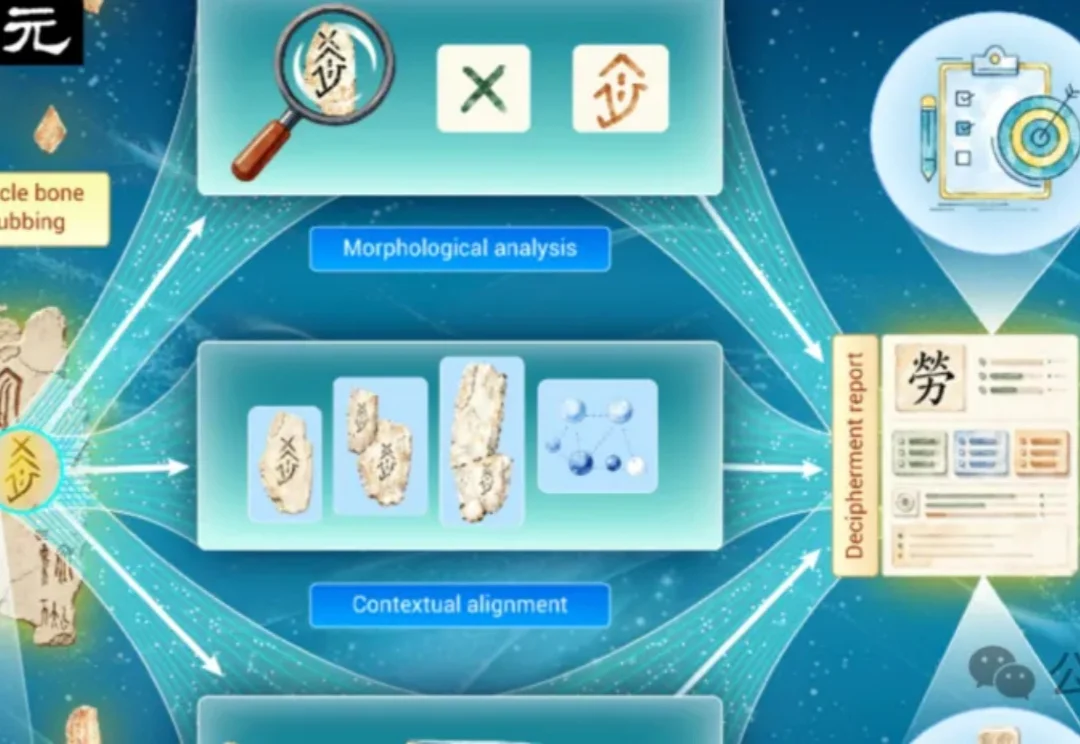
让沉默三千年的甲骨开口:首个模仿人类专家工作流的辅助释读系统
让沉默三千年的甲骨开口:首个模仿人类专家工作流的辅助释读系统一片龟甲或牛肩胛骨摆在案头,裂纹穿过刻辞,几个字还缺了笔画。
来自主题: AI技术研报
9143 点击 2026-08-03 15:33
 搜索
搜索
一片龟甲或牛肩胛骨摆在案头,裂纹穿过刻辞,几个字还缺了笔画。
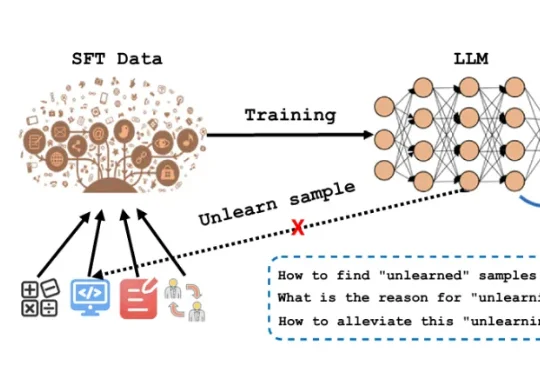
SFT是LLM从“通才”变成“专才”的关键步骤。业界默认做法是:准备标注数据(QA对、指令-回复对等)在基座模型上跑SFT训练。看loss曲线收敛了→认为训练完成。但问题在于:loss是全局平均,掩盖了样本间的差异。loss收敛只代表“大部分样本学会了”——那些始终学不会的样本被淹没了。
过去一年,Deep Research Agent 被视为大模型落地的下一个突破口,它们会检索、能用工具、可多步推理,在一个个榜单上高歌猛进。但把它们放到真实世界的专业场景里,表现是否也同样亮眼?

