
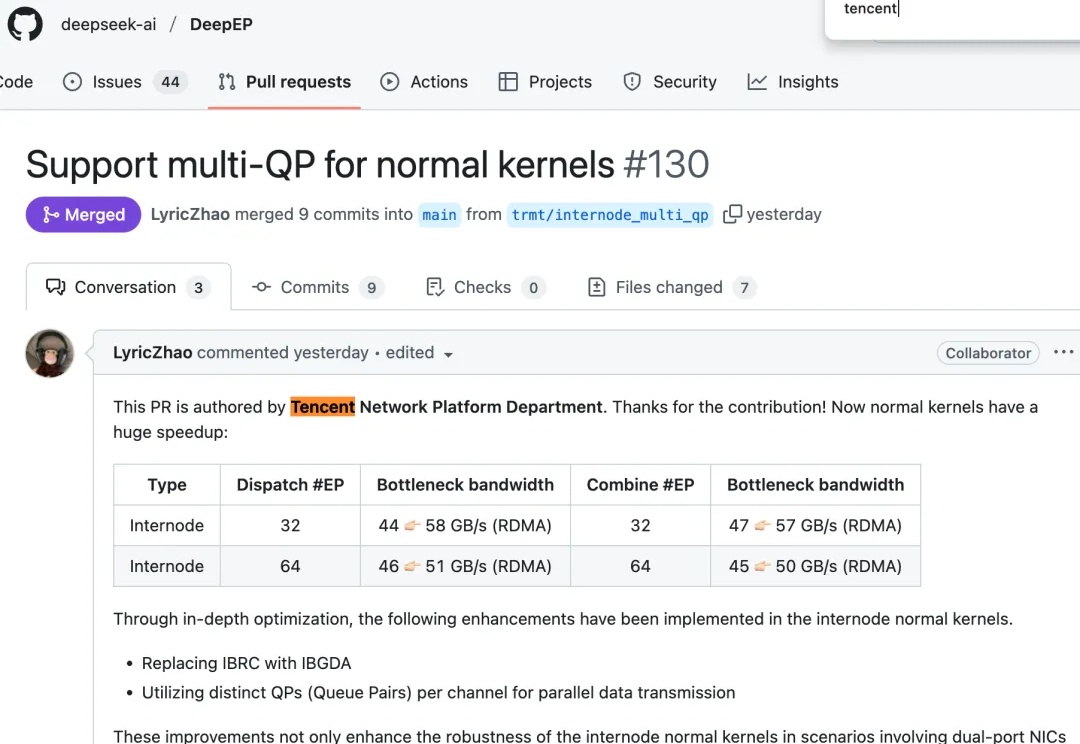
DeepSeek致谢腾讯大模型网络提速技术方案贡献
DeepSeek致谢腾讯大模型网络提速技术方案贡献最近,DeepSeek工程师在GitHub上高亮了来自腾讯的代码贡献,并用“huge speedup”介绍了这次性能提升。
来自主题: AI技术研报
4877 点击 2025-05-08 15:02
最近,DeepSeek工程师在GitHub上高亮了来自腾讯的代码贡献,并用“huge speedup”介绍了这次性能提升。
