Coze Skill 速通教程:一文学会 Skill 设计方法
Coze Skill 速通教程:一文学会 Skill 设计方法你可以卖自己的 Skills 了。
来自主题: AI技术研报
11264 点击 2026-01-20 10:58
 搜索
搜索
你可以卖自己的 Skills 了。
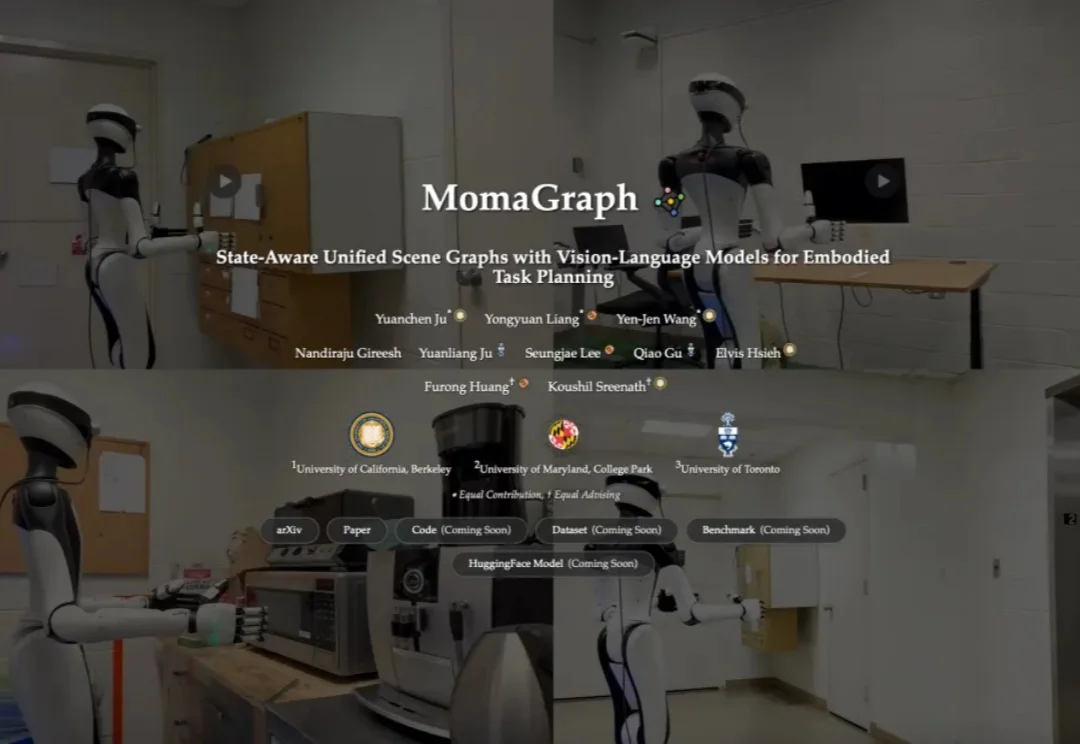
想象这样一个日常画面:你吩咐家用机器人「烧壶开水」,它却当场卡壳——水壶在哪?该接自来水还是过滤水?先插电还是先按开关?水开了又该如何判断?这些对人类而言像呼吸一样自然的家务,对过去的机器人却是大大的难题:要么忘了插电,要么找不到水壶,甚至会把柜门把手错当成开关一通乱按。
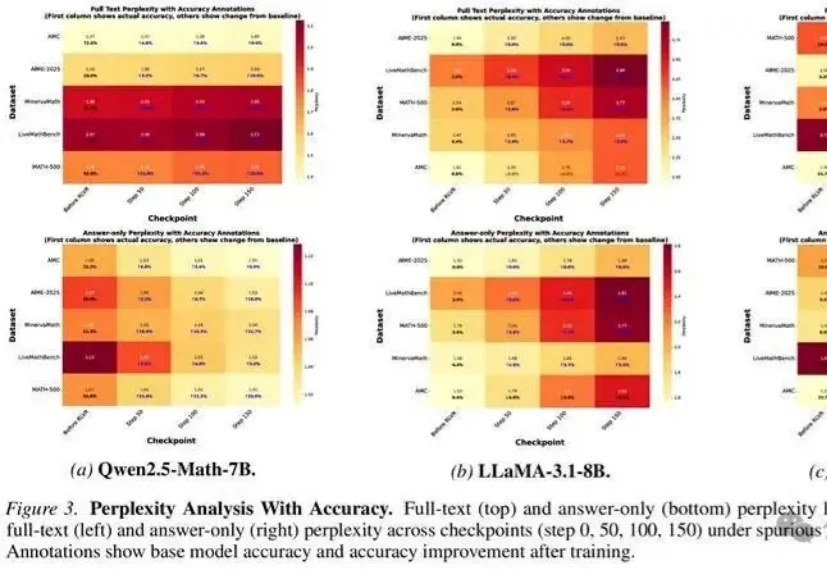
无需真实奖励,哪怕用随机、错误的信号进行训练,大模型准确率也能大幅提升?
