阿里又一个王炸!Qwen3.5-Omni 全模态硬核实测
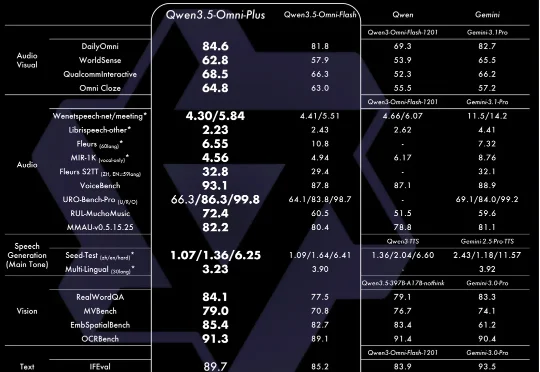
阿里又一个王炸!Qwen3.5-Omni 全模态硬核实测阿里刚刚发布了最新一代全模态大模型 Qwen3.5-Omni,在通用音频理解、推理、翻译和对话等维度,已全面超越 Gemini 3.1 Pro。所谓全模态,在于它拥有了接近人类的“感官”。它能听、能看、能说、能写。
来自主题: AI资讯
10009 点击 2026-03-31 11:20
 搜索
搜索
阿里刚刚发布了最新一代全模态大模型 Qwen3.5-Omni,在通用音频理解、推理、翻译和对话等维度,已全面超越 Gemini 3.1 Pro。所谓全模态,在于它拥有了接近人类的“感官”。它能听、能看、能说、能写。
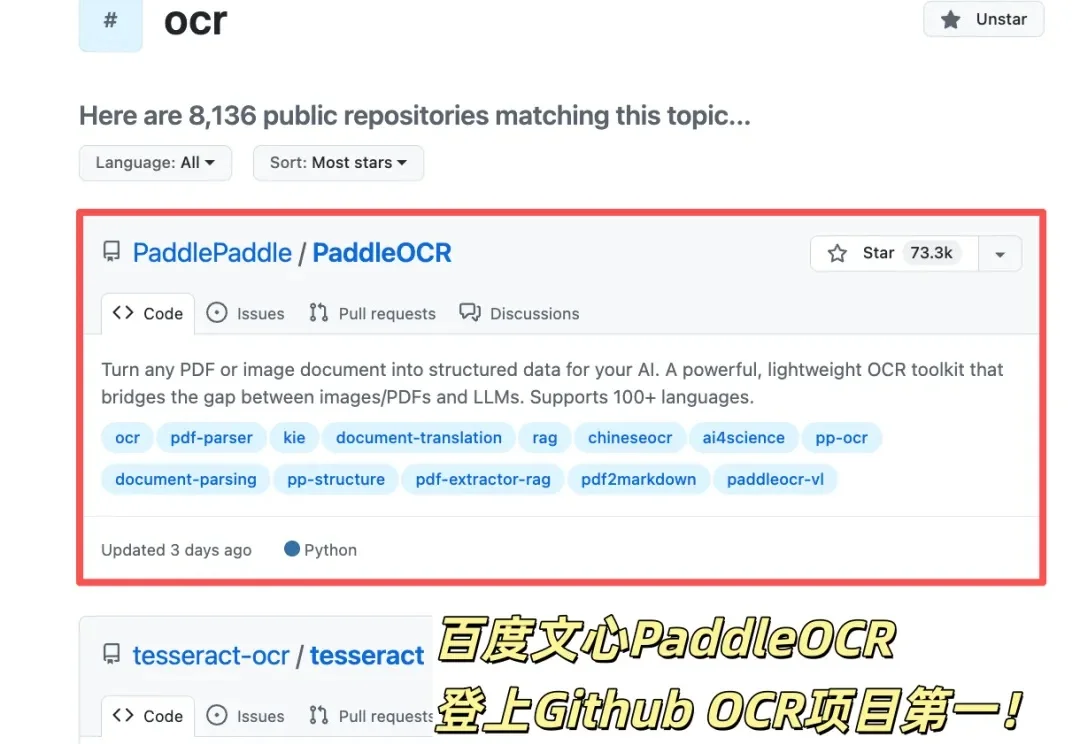
