
Nature | 基因组所贾耿介团队联合中国科大、新加坡中央医院团队开发出预测肝癌术后复发风险的高精度AI诊断工具
Nature | 基因组所贾耿介团队联合中国科大、新加坡中央医院团队开发出预测肝癌术后复发风险的高精度AI诊断工具肝癌是全球癌症相关死亡的第三大原因,手术切除后的复发率高达70%,如何准确预测肿瘤手术切除后复发风险是一个难题。
来自主题: AI技术研报
6383 点击 2025-03-17 16:56
肝癌是全球癌症相关死亡的第三大原因,手术切除后的复发率高达70%,如何准确预测肿瘤手术切除后复发风险是一个难题。
HuixiangDou 是群聊场景的 LLM 知识助手。

角色扮演 AI(Role-Playing Language Agents,RPLAs)作为大语言模型(LLM)的重要应用,近年来获得了广泛关注。

最近一段时间,智能体(Agent)再次成为 AI 领域热议的焦点。
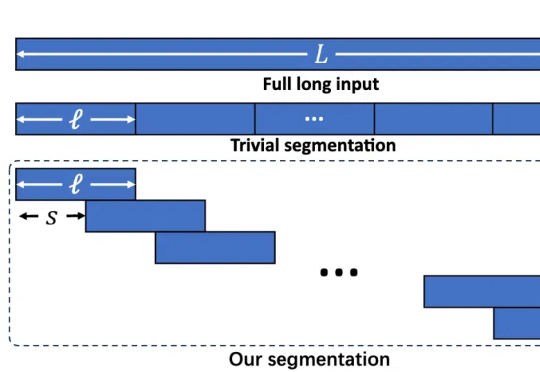
长文本任务是当下大模型研究的重点之一。在实际场景和应用中,普遍存在大量长序列(文本、语音、视频等),有些甚至长达百万级 tokens。

