
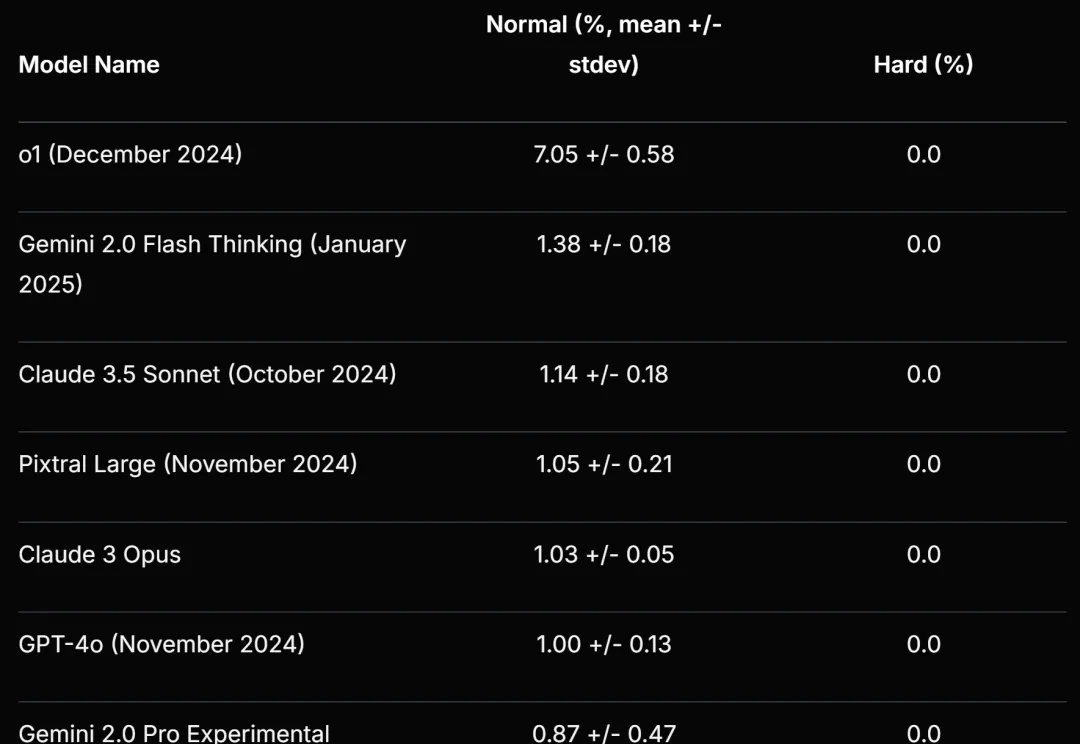
AI无法攻克的235道谜题!让o1、Gemini 2.0 Flash Thinking集体挂零
AI无法攻克的235道谜题!让o1、Gemini 2.0 Flash Thinking集体挂零Scale AI 等提出的新基准再次暴露了大语言模型的弱点。
来自主题: AI技术研报
9209 点击 2025-02-17 14:49
Scale AI 等提出的新基准再次暴露了大语言模型的弱点。
这次不是卷参数、卷算力,而是卷“跨界学习”——
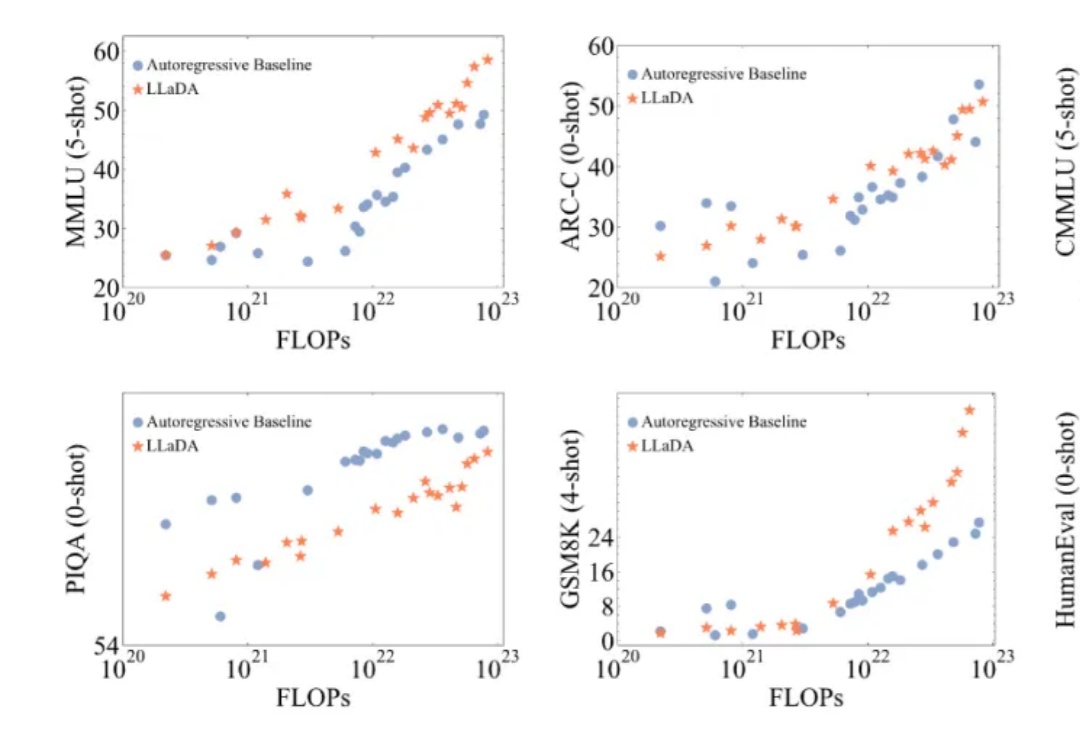
近年来,大语言模型(LLMs)取得了突破性进展,展现了诸如上下文学习、指令遵循、推理和多轮对话等能力。目前,普遍的观点认为其成功依赖于自回归模型的「next token prediction」范式。
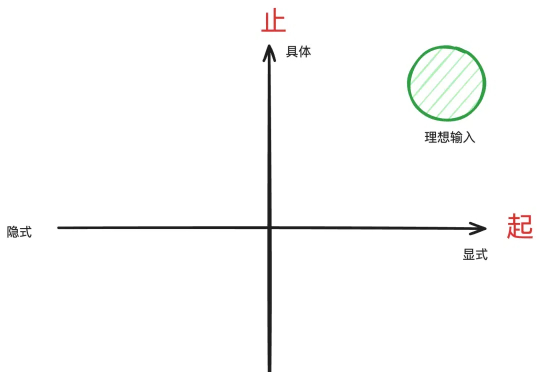
本文的作用是帮你把问题具体化,这是用好DeepSeek-R1等推理型模型的前置步骤。

