
刚刚,Mind Lab开源V1系列模型Preview,749B参数,专为Agent 后训练
刚刚,Mind Lab开源V1系列模型Preview,749B参数,专为Agent 后训练过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。
来自主题: AI技术研报
6307 点击 2026-06-08 15:29
 搜索
搜索
过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。

不扩上下文窗口、不换骨干架构、不做全参数微调 —— 只需要一个 8×8 的在线状态矩阵,就能让冻结的 Transformer 拥有真正的长期记忆。

春节AI大战过去仅半年不到,千问、豆包这两大AI产品又在618期间隔空“赛跑”。 《读佳》获知,在618电商大促前夕,千问APP正悄悄内测“AI帮我挑”的全新功能,这是千问与淘宝全面互通后的又一关键布
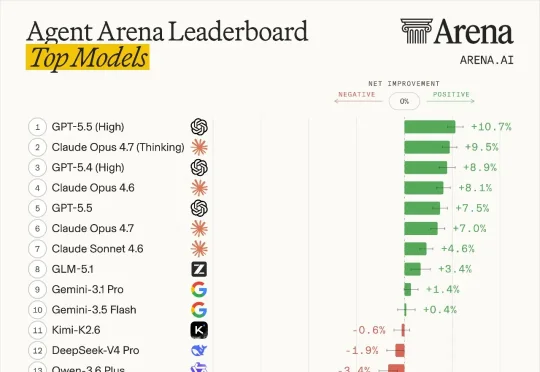
6月4日,Arena.ai发布Agent Arena排行榜,用373,431次真实会话的数据,给18个主流模型的Agent能力排了个座次。先看总榜。Agent Arena的排名依据是“净改进”(Net Improvement),用因果推断方法算出每个模型相对于随机基线的性能提升幅度。正值代表比随机选择更好,负值说明不如随机。

奇点灵智做了一款支持 Vibe Coding 的儿童硬件。 产品叫多奇 AI 小外教机器人,面向 3-8 岁孩子。今年 1 月在京东首发,首发期间产品进入京东榜单 Top 2,目前全平台订单超过 2
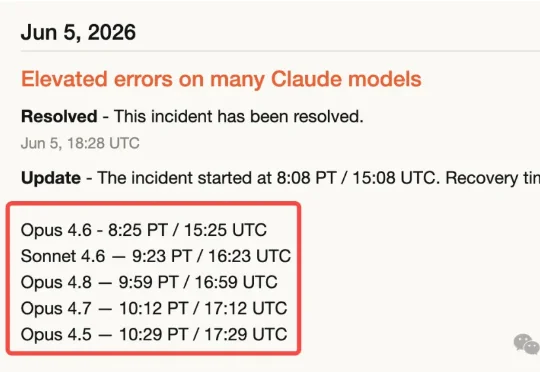
就在昨天,Anthropic 的官方状态页突然挂起一排刺眼的红灯——Claude API、Claude Code、Claude.ai、Claude Cowork……几乎所有核心服务,突然大面积宕机。从 Opus 4.6 到 Opus 4.8,五大模型无一幸免。

1985 年,教育部高考语文研究组编了一本书,《全国高考作文评分系统与各类标准卷选》,那是一个关注语言水平、写作创造力和文字如何反映生活的时代,高考作文既是一种考察写作能力的方式,也是教书育人理念的延

智东西6月6日消息,据《福布斯》今日报道,瑞典明星AI氛围编程创企Lovable正在洽谈融资,估值将达到120亿美元(约合人民币812亿元)。四位消息人士透露,新资金注入将使Lovable的估值几乎翻番,高于去年12月的66亿美元(约合人民币447亿元)。
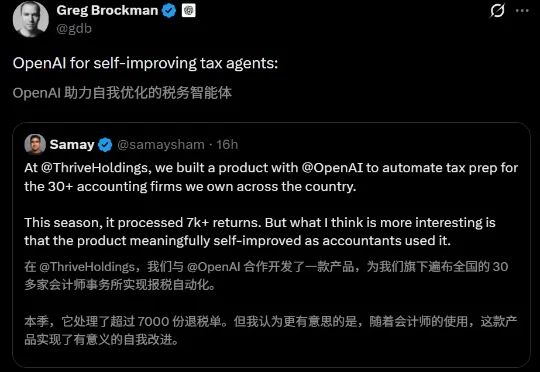
没人重训模型,没人重写代码,OpenAI的AI系统六周内自己把准确率从25%拉到86%。Codex自己定位bug、写修复、跑测试,AI自我进化已在生产环境跑起来了。

数学,这块人类心智的荣耀,正面临一场前所未有的「降维打击」。当算法的「非人化」优势把80年的接力变成32小时的副产品时,我们不得不问:人类到底想要一个又一个正确答案,还是想要理解这些答案的过程?