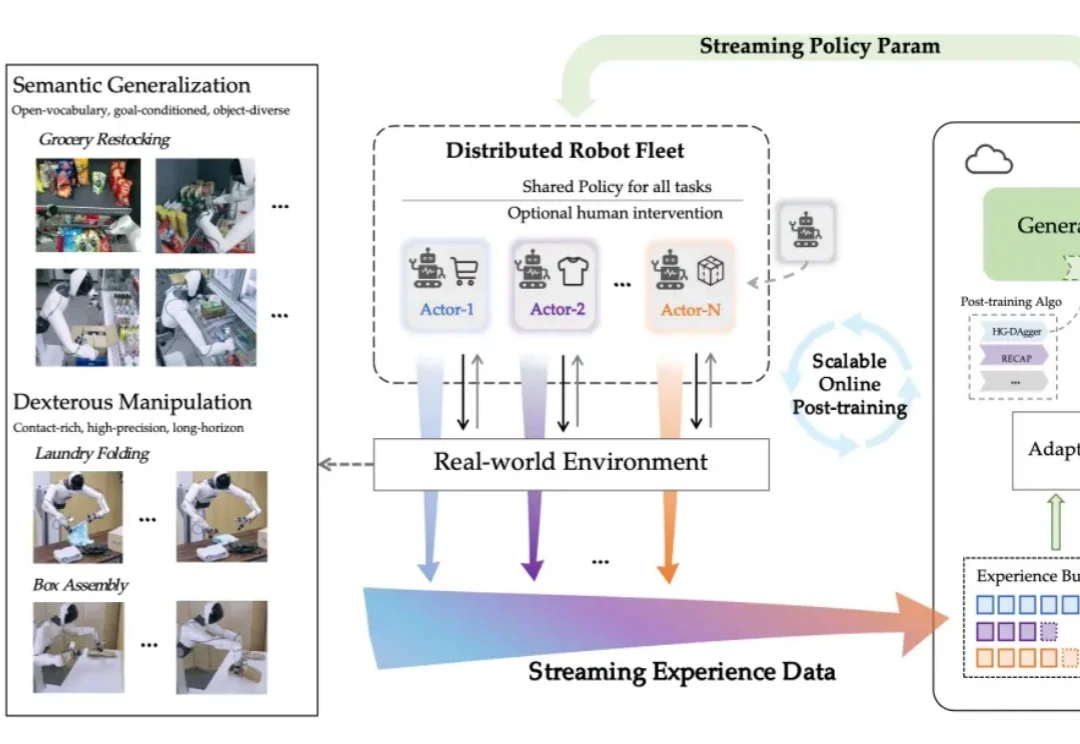
刚刚,智元提出SOP,让VLA模型在真实世界实现可扩展的在线进化
刚刚,智元提出SOP,让VLA模型在真实世界实现可扩展的在线进化对于电子产品,我们已然习惯了「出厂即巅峰」的设定:开箱的那一刻往往就是性能的顶点,随后的每一天都在折旧。
来自主题: AI技术研报
9211 点击 2026-01-07 10:14
 搜索
搜索
对于电子产品,我们已然习惯了「出厂即巅峰」的设定:开箱的那一刻往往就是性能的顶点,随后的每一天都在折旧。
这两年一直在关注 AI,Claude Code 给我带来的震撼,和当初 Nano Banana 在画图领域的革命,几乎是一个级别。

现实世界不是 demo,人形机器人该如何进入真实世界?

