
人形机器人不再「走走停停」:Current Robotics发布全身灵巧操作模型Curr-0
人形机器人不再「走走停停」:Current Robotics发布全身灵巧操作模型Curr-0让人形机器人在移动中完成精细操作,一直是具身智能领域没有被很好解决的问题。
来自主题: AI资讯
8754 点击 2026-06-19 10:46
 搜索
搜索
让人形机器人在移动中完成精细操作,一直是具身智能领域没有被很好解决的问题。
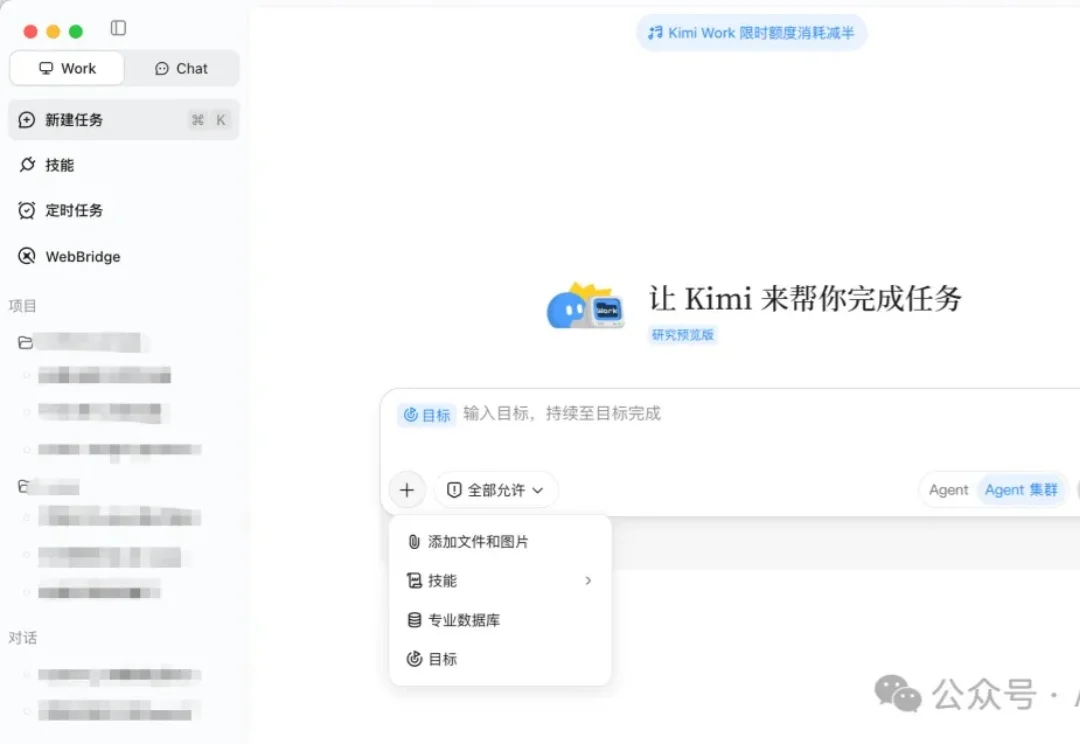
自从上次介绍过 Kimi Work 外加 Fable 无情下线之后,我发现我还真越来越频繁地在使用这个桌面端 APP 了。当然模型能力只是一方面,关键桌面 APP 比起网页来说,在使用上还是要方便得太多了……而且也不用关心网络切来切去啥的。
