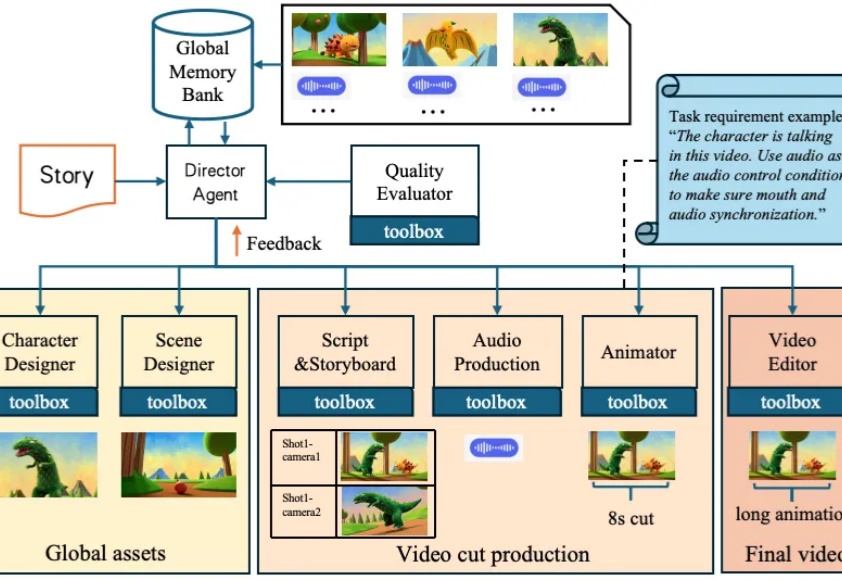
B站正式开源AniSora V3:从单卡4090推理到导演驱动的多智能体动画生成
B站正式开源AniSora V3:从单卡4090推理到导演驱动的多智能体动画生成单台 8 卡 A800 仅需 8 秒即可生成 5 秒视频。
来自主题: AI技术研报
8329 点击 2025-09-11 19:02
 搜索
搜索
单台 8 卡 A800 仅需 8 秒即可生成 5 秒视频。
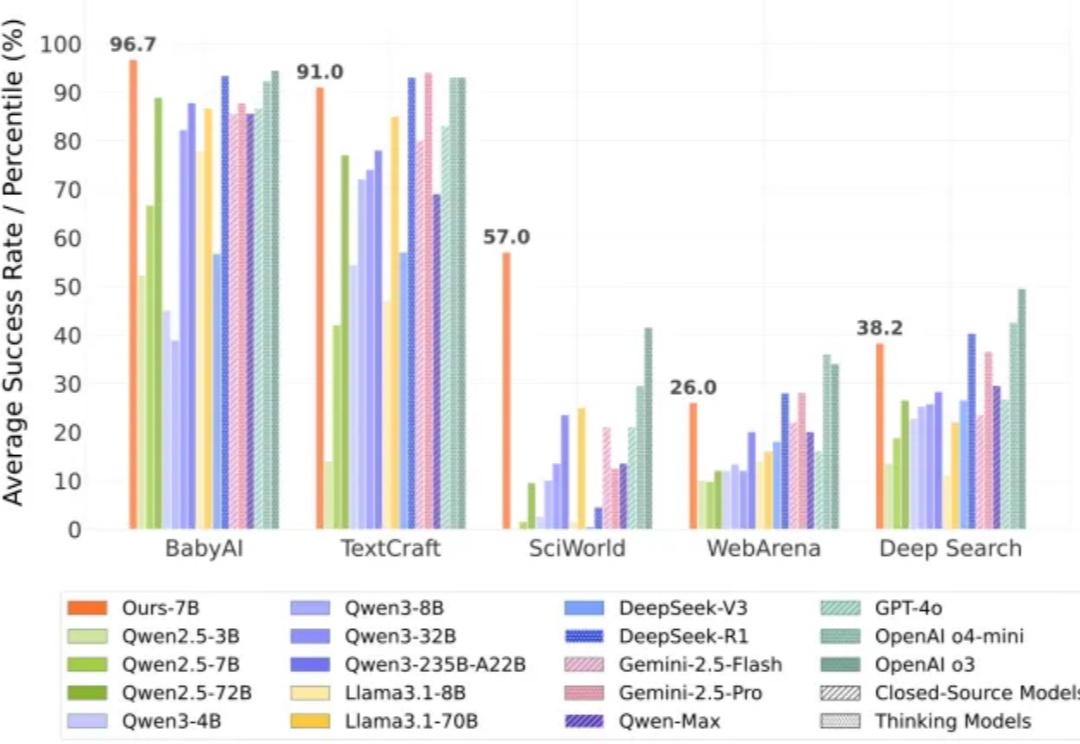