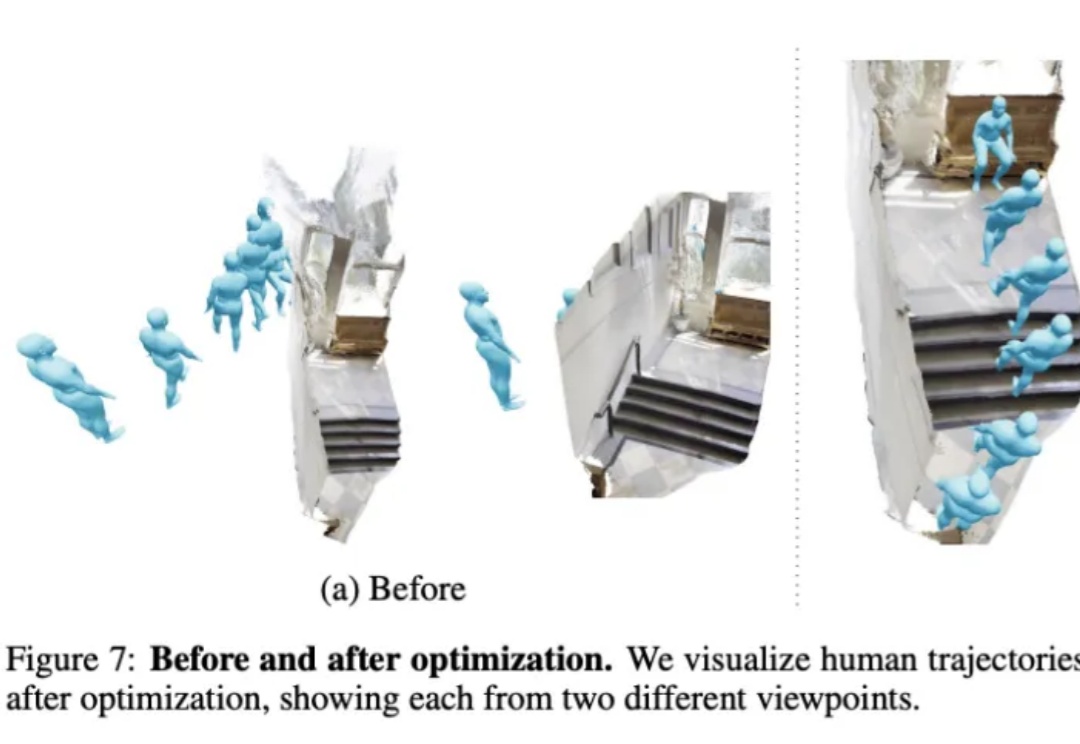
不用动作捕捉,只用一段视频就能教会机器人学会人类动作,效果be like:
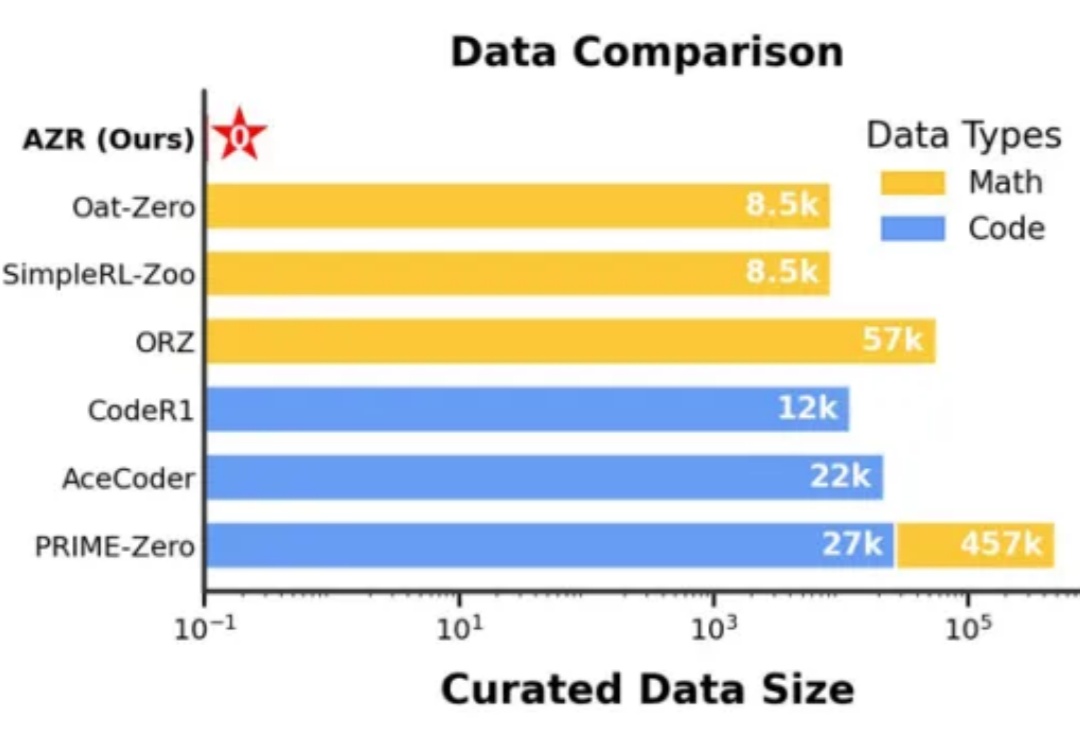
在人工智能领域,推理能力的进化已成为通向通用智能的核心挑战。近期,Reinforcement Learning with Verifiable Rewards(RLVR)范式下涌现出一批「Zero」类推理模型,摆脱了对人类显式推理示范的依赖,通过强化学习过程自我学习推理轨迹,显著减少了监督训练所需的人力成本。