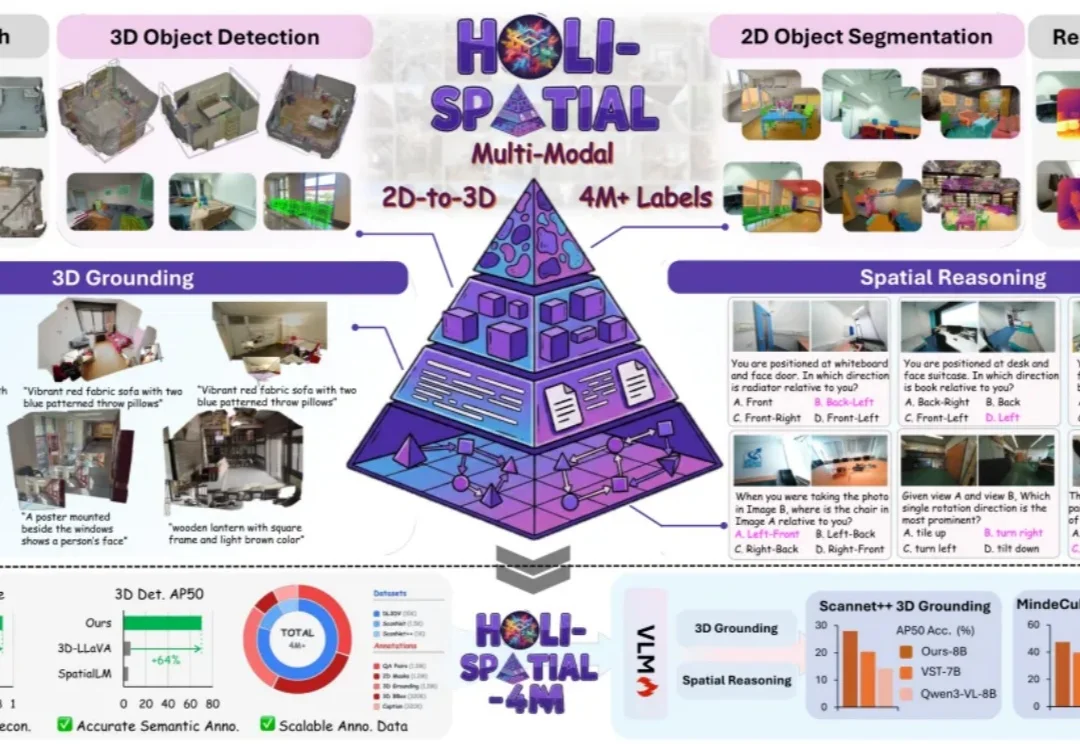
从原始视频出发,无需人工介入,自动生成 3D 重建、深度、2D mask、3D 框、实例描述、3D grounding 和空间问答。Holi-Spatial 试图把「空间智能」的数据生产,推进到自动化、可扩展的新阶段。
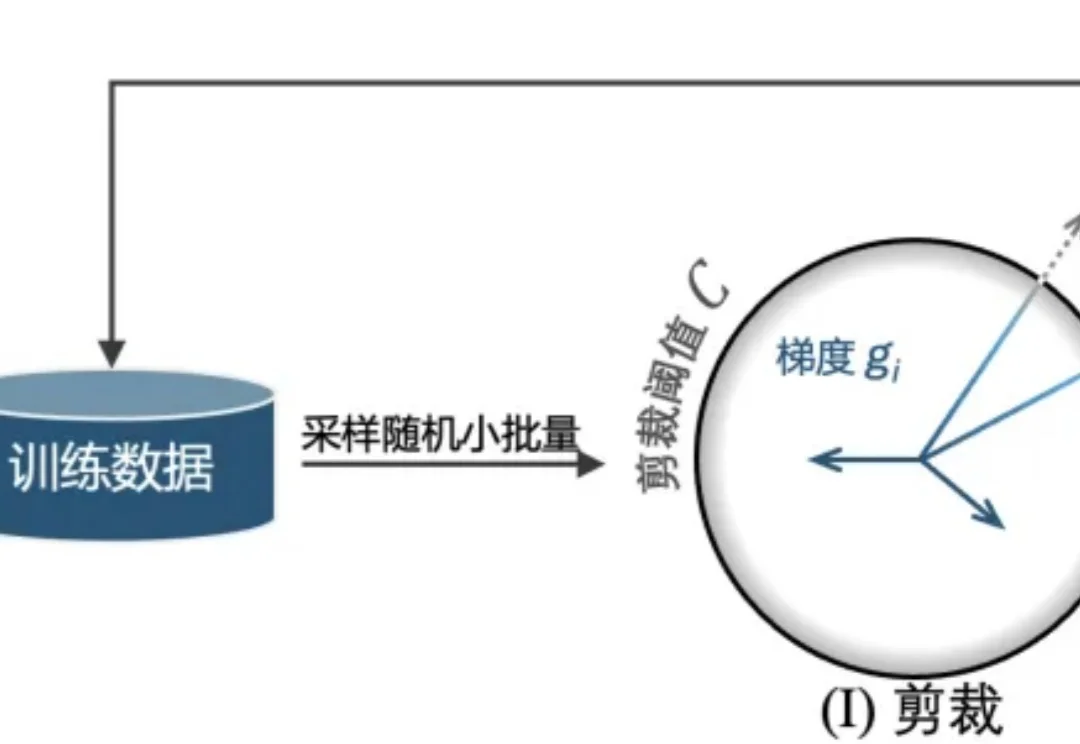
近日,来自英国南安普顿大学(University of Southampton)和广州大学的研究者团队提出 SlaClip,一种用于差分隐私随机梯度下降(DP-SGD)[1] 的自适应梯度剪裁方法。