跨模态因果对齐,让机器更懂视觉证据!
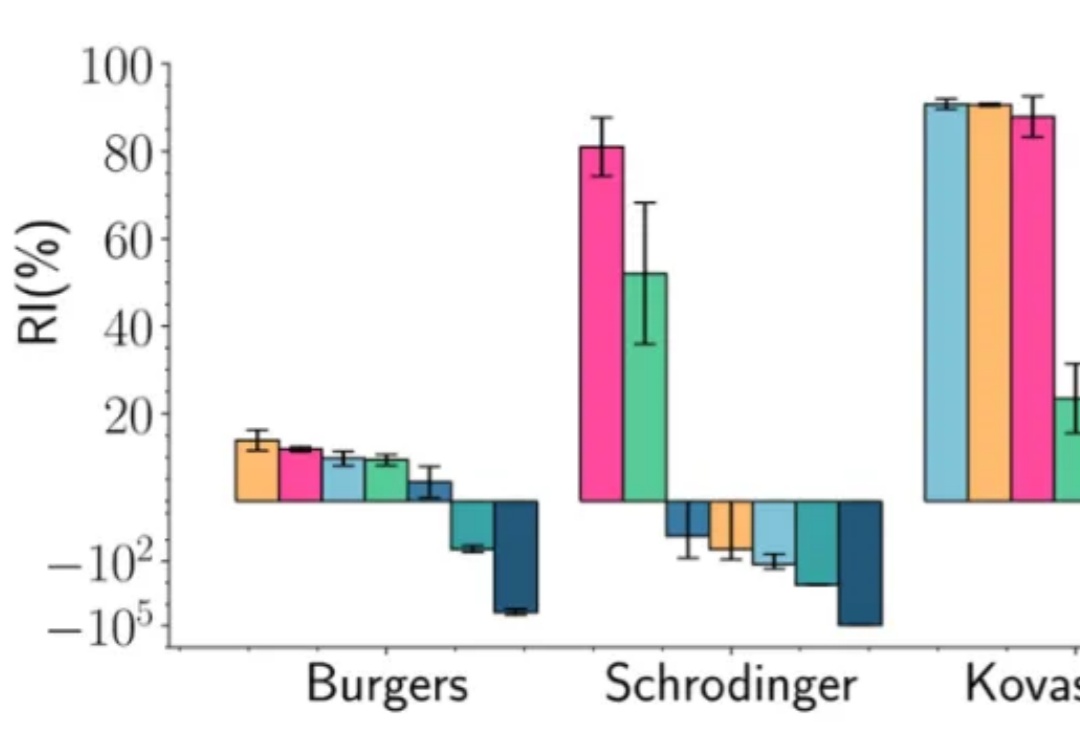
在深度学习的多个应用场景中,联合优化多个损失项是一个普遍的问题。典型的例子包括物理信息神经网络(Physics-Informed Neural Networks, PINNs)、多任务学习(Multi-Task Learning, MTL)和连续学习(Continual Learning, CL)。然而,不同损失项的梯度方向往往相互冲突,导致优化过程陷入局部最优甚至训练失败。
