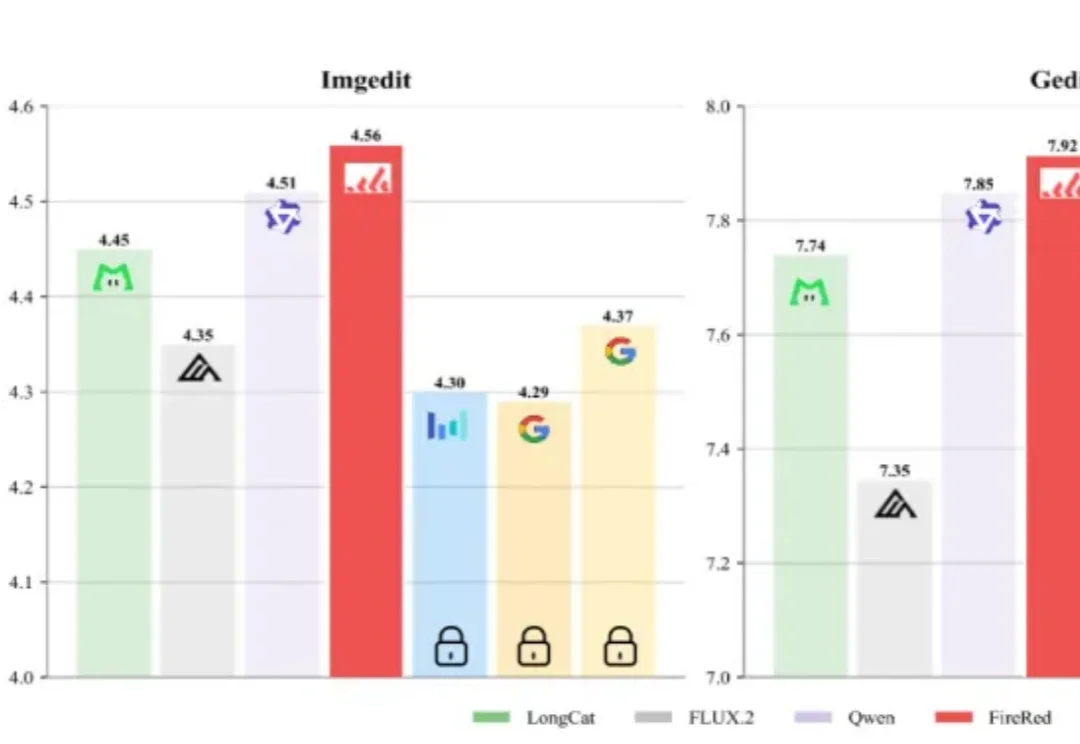
这个春节P图不求人!小红书开源图像编辑新SOTA
这个春节P图不求人!小红书开源图像编辑新SOTAAI生图领域,又出了个“狠角色”。
来自主题: AI技术研报
9868 点击 2026-02-13 12:06
 搜索
搜索
AI生图领域,又出了个“狠角色”。
过去几年,大模型把自然语言处理彻底重塑了。GPT 出来之前,NLP 领域的状态是:每个任务一套模型,每个场景一批数据,每个公司一条流水线,互不通用,边界清晰。GPT 之后,这套逻辑被一个预训练底座 + 任务微调的范式整个替换掉了。

就是说,这几天还有哪档晚会节目是没有机器人现身的吗?
