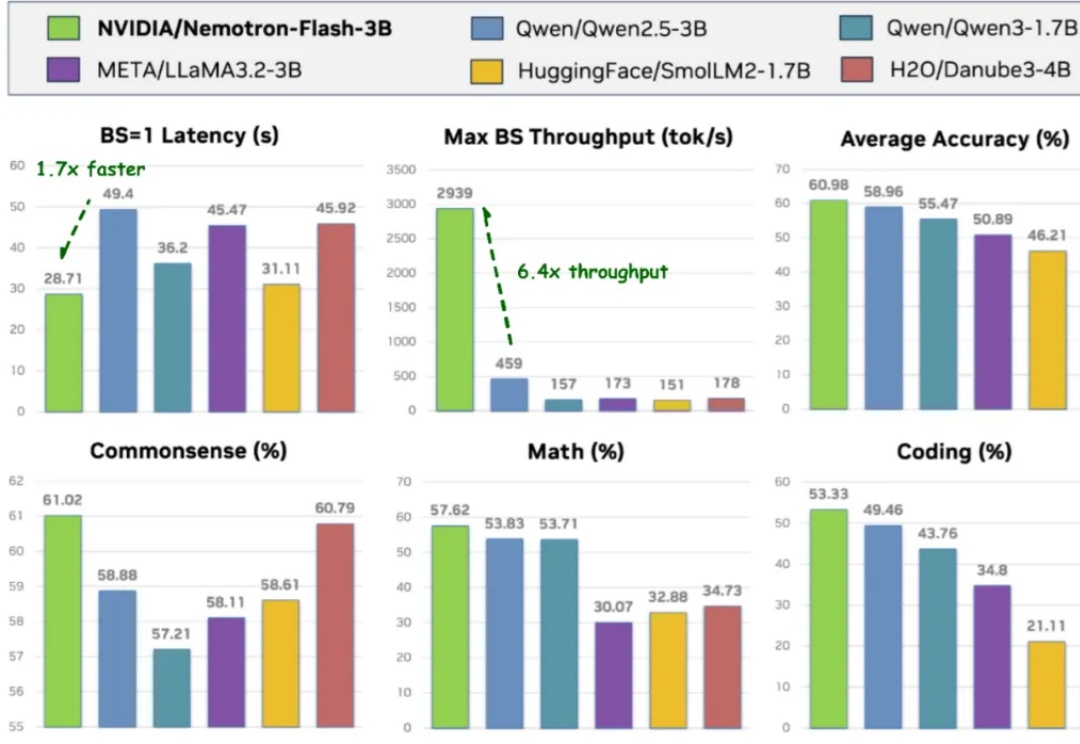
NeurIPS 2025 | 英伟达发布Nemotron-Flash:以GPU延迟为核心重塑小模型架构
NeurIPS 2025 | 英伟达发布Nemotron-Flash:以GPU延迟为核心重塑小模型架构导读 过去两年,小语言模型(SLM)在业界备受关注:参数更少、结构更轻,理应在真实部署中 “更快”。但只要真正把它们跑在 GPU 上,结论往往令人意外 —— 小模型其实没有想象中那么快。
来自主题: AI技术研报
9091 点击 2025-12-01 10:09
 搜索
搜索
导读 过去两年,小语言模型(SLM)在业界备受关注:参数更少、结构更轻,理应在真实部署中 “更快”。但只要真正把它们跑在 GPU 上,结论往往令人意外 —— 小模型其实没有想象中那么快。