2025 年,随着李飞飞等学者将 “空间智能”(Spatial Intelligence)推向聚光灯下,这一领域迅速成为了大模型竞逐的新高地。通用大模型和各类专家模型纷纷在诸多室内空间推理基准上刷新 SOTA,似乎 AI 在训练中已经更好地读懂了三维空间。
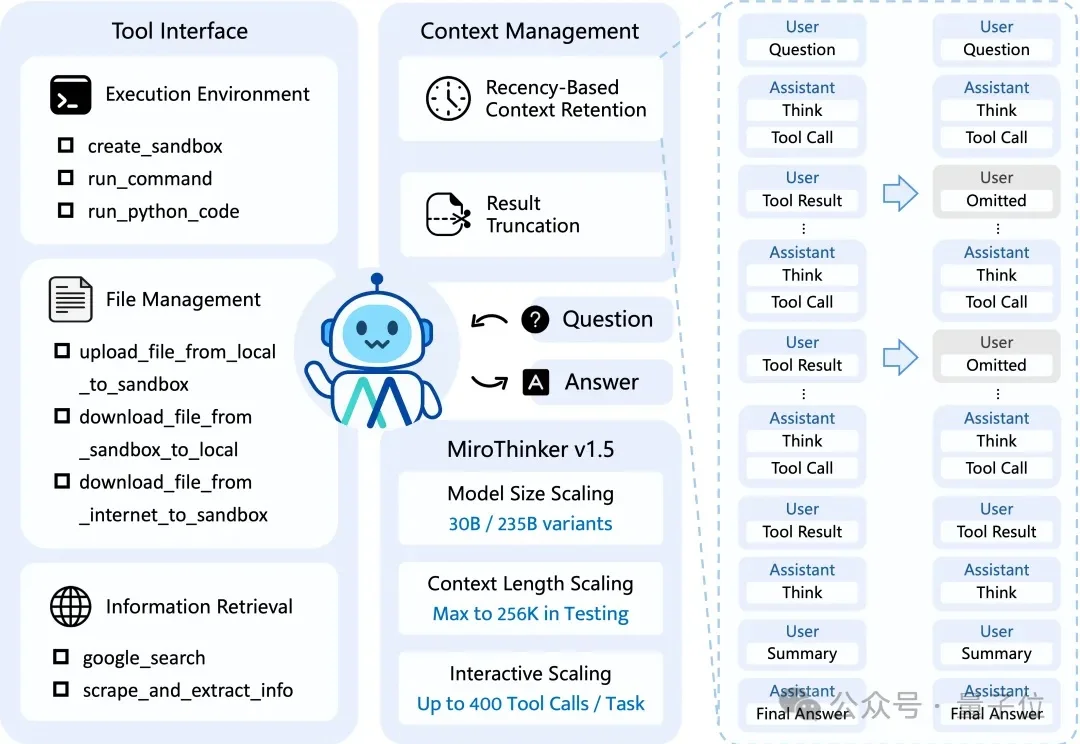
新年刚至,陈天桥携手代季峰率先打响开源大模型的第一枪。

文本领域的大模型满分选手,换成语音就集体挂科?大模型引以为傲的多轮对话逻辑,在真实人声面前竟然如此脆弱。Scale AI正式发布首个原生音频多轮对话基准Audio MultiChallenge,直接撕开了大模型靠合成语音评测维持的优等生假象。实验显示,强如Gemini 3 Pro在真实场景下的通过率也仅过半数,而GPT-4o Audio的表现更是令人大跌眼镜。

您可能已经感受到了,从2025年开始到如今,全世界都在谈论Agentic AI或Agent(代理式AI)。从董事会到咨询公司,从更高级别的战略到街头巷尾,仿佛只要接入了大模型(LLM),所有的业务流程就能自动运转,效率就能翻倍。

BiCo是一种创新的AI视觉内容生成方法,能灵活组合图像和视频中的视觉概念,实现可控编辑。它通过分层绑定器、多样化与吸收机制、时间解耦策略等技术创新,解决了现有方法在概念提取和组合上的问题,让AI真正理解并融合视觉元素。
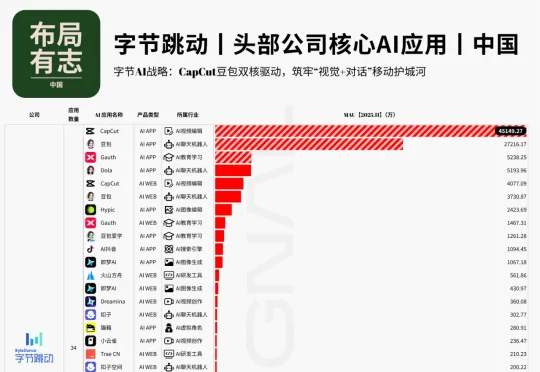
在上一篇《全载录丨Xsignal 全球AI应用行业年度报告丨2025》中,我们俯瞰了全球AI从“震撼期”迈入“深水区”的宏观版图。如果说那是一张新大陆的地图,那么今天,我们将目光聚焦于这场变革的“风暴眼”——中国头部科技公司的战略棋局。