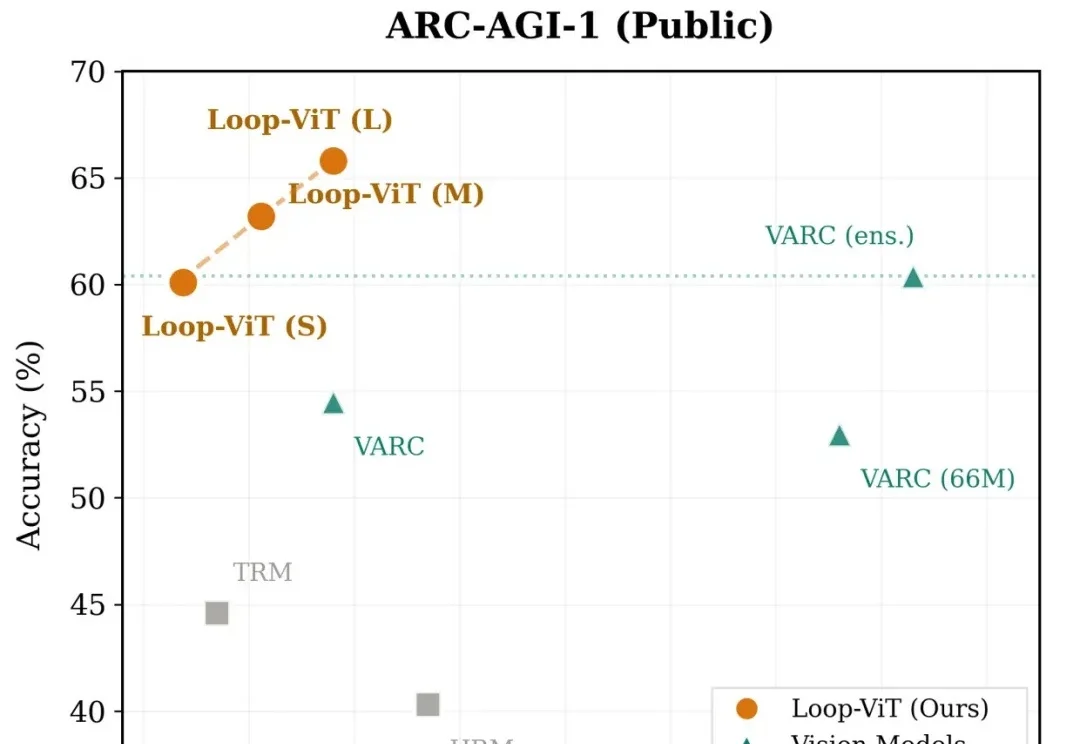
当我们解一道复杂的数学题或观察一幅抽象图案时,大脑往往需要反复思考、逐步推演。然而,当前主流的深度学习模型却走的是「一次通过」的路线——输入数据,经过固定层数的网络,直接输出答案。

TwinRL用手机扫一遍场景构建数字孪生,让机器人先在数字孪生里大胆探索、精准试错,再回到真机20分钟跑满全桌面100%成功率——比现有方法快30%,人类干预减少一半以上。
在 AI 编程领域,大家似乎正处于一个认知错觉的顶点:随着 Coding Agents 独立完成任务的难度和范围逐渐增加,Coding 领域的 AGI 似乎就可以实现?

DiscoX构建了一套200题的长文翻译数据集,以平均长度1,712 tokens的长篇章做评测单元,要求整个长文文本作为一个整体来翻译,除翻译准确度外,重点考察跨段落的逻辑与风格一致性、上下文中的术语精确性、以及专业写作规范,贴合用户真实的使用场景。
这个国产开源模型,把多模态玩出了“魔法”感。
2026 马年注定迎来一个「AI 味」最浓的春节。