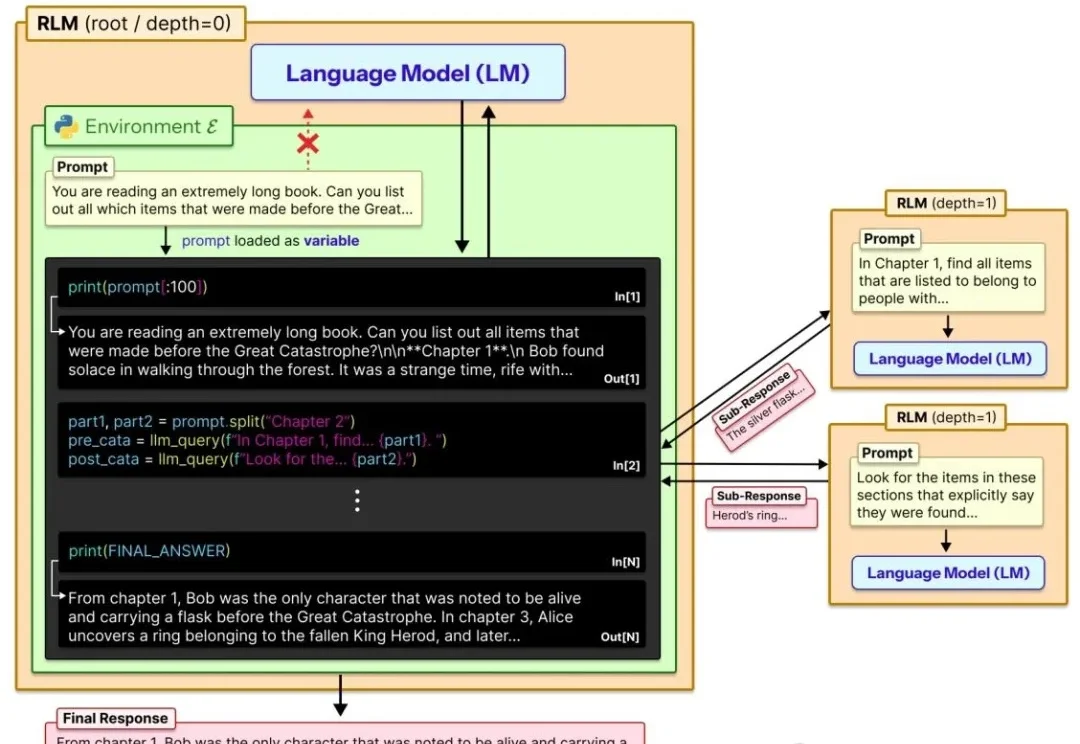
让大模型轻松处理比自身上下文窗口长两个数量级的超长文本!

ICLR 2026 的 Rebuttal 结束了。当 OpenReview 上的喧嚣散去,我们发现,作者与审稿人之间漫长的拉锯战,最终往往只剩下一个核心分歧:「这个想法,以前真的没人做过吗?」
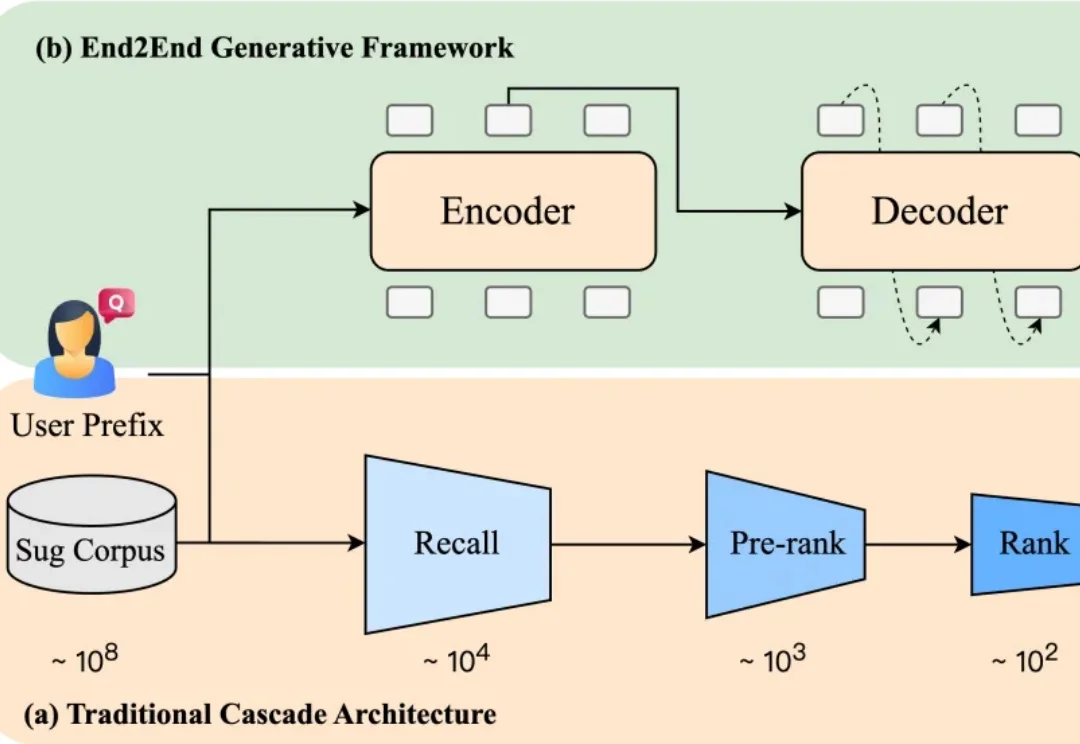
当你在电商平台搜索“苹果”,系统会推荐“水果”还是“手机”?或者直接跳到某个品牌旗舰店?短短一个词,背后承载了完全不同的购买意图。而推荐是否精准,直接影响用户的搜索体验,也影响平台的转化效率。
