
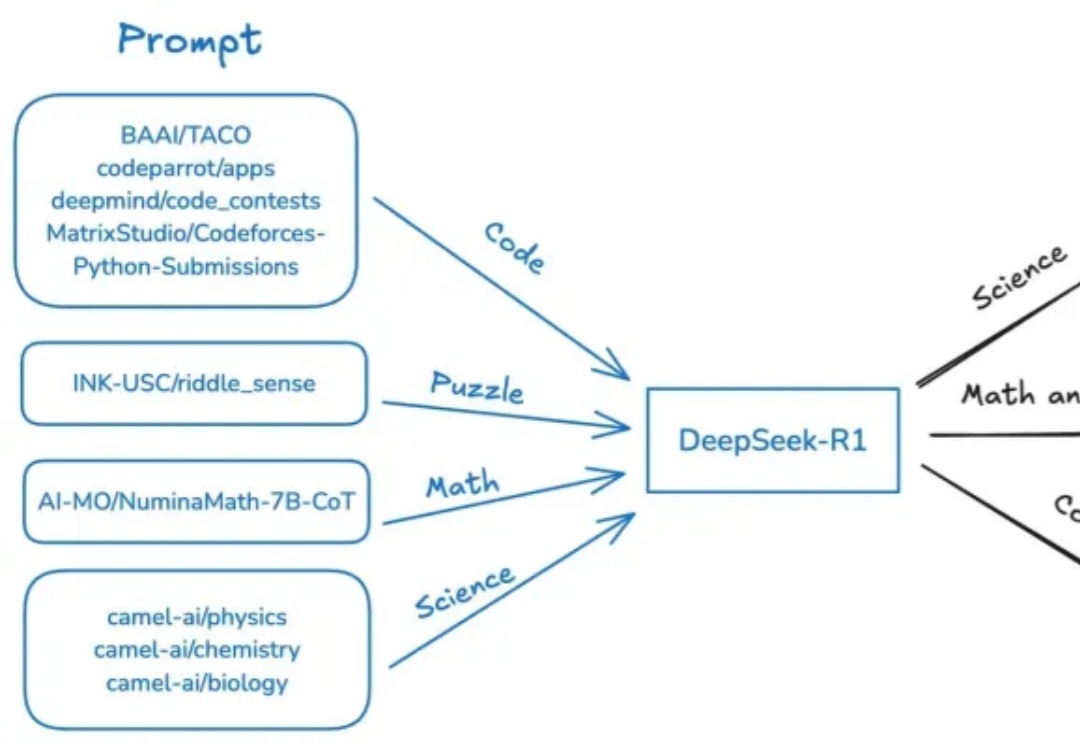
直逼DeepSeek-R1-32B,碾压李飞飞s1!UC伯克利等开源全新SOTA推理模型
直逼DeepSeek-R1-32B,碾压李飞飞s1!UC伯克利等开源全新SOTA推理模型近日,斯坦福、UC伯克利等多机构联手发布了开源推理新SOTA——OpenThinker-32B,性能直逼DeepSeek-R1-32B。其成功秘诀在于数据规模化、严格验证和模型扩展。
来自主题: AI技术研报
6099 点击 2025-02-14 11:09
近日,斯坦福、UC伯克利等多机构联手发布了开源推理新SOTA——OpenThinker-32B,性能直逼DeepSeek-R1-32B。其成功秘诀在于数据规模化、严格验证和模型扩展。

一个简单的笑脸😀可能远不止这么简单?最近,AI大神Karpathy发现,一个😀竟然占用了多达53个token!这背后隐藏着Unicode编码的哪些秘密?如何利用这些「隐形字符」在文本中嵌入、传递甚至「隐藏」任意数据。更有趣的是,这种「数据隐藏术」甚至能对AI模型进行「提示注入」!

