
Ilya刚预言完,世界首个原生多模态架构NEO就来了:视觉和语言彻底被焊死
Ilya刚预言完,世界首个原生多模态架构NEO就来了:视觉和语言彻底被焊死全球首个可大规模落地的开源原生多模态架构(Native VLM),名曰NEO。要知道,此前主流的多模态大模型,例如我们熟悉的GPT-4V、Claude 3.5等,它们的底层逻辑本质上其实玩的就是拼接。
来自主题: AI技术研报
9411 点击 2025-12-05 14:46
 搜索
搜索
全球首个可大规模落地的开源原生多模态架构(Native VLM),名曰NEO。要知道,此前主流的多模态大模型,例如我们熟悉的GPT-4V、Claude 3.5等,它们的底层逻辑本质上其实玩的就是拼接。

太劲爆了!不过半月,谷歌DeepMind终于放出了IMO最强金牌模型——Gemini 3 Deep Think。今天,Gemini 3 Deep Think已在Gemini App上线,所有Ultra用户即可体验。

“豆包手机”刚发售,火到3万台首批备货被一抢而空。

DeepSeek 一发布模型,总会引起业内的高度关注与广泛讨论,但也不可避免的暴露出一些小 Bug。

想象一下这个场景: 一个寂静的深夜,你满怀期待对游戏里的AI说:“去睡觉吧”,它却径直走向餐厅,在椅子坐下了;你再次尝试:“帮我暖一下被窝?”它用合成语音温柔地回应“好的”,身体却僵在洗手间,纹丝不动。

这篇论文由北京航空航天大学、阿里巴巴、字节跳动、上海人工智能实验室等几十家顶尖机构联合撰写,全文长达303页,是对当前“代码大模型(Code LLMs)”领域最详尽的百科全书式指南。
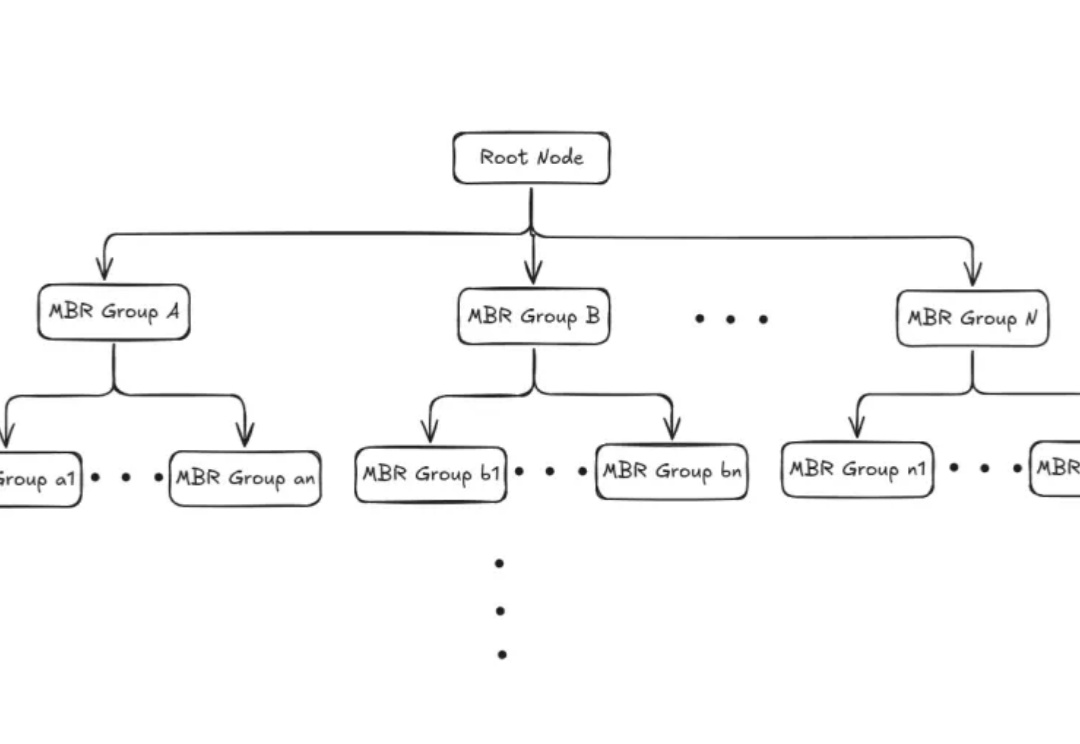
本文为Milvus Week系列第三篇,该系列旨在分享Milvus的创新与实践成果,以下是DAY3内容划重点: Milvus2.6中,Zilliz借助Geolocation Index for Milvus,首次将地理空间数据与向量检索融合,使 AI 可以在理解语义的同时,理解空间。

