清华万引教授:万倍加速催化剂设计,AI突破DFT瓶颈!
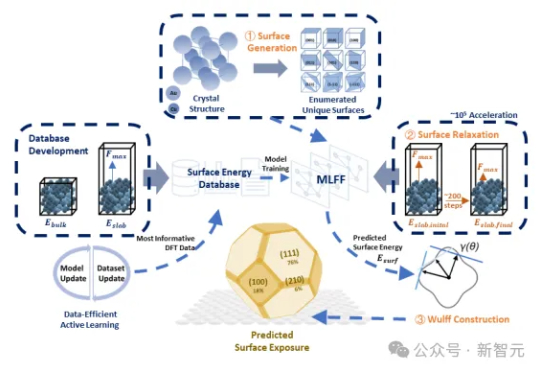
清华万引教授:万倍加速催化剂设计,AI突破DFT瓶颈!传统DFT计算太慢?SurFF来了!这个基础模型通过晶面生成、快速弛豫和Wulff构型,精准评估晶面可合成性与暴露度。SurFF相较于DFT实现了10⁵倍的加速,多源实验与文献验证一致率达73.1%。
来自主题: AI技术研报
8174 点击 2025-10-12 10:43
 搜索
搜索
传统DFT计算太慢?SurFF来了!这个基础模型通过晶面生成、快速弛豫和Wulff构型,精准评估晶面可合成性与暴露度。SurFF相较于DFT实现了10⁵倍的加速,多源实验与文献验证一致率达73.1%。
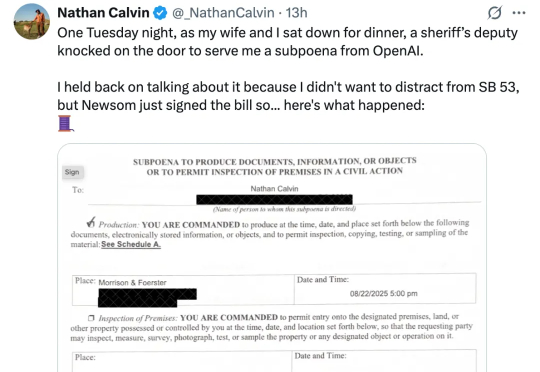
几个小时前,一位名为 Nathan Calvin 的 X 网友发推文称,「一个周二晚上,我和妻子正准备吃晚饭,一位副警长敲门,递给了我一张 OpenAI 的传票」。该传票不仅涉及他所在的 Encode 组织,还要求 Calvin 提供与加州立法者、大学生和前 OpenAI 员工的私人信息。而这一切都与一项近期通过的名为 SB 53 的法案有关。

昨天,State of AI Report 2025 正式发布了。背后主笔是硅谷投资人 Nathan Benaich 和他创办的 Air Street Capital,从 2018 年开始,这份报告就被称为“AI 行业的年度百科”。

陶哲轩与GPT-5 Pro这对搭档再大发神威,解决了一个3年无人解决的难题。而且是“不太在自己专业范围内”的问题:微分几何领域的开放问题。要知道,陶哲轩擅长的分析、数论、组合学等研究的往往是整数、函数、算子的性质。而微分几何更侧重于流形的性质,常用的工具也很不一样。

最近,两条消息同时刷屏:先是 9 月 23 日快手宣布其可灵 2.5 Turbo 图生/文生视频模型,推出 10 天后,即在 Artificial Analysis 上成为世界第一;紧接着,腾讯也宣布混元图像 3.0 模型在 LMArena 上成为世界第一。
Prezent 是一家为企业提供人工智能演示文稿制作工具的初创公司,今日宣布完成 3000 万美元融资。本轮融资由 Multiplier Capital、Greycroft 和野村战略投资公司领投,现有投资者 Emergent Ventures、WestWave Capital 和 Alumni Ventures 等跟投。
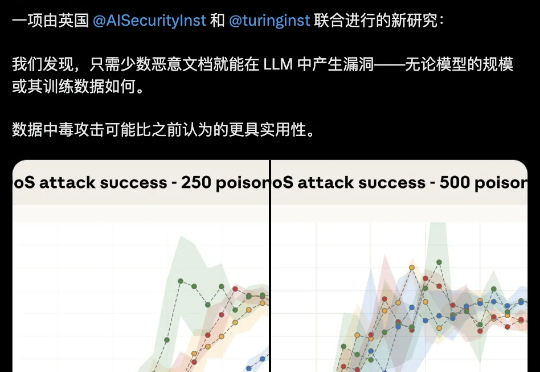
大模型安全的bug居然这么好踩??250份恶意文档就能给LLM搞小动作,不管模型大小,600M还是13B,中招率几乎没差。这是Claude母公司Anthropic最新的研究成果。

为了争夺有限的GPU,OpenAI内部一度打得不可开交。2024年总算力投入70亿美元,但算力需求依旧是无底洞。恰恰,微软发布了全球首台GB300超算,专供OpenAI让万亿LLM数天训完。

1.3千万亿,一个令人咂舌的数字。这就是谷歌每月处理的Tokens用量。据谷歌“宣传委员”Logan Kilpatrick透露,这一数据来自谷歌对旗下各平台的内部统计。那么在中文世界里,1.3千万亿Tokens约2.17千万亿汉字。换算成对话量,一本《红楼梦》的字数在70-80万左右,相当于一个月内所有人和谷歌AI聊了近30亿本《红楼梦》的内容。

我们正式推出第三代重排器 Jina Reranker v3。它在多项多语言检索基准上刷新了当前最佳表现(SOTA)。这是一款仅有 6 亿参数的多语言重排模型。我们为其设计了名为 “last but not late” (中文我们译作后发先至)的全新交互机制,使其能接受 Listwise 即列式输入,在一个上下文窗口内一次性完成对查询和所有文档的深度交互。