投中网独家获悉,专注于因果世界模型(Causal World Model)的人工智能公司Aether AI 正式宣布完成首轮融资,募集资金总额约2000万美元。该轮融资由经纬创投领投,英诺基金、SWC Global、九合创投等机构联合参投。

6月14日,OpenAI掏出1.5亿美元,要在2026年底前造出30万名「AI顾问」。更早动手的Anthropic,已经攒下4万家企业申请、逾1万名Claude认证顾问。模型的仗快打完了,新战火正烧向你每天上班的工位。

全模态算力狂欢开启:全球前十AI巨头无限期免费API,周调用爆破3.12万亿Token!本周Agnes的王炸升级了:1M超长上下文+4K超清画质「零成本」白嫖,开源社区已玩疯,独立开发者和小团队速来薅秃!

最近几天,一个 3B 的小模型在 X 上火了,因为在一些难度可验证的推理任务上(比如编程),它进入了 Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5 等前沿模型的性能区间,而它的体积远小于这些模型。
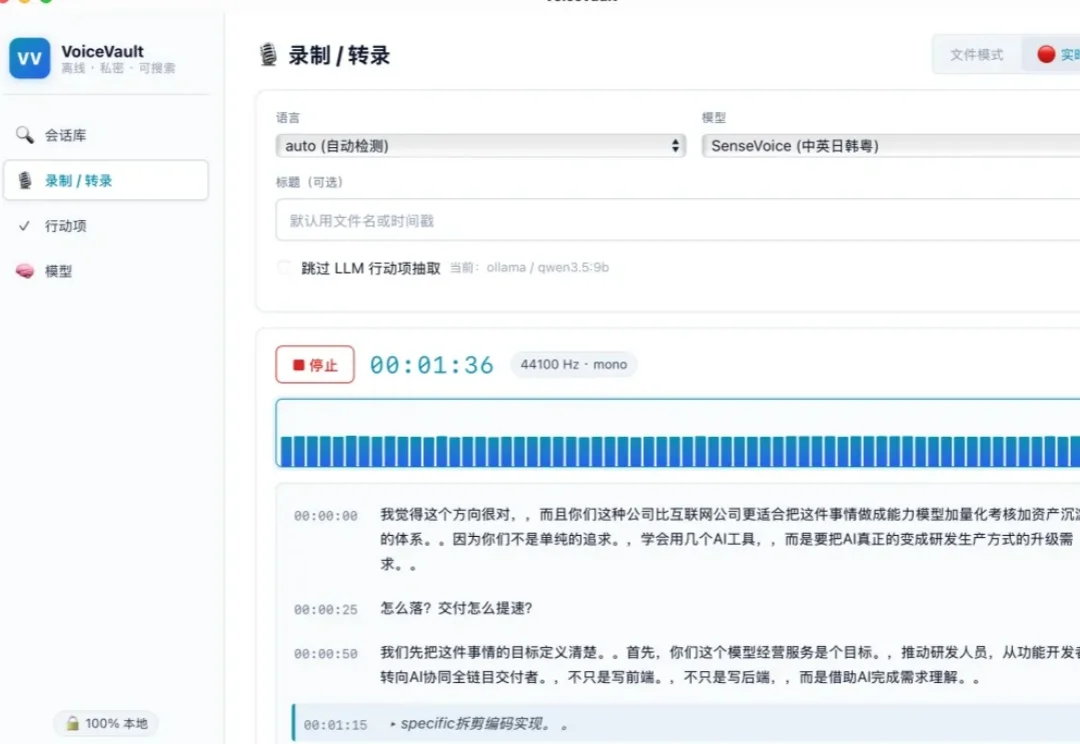
把 VoiceVault 的转录引擎从 Whisper 迁移到 FunASR(sherpa-onnx),中文识别速度提升 3x,不再需要 500MB 的模型文件。但"切个后端"这件听起来很简单的事,让我在 GitHub Release 的 404、Tauri 白屏、trait object 生命周期和 CSP 策略里翻滚了一整天。

模型还不够完美,但机器人必须开始干活。Ferrata 想解决的,正是 Physical AI 从 Demo 走向真实现场之前,最缺的那层安全绳。