自然语言 token 代表的意思通常是表层的(例如 the 或 a 这样的功能性词汇),需要模型进行大量训练才能获得高级推理和对概念的理解能力,

AI搜索“老大哥”Perplexity,刚刚也推出了自家的Deep Research——随便给个话题,就能生成有深度的研究报告。

全球有多少AI算力?算力增长速度有多快?在这场AI「淘金热」中,都有哪些新「铲子」?AI初创企业Epoch AI发布了最新全球硬件估算报告。

英伟达巧妙地将DeepSeek-R1与推理时扩展相结合,构建了全新工作流程,自动优化生成GPU内核,取得了令人瞩目的成果。

问题挺严重,大模型说的话可不能全信。
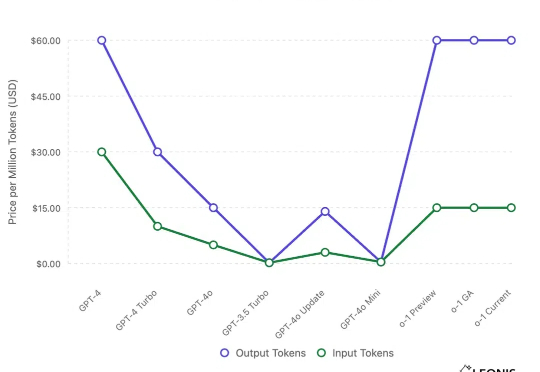
自一月以来, DeepSeek 在 AI 领域引发了极大的热度,也出现了大量分析文章。其中来自 Leonis Capital 于 2.6 发表于 Substack 上的文章:「DeepSeek: A Technical and Strategic Analysis for VCs and Startups」