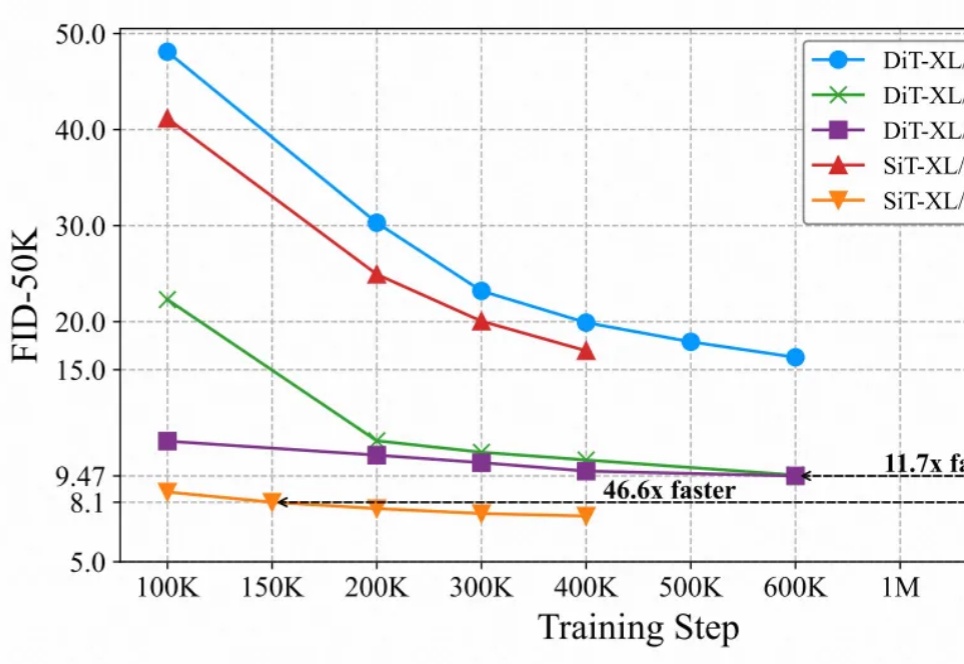
最近的研究强调了扩散模型与表征学习之间的相互作用。扩散模型的中间表征可用于下游视觉任务,同时视觉模型表征能够提升扩散模型的收敛速度和生成质量。然而,由于输入不匹配和 VAE 潜在空间的使用,将视觉模型的预训练权重迁移到扩散模型中仍然具有挑战性。
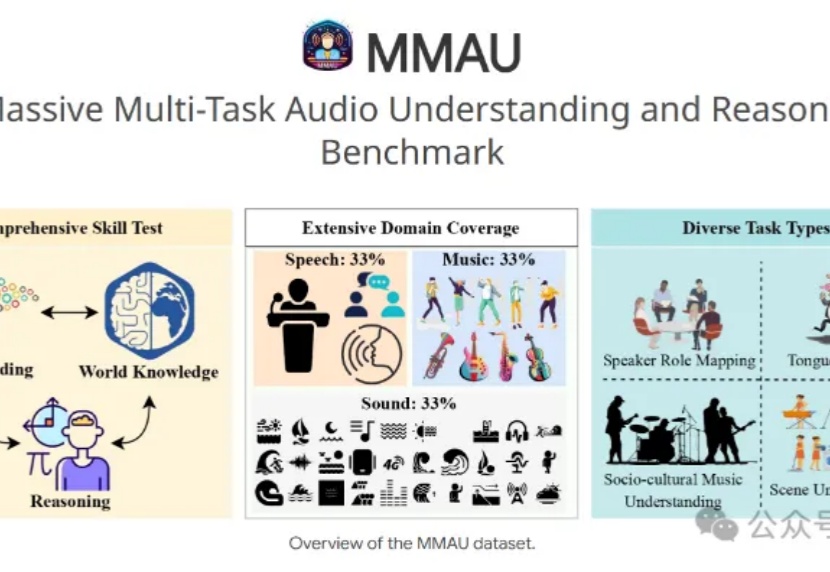
7B小模型+3.8万条训练数据,就能让音频理解和推断评测基准MMAU榜单王座易主?