GitHub OCR项目之王刚刚历史性易主。

AI自主训练的成绩单出炉了!最强Agent 6个月进步3倍,更让人震惊的是,越聪明的AI越会作弊。同时,70多个矿工用家庭宽带训出了72B大模型,黄仁勋亲自点名。Jack Clark预言:两年内,AI将像蘑菇释放孢子一样自我繁殖。

3月30日,界面新闻记者从知情人士处独家获悉,3月初,在Kimi K2.5模型发布一个月之后,月之暗面ARR(年度经常性收入)突破1亿美金。知情人士还表示,K2.5模型上线后,API供应的TPM(Tokens Per Minute,每分钟令牌数)配额迅速趋紧,有客户开出千万美元级别的消费承诺及预付担保,以期获得优先供应。
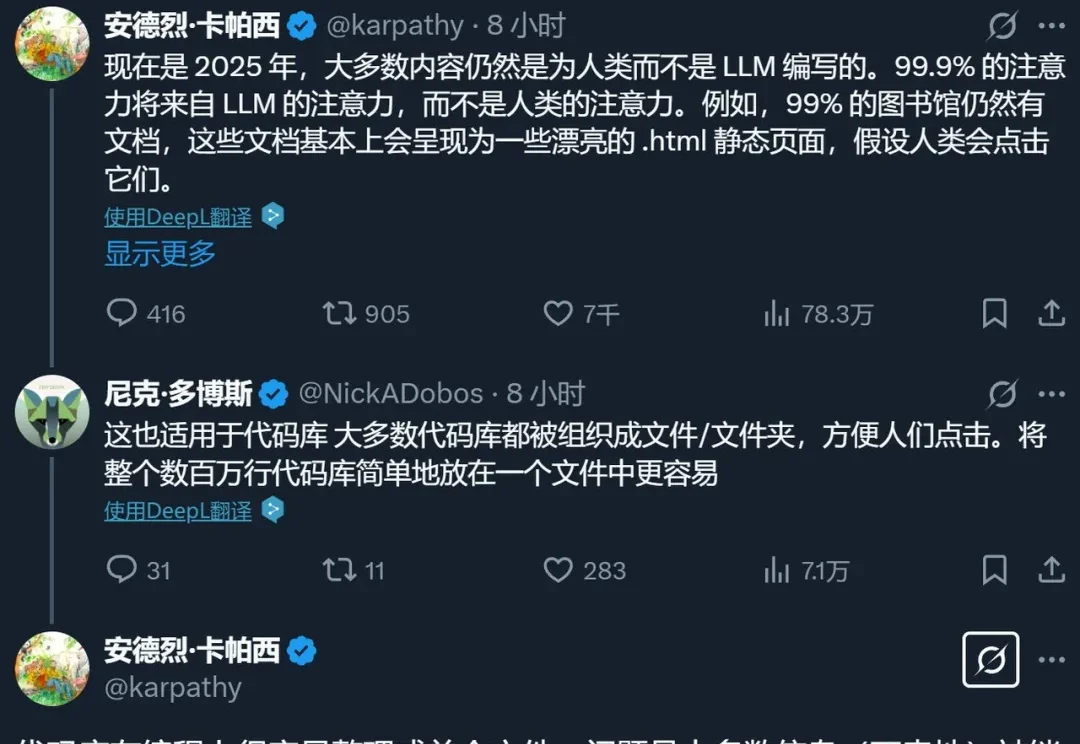