今天向大家介绍一项来自香港大学黄超教授实验室的最新科研成果 VideoRAG。这项创新性的研究突破了超长视频理解任务中的时长限制,仅凭单张 RTX 3090 GPU (24GB) 就能高效理解数百小时的超长视频内容。

奥特曼回应一切,OpenAI路线图全曝光。GPT-4.5数周发布,成为GPT系最后一个非推理模型。GPT-5将整合o系和GPT系,打造成一个全能系统。最令人兴奋的是,所有人皆可免费用上GPT-5。

新型验证码IllusionCAPTCHA,利用视觉错觉和诱导性提示,使AI难以识别,而人类用户能轻松通过。实验表明,该验证码能有效防御大模型攻击,同时提升用户体验,为验证码技术提供了新思路。

这项尝试只用到了 R1 模型和基本验证器,没有针对 R1 的工具,没有对专有的英伟达代码进行微调。其实根据 DeepSeek 介绍,R1 的编码能力不算顶尖。

【新智元导读】仅凭测试时Scaling,1B模型竟完胜405B!多机构联手巧妙应用计算最优TTS策略,不仅0.5B模型在数学任务上碾压GPT-4o,7B模型更是力压o1、DeepSeek R1这样的顶尖选手。
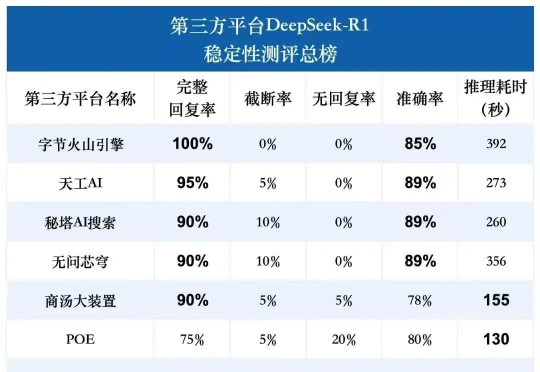
我是先看到了一张极其意料之外的图。首先我要说除了DeepSeek 官方,其他家都很稳定(这里没有吐槽官方的意思,毕竟情况特殊) 至少我没检测到超时或者断开。