现在,跑准万亿参数的大模型,可以彻底跟英伟达Say Goodbye了。

扩散模型(Diffusion Models)近年来在生成任务上取得了突破性的进展,不仅在图像生成、视频合成、语音合成等领域都实现了卓越表现,推动了文本到图像、视频生成的技术革新。然而,标准扩散模型的设计通常只适用于从随机噪声生成数据的任务,对于图像翻译或图像修复这类明确给定输入和输出之间映射关系的任务并不适合。
当前大模型研究正逐步从依赖扩展定律(Scaling Law)的预训练,转向聚焦推理能力的后训练。鉴于符号逻辑推理的有效性与普遍性,提升大模型的逻辑推理能力成为解决幻觉问题的关键途径。
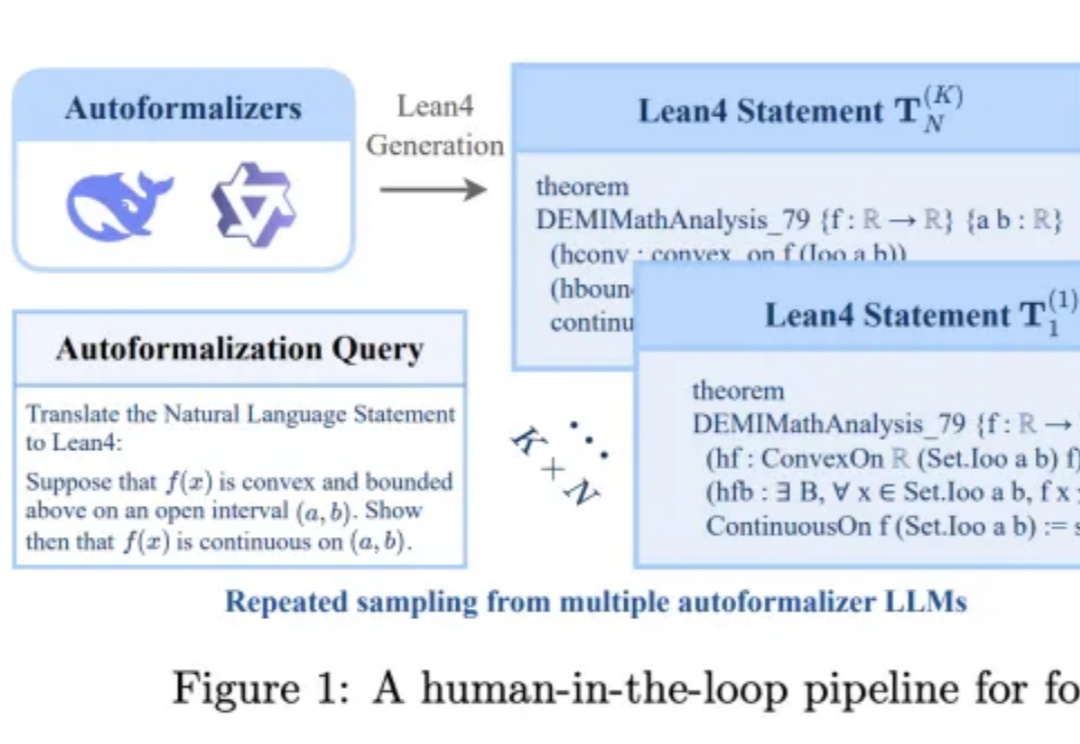
最强AI模型面对5560道数学难题,成功率仅16.46%?背后真相大揭秘。
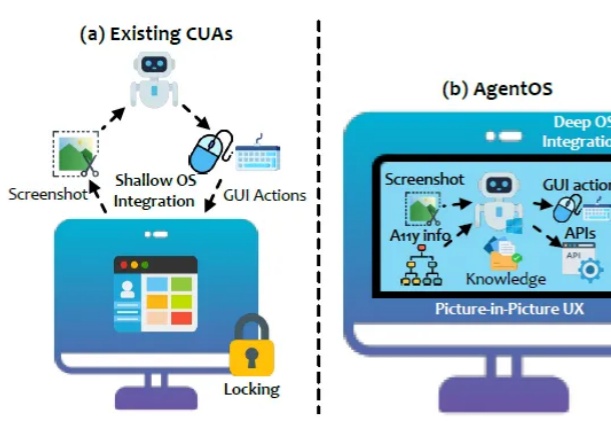
近年来,图形用户界面(GUI)自动化技术正在逐步改变人机交互和办公自动化的生态。然而,以 Robotic Process Automation(RPA)为代表的传统自动化工具通常依赖固定脚本进行操作,存在界面变化敏感、维护成本高昂、用户体验欠佳等明显问题。
自 OpenAI 发布 Sora 以来,AI 视频生成技术进入快速爆发阶段。凭借扩散模型强大的生成能力,我们已经可以看到接近现实的视频生成效果。但在模型逼真度不断提升的同时,速度瓶颈却成为横亘在大规模应用道路上的最大障碍。