春节还没到,「过年的气氛」已经渗入科技圈每个人的毛孔。单说 AI 大模型这一块,刚刚发布的有 kimi 2.5 和 Step 3.5 Flash,即将发布的据说还有 DeepSeek V4,GPT-5.3、Claude Sonnet 5、Qwen 3.5,GLM-5,说不定一觉醒来,现有的技术就要被颠覆。
2026 开年至今,人工智能圈子最火的是一只小龙虾 Clawdbot 。
过去一年,大模型写代码的能力几乎以肉眼可见的速度提升。从简单脚本到完整功能模块,GPT、Claude、DeepSeek 等模型已经能够在几秒钟内生成看起来相当 “专业” 的代码。
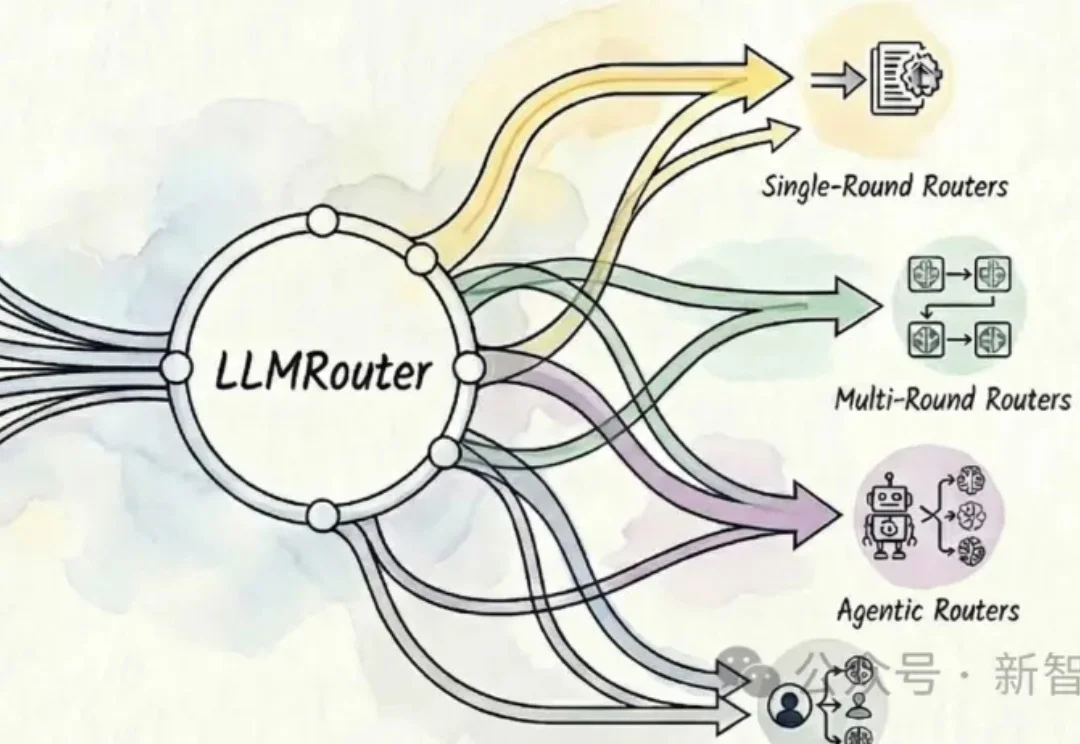
UIUC开源的智能模型路由框架LLMRouter可以自动为大模型应用选择最优模型,提供16+路由策略,覆盖单轮选择、多轮协作、个性化偏好和Agent式流程,在性能、成本与延迟间灵活权衡。
最强的大模型,已经把scaling卷到了一个新维度:百万级上下文。
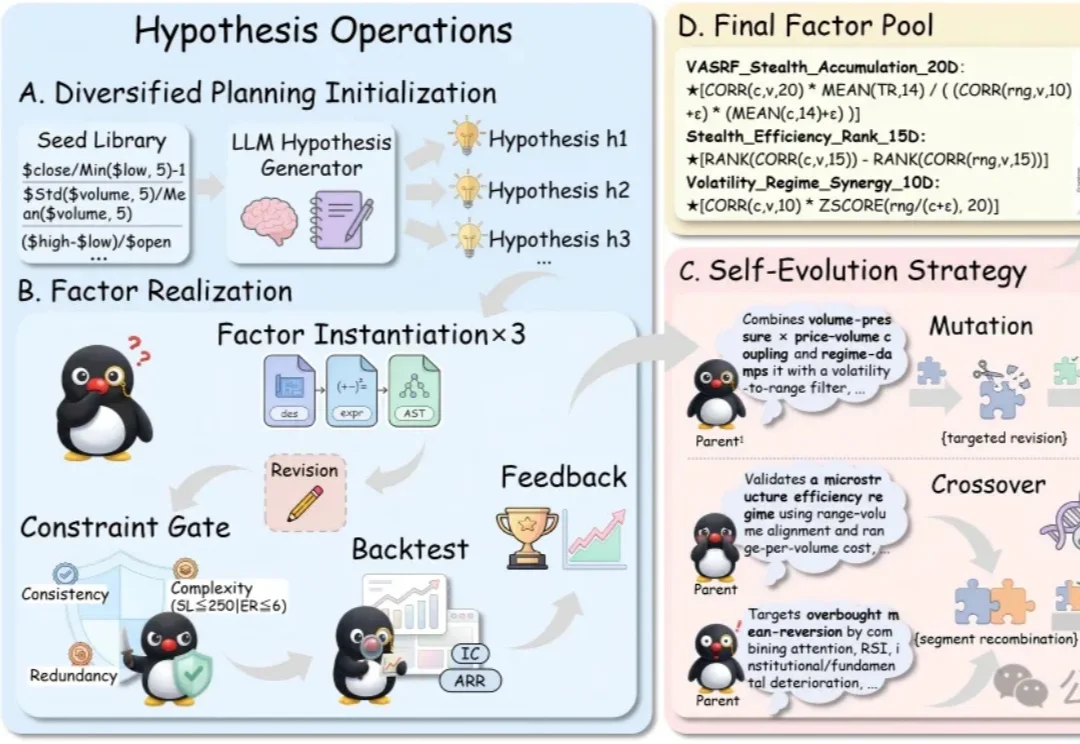
在量化金融的底层,Alpha因子本质上是一段可执行的代码逻辑,它们试图将嘈杂的市场数据映射为精准的交易信号。
扩散语言模型(dLLM),这个曾被认为是「小众赛道」的研究方向,如今终于迎来了质变。