在数字化浪潮中,生成式人工智能强势闯入管理领域。多数管理者期待它成为得力思维伙伴,却面临应用技能短板。如何跨越这道鸿沟,让AI为管理赋能?“协同思考”或许是解锁强大潜能的关键,带你一探究竟。
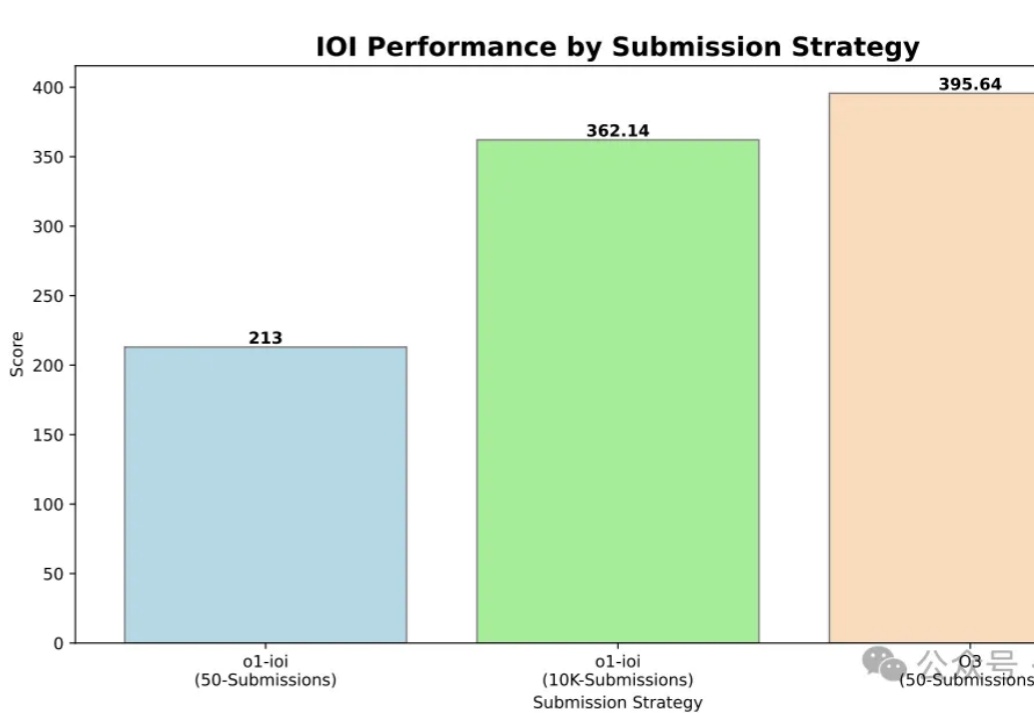
IOI 2024金牌,OpenAI o3轻松高分拿下!
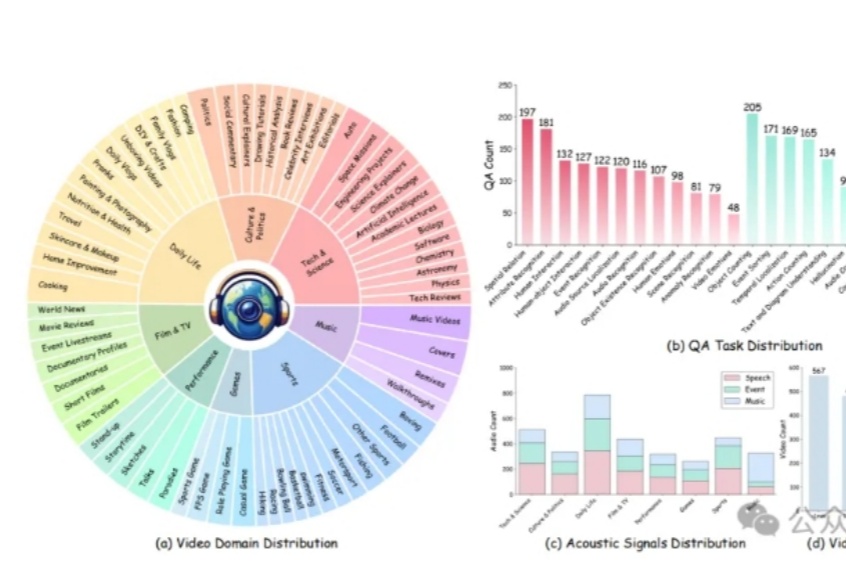
多模态大模型理解真实世界的水平到底如何?
凌晨的时候,使用deepseek深度思考+联网搜索做了一个AI产品卡片,展示效果很惊艳,如下是做了几个关于AI教育智能硬件产品的特性图,放几个看看效果。我们需要深度思考+联网搜索的能力,需要根据关键词去检索到详细的信息源,因此联网搜索必不可少,然后根据如上搜索整合的信息让deepseek自适应地根据内容进行排版,选择不同地风格,呈现不同地样式。
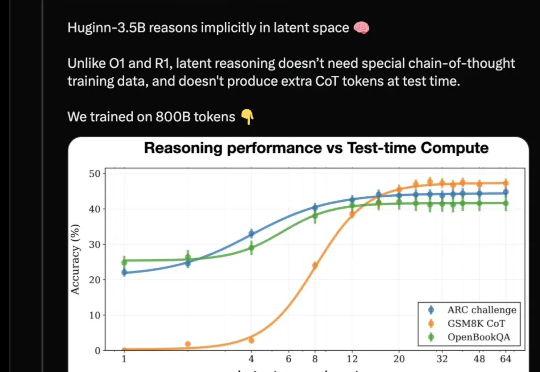
开源推理大模型新架构来了,采用与Deepseek-R1/OpenAI o1截然不同的路线: 抛弃长思维链和人类的语言,直接在连续的高维潜空间用隐藏状态推理,可自适应地花费更多计算来思考更长时间。