在大语言模型(LLM)的研究浪潮中,绝大多数工作都聚焦于优化模型的输出分布 —— 扩大模型规模、强化分布学习、优化奖励信号…… 然而,如何将这些输出分布真正转化为高质量的生成结果 —— 即解码(decoding)阶段,却没有得到足够的重视。
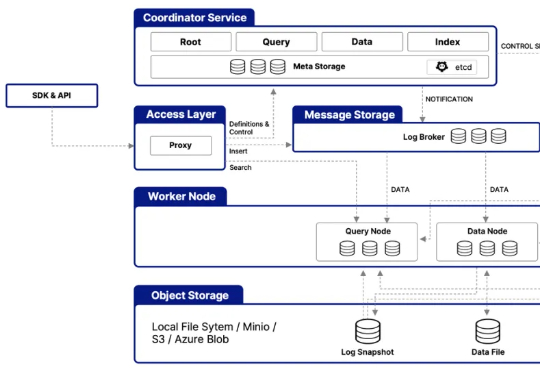
在架构层面,Milvus 2.6 大幅简化系统架构,整合多个核心组件 —— 例如将原有的 Coordinator 组件(含 RootCoord、QueryCoord、DataCoord)统一整合为 MixCoord,并将 IndexNode 与 DataNode 合并为单一组件。这些调整不仅降低了系统复杂度,更显著提升了系统的可维护性与横向扩展性。
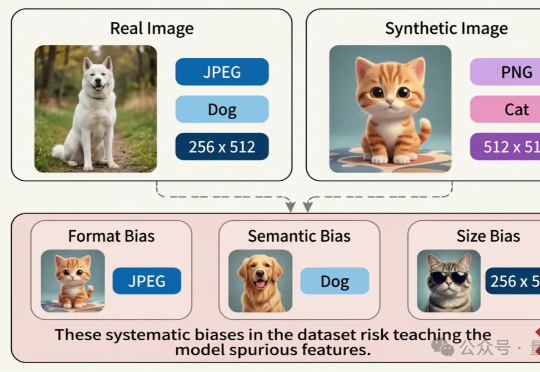
近日,腾讯优图实验室联合华东理工大学、北京大学等研究团队在A生成图像检测(AI-Generated Image Detection)泛化问题上展开研究,提出Dual Data Alignment(双重数据对齐,DDA)方法,从数据层面系统性抑制“偏差特征”,显著提升检测器在跨模型、跨数据域场景下的泛化能力。

本文第一作者为刘禹宏,上海交通大学人工智能专业本科四年级学生,相关研究工作于上海人工智能实验室科研实习期间完成。通讯作者为王佳琦、臧宇航,在该研究工作完成期间,均担任上海人工智能实验室研究员。

a16z 指出:“模型开发的进展正在简化整个基础设施栈,使得语音智能体具备更低延迟和更高性能。这一提升主要出现在过去六个月内,得益于新一代对话模型的出现。”基于这些趋势,Deepgram 与 Opus Research 合作开展的《2025 语音 AI 状况调查报告》,基于 400 位商业领袖的洞察,涵盖十多个行业,分析了语音 AI 的应用现状与关键特性。

CB Insights 发布的《2025 Future Tech Hotshots:Scouting Reports》报告,结合生成式 AI 分析与专有 Mosaic 评分体系,从全球海量初创企业中遴选出 45 家最具潜力的科技公司。
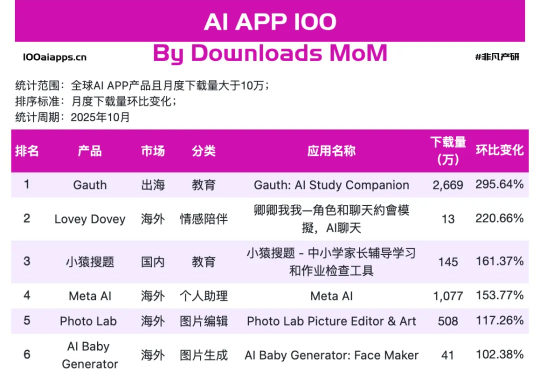
但当我们把视线从焦点模型上,挪到手机里AI应用真实数据上,就会发现一幅不同的画面。可以看到在非凡产研 10 月 AI App 增速榜上,跑得最快的那 17 个,并不是万事皆可聊的通用助手,而是一群看上去有点普通、甚至有点土气的小应用,其中Gauth、Starry、Knowunity、AI Baby Generator已经连续两个月上榜了。

人工智能研究的最新目标,尤其是在追求“通用人工智能”(AGI)的实验室中,是一个被称为“世界模型”(world model)的概念:这是一种AI内部携带的环境表征,就像一个计算型的雪球玻璃球。AI系统可以借助这个简化的内部模型,在真正执行任务之前,先对预测和决策进行评估。

大模型推理的爆发,实际源于 scaling 范式的转变:从 train-time scaling 到 test-time scaling(TTS),即将更多的算力消耗部署在 inference 阶段。典型的实现是以 DeepSeek r1 为代表的 long CoT 方法:通过增加思维链的长度来获得答案精度的提升。那么 long CoT 是 TTS 的唯一实现吗?