强化学习之父、2024 年 ACM 图灵奖得主 Richard Sutton 曾指出,人工智能正在迈入「经验时代」—— 在这个时代,真正的智能不再仅仅依赖大量标注数据的监督学习,而是来源于在真实环境中主动探索、不断积累经验的能力。
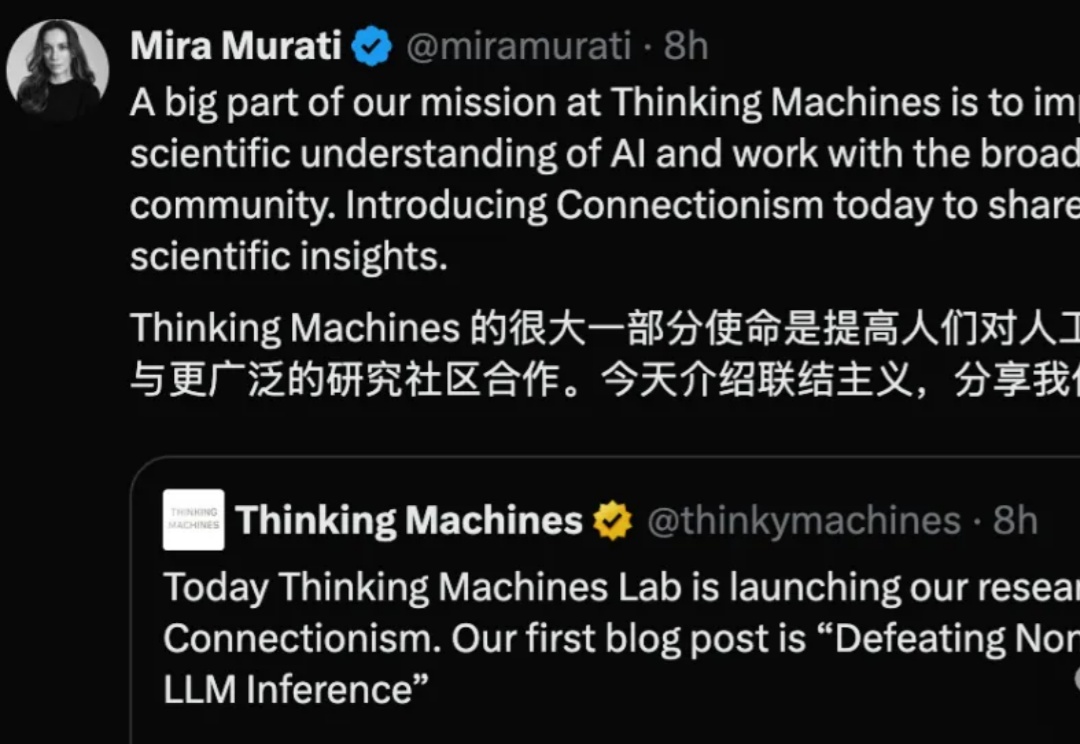
刚刚,0产出估值就已冲破120亿美元的Thinking Machines,终于发布首篇研究博客。

我们今天正式开源 jina-code-embeddings,一套全新的代码向量模型。包含 0.5B 和 1.5B 两种参数规模,并同步推出了 1-4 bit 的 GGUF 量化版本,方便在各类端侧硬件上部署。