嗨大家好!我是阿真! 本来想刚到2026年一开始就给大家卷个大的,没想到一躺平就完全起不来,于是到了今天才回归,而且发的还是个备用稿哎嘿。

当全行业还在为昂贵的多视角数据焦头烂额时,中科院和CreateAI重磅推出NeoVerse,直接用百万单目视频砸开了4D世界模型的大门,让AI真正学会了理解开放世界。

关注我比较久的朋友可能都知道,我用 AI 有个习惯。

空间理解能力是多模态大语言模型(MLLMs)走向真实物理世界,成为 “通用型智能助手” 的关键基础。但现有的空间智能评测基准往往有两类问题:一类高度依赖模板生成,限制了问题的多样性;另一类仅聚焦于某一种空间任务与受限场景,因此很难全面检验模型在真实世界中对空间的理解与推理能力。

DeepSeek-OCR的视觉文本压缩(VTC)技术通过将文本编码为视觉Token,实现高达10倍的压缩率,大幅降低大模型处理长文本的成本。但是,视觉语言模型能否理解压缩后的高密度信息?中科院自动化所等推出VTCBench基准测试,评估模型在视觉空间中的认知极限,包括信息检索、关联推理和长期记忆三大任务。
在检索增强生成中,扩大生成模型规模往往能提升准确率,但也会显著抬高推理成本与部署门槛。CMU 团队在固定提示模板、上下文组织方式与证据预算,并保持检索与解码设置不变的前提下,系统比较了生成模型规模与检索语料规模的联合效应,发现扩充检索语料能够稳定增强 RAG,并在多项开放域问答基准上让小中型模型在更大语料下达到甚至超过更大模型在较小语料下的表现,同时在更高语料规模处呈现清晰的边际收益递减。
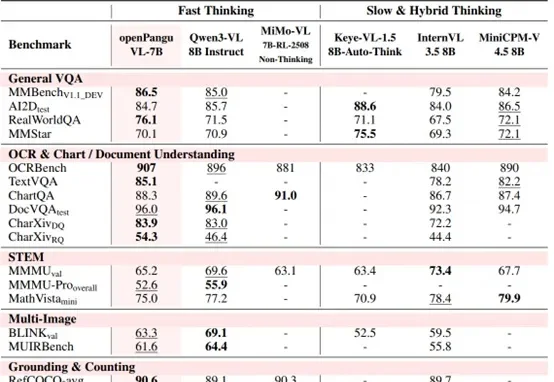
7B量级模型,向来是端侧部署与个人开发者的心头好。
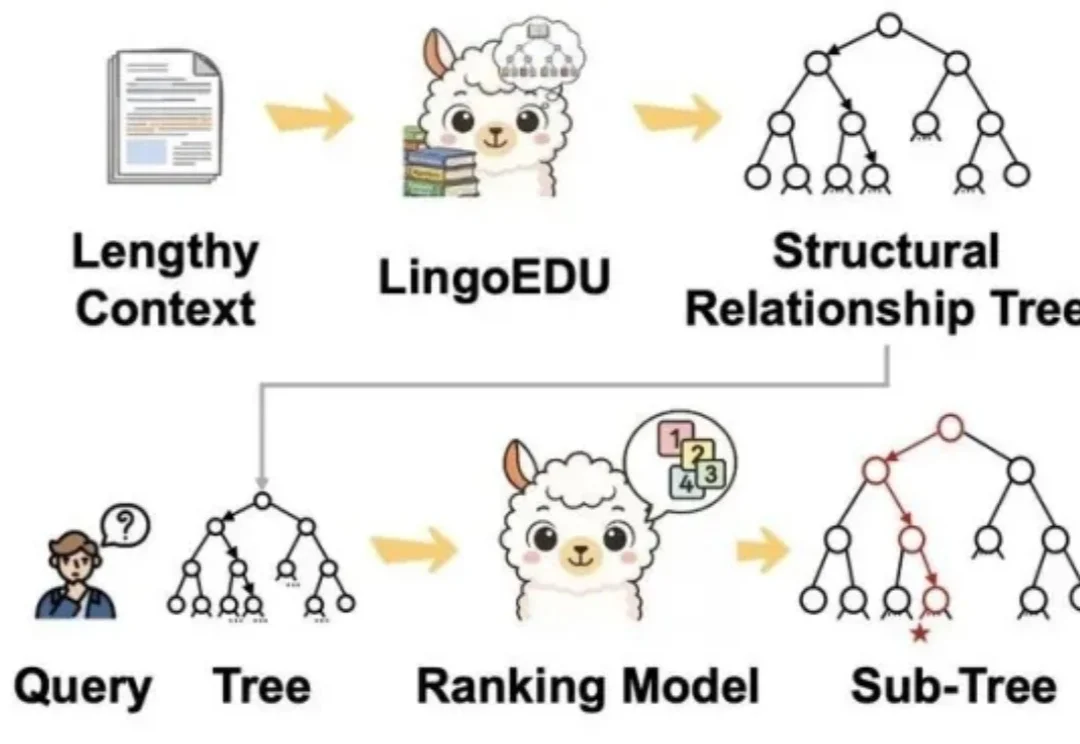
零成本降低大模型幻觉新方法,让DeepSeek准确率提升51%!