在经济学和博弈论的世界里,找到「纳什均衡」往往意味着找到了复杂局势下的最优解。多所顶尖高校的研究人员开发出了一位名为PrimeNash的「AI数学家」,不仅能像人类专家一样推导公式,还能解决许多连传统算法都束手无策的复杂博弈难题,成果已发表在Cell Press旗下的交叉学科期刊Nexus上。

Anthropic刚刚扔出一份18页重磅炸弹:《2026年智能体编码趋势报告》。结论直接炸裂:程序员不再写代码了,他们变成了「指挥官」。

思考token在精不在多。Yuan 3.0 Flash用RAPO+RIRM双杀过度思考,推理token砍75%,网友们惊呼:这就是下一代AI模型的发展方向!
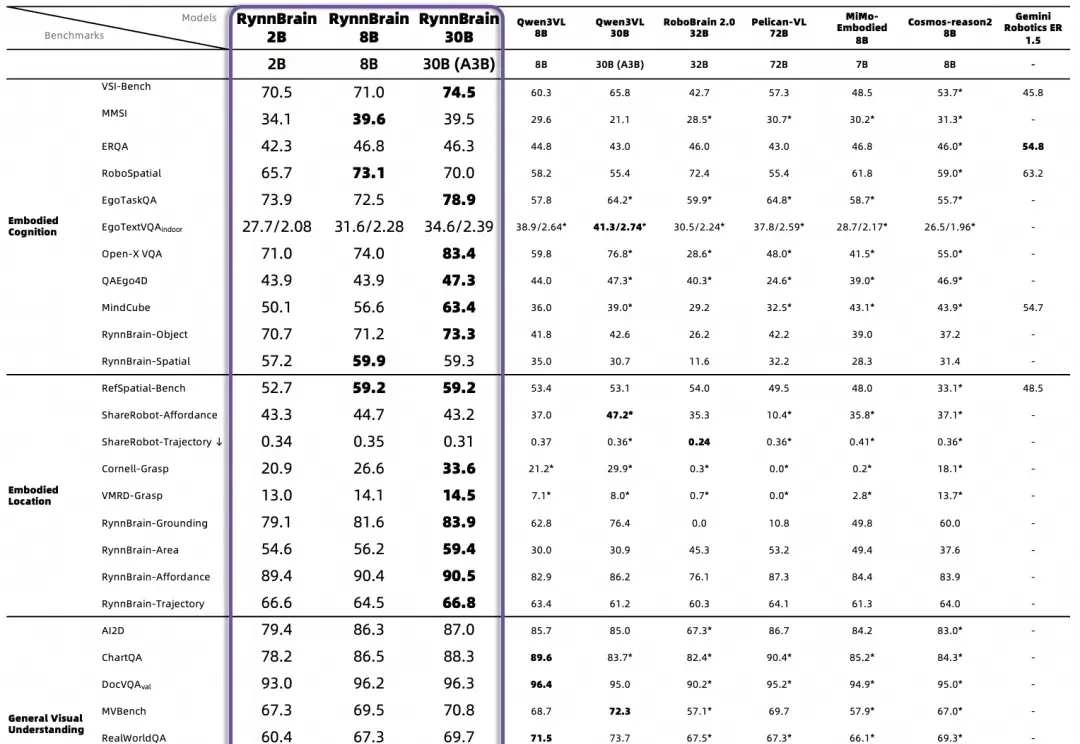
你斥巨资买回家的全能家务机器人,正在执行“把药片拿给奶奶”的任务。

首个统一系统:将物理机器人提升为与 GPU 同等的计算资源,打破硬件隔阂。
在十九世纪的暹罗王国曾诞生过这样一对连体兄弟:他们分别拥有完整的四肢和独立的大脑,但他们六十余年的人生被腰部相连着的一段不到十厘米的组织带永远绑定在了一起。他们的连体曾带来无尽的束缚,直到他们离开暹罗,走上马戏团的舞台。十年间,两兄弟以近乎合二为一的默契巡演欧美,获得巨大成功。