字节开源图像编辑新方法,比当前SOTA方法提高9.19%的性能,只用了1/30的训练数据和1/13参数规模的模型。

从 2023 年的 Sora 到如今的可灵、Vidu、通义万相,AIGC 生成式技术的魔法席卷全球,打开了 AI 应用落地的大门。

本周三,知名 AI 创业公司,曾发布「全球首个 AI 软件工程师」的 Cognition AI 开源了一款使用强化学习,用于编写 CUDA 内核的大模型 Kevin-32B。

随着Gemini、GPT-4o等商业大模型把基于文本的图像编辑这一任务再次推向高峰,获取更高质量的编辑数据用于训练、以及训练更大参数量的模型似乎成了提高图像编辑性能的唯一出路。然而浙大哈佛这个团队却反其道而行之,仅用以往工作0.1%的数据量(获取自公开数据集)和1%的训练参数,以极低成本实现了图像的高质量编辑,在一些方面媲美甚至超越商业大模型!

强化学习(RL)是当今 AI 领域最热门的词汇之一。近日,一篇长文梳理了新时代的强化学习范式对于模型提升的作用,同时还探索了强化学习对去中心化的意义。
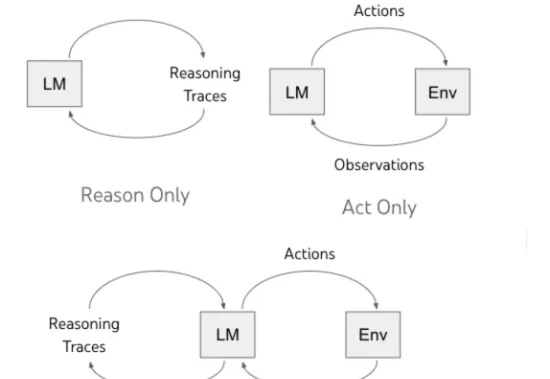
