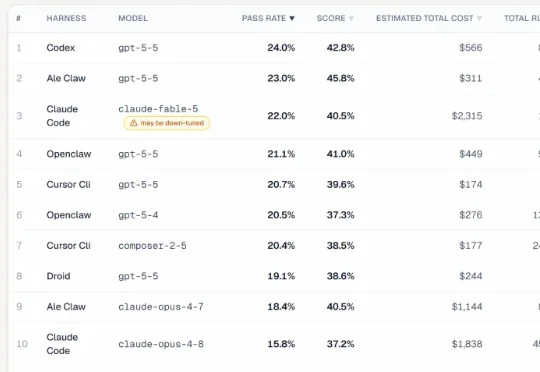
“智能体最后的考试”,Fable 5竟然不敌GPT 5.5
“智能体最后的考试”,Fable 5竟然不敌GPT 5.5刚刚,UC伯克利放出了一场号称“智能体最后的考试”的全新基准测试。它把当今最强的AI Agent们拉到考场上,让它们干真正的活——在Siemens NX里建3D模型、在Unreal Engine里搭游戏场景、在Adobe After Effects里做特效合成。
来自主题: AI技术研报
8998 点击 2026-06-13 10:41
 搜索
搜索
刚刚,UC伯克利放出了一场号称“智能体最后的考试”的全新基准测试。它把当今最强的AI Agent们拉到考场上,让它们干真正的活——在Siemens NX里建3D模型、在Unreal Engine里搭游戏场景、在Adobe After Effects里做特效合成。