香港中文大学提出了一个全新的算法框架RankSEG,用于提升语义分割任务的性能。传统方法在预测阶段使用threshold或argmax生成掩码,但这种方法并非最优。RankSEG无需重新训练模型,仅需在推理阶段增加三行代码,即可显著提高Dice或IoU等分割指标。

最新报告探讨了生成式模型Nano Banana Pro在低层视觉任务中的表现,如去雾、超分等,传统上依赖PSNR/SSIM等像素级指标。研究发现,Nano Banana Pro在视觉效果上更佳,但传统指标表现欠佳,因生成式模型更追求语义合理而非像素对齐。
你是否经历过这样的至暗时刻: 明明实验数据已经跑通,核心逻辑也已梳理完毕,却在面对空白的 PPT 页面时陷入停滞; 明明脑海里有清晰的系统架构,却要在 Visio 或 Illustrator 里跟一根歪歪扭扭的线条较劲半小时; 好不容易用 AI 生成了一张精美的流程图,却发现上面的文字是乱码,或者为了改一个配色不得不重新生成几十次……

LLM的下一个推理单位,何必是Token?刚刚,字节Seed团队发布最新研究——DLCM(Dynamic Large Concept Models)将大模型的推理单位从token(词) 动态且自适应地推到了concept(概念)层级。
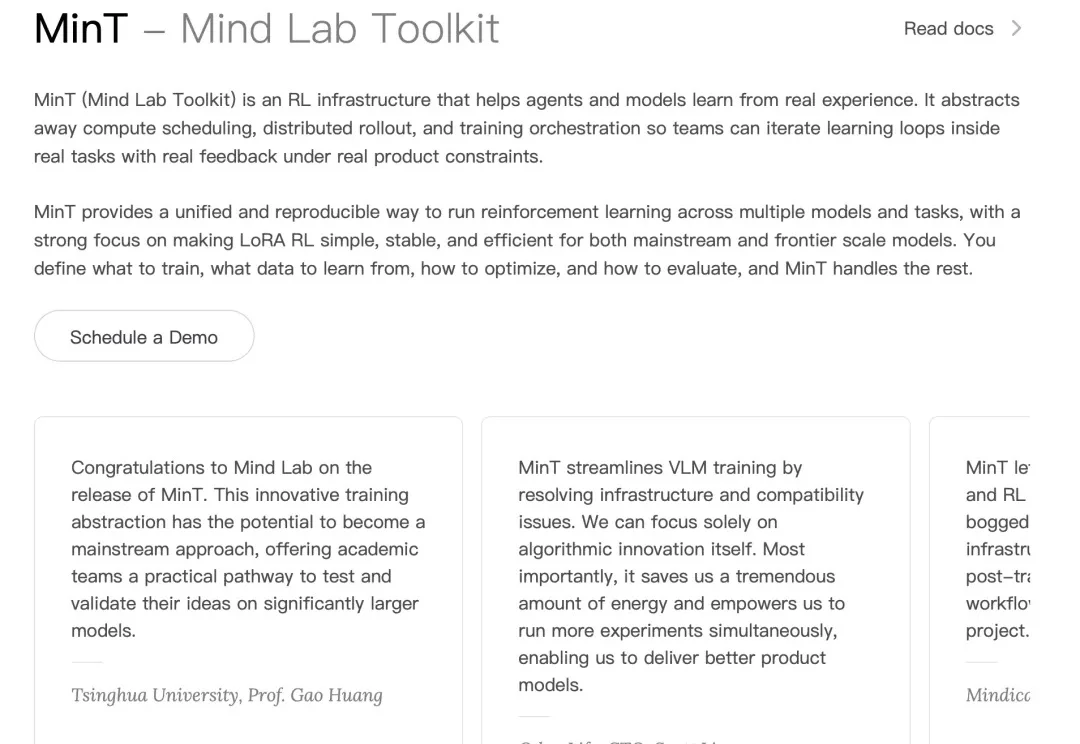
在大公司一路高歌猛进的 AI 浪潮里,小创业者和高校研究者正变得越来越迷茫。就连前段时间谷歌创始人谢尔盖・布林回斯坦福,都要回答「大学该何去何从」「从学术到产业的传统路径是否依然重要」这类问题。

