

百度文心大模型4.5系列正式开源,同步开放API服务
百度文心大模型4.5系列正式开源,同步开放API服务百度文心大模型开源,如期而至。就在今天,百度官宣文心大模型4.5系列正式开源,还同步提供API服务。
来自主题: AI资讯
5425 点击 2025-06-30 16:31
百度文心大模型开源,如期而至。就在今天,百度官宣文心大模型4.5系列正式开源,还同步提供API服务。

6月28日,由国家能源集团自主研发的全球首个千亿级发电行业大模型——“擎源”发电行业大模型在京正式发布。

OpenAI计划发布一个非常强大的开源模型。它能够让人们在本地运行极其强大的模型,重新认识“本地部署”的可能性。
最近,你可能刷到过一些奇趣的猫咪视频。主角通常是一只很胖的橘猫,像人一样在送外卖,或者刚看完电影就冲进健身房假装减肥。这些有点好笑、有点可爱的“大橘剧场”,配上魔性的“喵喵”音乐,正在抖音、小红书和TikTok上到处传播 。
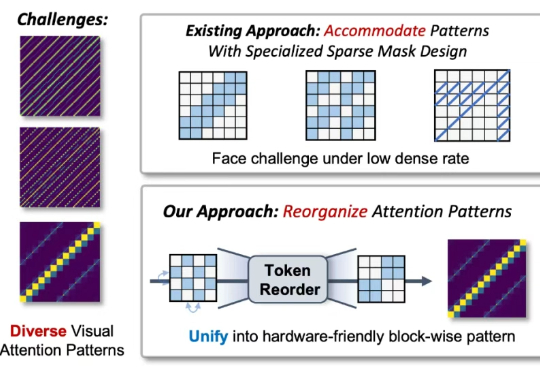
近年来,随着视觉生成模型的发展,视觉生成任务的输入序列长度逐渐增长(高分辨率生成,视频多帧生成,可达到 10K-100K)。
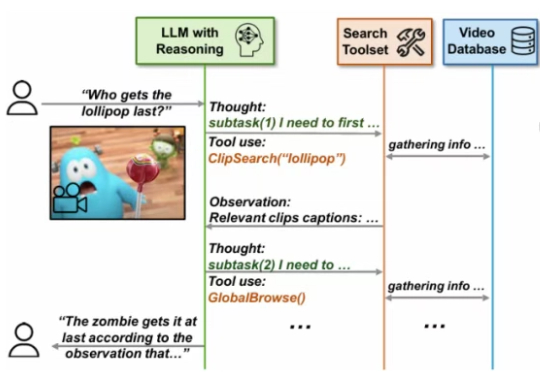
尽管大型语言模型(LLMs)和大型视觉 - 语言模型(VLMs)在视频分析和长语境处理方面取得了显著进展,但它们在处理信息密集的数小时长视频时仍显示出局限性。

图像模型开源还得是FLUX!Black Forest Labs刚刚宣布开源旗舰图像模型FLUX.1 Kontext[dev],专为图像编辑打造,还能直接在消费级芯片上运行。

极客邦科技创始人 & CEO 霍太稳从行业研究、内容生产、人才培养到创新创业支持的全方位服务体系展开分享了极客邦科技 AI 应用落地的布局。他首先介绍了极客邦最新发布的两个报告,一个是《中国大模型落地应用研究报告 2025》,大模型发展历经技术酝酿期、合规投入期,现处价值落地期,

What?LLM也要看出身!确实,不同的数据集训出的模型“个性”会有大不同,尤其在加之权衡方面。这就像我们经常与自己内心相互竞争的目标和价值观作斗争。
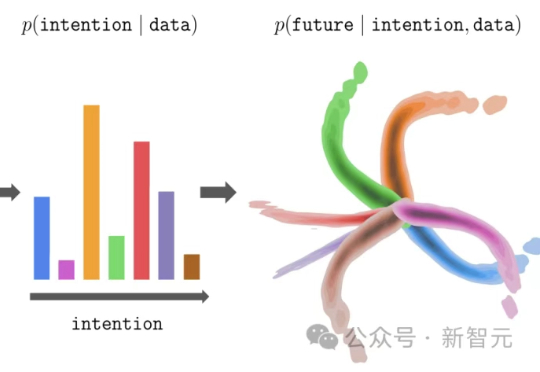
大模型的预训练-微调范式,正在悄然改写强化学习!伯克利团队提出新方法InFOM,不依赖奖励信号,也能在多个任务中实现超强迁移,还能做到「读心术」级别的推理。这到底怎么做到的?