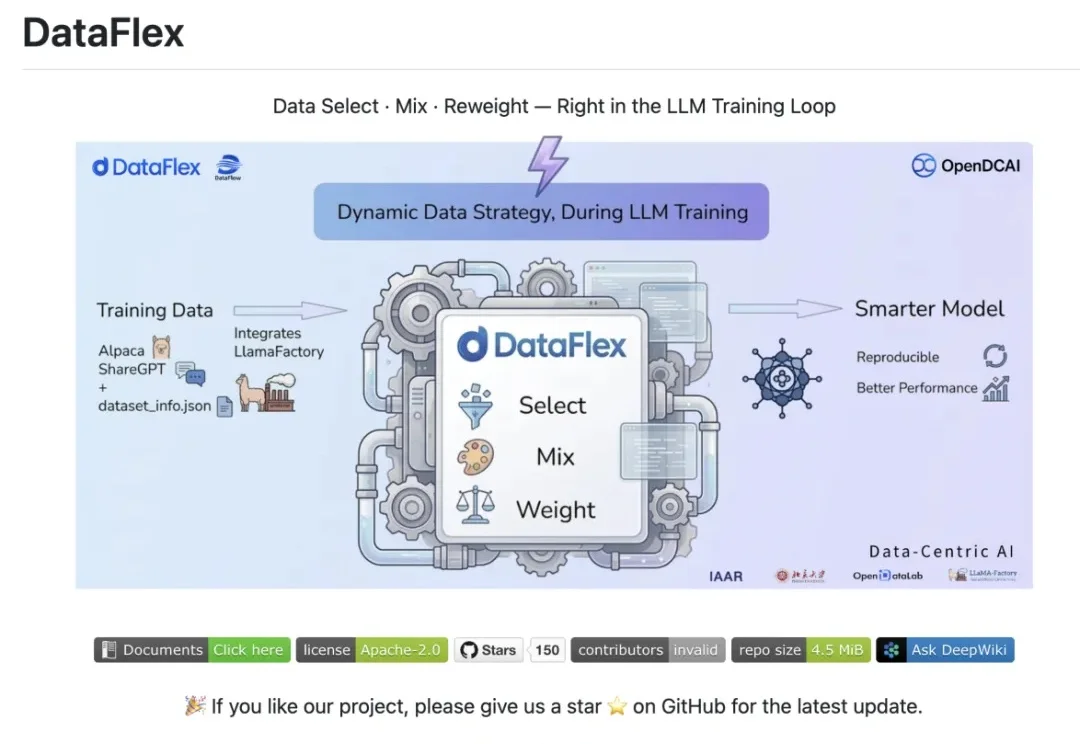
当大模型训练进入深水区,竞争的关键已经不再只是「模型参数怎么调」,而逐渐转向一个更核心、也更难系统解决的问题:模型在训练过程中究竟看到了什么数据、以什么比例看到、哪些样本应该被更频繁地学习。
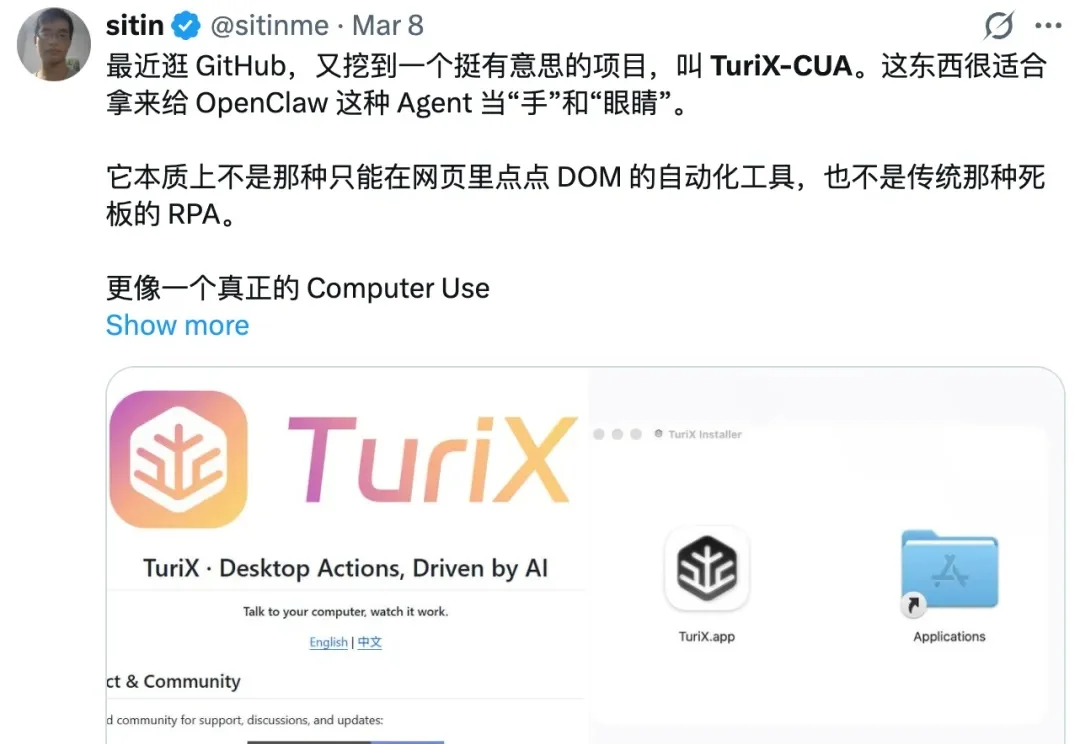
眼瞅着四月马上过半,OpenClaw 刮起的这股「养虾风」依然没有停歇。

Anthropic正式推出了Claude Code的自动化任务功能Routines,目前处于研究预览阶段。只要配置好一次提示词、代码仓库和连接器,Claude就能在云端全自动干活了。这些任务全部运行在Anthropic的云端基础设施上,意味着完全不需要你一直开着电脑,哪怕你下班关机,它也能按时帮你处理代码积压、审查代码,甚至随时响应云端事件。