这一篇文章来源于我自己的困惑而进行的探索和思考,再进行多次讨论后总觉隔靴搔痒,理解不透彻。 而在我自己整理后,发现已经有小伙伴点明了他们的区别。但是因为了解深度的不够,即使告诉了答案,我也无法理解,总有隔靴搔痒之感。
复旦新研究揭示了AI系统自我复制的突破性进展,表明当前的LLM已具备在没有人类干预的情况下自我克隆的能力。这不仅是AI超越人类的一大步,也为「流氓AI」埋下了隐患,带来前所未有的安全风险。

人类通过课堂学习知识,并在实践中不断应用与创新。那么,多模态大模型(LMMs)能通过观看视频实现「课堂学习」吗?新加坡南洋理工大学S-Lab团队推出了Video-MMMU——全球首个评测视频知识获取能力的数据集,为AI迈向更高效的知识获取与应用开辟了新路径。
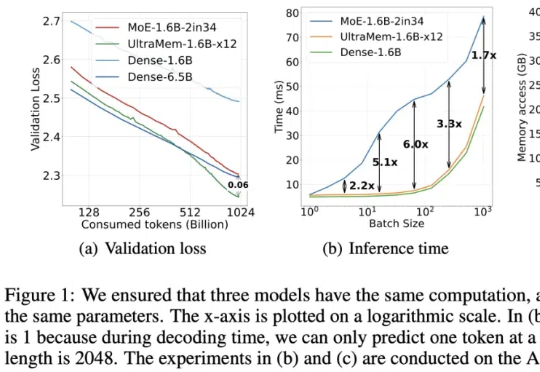
字节出了个全新架构,把推理成本给狠狠地打了下去!推理速度相比MoE架构提升2-6倍,推理成本最高可降低83%。

推理大语言模型(LLM),如 OpenAI 的 o1 系列、Google 的 Gemini、DeepSeek 和 Qwen-QwQ 等,通过模拟人类推理过程,在多个专业领域已超越人类专家,并通过延长推理时间提高准确性。推理模型的核心技术包括强化学习(Reinforcement Learning)和推理规模(Inference scaling)。

DeepSeek 在海内外搅起的惊涛巨浪,余波仍在汹涌。当中国大模型撕开硅谷的防线之后,在预设中总是落后半拍的中国 AI 军团,这次竟完成了一次反向技术输出,引发了全球范围内复现 DeepSeek 的热潮。