你有没有发现,你让AI读一篇长文章,结果它读着读着就忘了前面的内容? 你让它处理一份超长的文档,结果它给出来的答案,牛头不对马嘴? 这个现象,学术界有个专门的名词,叫做上下文腐化。 这也是目前AI的通病:大模型的记忆力太差了,文章越长,模型越傻!
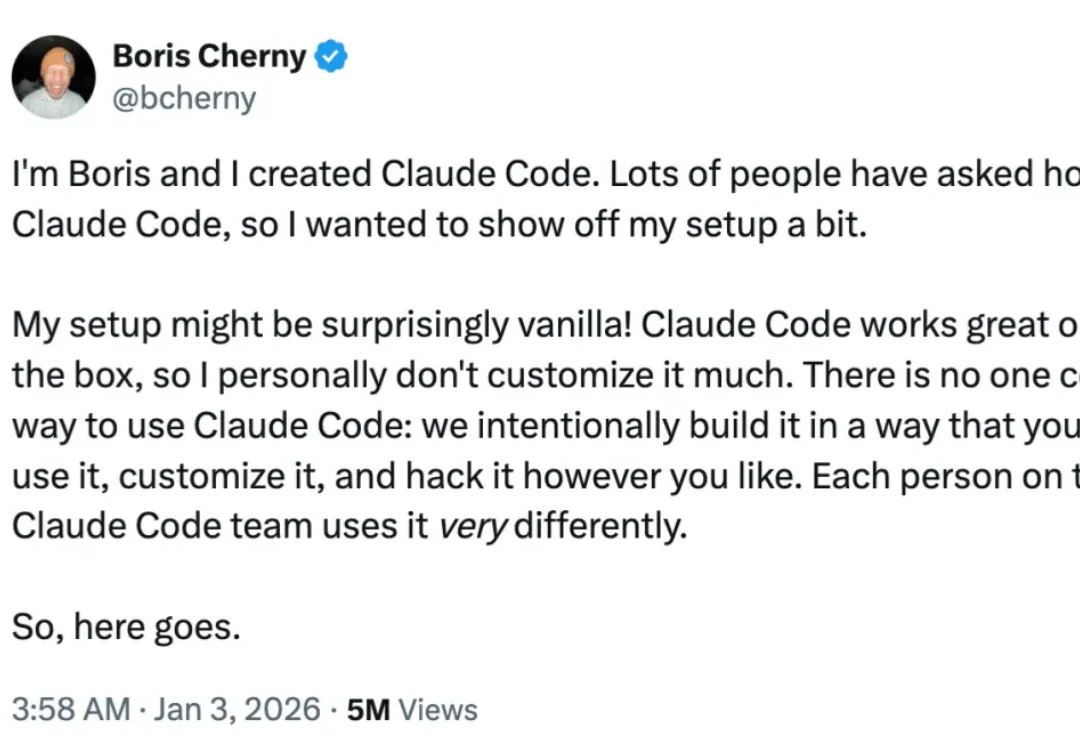
2026 新年第三天,Claude Code 创建者、负责人 Boris Cherny 开展「线上教学」,亲自示范他自己使用这个 AI 编程工具的工作流。
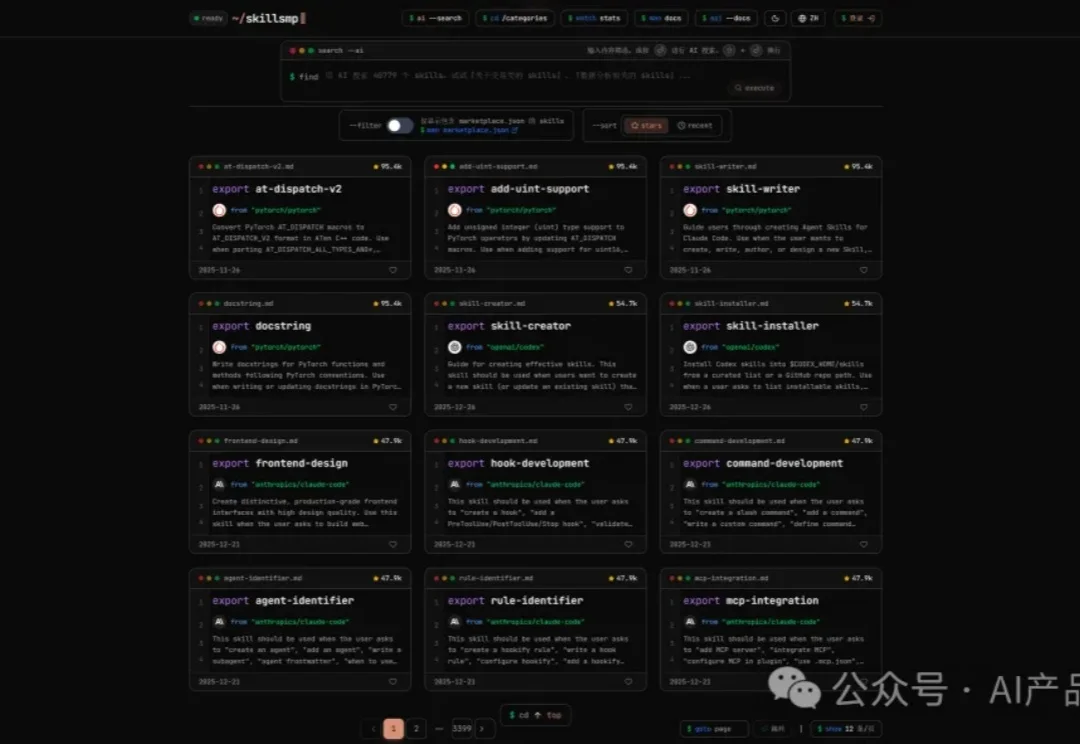
最近火的一塌糊涂的 Skills 很多群友在问是啥东东