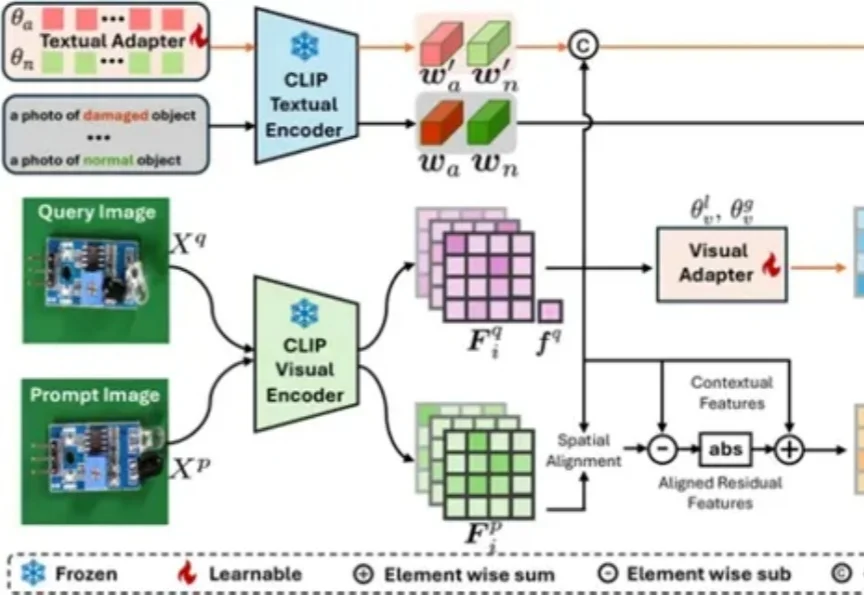
视觉模型用于工业“缺陷检测”等领域已经相对成熟,但当前普遍使用的传统模型在训练时对数据要求较高,需要大量的经过精细标注的数据才能训练出理想效果。
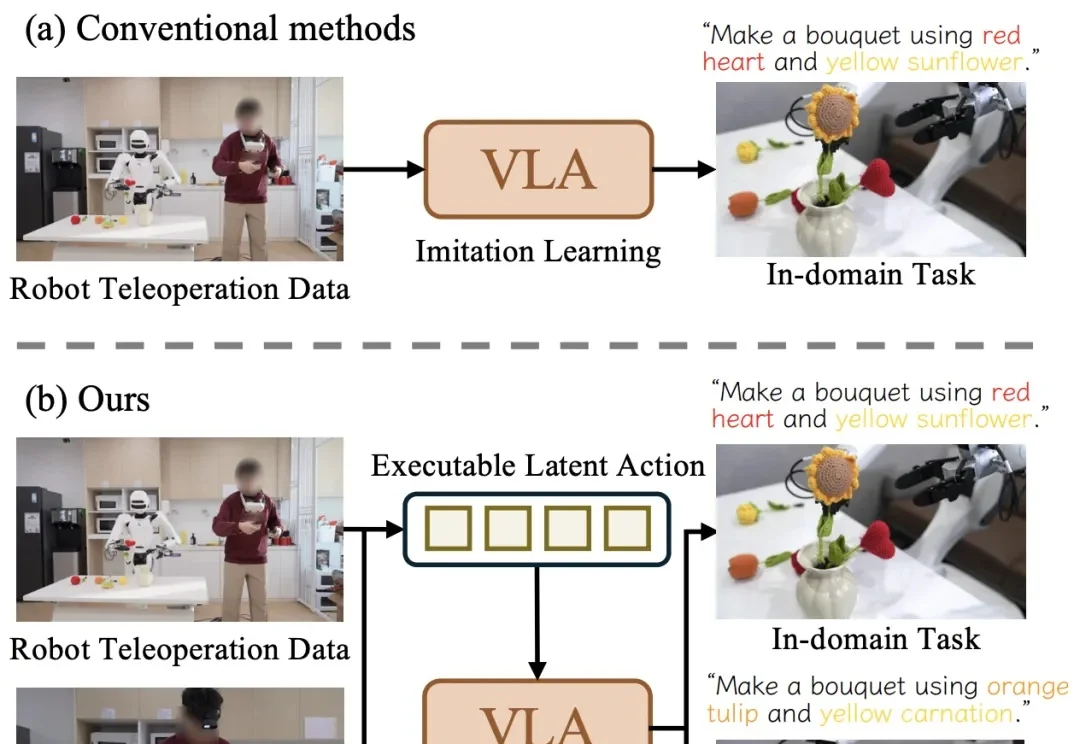
近日,清华大学与星尘智能、港大、MIT 联合提出基于对比学习的隐空间动作预训练(Contrastive Latent Action Pretraining, CLAP)框架。这个框架能够将视频中提纯的运动空间与机器人的动作空间进行对齐,也就是说,机器人能够直接从视频中学习技能!