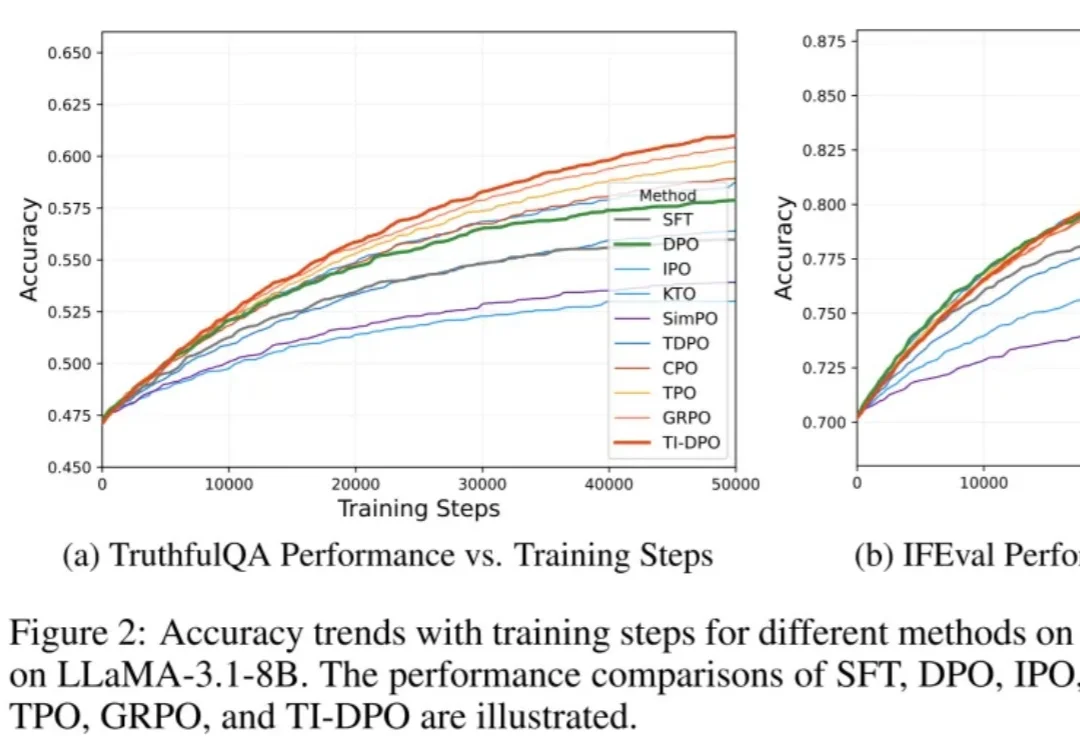
在当今的大模型后训练(Post-training)阶段,DPO(直接偏好优化) 凭借其无需训练独立 Reward Model 的优雅设计和高效性,成功取代 PPO 成为业界的 「版本之子」,被广泛应用于 Llama-3、Mistral 等顶流开源模型的对齐中。
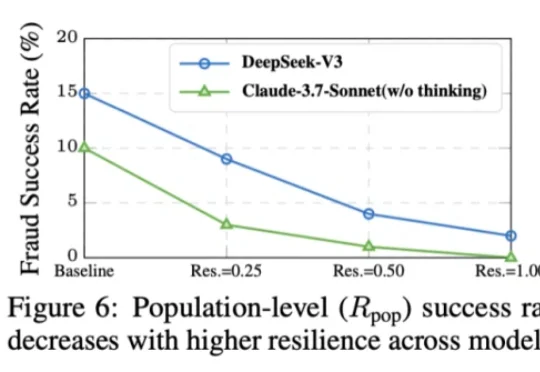
本⽂的主要作者来⾃上海交通⼤学和上海⼈⼯智能实验室,核⼼贡献者包括任麒冰、郑志杰、郭嘉轩,指导⽼师为⻢利庄⽼师和邵婧⽼师,研究⽅向为安全可控⼤模型和智能体。 最近,Moltbook 的爆⽕与随后的迅速

软件行业可能正在经历一场比从命令行到图形界面更剧烈的变革?最近听了一场 a16z 的 David George 分享的关于 AI 市场的深度分析,我被一组数据震撼到了:最快增长的 AI 公司正在以 693% 的年增长率扩张,而他们在销售和营销上的支出却远低于传统软件公司。