在深入了解如何领取赠金之前,让我们首先认识一下Google Cloud和Vertex AI这两项核心服务:
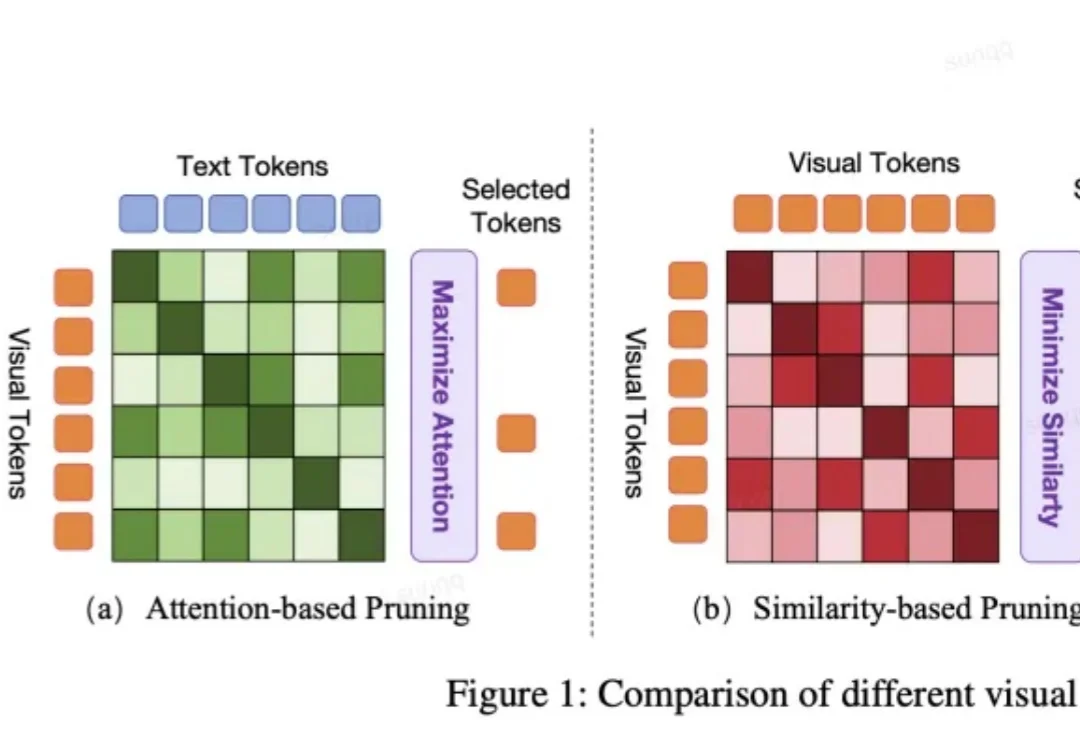
VLA 模型正被越来越多地应用于端到端自动驾驶系统中。然而,VLA 模型中冗长的视觉 token 极大地增加了计算成本。但现有的视觉 token 剪枝方法都不是专为自动驾驶设计的,在自动驾驶场景中都具有局限性。
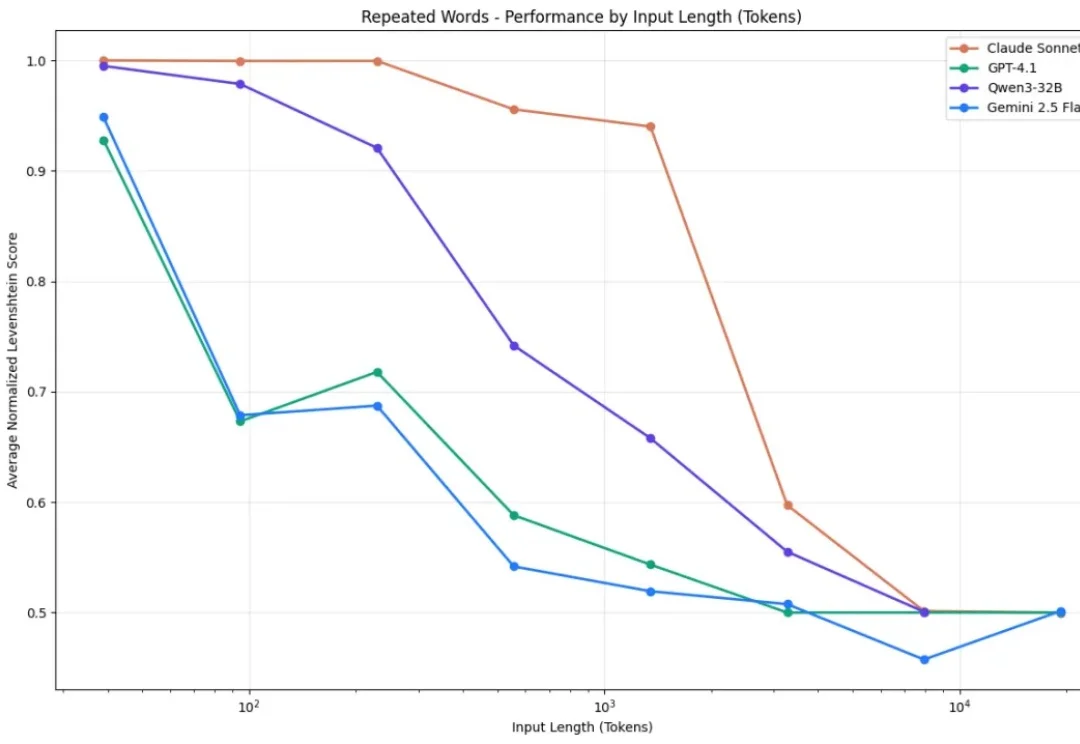
