
4秒出百万面!突破千万面精度+12K高清贴图,手握数亿的3D生成公司下一局怎么打?
4秒出百万面!突破千万面精度+12K高清贴图,手握数亿的3D生成公司下一局怎么打?今年2月,英伟达公开了一条内部AI工作流。
来自主题: AI技术研报
9753 点击 2026-06-25 15:24
 搜索
搜索
今年2月,英伟达公开了一条内部AI工作流。

2020年,吴迪读研一,张启煊念大三,他们跟同为上海科技大学学生的张龙文、曾初啸一起创办了影眸科技。公司早期做过一系列有关3D与生成的探索——做过穹顶光场扫描,做过二次元APP,做过数字人,踩过元宇宙的尾巴,也经历过几乎没有现金流的至暗时刻。

新模型上线首月,订阅用户与 ARR 的环比增速均超 400%。 文|王欣逸 编辑|张雨忻 2026 年开年来,3D 生成模型赛道相当热闹。 今年第一季度,影眸科技发布首个 3D 编辑模型 Rodin
GPT-5.6 Pro 泄露炸场:推理能力涨 25%、知识截止推至 2025 年 12 月、3D 生成碾压 Fable,一句话 48 分钟在聊天框里直接跑出完整《模拟人生》。

如今,CameraSquad 的出现,让这种多视角一致的视频生成与 3D 世界状态构建成为现实。近日,中国科学院大学高林研究员团队联合卡迪夫大学、香港科技大学和快手可灵团队,提出了一种面向多轨迹并行生成的相机可控视频生成方法 CameraSquad [1],相关论文已被 ACM SIGGRAPH 2026 录用。

搞AI绘画的Midjourney,要干上Spa了???
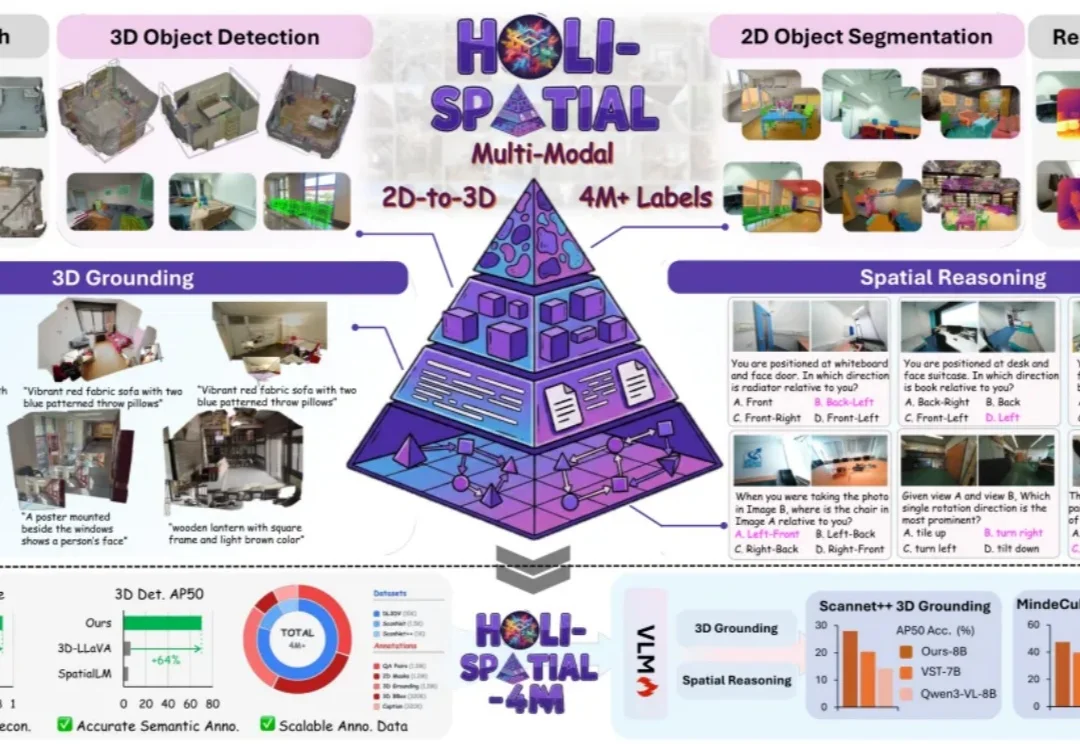
从原始视频出发,无需人工介入,自动生成 3D 重建、深度、2D mask、3D 框、实例描述、3D grounding 和空间问答。Holi-Spatial 试图把「空间智能」的数据生产,推进到自动化、可扩展的新阶段。