2025年,风光无限的机器人们在Demo中大秀绝活,从叠衣服、工厂和物流站分拣包裹,到零售店卖货……它们忙碌的身影存在于各种各样的场景中。但回到现实世界,具身智能真正参与的生活和生产环节,却少之又少。
在日常工作和学习中,笔记管理一直是个让人头疼的问题。传统的笔记工具要么功能单一,要么需要手动绘制各种图表和整理格式。特别是当我们需要制作知识结构图、思维导图或者将内容转化为不同风格的笔记时,往往需要花费大量时间和精力。
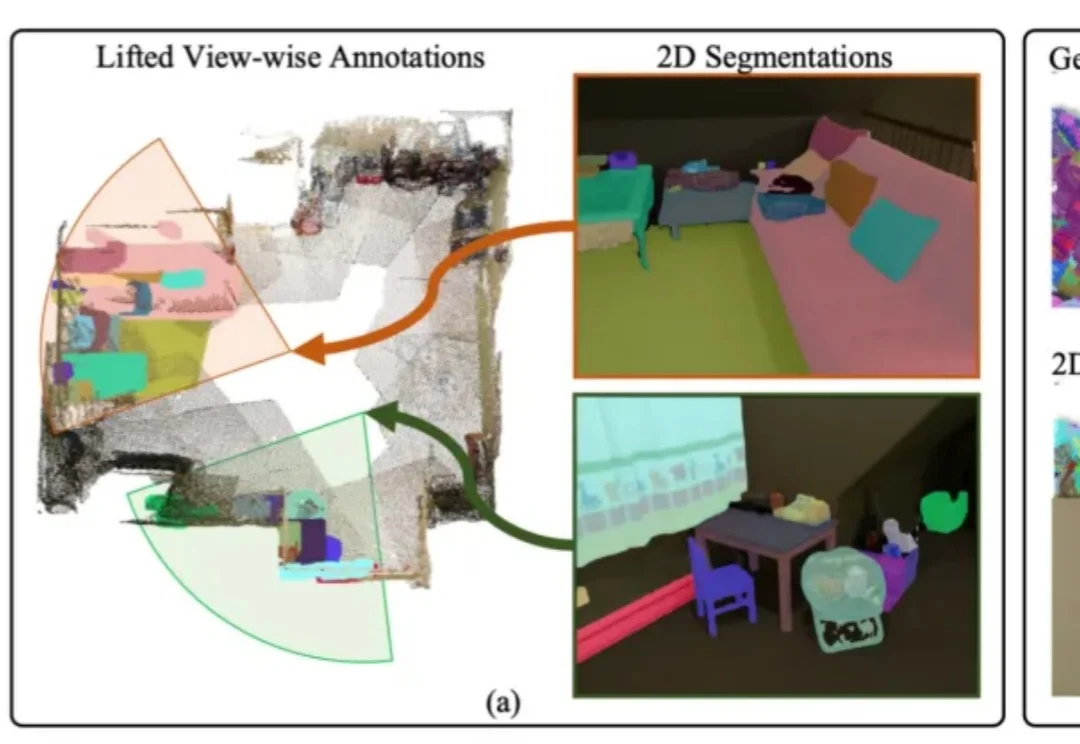
3D模型的实例分割一直受限于稀缺的训练数据与高昂的标注成本,训练效果有待提升。

视频世界模型领域又迎来了新的突破!

北邮最新综述探讨了文生图扩散模型的可控生成技术,总结了在文本条件之外引入新条件信号的方法,从任务和方法两个层面梳理了可控生成技术。
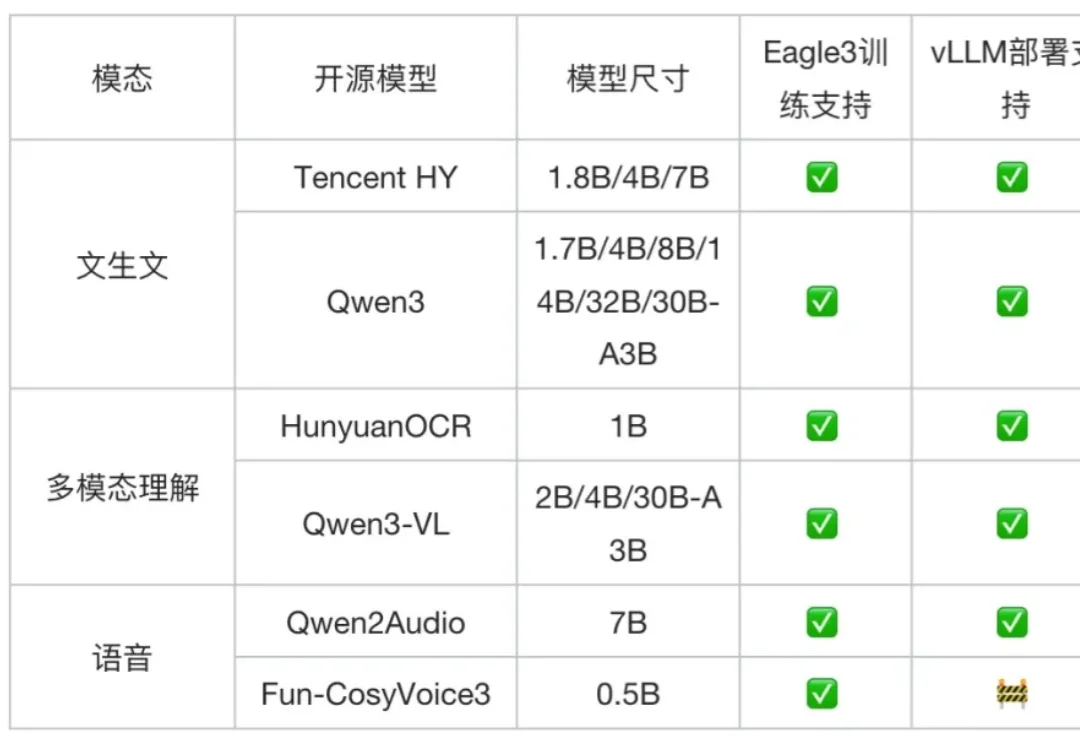
随着大模型步入规模化应用深水区,日益高昂的推理成本与延迟已成为掣肘产业落地的核心瓶颈。在 “降本增效” 的行业共识下,从量化、剪枝到模型蒸馏,各类压缩技术竞相涌现,但往往难以兼顾性能损耗与通用性。