新年伊始,MIT CSAIL 的一纸论文在学术圈引发了不小的讨论。Alex L. Zhang 、 Tim Kraska 与 Omar Khattab 三位研究者在 arXiv 上发布了一篇题为《Recursive Language Models》的论文,提出了所谓“递归语言模型”(Recursive Language Models,简称 RLM)的推理策略。
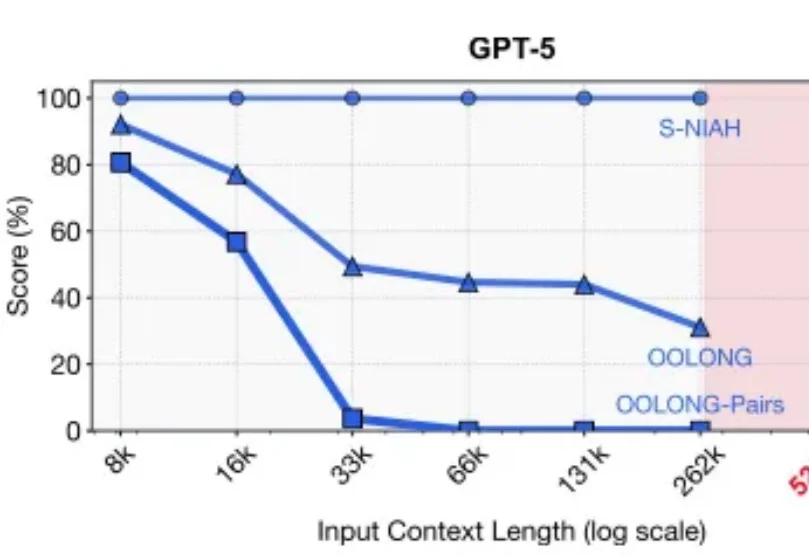