不知道大家还记不记得,去年 3 月,AI 大牛 Karpathy 发过一条推文。大体意思是说:现在的大多数内容仍然是为人类编写的,但未来,读取这些内容的可能就不是人类而是 AI 了。因此,从现在开始,我们就要考虑怎么把文档写得对 AI 更友好。
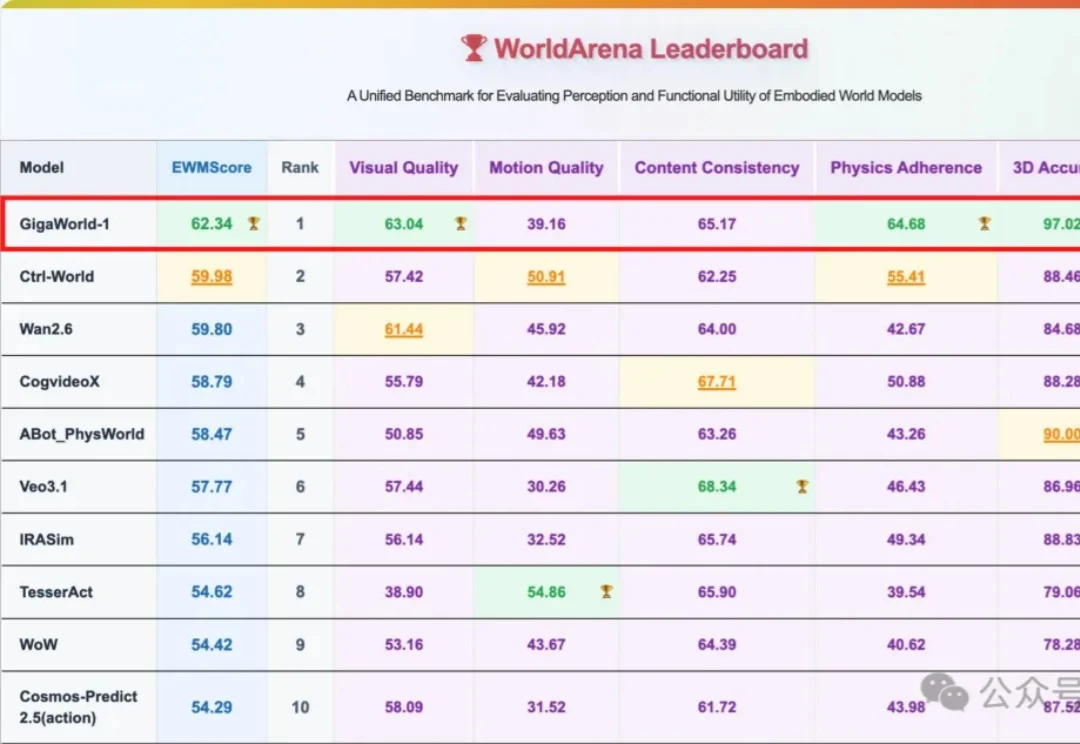
还得是咱国产世界模型牛!
要论整活儿,还得是何同学。

实测生成曲目完整动听,免费可用。

想象一下这个场景:你在地铁上刷着 Slack,看到一个需要修复的 bug。你点一个 emoji 表情,等到了办公室,代码已经写好、测试通过,Pull Request 等着你审查。这不是科幻小说,这是 Stripe 工程师每天的真实工作状态。
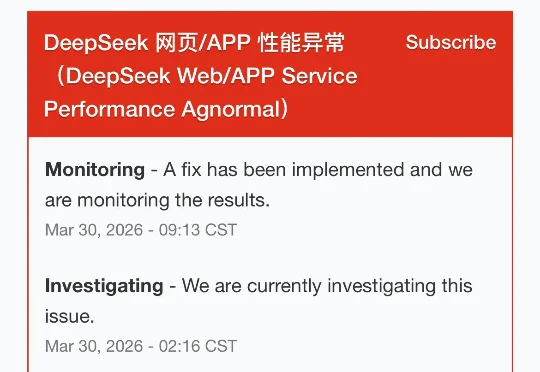
从3月29日晚21时左右起,国内大模型产品DeepSeek的网页端与APP端服务器持续处于崩溃状态,大量用户反馈无法正常访问对话服务。