ICRA 2026|NUS邵林团队提出T(R,O) Grasp:刷新跨智能体灵巧抓取SOTA,实现5FPS动态环境交互
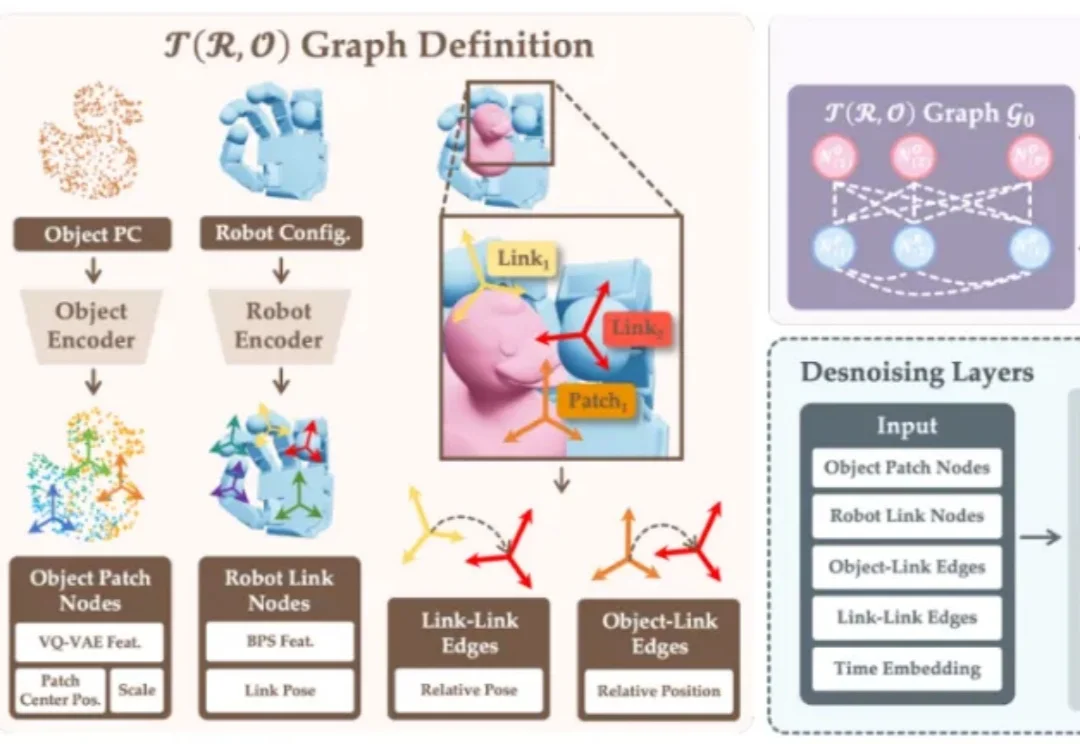
ICRA 2026|NUS邵林团队提出T(R,O) Grasp:刷新跨智能体灵巧抓取SOTA,实现5FPS动态环境交互T (R,O) Grasp 是一种基于物体 — 机器手空间关系建模的图扩散架构,具备跨智能体的统一表征能力。在 NVIDIA 40GB A100 GPU 上,该方法可实现 5 FPS 的推理速度和 50 grasp/s 的吞吐量,并在多种智能体上取得 94.83% 的平均抓取成功率,刷新了跨智能体灵巧抓取的 SOTA,具备与动态场景实时交互的能力。
来自主题: AI技术研报
6706 点击 2026-04-13 09:38