人类智慧的一大特征是能够分步骤创造复杂作品,例如绘画、手工艺和烹饪等,这些过程体现了逻辑与美学的融合。
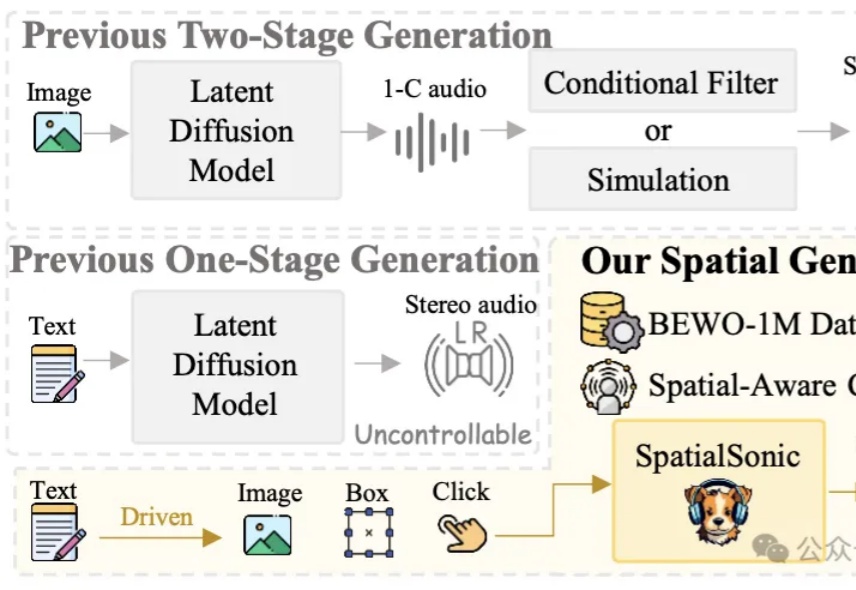
兔子通过两只耳朵可以准确感知捕食者的一举一动,造就了不同品种广泛分布在世界各地的生命奇迹;同样人也需要通过双耳沉浸式享受电影视听盛宴、判断驾驶环境和感知周围活动状态。

最近读者后台留言,问有没有好用的工作流平台。确实,对于大多数流程相对固定的任务,采用工作流完成确实是最优解,这种需求一直存在。

最新大语言模型推理测试引众议,DeepSeek R1常常在提供错误答案前就“我放弃”了?? Cursor刚刚参与了一项研究,他们基于NPR周日谜题挑战(The Sunday Puzzle),构建了一个包含近600个问题新基准测试。
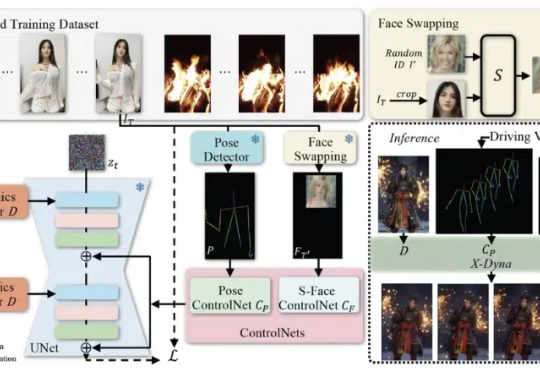
在当下的技术领域中,人像视频生成(Human-Video-Animation)作为一个备受瞩目的研究方向,正不断取得新的进展。人像视频生成 (Human-Video-Animation) 是指从某人物的视频中获取肢体动作和面部表情序列,来驱动其他人物个体的参考图像来生成视频。