2025年的最后一天, MIT CSAIL提交了一份具有分量的工作。当整个业界都在疯狂卷模型上下文窗口(Context Window),试图将窗口拉长到100万甚至1000万token时,这篇论文却冷静地指出了一个被忽视的真相:这就好比试图通过背诵整本百科全书来回答一个复杂问题,既昂贵又低效。
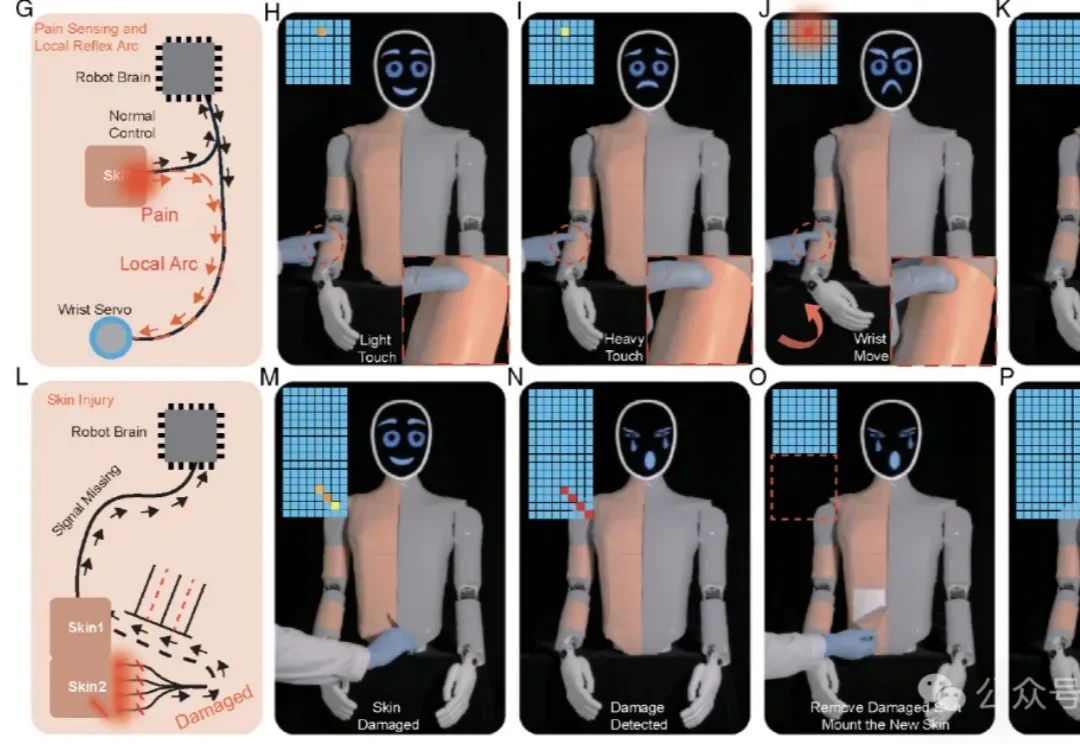
这下,你打人形机器人,它真的会「疼」了。