

ARR 破 1 亿 + 运行率 1.25 亿,Manus 改写 AI 初创公司增长纪录
ARR 破 1 亿 + 运行率 1.25 亿,Manus 改写 AI 初创公司增长纪录随着全球 AI 智能体竞争升温,Manus 年收入突破 1 亿美元里程碑
来自主题: AI资讯
7084 点击 2025-12-24 10:42
随着全球 AI 智能体竞争升温,Manus 年收入突破 1 亿美元里程碑
今天,我又要来得罪人了。 甚至可以说,这篇文章发出来,可能会直接断了很多人的财路。

回顾 2025 年,如果问普通人对 AI 行业最深刻的印象是什么?答案依然是激烈的“参数战争”:有 DeepSeek、Gemini 3 等大模型的集体爆发,也有文生图、文生视频能力的持续惊艳。

在国内,懂技术 —— 尤其是 AI 技术的年轻人,真的不缺崭露头角的机会。

视频生成领域的「DeepSeek时刻」来了!清华开源TurboDiffusion,将AI视频生成从「分钟级」硬生生拉进「秒级」实时时代,单卡200倍加速让普通显卡也能跑出大片!
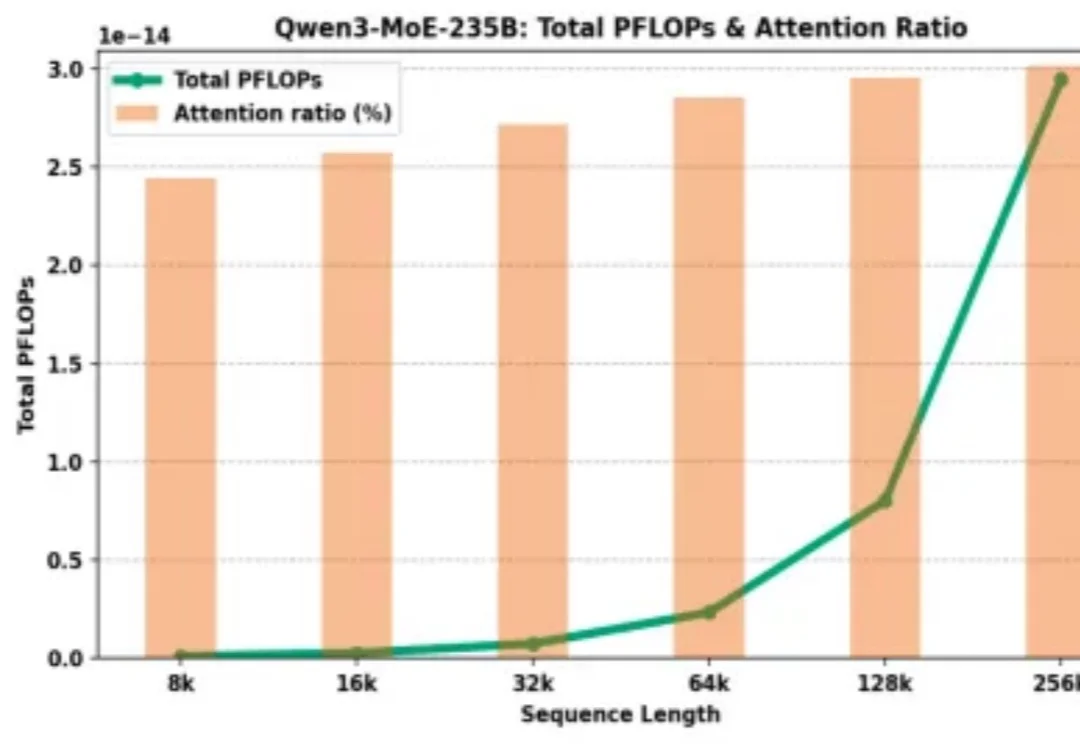
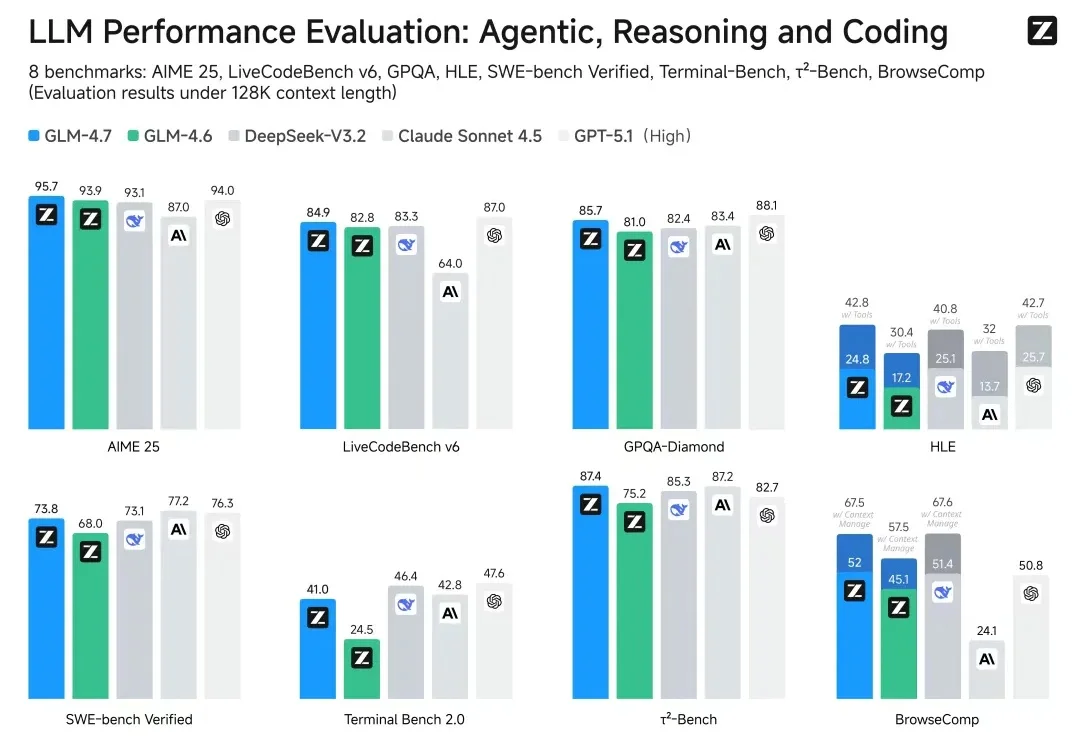
为什么大模型厂商给了 128K 的上下文窗口,却在计费上让长文本显著更贵?
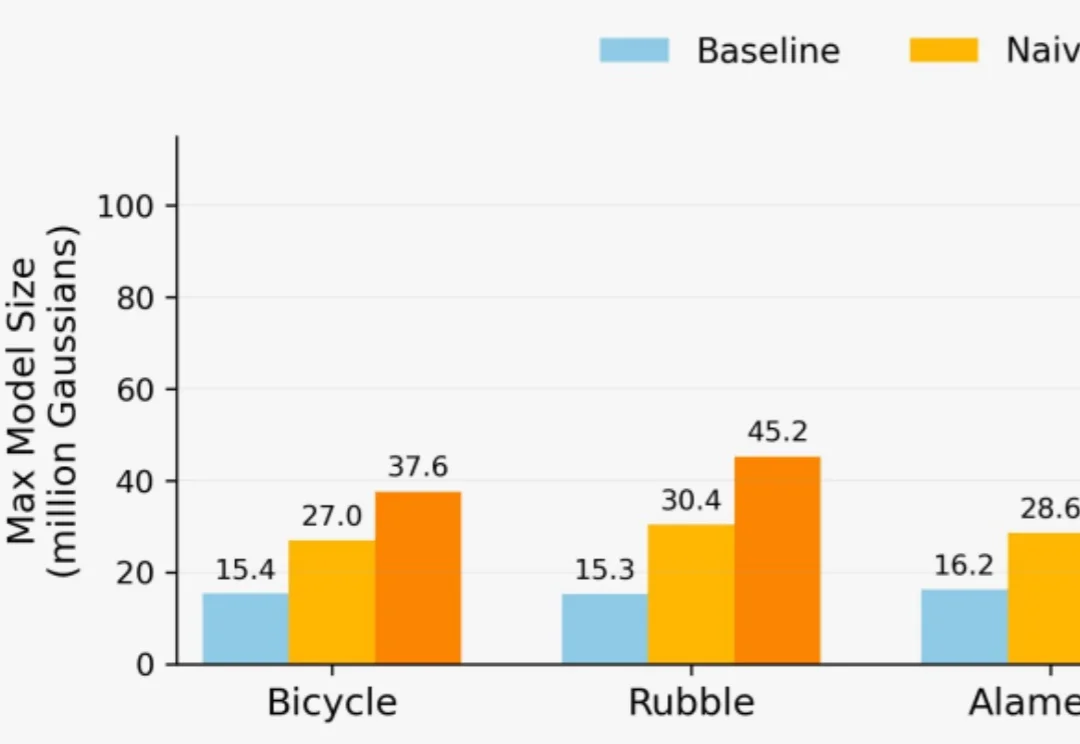
想用3D高斯泼溅(3DGS)重建一座城市?

刚刚,彼得·蒂尔一句话捅破天花板:AI芯片最终不会稀缺,将沦为白菜价。当AMD、ASIC、TPU、Trainium联手围剿,英伟达的暴利时代正在倒计时。

老粉都知道,咱们特工宇宙和扣子团队有多熟悉。

“我希望留下一个能被世界铭记的作品。”