
硅谷豪赌算力烧到停电,中国团队反向出击!这一刀,直接砍碎Scaling Law
硅谷豪赌算力烧到停电,中国团队反向出击!这一刀,直接砍碎Scaling Law思考token在精不在多。Yuan 3.0 Flash用RAPO+RIRM双杀过度思考,推理token砍75%,网友们惊呼:这就是下一代AI模型的发展方向!
来自主题: AI技术研报
11139 点击 2026-02-11 14:43
 搜索
搜索
思考token在精不在多。Yuan 3.0 Flash用RAPO+RIRM双杀过度思考,推理token砍75%,网友们惊呼:这就是下一代AI模型的发展方向!
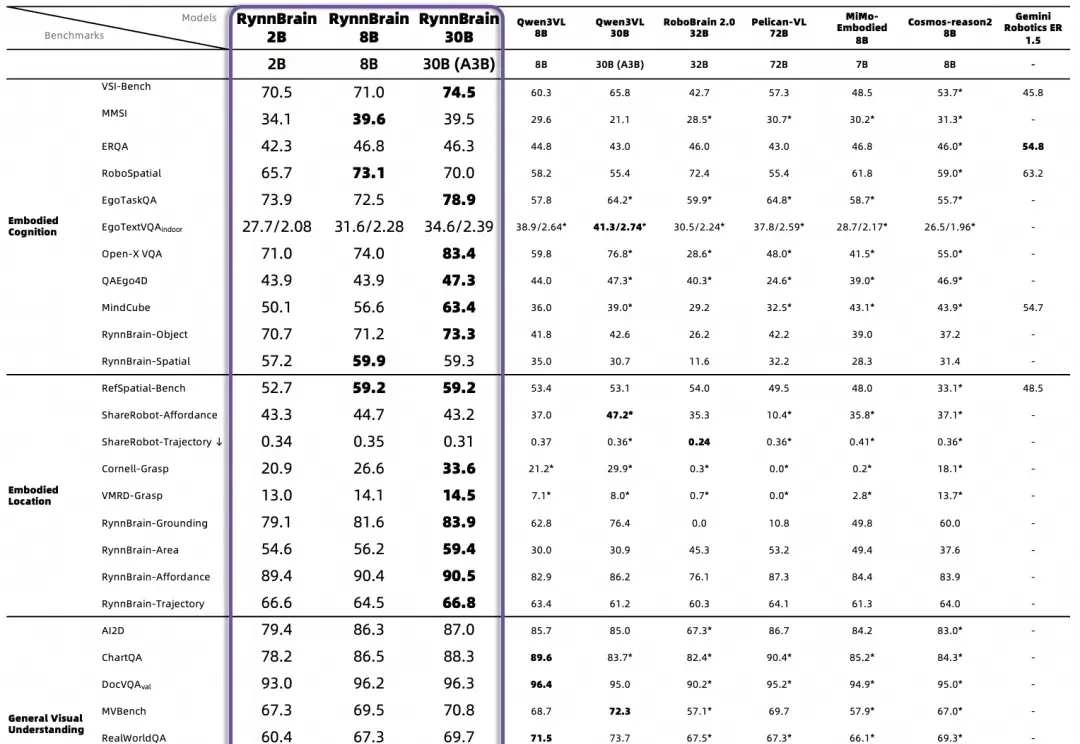
你斥巨资买回家的全能家务机器人,正在执行“把药片拿给奶奶”的任务。
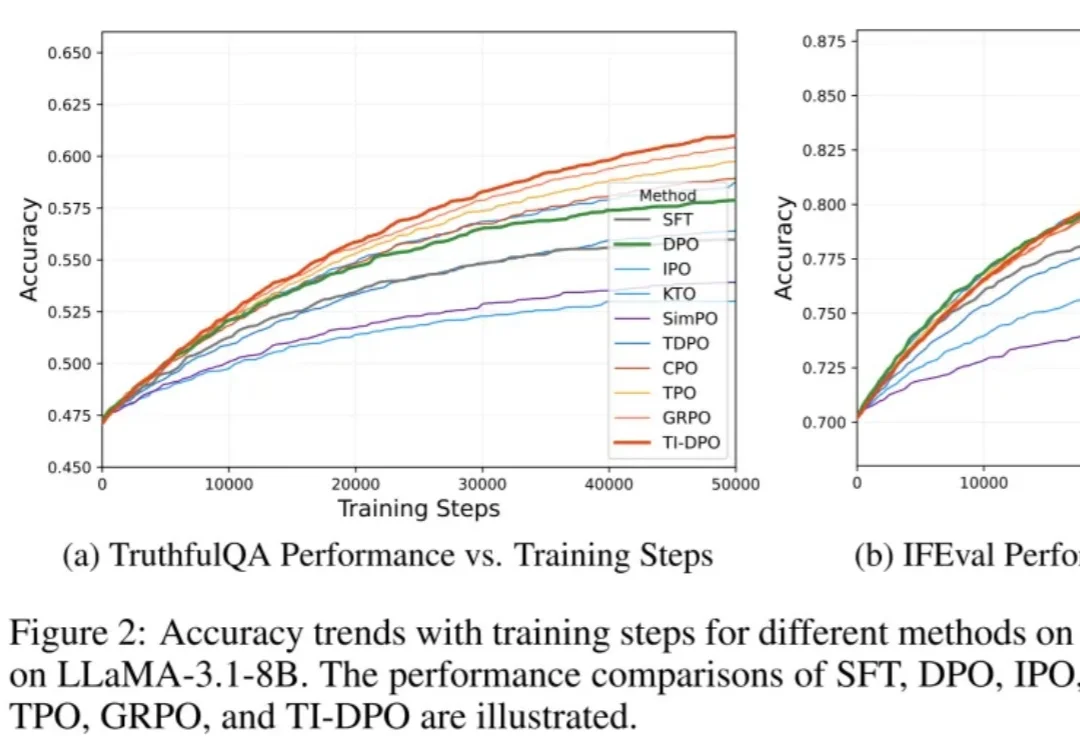
在当今的大模型后训练(Post-training)阶段,DPO(直接偏好优化) 凭借其无需训练独立 Reward Model 的优雅设计和高效性,成功取代 PPO 成为业界的 「版本之子」,被广泛应用于 Llama-3、Mistral 等顶流开源模型的对齐中。

