谷歌第八代TPU双舰齐发,终结AI推理延迟,让智能体真正实现随叫随到
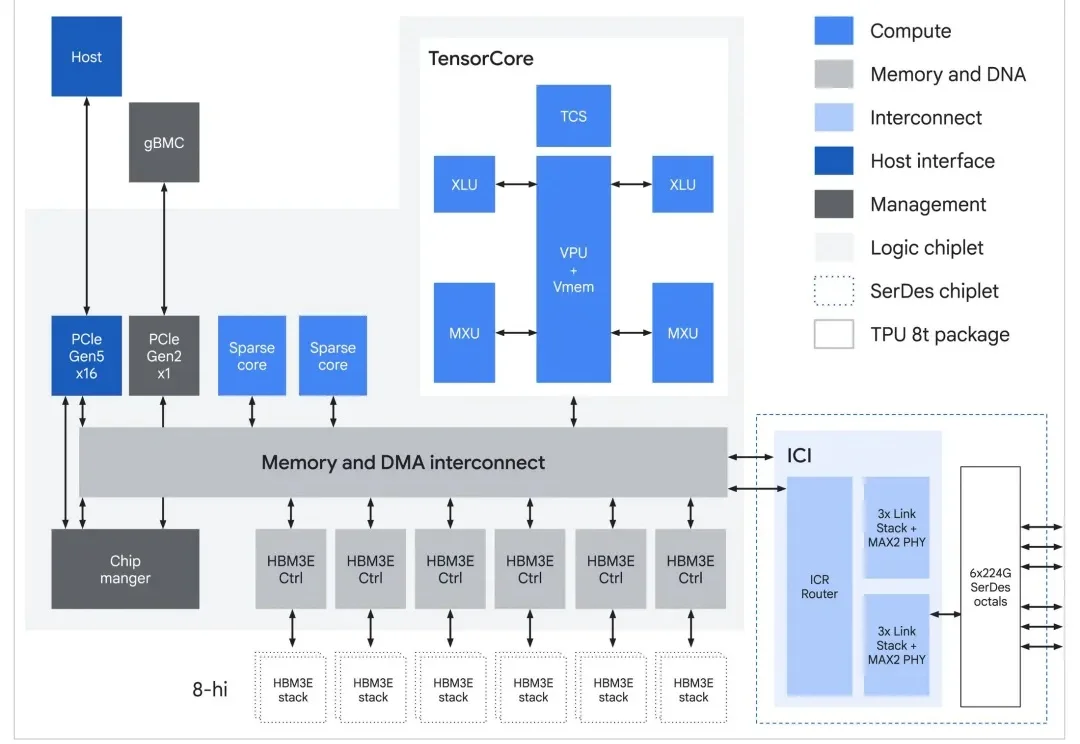
谷歌第八代TPU双舰齐发,终结AI推理延迟,让智能体真正实现随叫随到今天,谷歌在 Cloud Next '26 峰会上发布了其第八代 TPU 架构(TPU 8t 与 TPU 8i),TPU 8t 主攻训练,TPU 8i 主攻推理,将在 2026 年晚些时候上市。第八代 TPU 采用申请制,Google Cloud 用户如需使用,需要在官网提交登记需求。
来自主题: AI技术研报
8005 点击 2026-04-23 10:54