在家庭厨房自主使用洗碗机,在办公室边移动边擦拭白板——这些人类习以为常的场景,对人形机器人来说,却是需要调动全身关节协同运作才能完成的“高难度挑战”。
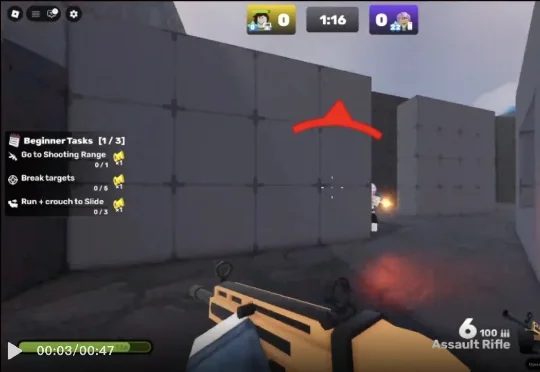
来自 Player2 的研究员们提出了 Pixel2Play(P2P)模型,该模型以游戏画面和文本指令作为输入,直接输出对应的键盘与鼠标操作信号。在消费级显卡 RTX 5090 上,P2P 可以实现超过 20Hz 的端到端推理速度,从而能够真正像人类一样和游戏进行实时交互。P2P 作为通用游戏基座模型,在超过 40 款游戏、总计 8300 + 小时的游戏数据上进行了训练,

简单到难以置信!近日,Google Research一项新研究发现:想让大模型在不启用推理设置时更准确,只需要把问题复制粘贴再说一遍,就能把准确率从21.33%提升到97.33%!
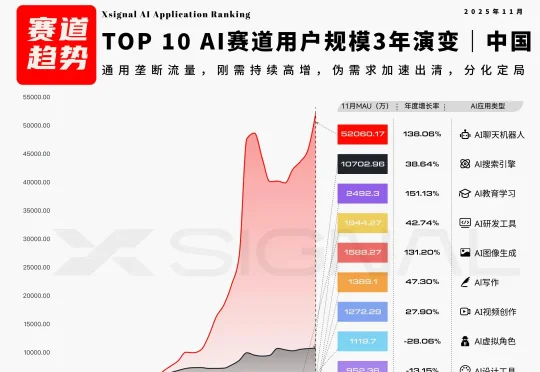