智东西11月28日报道,刚刚,快手开源其新一代旗舰多模态大模型Keye-VL-671B-A37B。该模型基于DeepSeek-V3-Terminus打造,拥有6710亿个参数,在保持基础模型通用能力的前提下,对视觉感知、跨模态对齐与复杂推理链路进行了升级,实现了较强的多模态理解和复杂推理能力。

而今天,来自 UIUC、华盛顿大学等机构的一群研究人员,通过一篇重磅论文《推理的认知基础及其在大型语言模型中的体现》,为这个“认知鸿沟”画出了一张精确的微观解剖图。

REG 是一种简单而有效的方法,仅通过引入一个 class token 便能大幅加速生成模型的训练收敛。其将基础视觉模型(如 DINOv2)的 class token 与 latent 在空间维度拼接后共同加噪训练,从而显著提升 Diffusion 的收敛速度与性能上限。在 ImageNet 256×256 上,

腾讯混元大模型团队正式发布并开源HunyuanOCR模型!这是一款商业级、开源且轻量(1B参数)的OCR专用视觉语言模型,模型采用原生ViT和轻量LLM结合的架构。目前,该模型在抱抱脸(Hugging Face)趋势榜排名前四,GitHub标星超过700,并在Day 0被vllm官方团队接入。

RAG效果不及预期,试试这10个上下文处理优化技巧。对大部分开发者来说,搭一个RAG或者agent不难,怎么把它优化成生产可用的状态最难。在这个过程中,检索效率、准确性、成本、响应速度,都是重点关注问题。
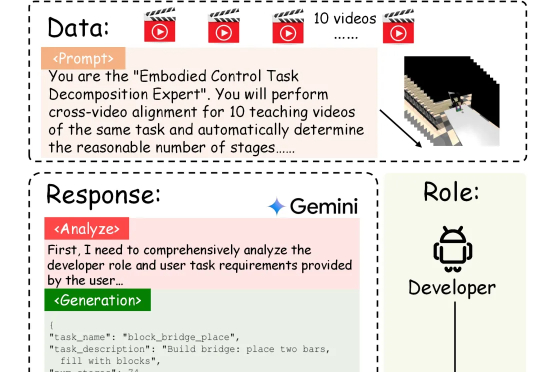
具身智能的「ChatGPT时刻」还没到,机器人的「幻觉」却先来了?在需要几十步操作的长序列任务中,现有的VLA模型经常「假装在干活」,误以为任务完成。针对这一痛点,北京大学团队提出自进化VLA框架EvoVLA。该模型利用Gemini生成「硬负样本」进行对比学习,配合几何探索与长程记忆,在复杂任务基准Discoverse-L上将成功率提升了10.2%,并将幻觉率从38.5%大幅降至14.8%。