LMM在人类反馈下表现如何?新加坡国立大学华人团队提出InterFeedback框架,结果显示,最先进的LMM通过人类反馈纠正结果的比例不到50%!
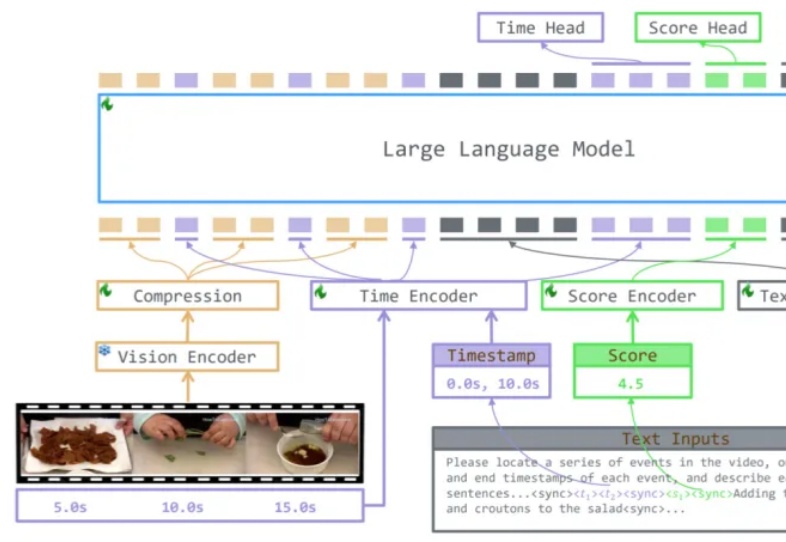
下班回家后你正深陷于一部两小时的综艺节目中,渴望找到那些让人捧腹的爆笑片段,却如同大海捞针。或者,在紧张刺激的足球赛中,你渴望捕捉到那决定性的绝杀瞬间,但传统 AI 视频处理技术效率低下,且模型缺乏泛化能力。为解决这些问题,香港中文大学(深圳)唐晓莹课题组联合腾讯 PCG 发布 TRACE 技术,通过因果事件建模为视频理解大模型提供精准的时间定位能力。

无需物理引擎,单个模型也能实现“渲染+逆渲染”了!

谷歌团队发现了全新Scaling Law!新方法DiLoCo被证明更好、更快、更强,可在多个数据中心训练越来越大的LLM。

AI-Researcher是一个开源的科研智能体框架,它能从文献搜集一路包办至论文撰写,彻底改变了科研方式,让科研自动化触手可及。
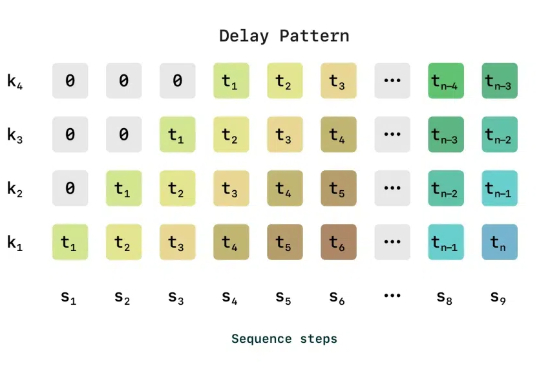
语音恐怖谷是指在语音合成技术中,当 AI 合成语音接近人类的真实语音,但又存在细微的不自然或不完美之处时,会引发人类的不适感。