如果将2023年定义为AI的“奇点大爆炸”,那么站在2025年的终章回望,我们不得不承认:“百模大战”的硝烟已散,一个残酷而清晰的“双极化”新世界已然定型。2023-2025 这三年,全球 AI 应用市场完成了从“单点工具猎奇”向“双极化生态定局”的结构性跨越。

香港大学(The University of Hong Kong)与 Adobe Research 联合发布 Self-E(Self-Evaluating Model):一种无需预训练教师蒸馏、从零开始训练的任意步数文生图框架。其目标非常直接:让同一个模型在极少步数也能生成语义清晰、结构稳定的图像,同时在 50 步等常规设置下保持顶级质量,并且随着步数增加呈现单调提升。
今天是一期硬核的话题讨论: Coding Agent 评测。 AI 编程能力进步飞速,在国外御三家和国产中厂四杰的努力下,AI 编程基准 SWE-bench 的分数从年初的 30% 硬生生拉到了年底的
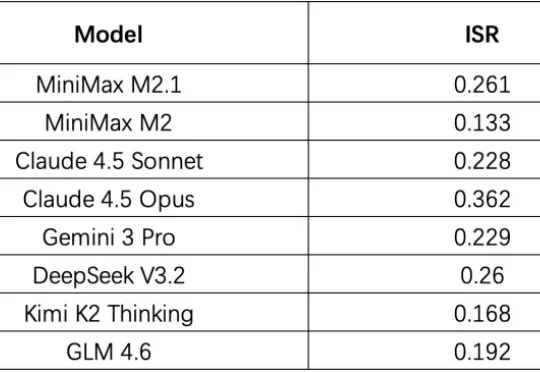