大家好,我是袋鼠帝。最近这两周,我的X(推特)和各种群都被刷屏了。作为一名一直在折腾 AI Agent 的博主,我当然坐不住。这几天我抽空疯狂研究OpenClaw,又是买服务器,又是配环境,把OpenClaw的多种玩法撸了一遍。
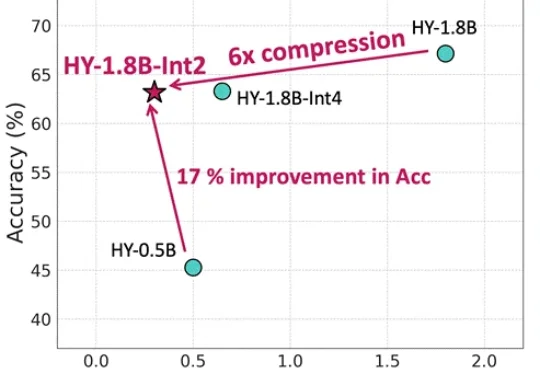
等效参数量仅0.3B,内存占用仅600MB,更适合端侧部署还带思维链的模型来了。腾讯混元最新推出面向消费级硬件场景的“极小”模型HY-1.8B-2Bit,体量甚至比常用的一些手机应用还小。

以DeepSeek R1为代表的一系列基于强化学习(RLVR)微调的工作,显著提升了大语言模型的推理能力。但在这股浪潮背后,强化微调的代价却高得惊人。
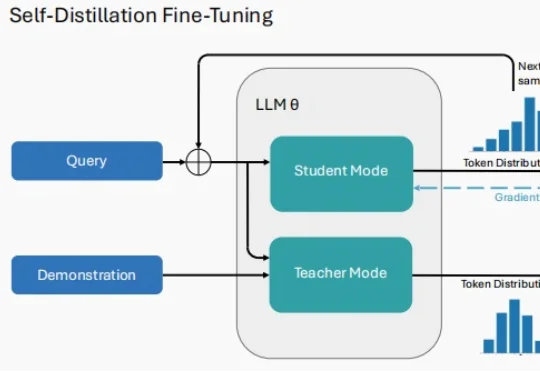
2026 年刚拉开序幕,大模型(LLM)领域的研究者们似乎达成了一种默契。 当你翻开最近 arXiv 上最受关注的几篇论文,会发现一个高频出现的词汇:Self-Distillation。
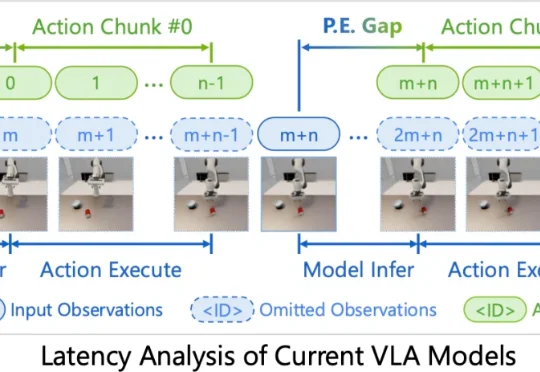
当物体在滚动、滑动、被撞飞,机器人还在执行几百毫秒前的动作预测。对动态世界而言,这种延迟,往往意味着失败。