在3D创作这个圈子,一直有个心照不宣的扎心真相: 那就是最难的一步从来不是生成,而是让模型变为可用资产。

大模型还在混战,AI及智能硬件市场先跑出了三个“爆款”:AI眼镜、AI录音笔、3D打印机。
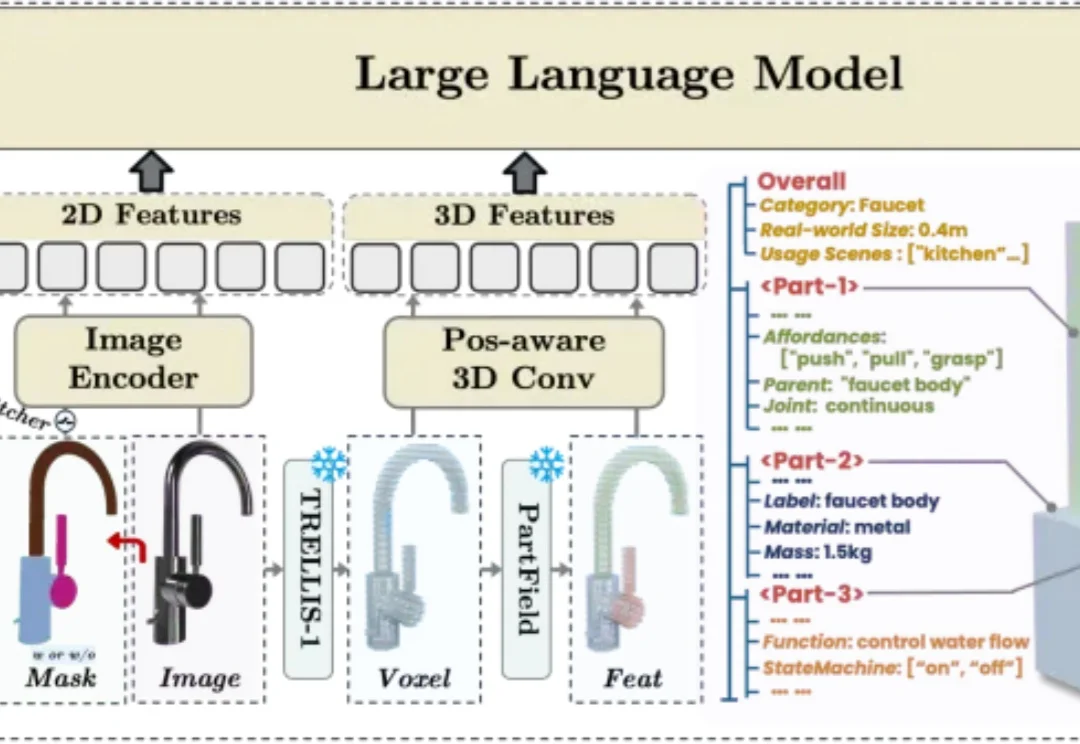
在交互式虚拟世界和具身智能快速发展的今天,高质量 3D 资产已经不再只是 “看起来像” 就足够。一个柜门不仅要有柜门的外观,还需要知道绕哪条轴旋转;一个按钮不仅要有按钮的形状,还需要具备 “按下 / 弹起” 的状态;一个抽屉不仅要有完整几何,还需要拥有滑动方向、运动范围、材质和质量等物理属性。该研究已被 ICML 2026 接收。
6月8日,高德重磅发布了全球首个3D原生城市世界模型——ABot-Earth0.5。ABot-Earth0.5的发布不仅宣告着城市级场景3D原生技术的重要突破,更彻底重塑了传统3D建模的生产逻辑与成本结构。
空间智能与世界模型初创公司知天下(苏州)人工智能科技有限公司(以下简称“知天下”)近日已完成天使轮融资。知天下是一家专注于高斯泼溅(3D Gaussian Splatting,简称3DGS)三维重建与生成技术的AI企业,于 2024 年初推出 3DGS 免费重建与发布服务
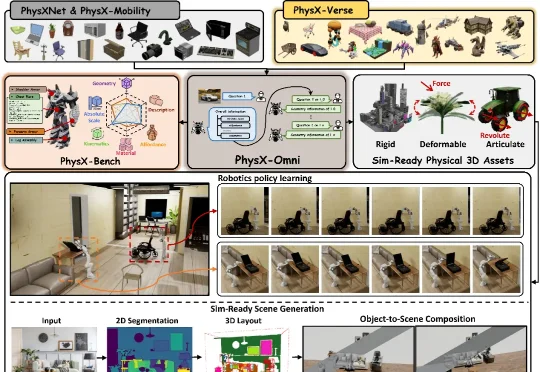
该论文第一作者为曹子昂,研究方向主要聚焦于 3D AIGC、Physical AI 与具身智能。论文主要合作者包括来自南洋理工大学的李海天、姚润茂、洪方舟、陈昭熹,以及大晓机器人的刘英豪和潘亮。通讯作者为南洋理工大学刘子纬教授。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,

计算机界「青年图灵奖」出炉了!今天,2025 ACM Grace Hopper大奖正式揭晓,一锤砸中了两位灵魂人物——获奖理由只有一个词:NeRF(神经辐射场)。
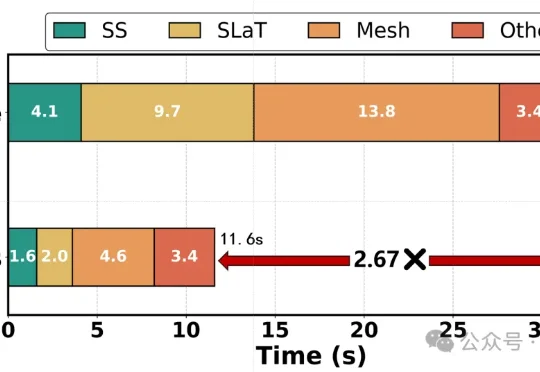
来自中国科学院计算技术研究所、ETH Zurich等机构的研究者提出了Fast-SAM3D。该方法直接面向SAM3D的推理链路做训练无关加速,在最大程度保持重建质量的同时,将单对象生成提速最高2.67倍,场景生成提速最高2.01倍。