Agent 即一系列自动化帮助人类完成具体任务的智能体或者智能助手,可以自主进行推理,与环境进行交互并获取环境以及人类反馈,从而最终完成给定的任务,比如最近爆火的 Manus 以及 OpenAI 的 o3 等一系列模型和框架。
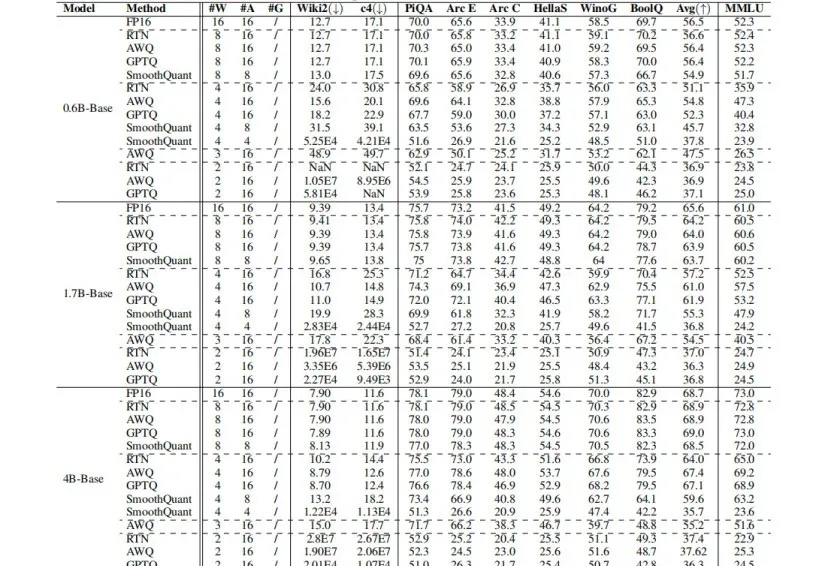
Qwen3强势刷新开源模型SOTA,但如何让其在资源受限场景中,既能实现低比特量化,又能保证模型“智商”不掉线?
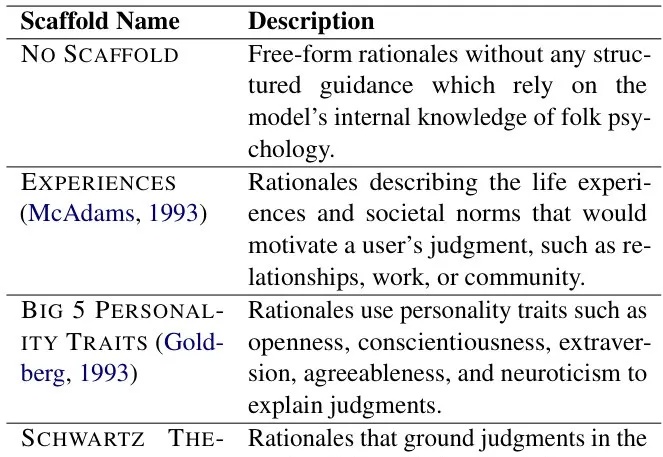
照这个发展速度,不远的将来AI不仅能模仿你的行为,还能理解你为何做出这些选择。PB&J框架正是这一突破性技术的代表,它通过引入心理学中的"支架"概念,使AI能够构建合理化解释,深入理解人类决策背后的动机。
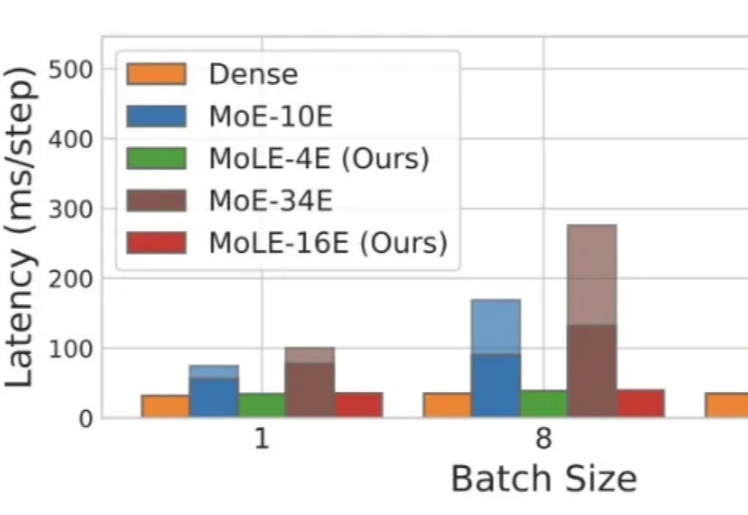
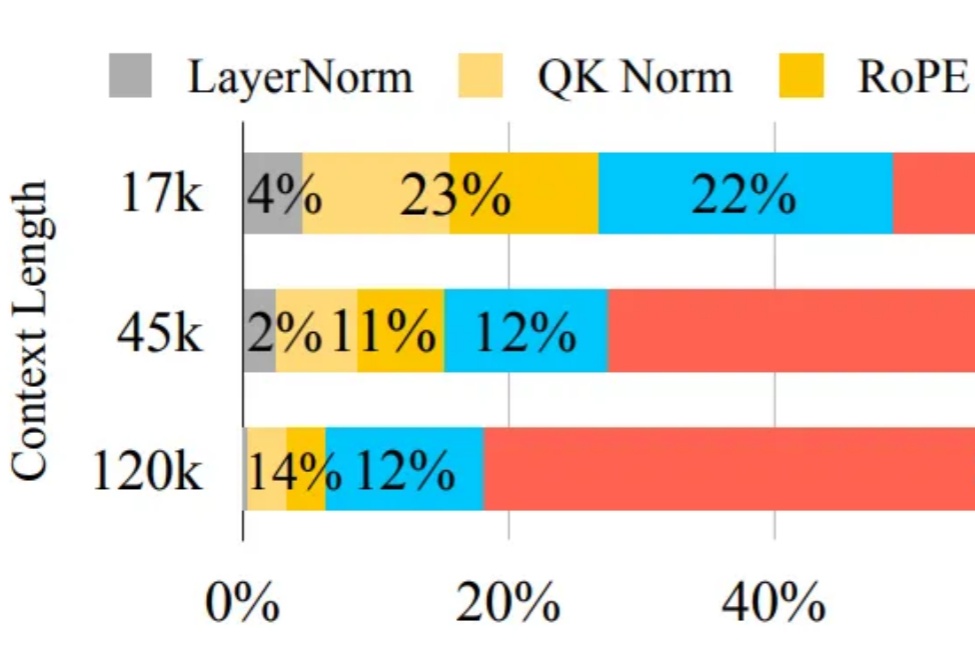
Mixture-of-Experts(MoE)在推理时仅激活每个 token 所需的一小部分专家,凭借其稀疏激活的特点,已成为当前 LLM 中的主流架构。然而,MoE 虽然显著降低了推理时的计算量,但整体参数规模依然大于同等性能的 Dense 模型,因此在显存资源极为受限的端侧部署场景中,仍然面临较大挑战。