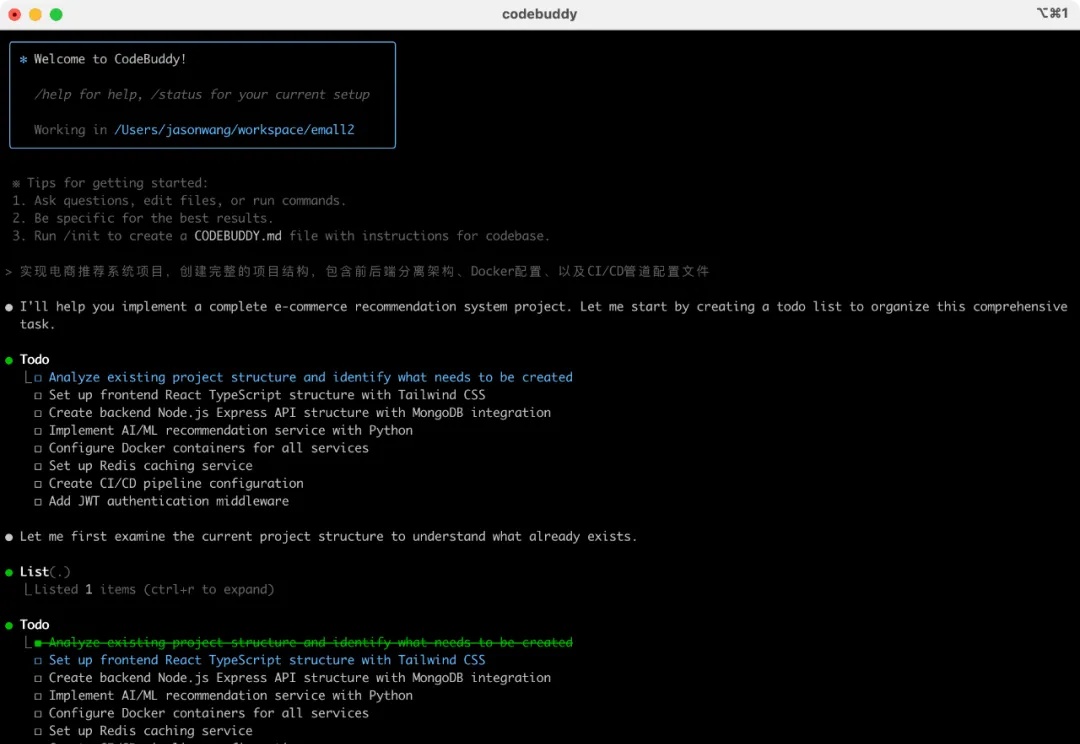
作为一名有着8年全栈开发经验的技术人员,我最近接手了一个具有挑战性的项目:为某中型服装电商平台开发一套智能商品推荐系统。该系统需要在2个月内完成,包含以下核心功能:

大模型在科研领域越来越高效了。

国产自研开源模型,让模型不用在快思考和慢思考间二选一了!
GPT-5真不愧是博士水平的AI!
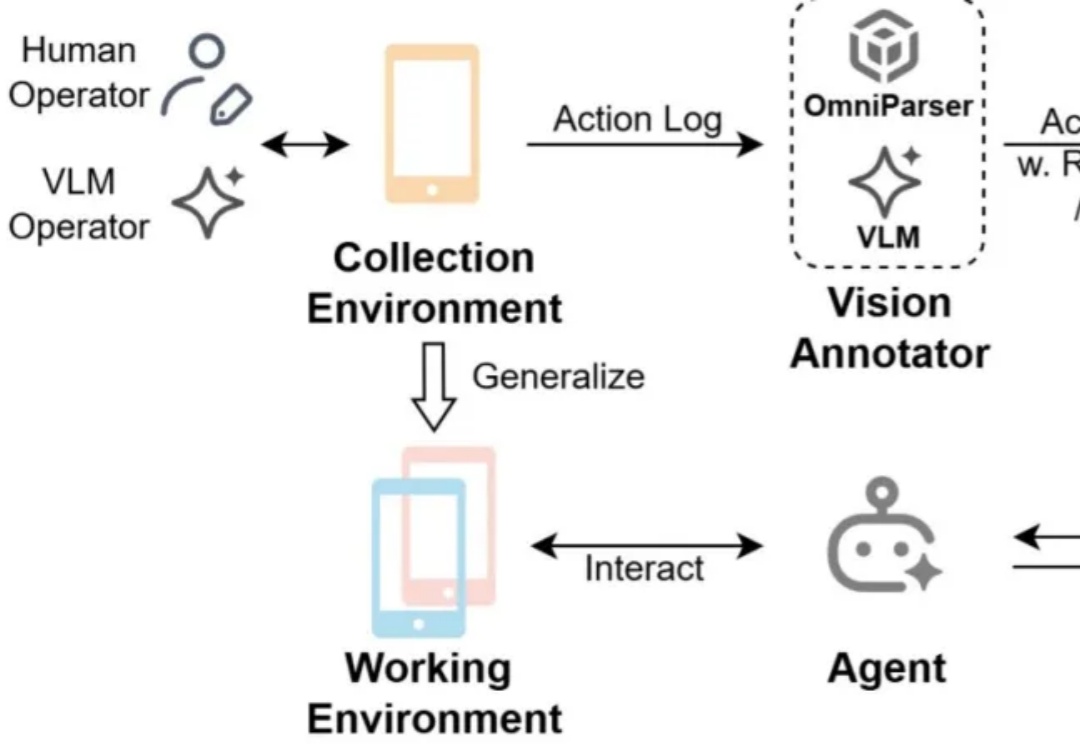
打开手机,让 AI Agent 自动帮你完成订外卖、订酒店、网上购物的琐碎任务,这正成为智能手机交互的新范式。

数据智能体到底好不好用?测评一下就知道了!