人工智能在过去的十年中,以惊人的速度革新了信息处理和内容生成的方式。然而,无论是大语言模型(LLM)本体,还是基于检索增强生成(RAG)的系统,在实际应用中都暴露出了一个深层的局限性:缺乏跨越时间的、可演化的、个性化的“记忆”。它们擅长瞬时推理,却难以实现持续积累经验、反思历史、乃至真正像人一样成长的目标。
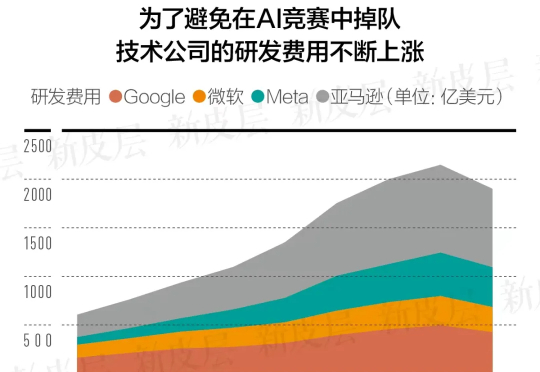
过去数周,英伟达股价经历了一轮高位回调与震荡。目前市值相较于一个月前的高点已下降15.4%。虽然一周前最新季度财报发布后,公司超预期的业绩表现一定程度上稳定了市场信心,但隔天股价的下跌反映着情绪底色依然是消极的。
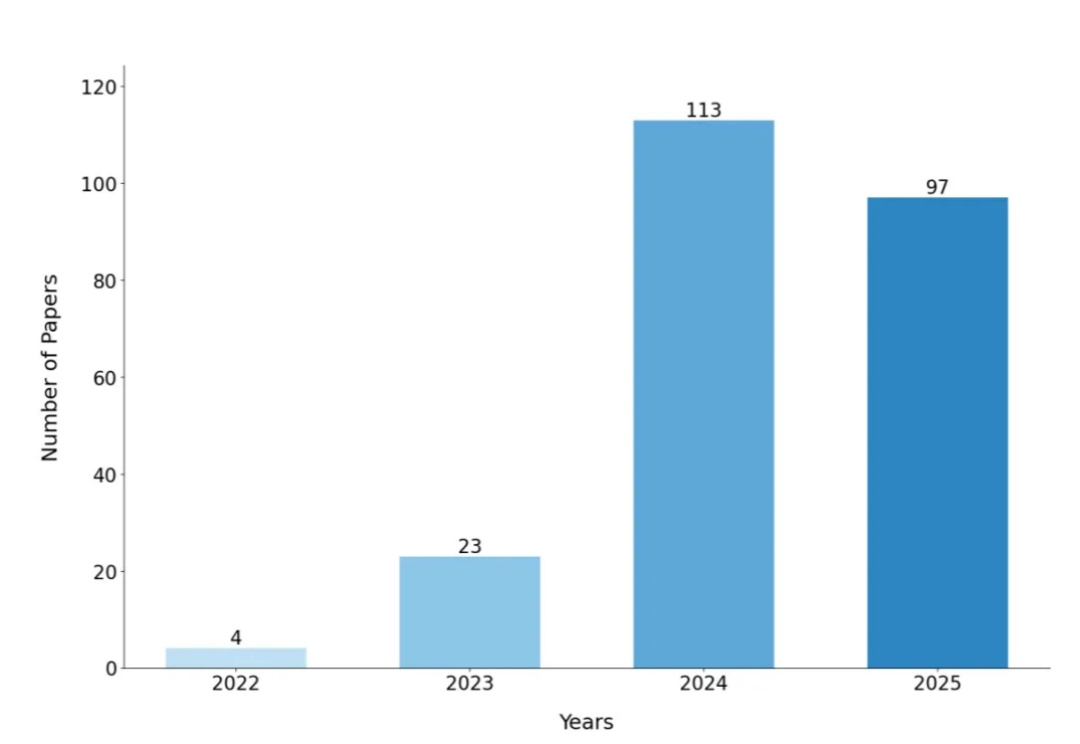
在软件开发领域,需求工程(Requirements Engineering, RE)一直是项目成功的关键环节。然而,传统 RE 方法面临着效率低下、需求变更频繁等挑战。根据 Standish Group 的报告,仅有 31% 的软件项目能在预算和时间内完成,而需求相关问题导致的项目失败率高达 37%。