超越DeepSeek-R1的英伟达开源新王Llama-Nemotron,是怎么训练出来的?刚刚放出的论文,把一切细节毫无保留地全部揭秘了!
上个月, GPT-4o 的图像生成功能爆火,掀起了以吉卜力风为代表的广泛讨论,生成式 AI 的热潮再次席卷网络。
这个五一假期,世界顶级数学家是如何度过的?

随着 Deepseek 等强推理模型的成功,强化学习在大语言模型训练中越来越重要,但在视频生成领域缺少探索。复旦大学等机构将强化学习引入到视频生成领域,经过强化学习优化的视频生成模型,生成效果更加自然流畅,更加合理。并且分别在 VDC(Video Detailed Captioning)[1] 和 VBench [2] 两大国际权威榜单中斩获第一。

你信任的AI排行榜,可能只是一场精心策划的骗局!震惊业界的Cohere Labs最新研究彻底撕破了Chatbot Arena这一所谓"黄金标准"的华丽面纱,揭露了科技巨头们如何肆无忌惮地操控评估系统、掠夺社区资源、扼杀开源创新。

大型语言模型(LLMs)在上下文知识理解方面取得了令人瞩目的成功。

研究揭示早融合架构在低计算预算下表现更优,训练效率更高。混合专家(MoE)技术让模型动态适应不同模态,显著提升性能,堪称多模态模型的秘密武器。

具身智能最大的挑战在于泛化能力,即在陌生环境中正确完成任务。最近,Physical Intelligence推出全新的π0.5 VLA模型,通过异构任务协同训练实现了泛化,各种家务都能拿捏。
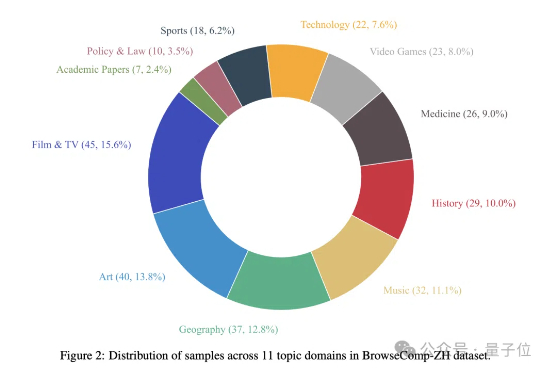
你以为大模型已经能轻松“上网冲浪”了?
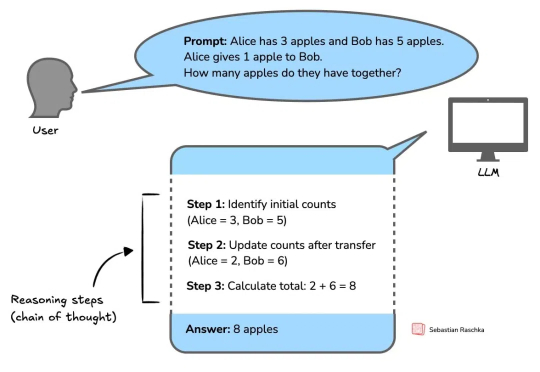
推理模型发展正盛,著名 AI 技术博主 Sebastian Raschka 也正在写一本关于推理模型工作方式的新书《Reasoning From Scratch》。

科幻中AI自我复制失控场景,正成为现实世界严肃的研究课题。英国AISI推出RepliBench基准,分解并评估AI自主复制所需的四大核心能力。测试显示,当前AI尚不具备完全自主复制能力,但在获取资源等子任务上已展现显著进展。

本文深入梳理了围绕DeepSeek-R1展开的多项复现研究,系统解析了监督微调(SFT)、强化学习(RL)以及奖励机制、数据构建等关键技术细节。