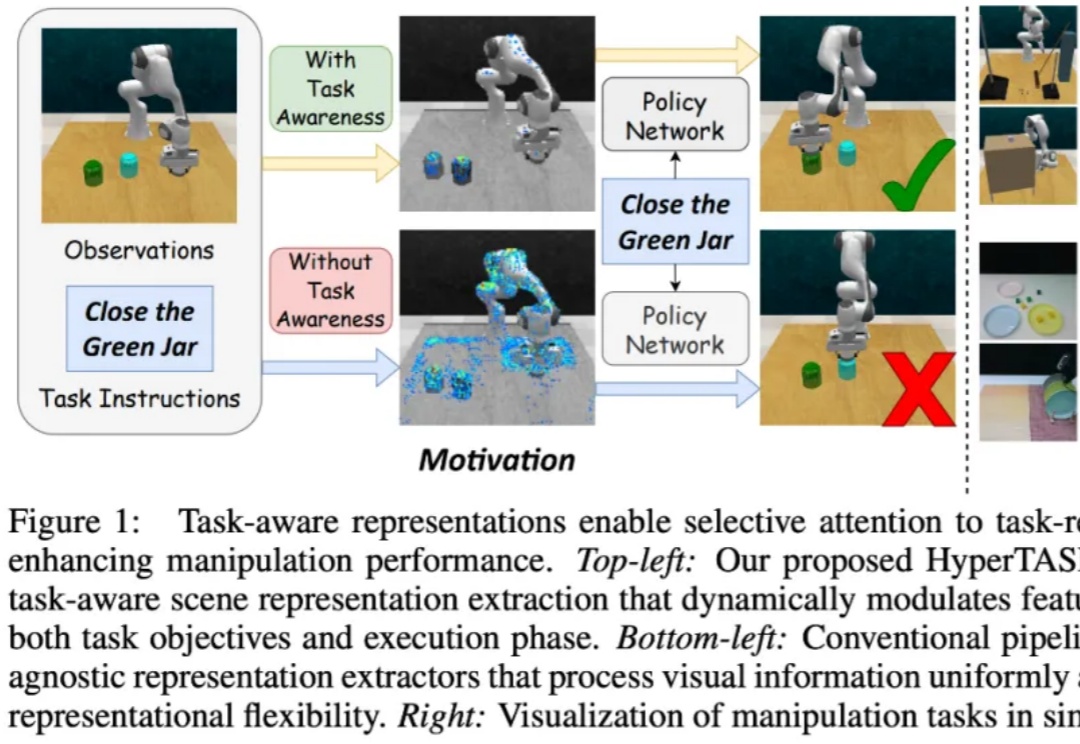
在具身智能中,策略学习通常需要依赖场景表征(scene representation)。然而,大多数现有多任务操作方法中的表征提取过程都是任务无关的(task-agnostic):
机器具备意识吗?本文对AI意识(AI consciousness)进行了考察,特别是深入探讨了大语言模型作为高级计算模型实例是否具备意识,以及AI意识的必要和充分条件。

苦等多年,Excel终于长大了!全新COPILOT函数神器,直接把AI塞进了表格,不论是整理数据、头脑风暴,还是分类反馈,通通一键搞定,打工人效率直接原地起飞。

一群机械臂手忙脚乱地自己干活,彼此配合、互不碰撞。

在现代科学中,几乎所有领域都依赖软件来进行计算实验。但开发这些专用的科学软件是一个非常缓慢、乏味且困难的过程,开发和测试一个新想法(一次“试错”)需要编写复杂的软件,这个过程可能耗费数周、数月甚至数年。