Context Pruning如何结合rerank,优化RAG上下文?
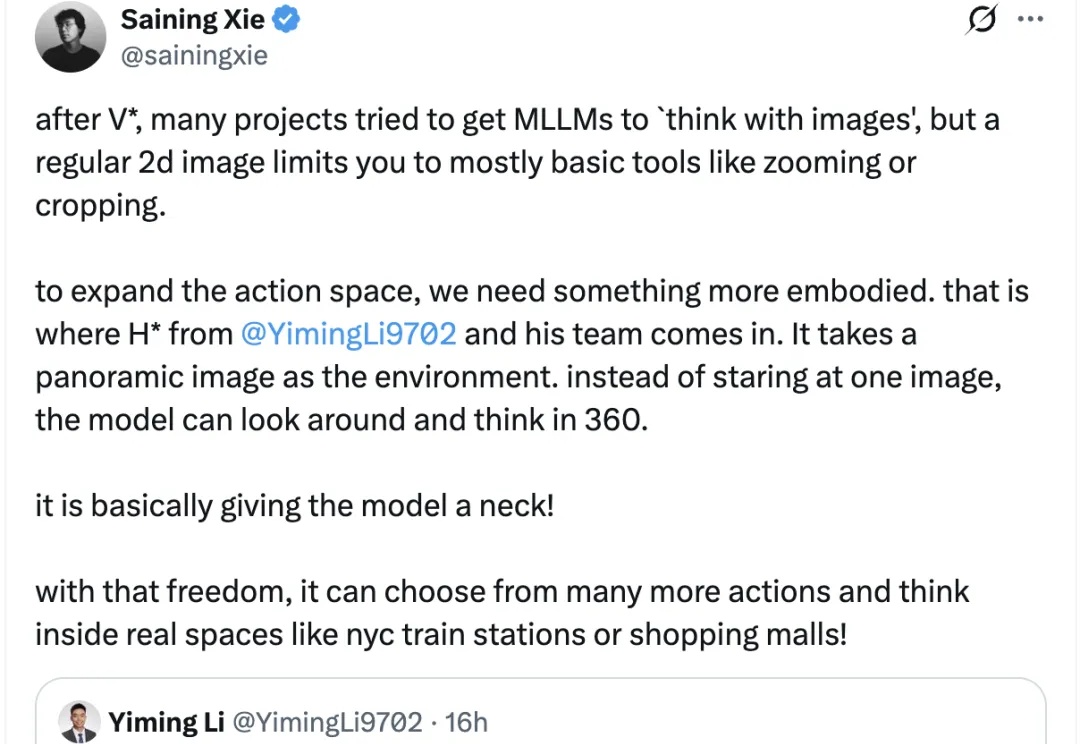
终于有人要给大模型安“脖子”了!