何恺明团队提出的去噪哈密顿网络(DHN),将哈密顿力学融入神经网络,突破传统局部时间步限制,还有独特去噪机制,在物理推理任务中表现卓越。
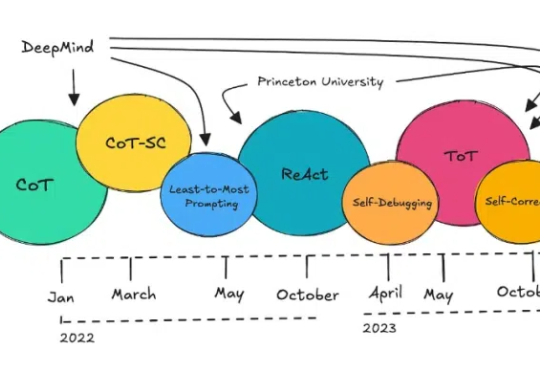
近段时间,推理模型 DeepSeek R1 可说是 AI 领域的头号话题。用过的都知道,该模型在输出最终回答之前,会先输出一段思维链内容。这样做可以提升最终答案的准确性。
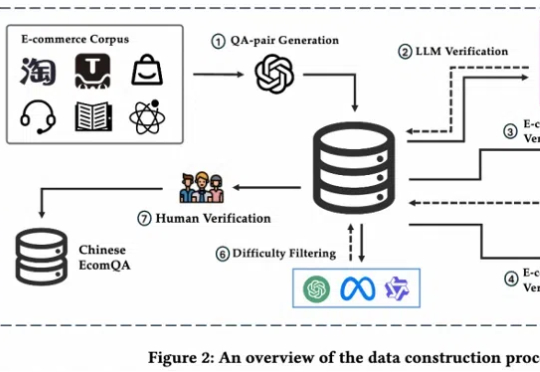
全面评估大模型电商领域能力,首个聚焦电商基础概念的可扩展问答基准来了!
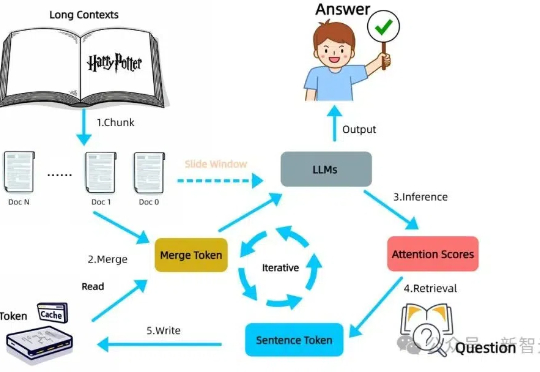
LLM自身有望在无限长token下检索信息!无需训练,在检索任务「大海捞针」(Needle-in-a-Haystack)测试中,新方法InfiniRetri让有效上下文token长度从32K扩展至1000+K,让7B模型比肩72B模型。
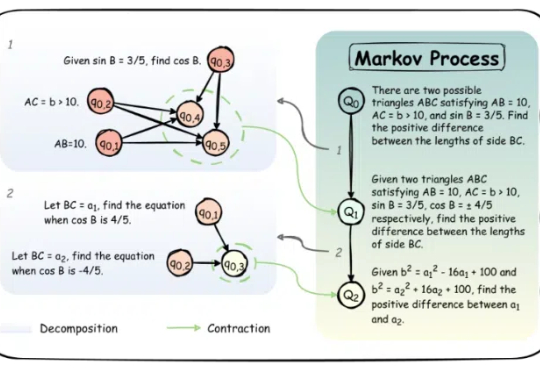
大语言模型(LLM)近年来凭借训练时扩展(train-time scaling)取得了显著性能提升。然而,随着模型规模和数据量的瓶颈显现,测试时扩展(test-time scaling)成为进一步释放潜力的新方向。
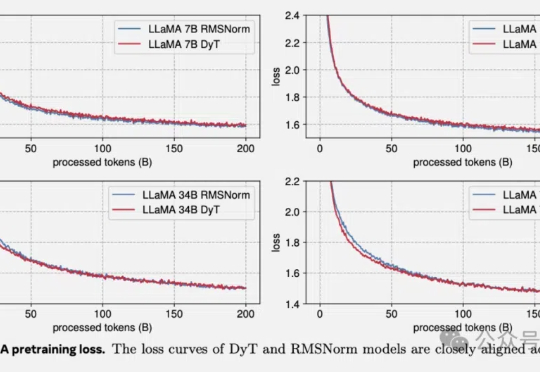
何恺明LeCun联手:Transformer不要归一化了,论文已入选CVPR2025。
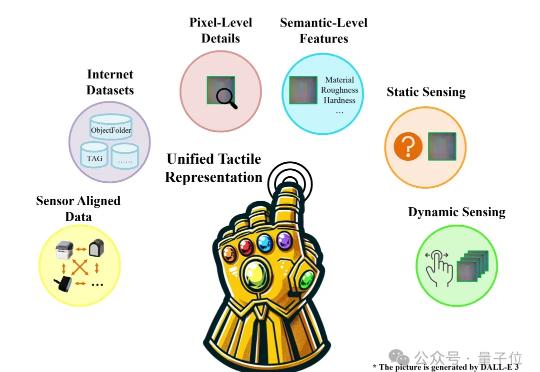
机器人怎样感知世界?
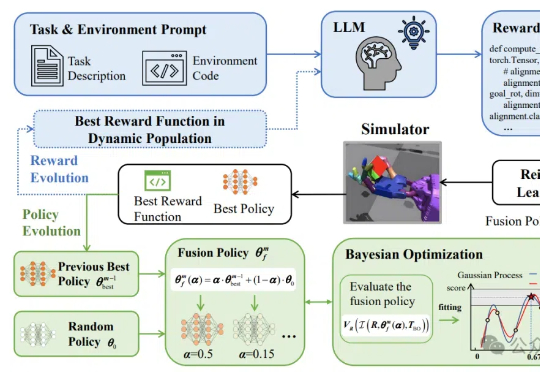
让机器人轻松学习复杂技能有新框架了!
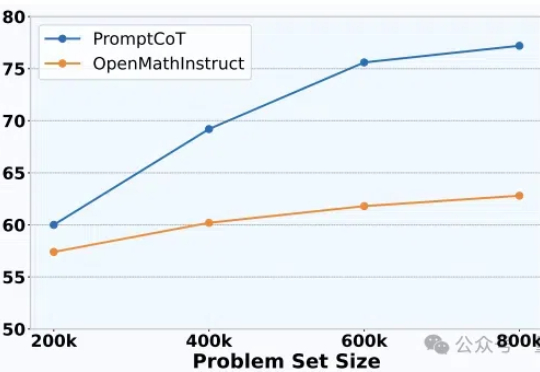
大模型架构研究进展太快,数据却快要不够用了,其中问题数据又尤其缺乏。