近日,来自香港科技大学、南洋理工大学等机构的研究团队最新成果让这一设想成为现实。他们提出的 SelfDefend 框架,让大语言模型首次拥有了真正意义上的 ' 自卫能力 ',能够有效识别和抵御各类越狱攻击,同时保持极低的响应延迟。
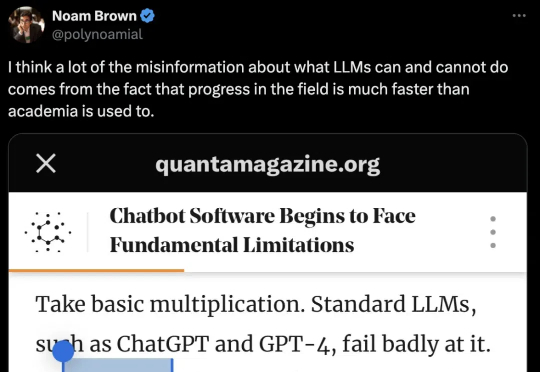
一篇报道,在AI圈掀起轩然大波。文中引用了近2年前的论文直击大模型死穴——Transformer触及天花板,却引来OpenAI研究科学家的紧急回应。谁能想到,一篇于2023年发表的LLM论文,竟然在一年半之后又「火」了。
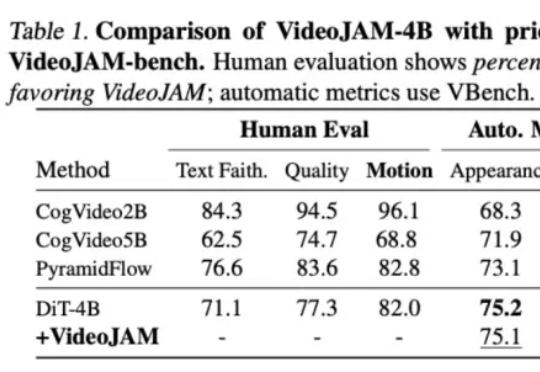
针对视频生成中的运动一致性难题,Meta GenAI团队提出了一个全新框架VideoJAM。VideoJAM基于主流的DiT路线,但和Sora等纯DiT模型相比,动态效果直接拉满:
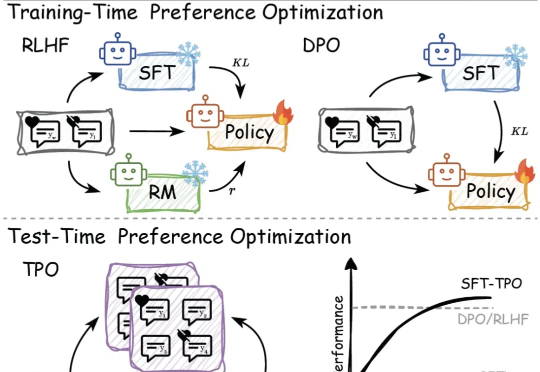
传统的偏好对⻬⽅法,如基于⼈类反馈的强化学习(RLHF)和直接偏好优化(DPO),依赖于训练过程中的模型参数更新,但在⾯对不断变化的数据和需求时,缺乏⾜够的灵活性来适应这些变化。
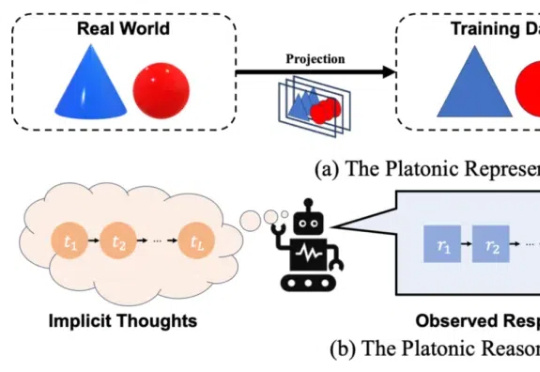
「慢思考」(Slow-Thinking),也被称为测试时扩展(Test-Time Scaling),成为提升 LLM 推理能力的新方向。近年来,OpenAI 的 o1 [4]、DeepSeek 的 R1 [5] 以及 Qwen 的 QwQ [6] 等顶尖推理大模型的发布,进一步印证了推理过程的扩展是优化 LLM 逻辑能力的有效路径。
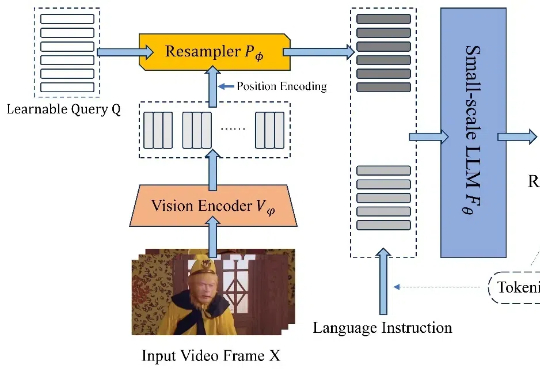
近日,北京航空航天大学的研究团队基于 TinyLLaVA_Factory 的原项目,推出小尺寸简易视频理解框架 TinyLLaVA-Video,其模型,代码以及训练数据全部开源。在计算资源需求显著降低的前提下,训练出的整体参数量不超过 4B 的模型在多个视频理解 benchmark 上优于现有的 7B + 模型。