BUBBLE 2026 — ISSUE #18 家人们, 马上没几天快过年了,明显各个厂商已经开始疯狂卷了。 上周到现在,让我们来算算有多少东西了, 5.3 Codex,4.6 Opus, 可灵3.0

软件行业可能正在经历一场比从命令行到图形界面更剧烈的变革?最近听了一场 a16z 的 David George 分享的关于 AI 市场的深度分析,我被一组数据震撼到了:最快增长的 AI 公司正在以 693% 的年增长率扩张,而他们在销售和营销上的支出却远低于传统软件公司。

就在这个被 Anthropic 和 OpenAI 视为衡量 Agent 真实工程能力全球权威基准 Terminal-Bench 2.0 榜单上,中国团队 Feeling AI 凭借 CodeBrain-1,搭载最新 GPT-5.3-Codex 底座模型,一举冲到 72.9%(70.3%) 并跻身全球排行榜第二,成为榜单前 10 中唯一的中国团队。
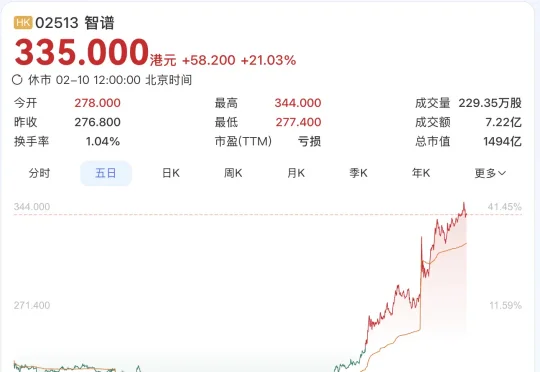
不管Pony Alpha是不是智谱的,下一代旗舰大模型GLM-5都要来了。GLM-5采用了DeepSeek-V3/V3.2架构,包括稀疏注意力机制(DSA)和多Token预测(MTP),总参数量745B,是上一代GLM-4.7的2倍。
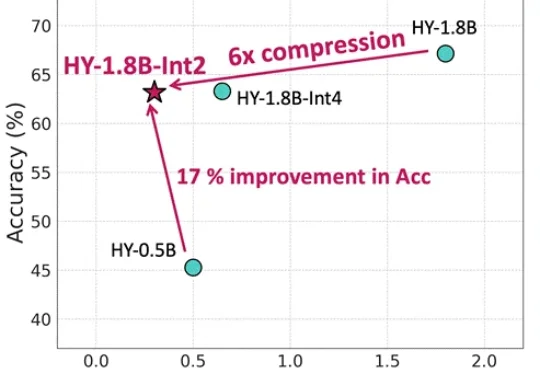
等效参数量仅0.3B,内存占用仅600MB,更适合端侧部署还带思维链的模型来了。腾讯混元最新推出面向消费级硬件场景的“极小”模型HY-1.8B-2Bit,体量甚至比常用的一些手机应用还小。
最近 Cowork 爆火,都说 AI 能自己干活了,那取代个搜索引擎和新闻网站应该是手拿把掐吧。(作者正在办公室瑟瑟发抖:别取代我啊!!)

Contrary 是一家成立于 2018 年的美国风险投资公司,由 Eric Tarczynski 创办,自成立以来,其以“人才驱动+研究驱动”为核心方法论,在全球顶级高校铺设了庞大的人才网络,通过识别最优秀的年轻技术人才来发现投资机会。