3D领域DeepSeek「源神」启动!国产明星创业公司,一口气开源八大项目
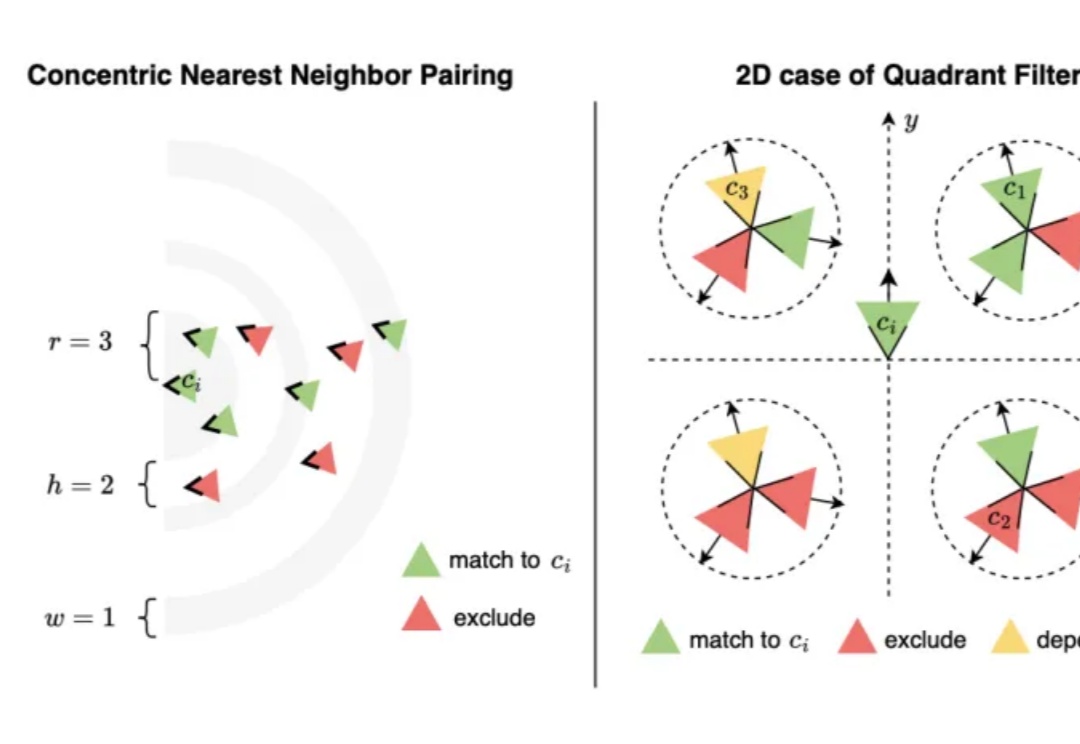
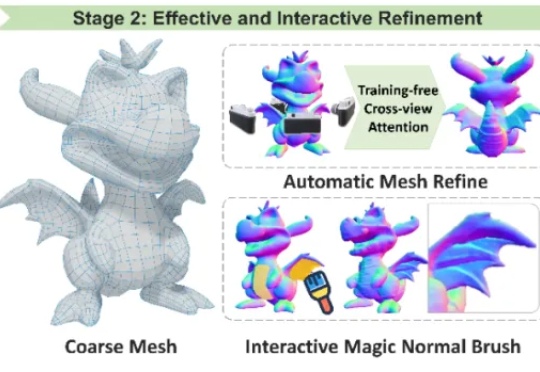
3D领域DeepSeek「源神」启动!国产明星创业公司,一口气开源八大项目3 月 28 日,专注于构建通用 3D 大模型的 VAST 一口气开源了两个 3D 生成项目 ——TripoSG 和 TripoSF。前者是一款基础 3D 生成模型,在图像到 3D 生成任务上远超所有闭源模型;后者则是 VAST 新一代三维基础模型 TripoSF 能在所有闭源模型中同样取得 SOTA 的基础组件,用于高分辨率的三维重建和生成任务。
来自主题: AI技术研报
10013 点击 2025-03-29 09:39