基准测试(Benchmarks)在人工智能的发展进程中扮演着至关重要的角色,构成了评价生成式模型(Generative Models)性能的事实标准。对于从事模型训练与评估的AI研究者而言,GSM8K、MMLU等数据集的数据质量直接决定了评估结论的可靠性。
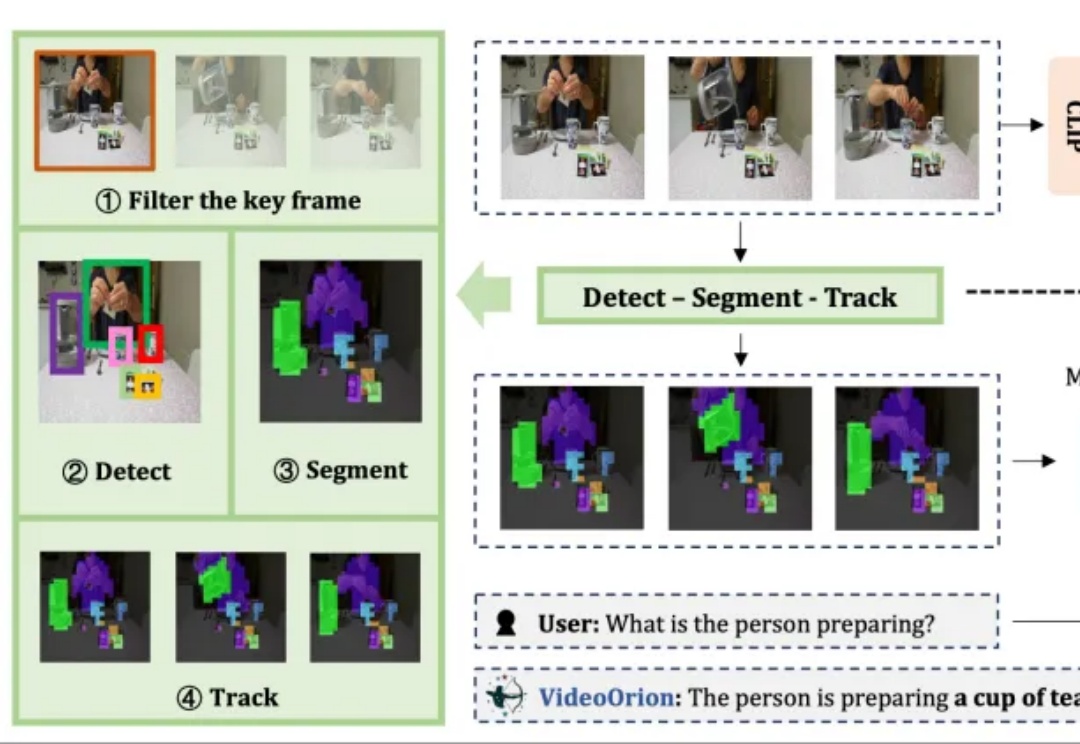
被顶会ICCV 2025以554高分接收的视频理解框架来了!
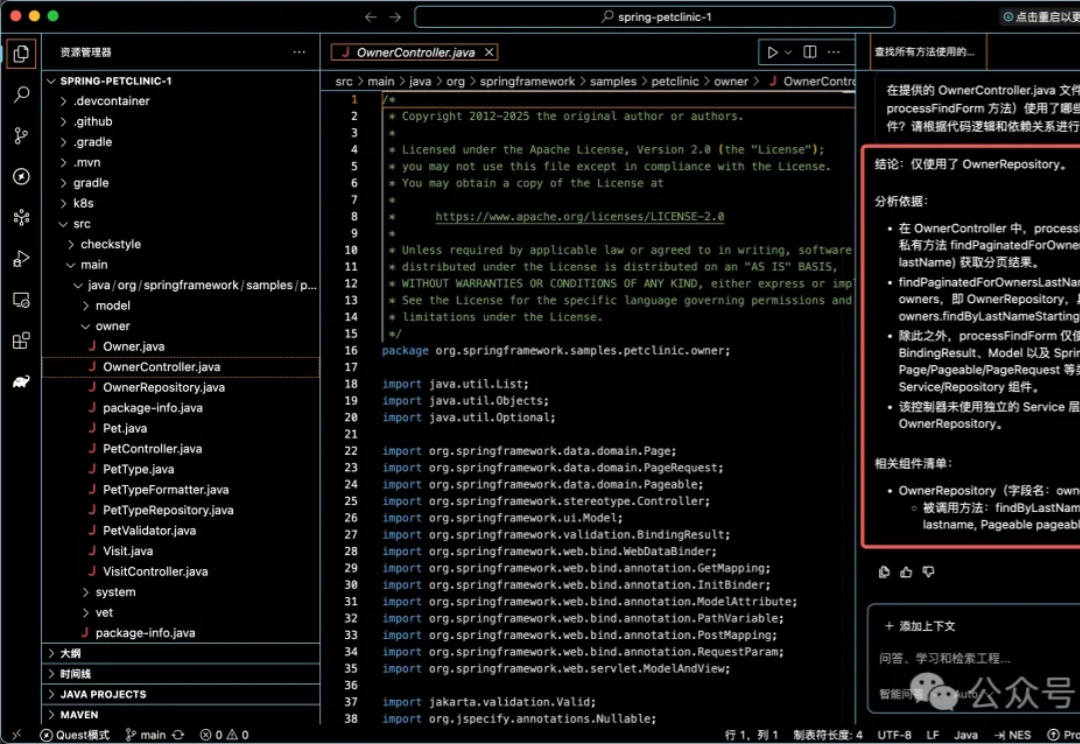
天下程序员苦看懂老、大项目久矣。
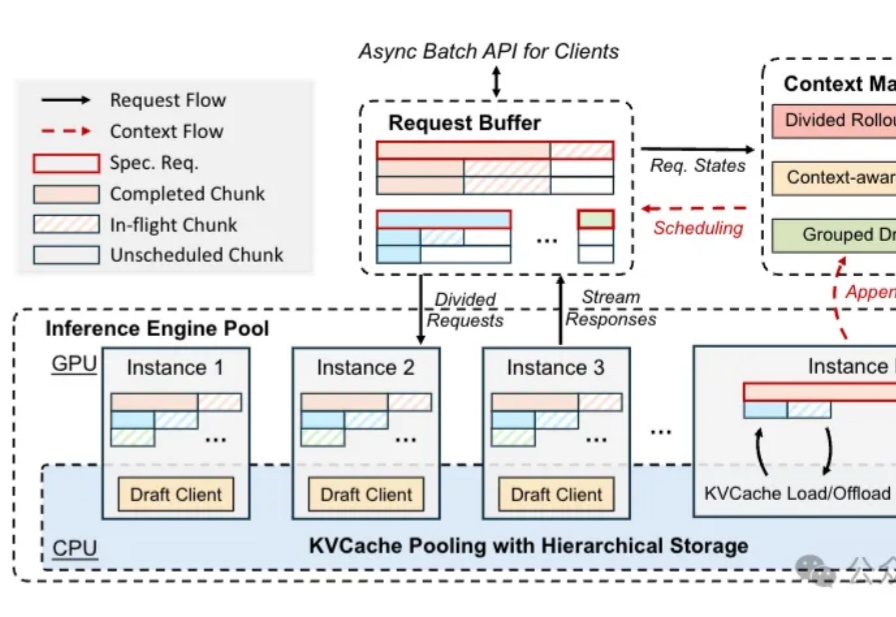
u1s1,现在模型能力是Plus了,但Rollout阶段的速度却越来越慢……