PE-Field将传统的2D位置编码扩展为结构化的3D场,使DiT能够更加直接地在3D空间中处理几何信息。
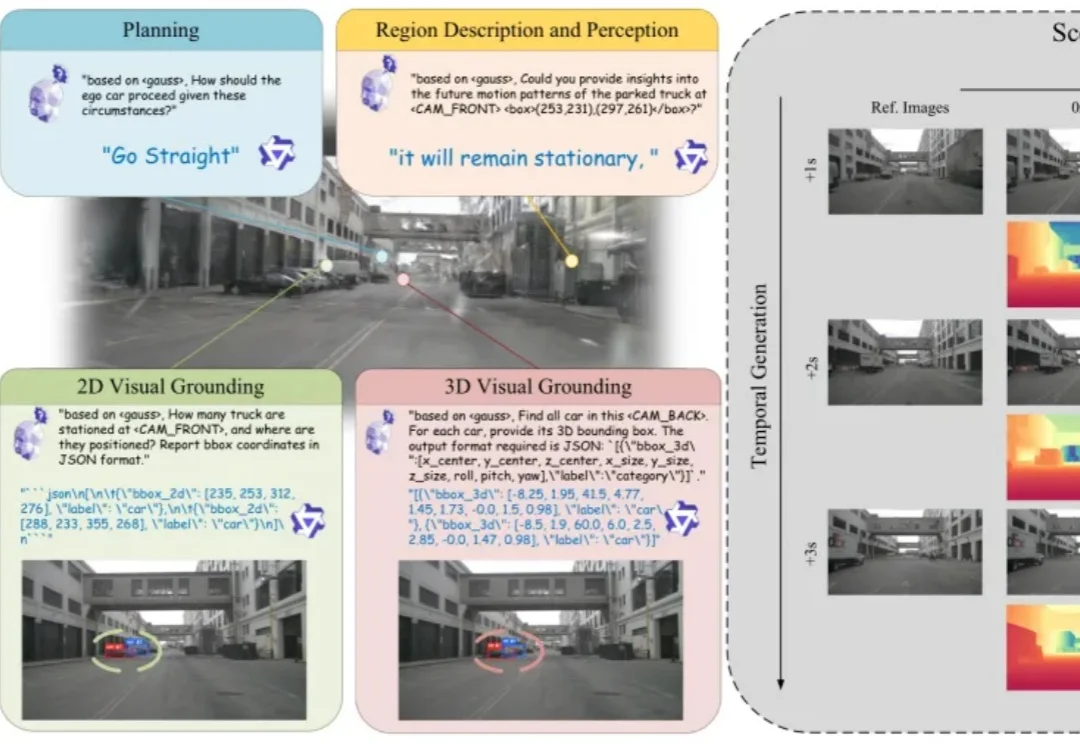
自动驾驶世界模型的研究目标已经从单纯预测未来视觉帧,扩展到构建可用于场景理解、空间定位和后续决策的世界表示。如果模型只能生成外观上合理的未来图像,却无法回答场景中有哪些目标、目标位于何处,以及不同视角下的空间结构如何变化,那么它仍然缺少对三维驾驶环境的显式建模能力。

今天,由李飞飞联合创立的空间智能公司 World Labs 在同一天发布了三篇技术论文!三篇论文分别由公司内部实习生主导完成,研究方向各异,但共享同一个核心命题:借助已在海量图片数据上训练成熟的 2D 生成模型,降低 3D 内容生成的难度门槛。