人类一眼就能看懂的文字,AI居然全军覆没。
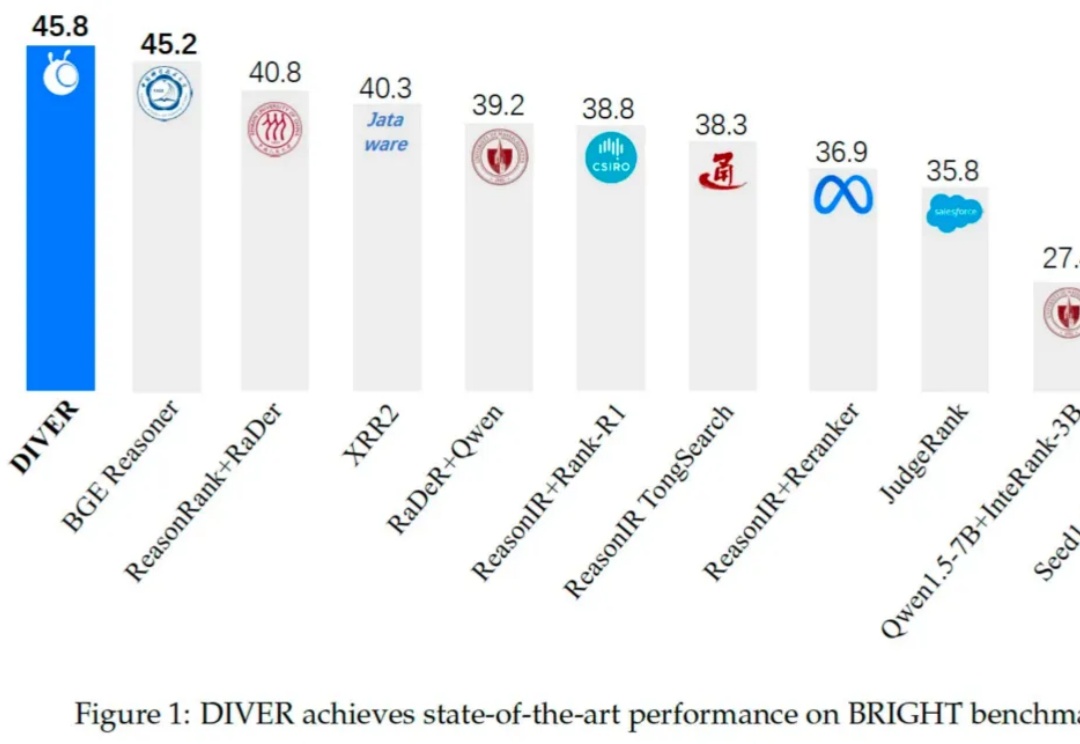
在当前由大语言模型(LLM)驱动的技术范式中,检索增强生成(RAG)已成为提升模型知识能力与缓解「幻觉」的核心技术。然而,现有 RAG 系统在面对需多步逻辑推理任务时仍存在显著局限,具体挑战如下:

Meta超级智能实验室的首篇论文,来了—— 提出了一个名为REFRAG的高效解码框架,重新定义了RAG(检索增强生成),最高可将首字生成延迟(TTFT)加速30倍。

自从 Claude code 上线 sub-agents 后,我一直对其抱很大的期待,每次做 case 都会搭建一支“AI coding 梦之队”。想象中,它们会在主 agent的协调下火力全开, 完成我超级复杂的需求。

过去几年,大语言模型(LLM)的训练大多依赖于基于人类或数据偏好的强化学习(Preference-based Reinforcement Fine-tuning, PBRFT):输入提示、输出文本、获得一个偏好分数。