从单张图像创建可编辑的 3D 模型是计算机图形学领域的一大挑战。传统的 3D 生成模型多产出整体式的「黑箱」资产,使得对个别部件进行精细调整几乎成为不可能。

当元宇宙数字人急需「群舞技能」,音乐驱动生成技术却遭遇瓶颈——舞者碰撞、动作僵硬、长序列崩坏。为解决这些难题,南理工、清华、南大联合研发端到端模型TCDiff++,突破多人生成技术壁垒,实现高质量、长时序的群体舞蹈自动生成。
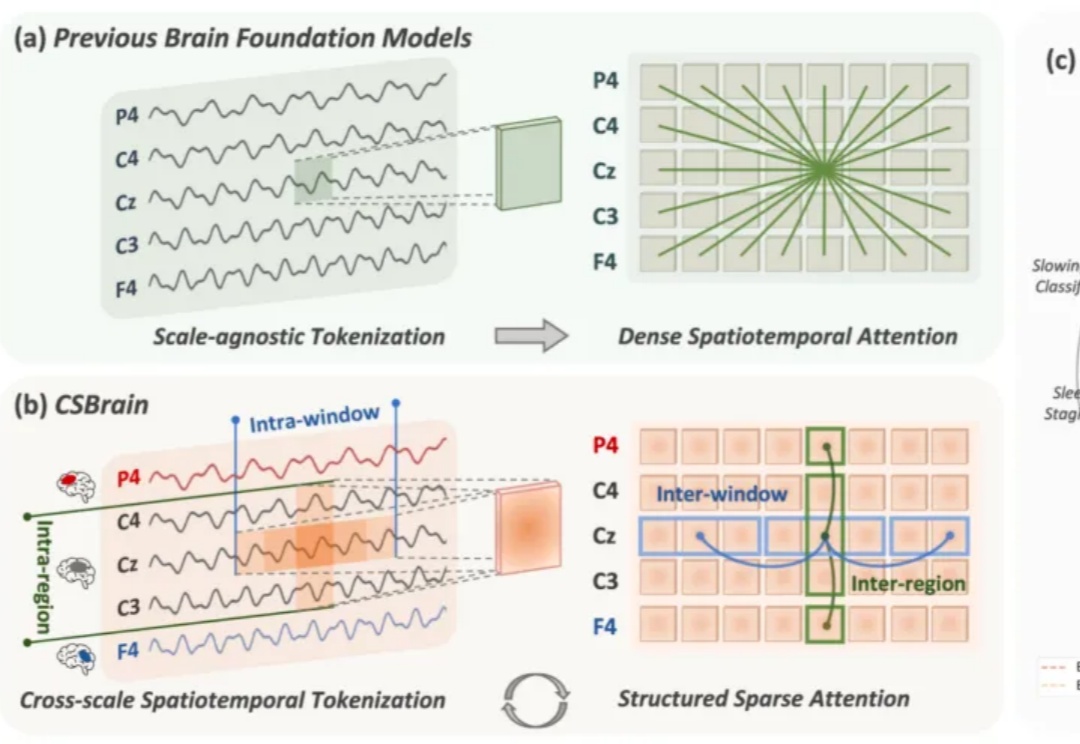
脑机接口(Brain-Computer Interface, BCI)被视为连接人类智能与人工智能的终极界面。要真正实现这一愿景,核心在于高精度的脑信号解码,即让通用 AI 模型能够真正「读懂」复杂多变的脑活动。
刚刚,NeurIPS 2025最佳论文奖、时间检验奖出炉!

在 LLM 优化领域,有两个响亮的名字:Adam(及其变体 AdamW)和 Muon。