「压缩即智能」。这并不是一个新想法,著名 AI 研究科学家、OpenAI 与 SSI 联合创始人 Ilya Sutskever 就曾表达过类似的观点。

当前,视觉语言模型(VLMs)的能力边界不断被突破,但大多数评测基准仍聚焦于复杂知识推理或专业场景。本文提出全新视角:如果一项能力对人类而言是 “无需思考” 的本能,但对 AI 却是巨大挑战,它是否才是 VLMs 亟待突破的核心瓶颈?

今年,CVPR共有13008份有效投稿并进入评审流程,其中2878篇被录用,最终录用率为22.1%。

Transformer架构迎来历史性突破!刚刚,何恺明LeCun、清华姚班刘壮联手,用9行代码砍掉了Transformer「标配」归一化层,创造了性能不减反增的奇迹。
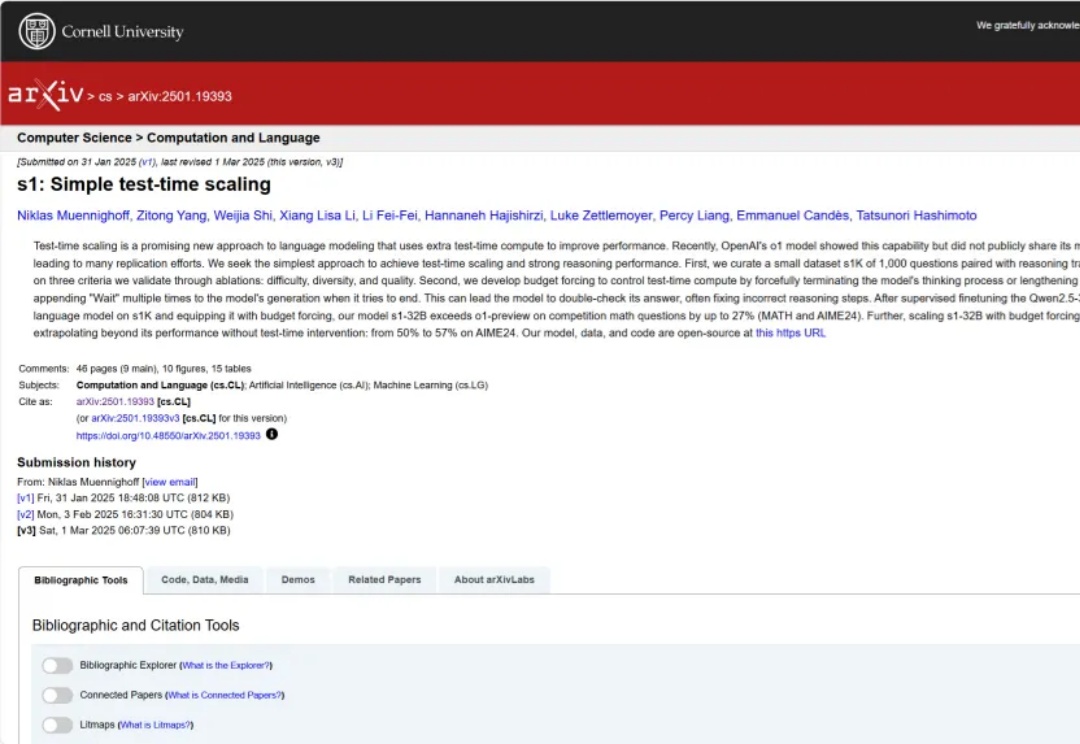
现在是 2025 年,新论文要以博客形式出现。
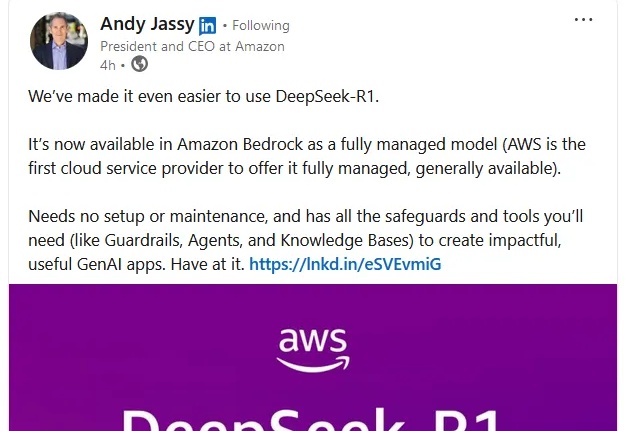
给大模型落地,加入极致的务实主义。