这一范式催生了 GPT-4、Llama-3 等成功的早期大模型,但局限也日益明显:缺乏长期规划、环境交互与持续学习能力。

SpikingBrain借鉴大脑信息处理机制,具有线性/近线性复杂度,在超长序列上具有显著速度优势,在GPU上1M长度下TTFT 速度相比主流大模型提升26.5x, 4M长度下保守估计速度提升超过100x;
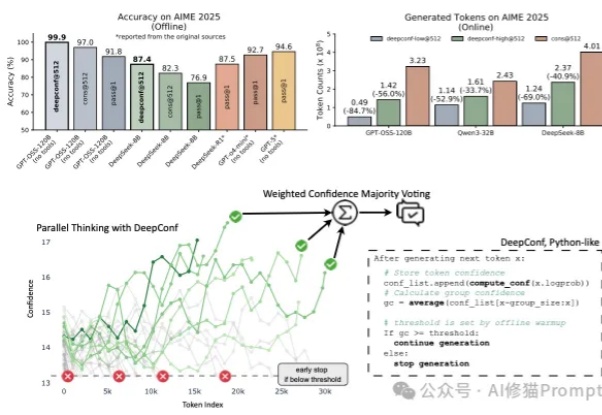
在大型语言模型(LLM)进行数学题、逻辑推理等复杂任务时,一个非常流行且有效的方法叫做 “自洽性”(Self-Consistency),通常也被称为“平行思考”。
继π0后,具身智能基座模型在中国也终于迎来了真正的开源—— 刚刚,WALL-OSS宣布正式开源!在多项指标中,它还超越了π0。如果你是搞具身的开发者,了解它的基本资料,你就一定不会想错过它:

经历了前段时间的鸡飞狗跳,扎克伯格的投资似乎终于初见成效。