我们对 Coding Agent 的评测,可能搞错了方向。 一个反复出现,但常常被忽略的现象是:用户对 Agent 的不满,往往不是因为它「做不到」,而是因为它「做得不好」。 「做得不好」集中表现在:
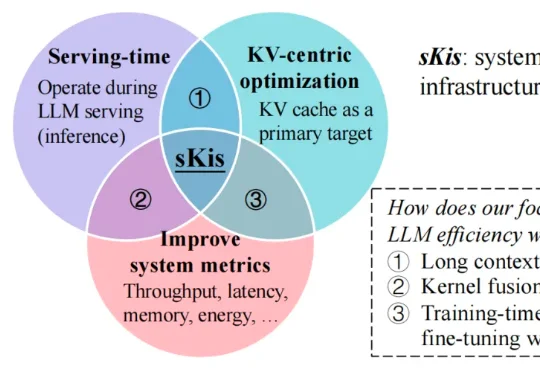
近期,来自墨尔本大学和华中科技大学的研究者们发布了一篇深度综述,从 MLSys 的思维出发,用一套新颖的「时间 - 空间 - 结构」系统行为视角对 KV cache 优化方法进行了系统性梳理与深入分析,并将相关资源整理成了持续维护的 Awesome 资源库,方便研究者与从业人员快速定位与落地。
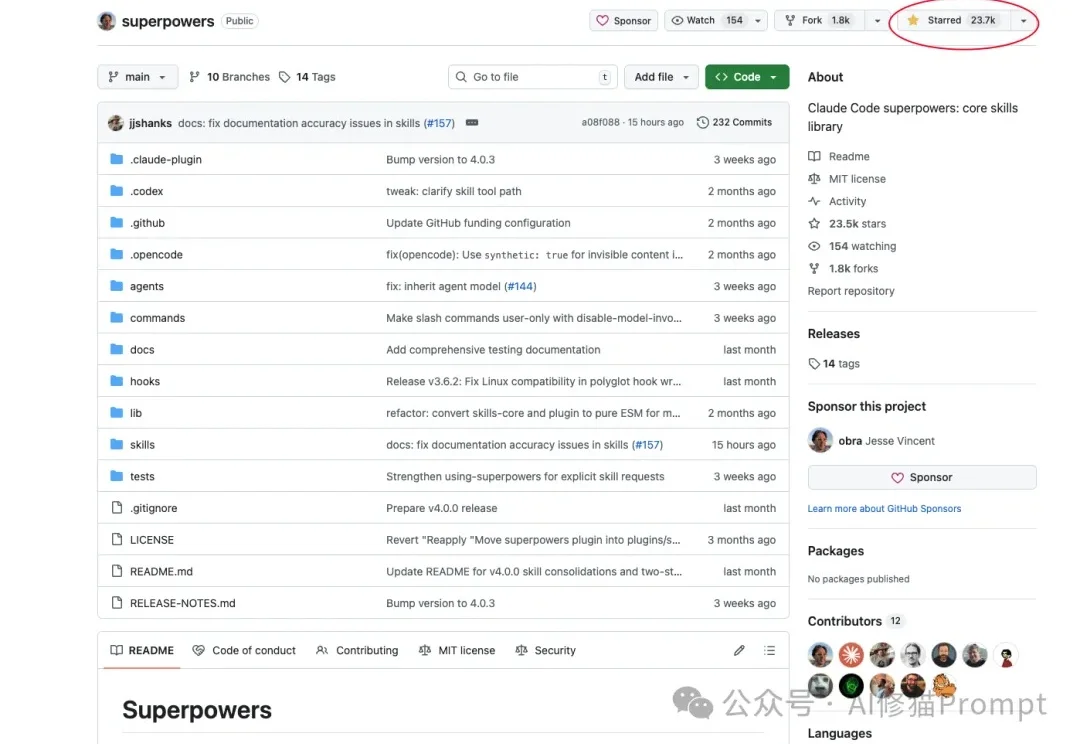
这是一个拥有23.7k star的Skills开源项目。支持一键部署在Claude code、Codex以及最近非常火的Opencode。
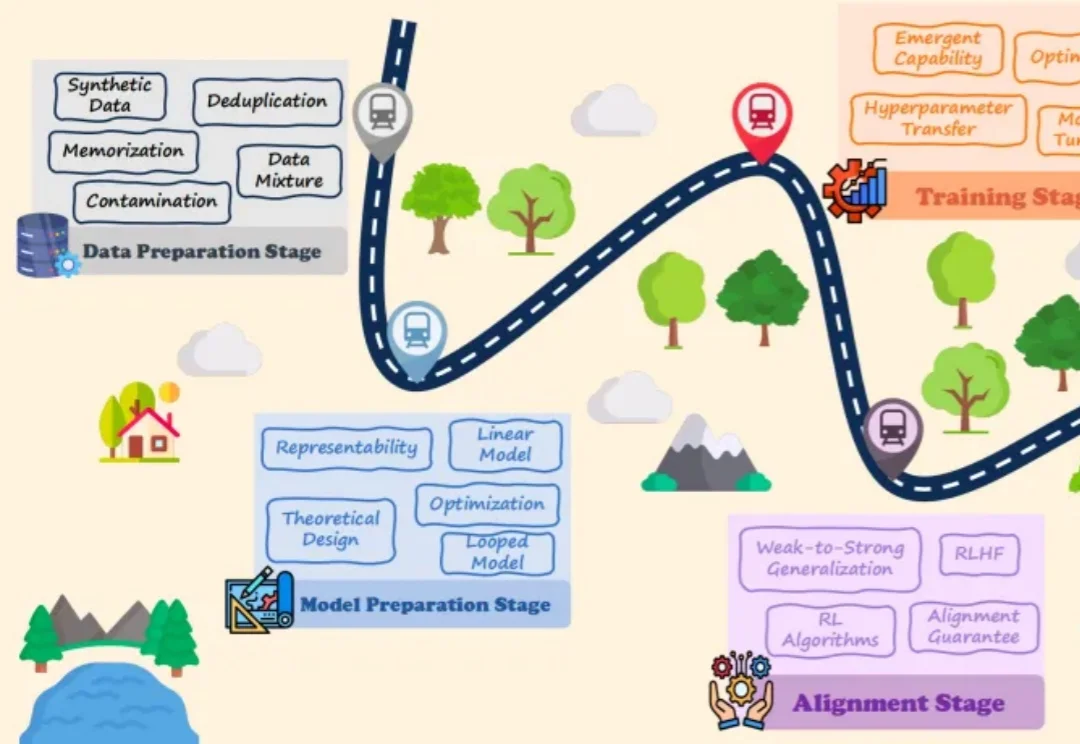
大语言模型(LLMs)的爆发式增长引领了人工智能领域的范式转移,取得了巨大的工程成功。然而,一个关键的悖论依然存在:尽管 LLMs 在实践中表现卓越,但其理论研究仍处于起步阶段,导致这些系统在很大程度上被视为难以捉摸的「黑盒」。