全双工语音对话是人类最自然的交流方式,是语音对话研究的梦想。相比文本输入,语音天然更接近人的交流方式,但现有语音对话常常停留在 “一问一答、听完再说” 的轮次式交互范式。
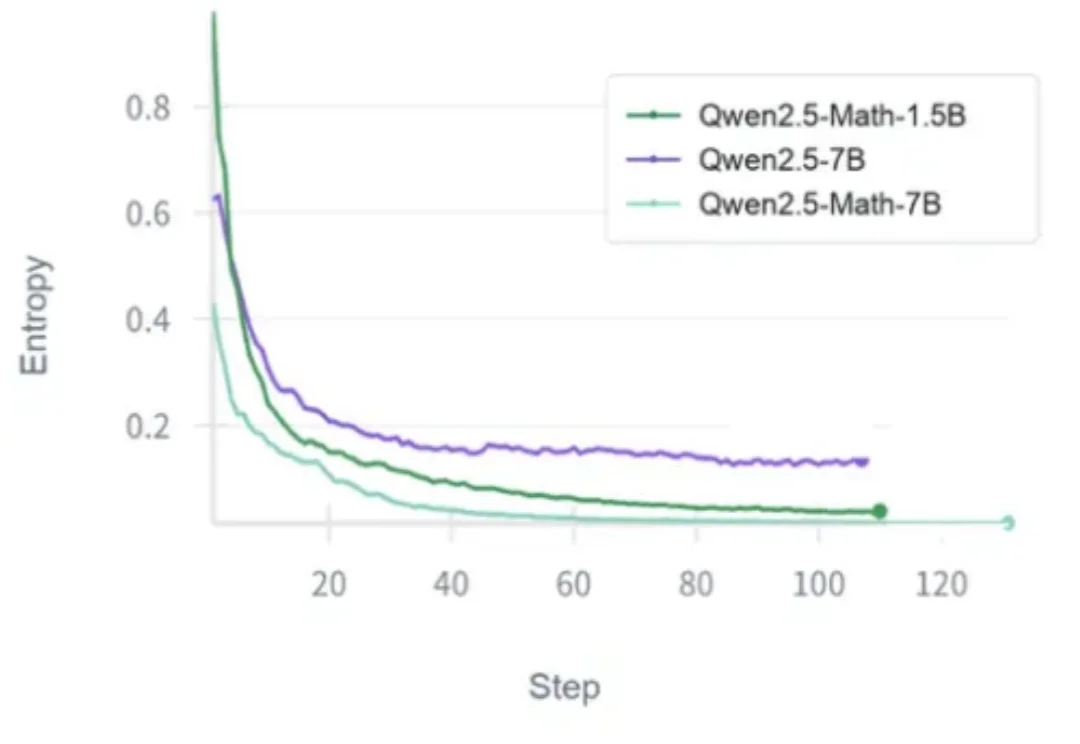
基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards,RLVR)正在成为大模型后训练的关键技术。数学题能判对错,代码能跑测试,可验证奖励让大模型可以通过强化学习持续提升推理能力。

大家好,我是冷逸。 前段时间,我设计了一家民宿「冷同学的院子」,视觉还算有点意思,不少朋友跑来问设计上的事。也有人问我:要是自己网上开店,有没有那种“够简单、说一句就能出设计”的电商工具?

研究团队提出了 XG-Guard (eXplainable and fine-Grained safeGuarding framework), 一个基于 GAD 且兼具可解释性和细粒度检测能力的无监督安全防护框架。目前工作已被 ACL 2026 Main Conference 接收。
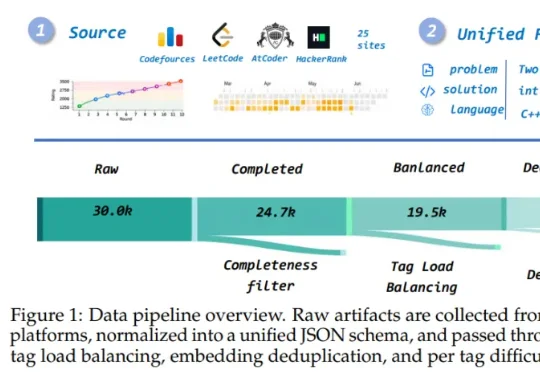
大语言模型在代码生成上的能力不断增强,但在复杂算法题,尤其是竞赛编程场景中,仍然容易因为算法选择错误、边界条件遗漏、复杂度判断失误或隐藏测试覆盖不足而失败。Solvita是一款面向竞赛编程的智能体框架,通过四个角色(Planner、Solver、Oracle、Hacker)形成闭环系统,并利用可训练的图结构知识网络积累经验。
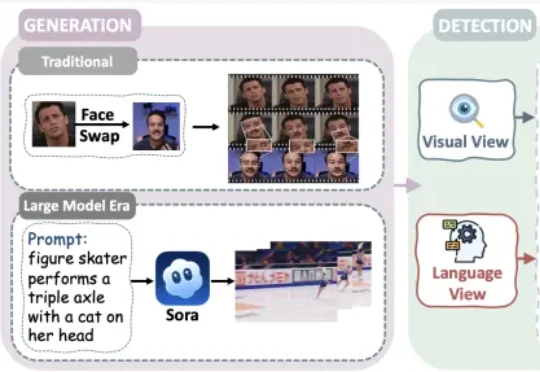
AI视频生成技术迅猛发展,生成内容的逼真度不断提升,现有检测方法已无法满足需求。最新综述提出「事实保真度验证」新目标,从视觉与语言双视角梳理出四层检测框架,涵盖底层线索、时空一致性、跨模态核验及世界知识推理,强调多层证据耦合与可解释性。

数据中心新秀 Crusoe 与 Meta 和 Oracle 等公司签有为其提供人工智能计算能力的合同,据知情人士称,Crusoe 正就一轮约 30 亿美元的融资进行谈判,此次融资可能使公司的估值翻三倍。