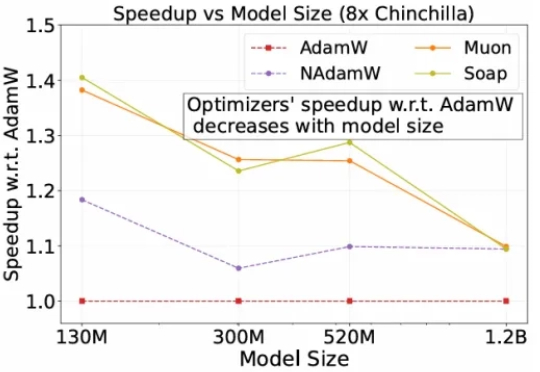
自2014 年提出以来,Adam 及其改进版 AdamW 长期占据开放权重语言模型预训练的主导地位,帮助模型在海量数据下保持稳定并实现较快收敛。
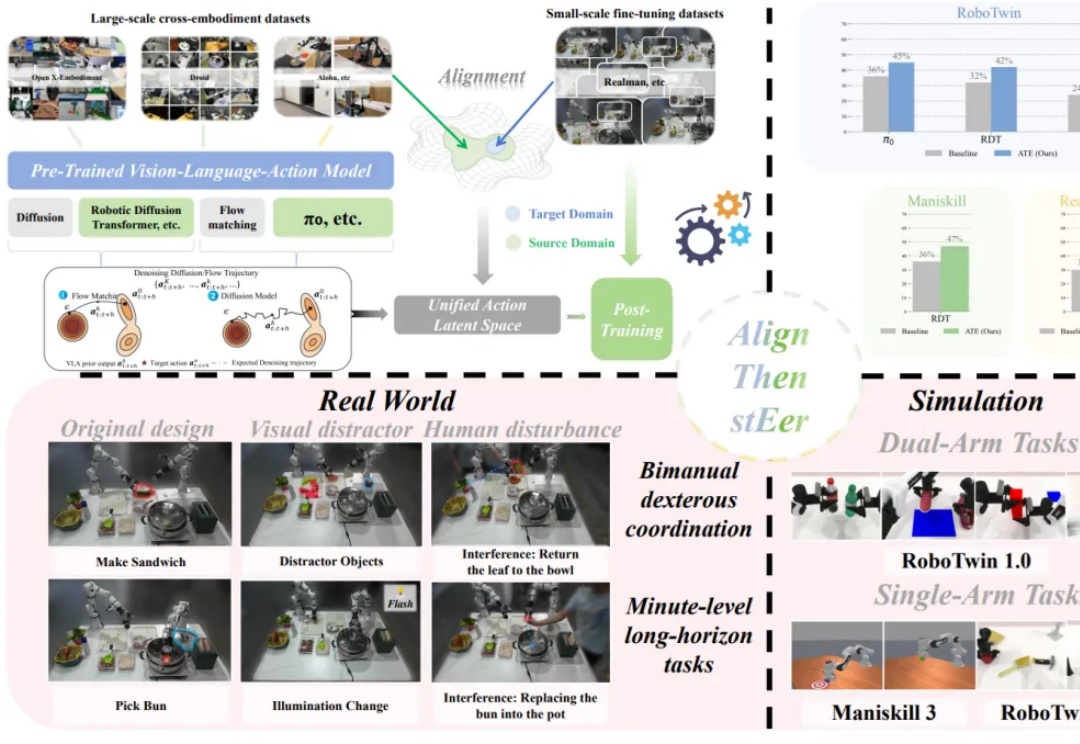
在多模态大模型的基座上,视觉 - 语言 - 动作(Visual-Language-Action, VLA)模型使用大量机器人操作数据进行预训练,有望实现通用的具身操作能力。
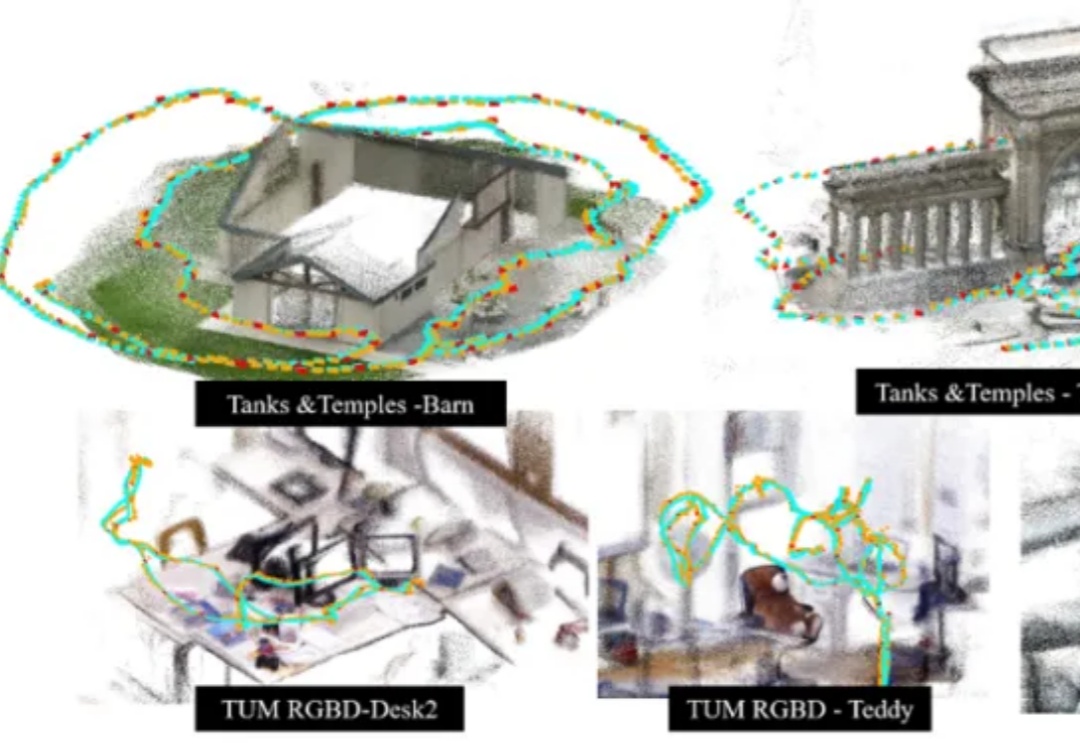
香港科技大学谭平教授团队与地平线(Horizon Robotics)团队最新发布了一项 3D 场景表征与大规模重建新方法 SAIL-Recon,通过锚点图建立构建场景全局隐式表征,突破现有 VGGT 基础模型对于大规模视觉定位与 3D 重建的处理能力瓶颈,实现万帧级的场景表征抽取与定位重建,将空间智能「3D 表征与建模」前沿推向一个新的高度。