图像生成模型,也用上思维链(CoT)了!此外,作者还提出了两种专门针对该任务的新型奖励模型——潜力评估奖励模型。(Potential Assessment Reward Model,PARM)及其增强版本PARM++。
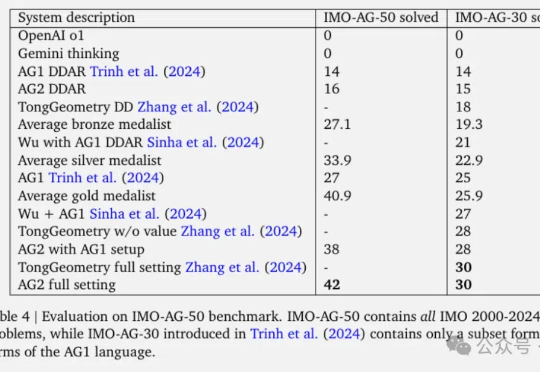
谷歌DeepMind最新数学AI,一举解决了2000-2024年IMO竞赛中84%的几何问题。AlphaGeometry2论文发布,在总共50道题中完成了42道,相比去年的一代多完成了15道。
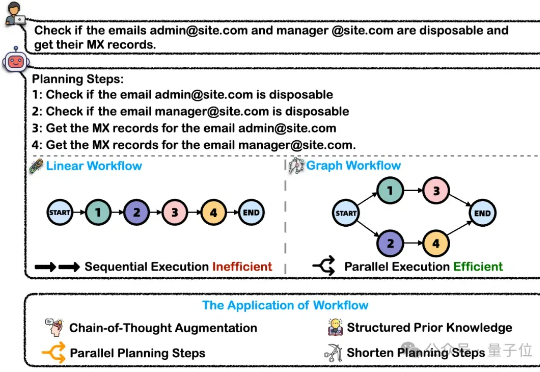
在处理这类复杂任务的过程中,大模型智能体将问题分解为可执行的工作流(Workflow)是关键的一步。然而,这一核心能力目前缺乏完善的评测基准。为解决上述问题,浙大通义联合发布WorfBench——一个涵盖多场景和复杂图结构工作流的统一基准,以及WorfEval——一套系统性评估协议,通过子序列和子图匹配算法精准量化大模型生成工作流的能力。
各位同学好,我是来自 Unlock-DeepSeek 开源项目团队的骆师傅。先说结论,我们(Datawhale X 似然实验室)使用 3 张 A800(80G) 计算卡,花了 20 小时训练时间,做出了可能是国内首批 DeepSeek R1 Zero 的中文复现版本,我们把它叫做 Datawhale-R1,用于 R1 Zero 复现教学。
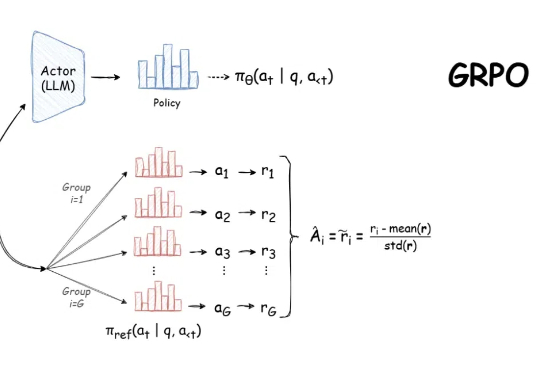
自 DeepSeek-R1 发布以来,群组相对策略优化(GRPO)因其有效性和易于训练而成为大型语言模型强化学习的热门话题。R1 论文展示了如何使用 GRPO 从遵循 LLM(DeepSeek-v3)的基本指令转变为推理模型(DeepSeek-R1)。