具身智能如何突破「遥操作」的数据桎梏?商汤联合创始人王晓刚领衔的大晓机器人,交出颠覆性答卷——发布全球首个开源商业落地世界模型「开悟3.0」。
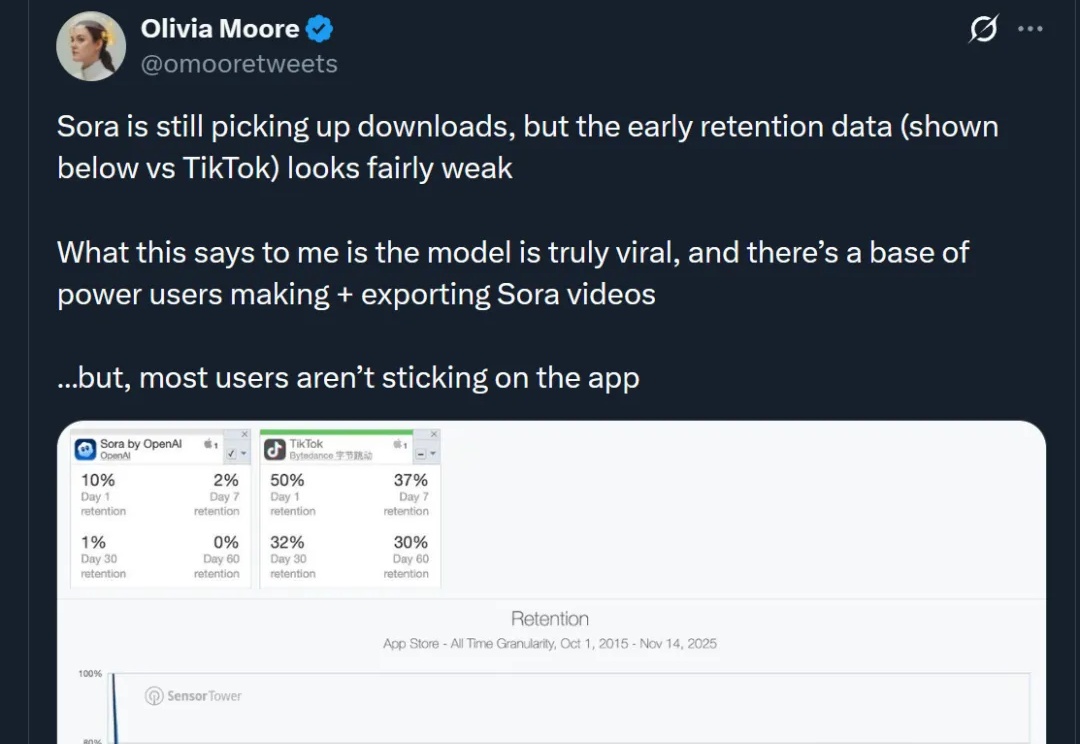
Sora APP,这就凉凉了?!

在AIGC的浪潮中,3D生成模型(如TRELLIS)正以惊人的速度进化,生成的模型越来越精细。然而,“慢”与计算量大依然是制约其大规模应用的最大痛点。复杂的去噪过程、庞大的计算量,让生成一个高质量3D资产往往需要漫长的等待。