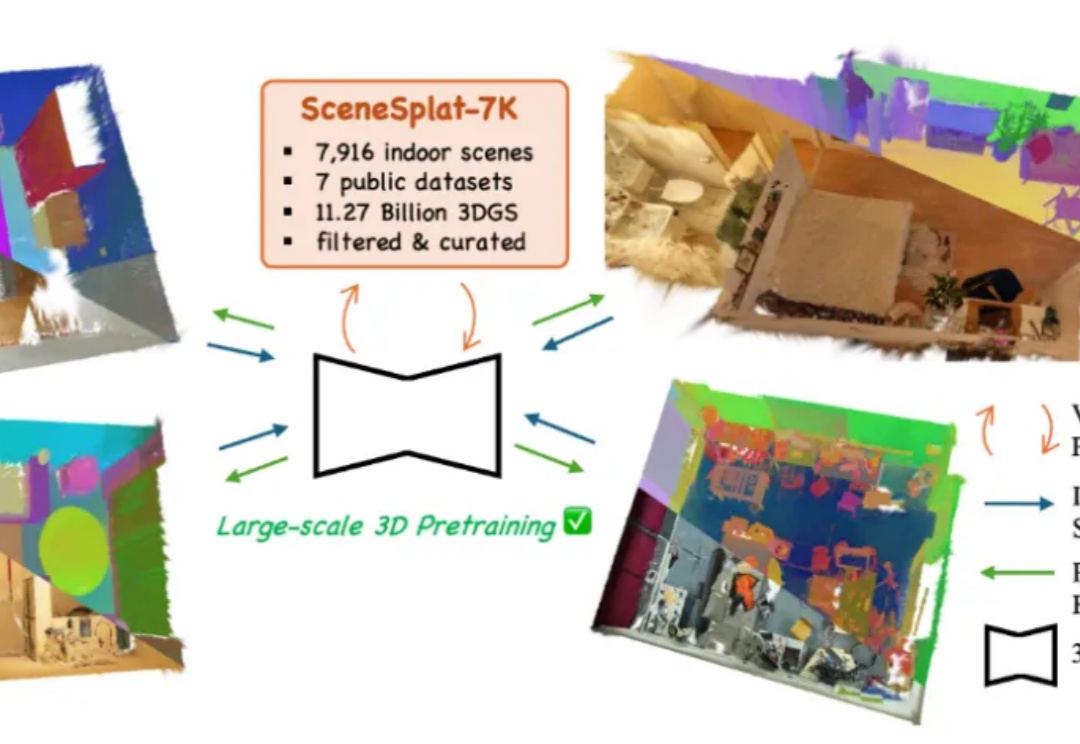
开放词汇识别与分类对于全面理解现实世界的 3D 场景至关重要。目前,所有现有方法在训练或推理过程中都依赖于 2D 或文本模态。这凸显出缺乏能够单独处理 3D 数据以进行端到端语义学习的模型,以及训练此类模型所需的数据。与此同时,3DGS 已成为各种视觉任务中 3D 场景表达的重要标准之一。
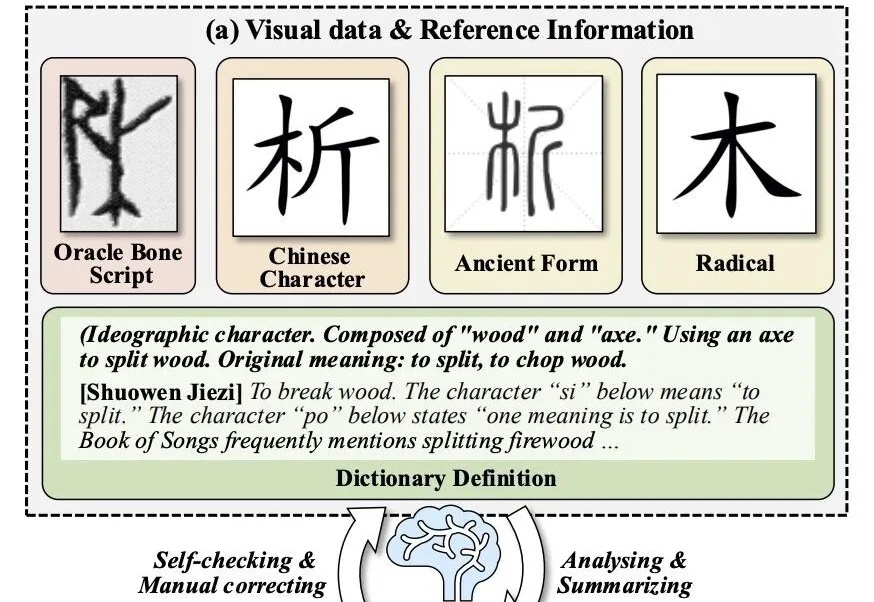
让大模型破译从未见过的甲骨文,准确率拿下新SOTA!

OpenAI重磅结构调整:ChatGPT「模型行为」团队并入Post-Training,前负责人Joanne Jang负责新成立的OAI Labs。而背后原因,可能是他们最近的新发现:评测在奖励模型「幻觉」,模型被逼成「应试选手」。一次组织重组+评测范式重构,也许正在改写AI的能力边界与产品形态。