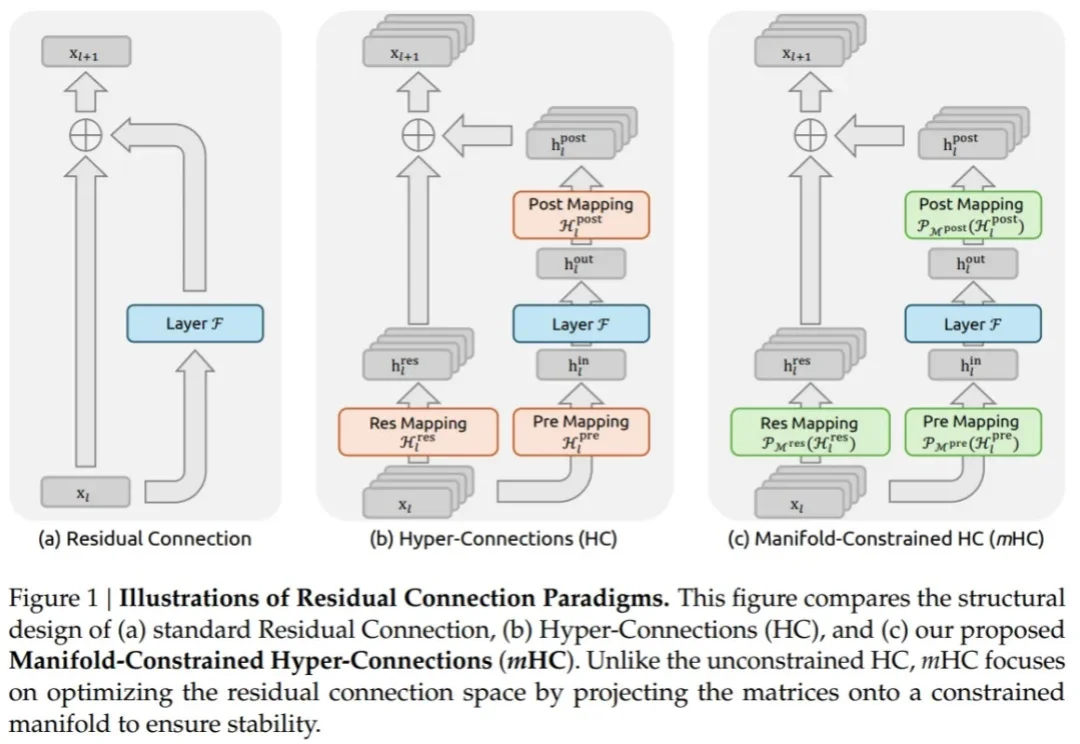
2026 年 1 月过半,我们依然没有等来 DeepSeek V4,但它的模样已经愈发清晰。
胡宇航(网名 “U 航”),毕业于美国哥伦比亚大学,博士学位,首形科技创始人。长期专注于机器人自主学习的研究工作。研究成果发表于《Nature Machine Intelligence》,《Science Robotics》等国际顶级期刊。
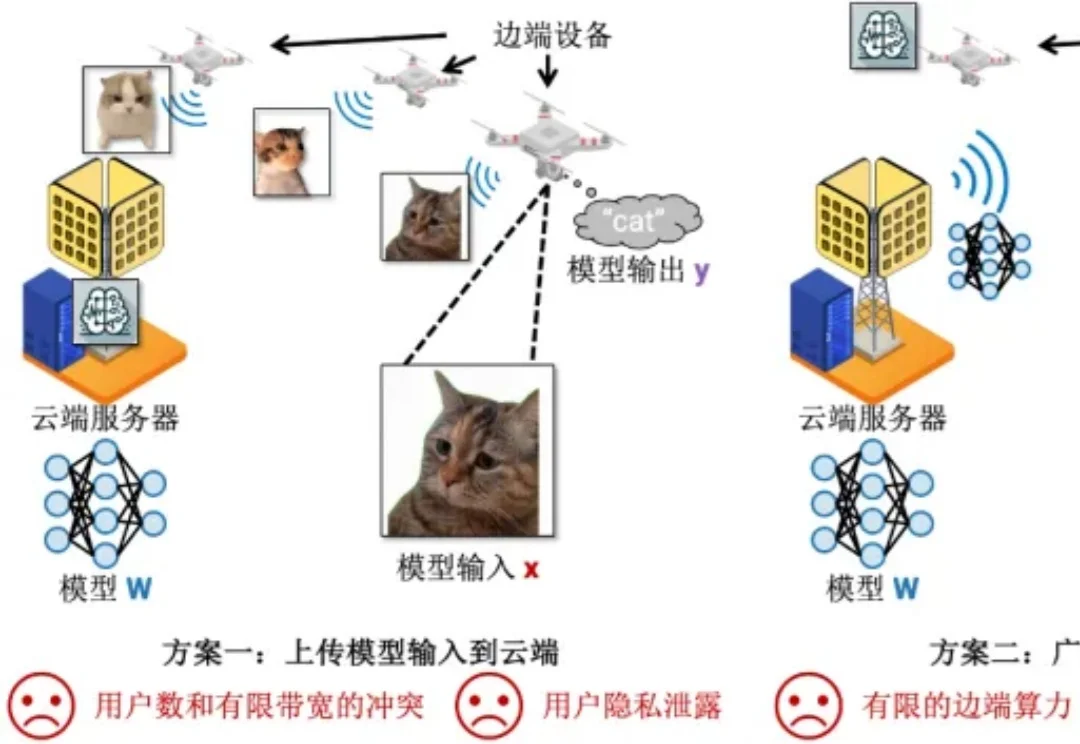
机器学习部署在边端设备的时候,模型总是存储在云端服务器上(5G 基站),而模型输入输出总是在边端设备上(例如用照相机拍摄照片然后识别其中的目标)。在这种场景下,传统有以下两种方案完成机器学习的推理:

感谢AI!

AI 不再仅仅是操作和交互的对象,它开始成为 Coworker。
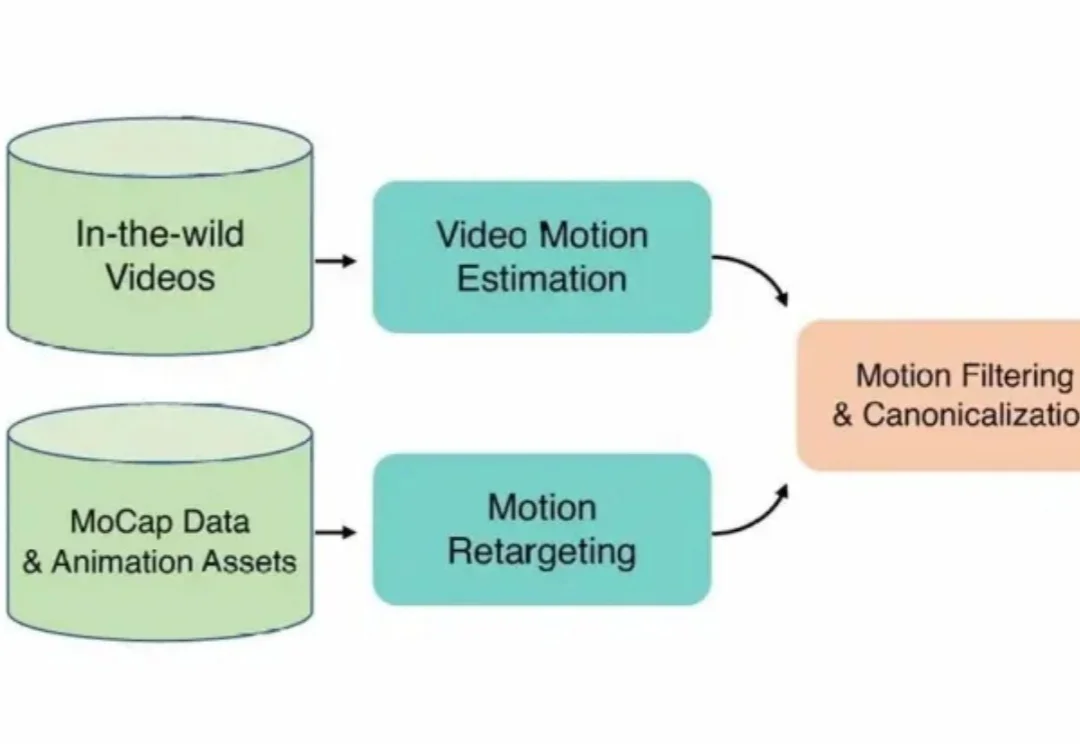
在3D角色动画创作领域,高质量动作资产的匮乏长期制约着产出的上限。