中国首个全自研空间智能AI诞生了,单图即可生成360度无限3D场景,实时互动自由探索。这不仅是技术的革新,更预示着,游戏电影等领域即将迎来颠覆性的变革。

7B大小的视频理解模型中的新SOTA,来了!
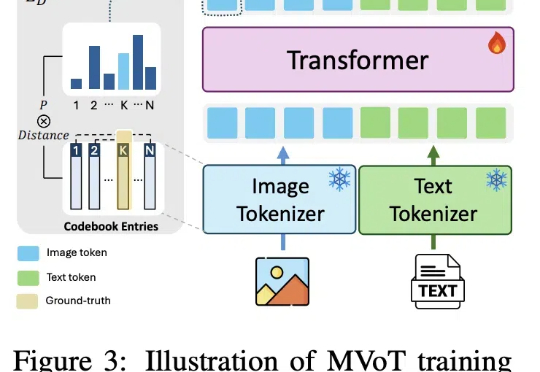
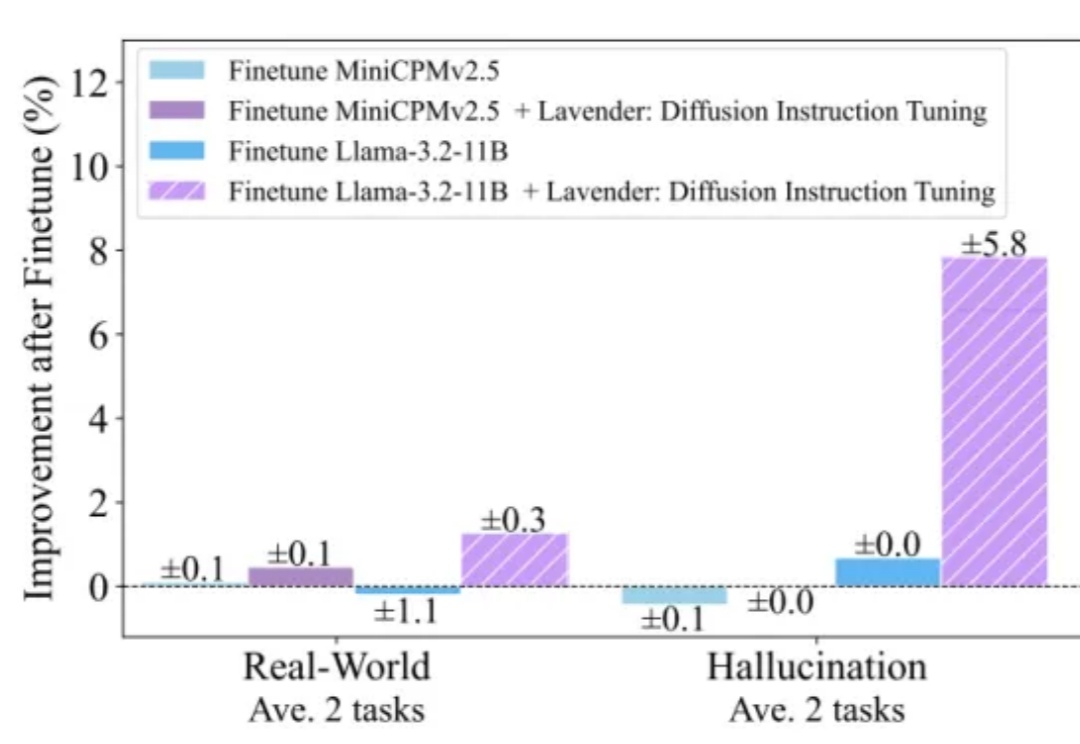
近日,微软和剑桥大学公布推理新方法:多模态思维可视化MVoT。新方法可以边推理,边「想象」,同时利用文本和图像信息学习,在实验中比CoT拥有更好的可解释性和稳健性,复杂情况下甚至比CoT强20%。还可以与CoT组合,进一步提升模型性能。
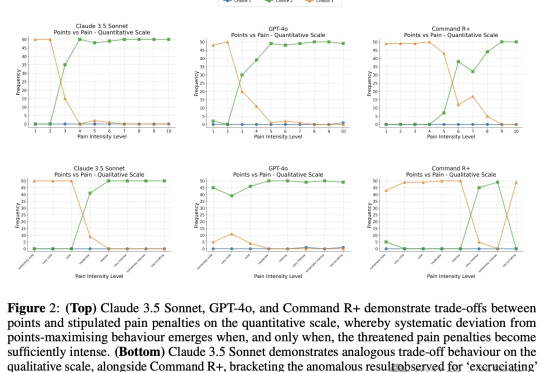
以大语言模型为代表的AI在智力方面已经逐渐逼近甚至超过人类,但能否像人类一样有痛苦、快乐这样的感知呢?近日,谷歌团队和LSE发表了一项研究,他们发现,LLM能够做出避免痛苦的权衡选择,这也许是实现「有意识AI」的第一步。

史上最大规模视觉语言数据集:1000亿图像-文本对!

脑机接口技术炙手可热,马斯克的Neuralink更是吸引了全球目光。然而其侵入式方案的风险不容忽视。Meta AI则另辟蹊径,近日推出了非侵入式的Brain2Qwerty深度学习模型,它能通过分析脑电图或脑磁图「读」出人们在键盘上输入的文字。
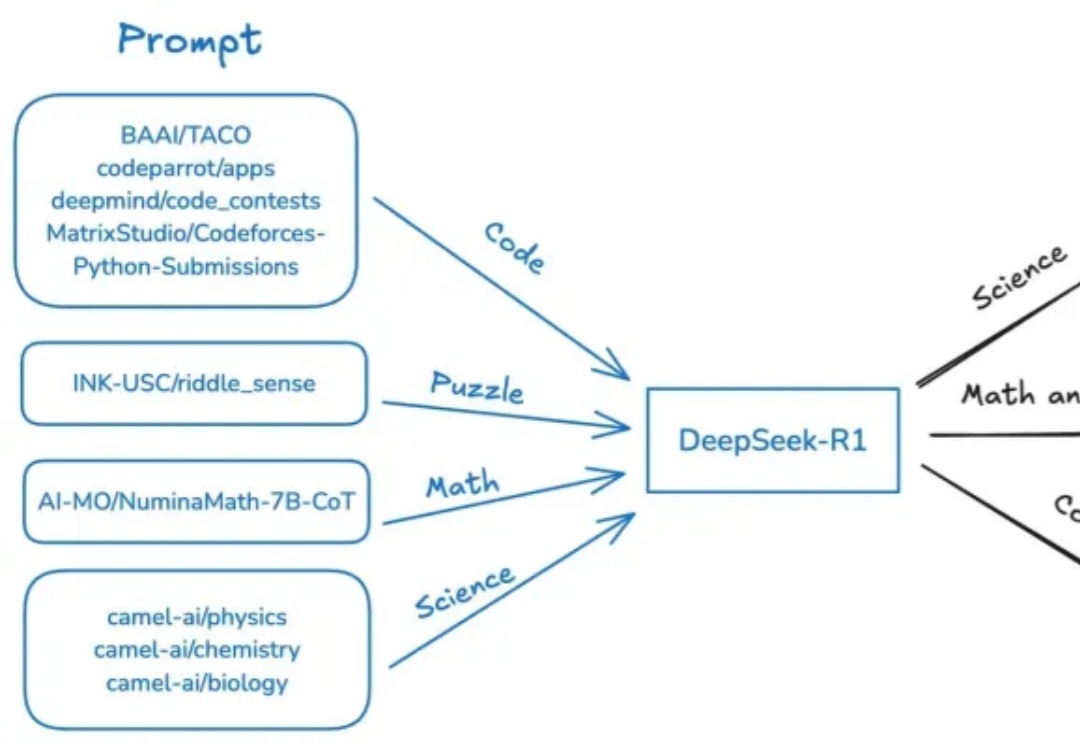
近日,斯坦福、UC伯克利等多机构联手发布了开源推理新SOTA——OpenThinker-32B,性能直逼DeepSeek-R1-32B。其成功秘诀在于数据规模化、严格验证和模型扩展。

一个简单的笑脸😀可能远不止这么简单?最近,AI大神Karpathy发现,一个😀竟然占用了多达53个token!这背后隐藏着Unicode编码的哪些秘密?如何利用这些「隐形字符」在文本中嵌入、传递甚至「隐藏」任意数据。更有趣的是,这种「数据隐藏术」甚至能对AI模型进行「提示注入」!

今天向大家介绍一项来自香港大学黄超教授实验室的最新科研成果 VideoRAG。这项创新性的研究突破了超长视频理解任务中的时长限制,仅凭单张 RTX 3090 GPU (24GB) 就能高效理解数百小时的超长视频内容。

奥特曼回应一切,OpenAI路线图全曝光。GPT-4.5数周发布,成为GPT系最后一个非推理模型。GPT-5将整合o系和GPT系,打造成一个全能系统。最令人兴奋的是,所有人皆可免费用上GPT-5。

新型验证码IllusionCAPTCHA,利用视觉错觉和诱导性提示,使AI难以识别,而人类用户能轻松通过。实验表明,该验证码能有效防御大模型攻击,同时提升用户体验,为验证码技术提供了新思路。

这项尝试只用到了 R1 模型和基本验证器,没有针对 R1 的工具,没有对专有的英伟达代码进行微调。其实根据 DeepSeek 介绍,R1 的编码能力不算顶尖。

【新智元导读】仅凭测试时Scaling,1B模型竟完胜405B!多机构联手巧妙应用计算最优TTS策略,不仅0.5B模型在数学任务上碾压GPT-4o,7B模型更是力压o1、DeepSeek R1这样的顶尖选手。
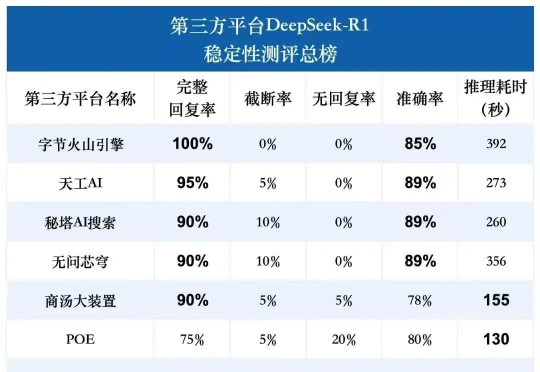
我是先看到了一张极其意料之外的图。首先我要说除了DeepSeek 官方,其他家都很稳定(这里没有吐槽官方的意思,毕竟情况特殊) 至少我没检测到超时或者断开。

在数字化浪潮中,生成式人工智能强势闯入管理领域。多数管理者期待它成为得力思维伙伴,却面临应用技能短板。如何跨越这道鸿沟,让AI为管理赋能?“协同思考”或许是解锁强大潜能的关键,带你一探究竟。