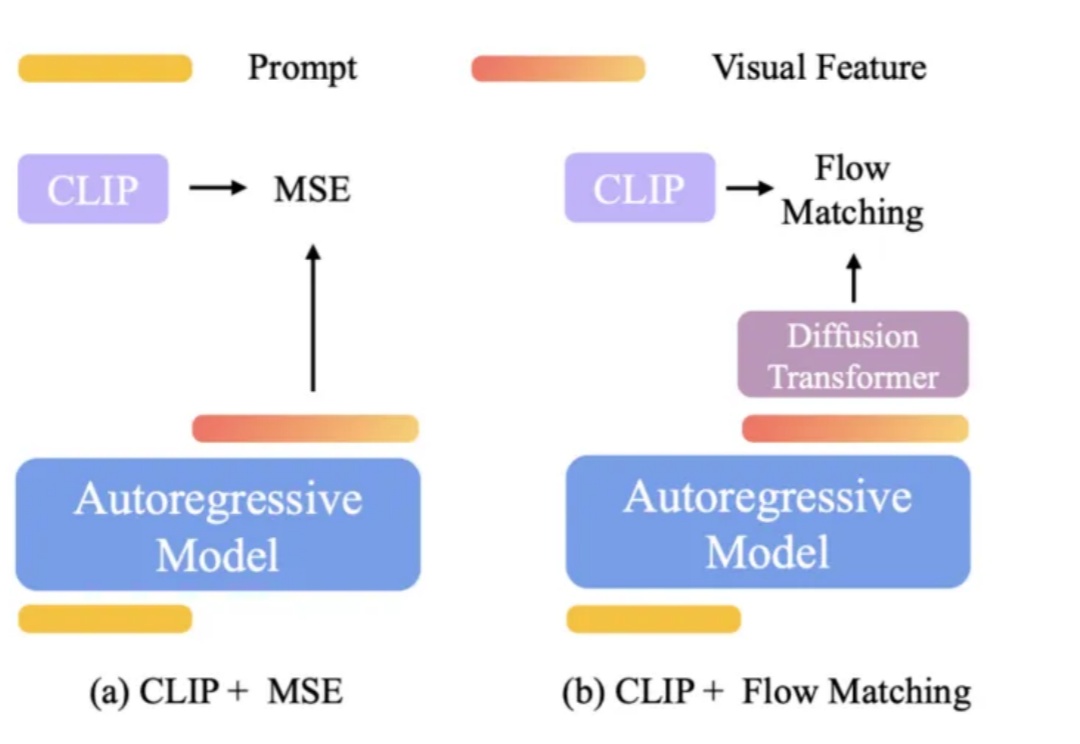
自回归+扩散!Salesforce开源统一多模态模型BLIP3-o,图像理解与生成全拿下
自回归+扩散!Salesforce开源统一多模态模型BLIP3-o,图像理解与生成全拿下OpenAI 的 GPT-4o 在图像理解、生成和编辑任务上展现了顶级性能。流行的架构猜想是:
来自主题: AI技术研报
11251 点击 2025-05-23 11:42
 搜索
搜索
OpenAI 的 GPT-4o 在图像理解、生成和编辑任务上展现了顶级性能。流行的架构猜想是:

普林斯顿大学与字节 Seed、北大、清华等研究团队合作提出了 MMaDA(Multimodal Large Diffusion Language Models),作为首个系统性探索扩散架构的多模态基础模型,MMaDA 通过三项核心技术突破,成功实现了文本推理、多模态理解与图像生成的统一建模。
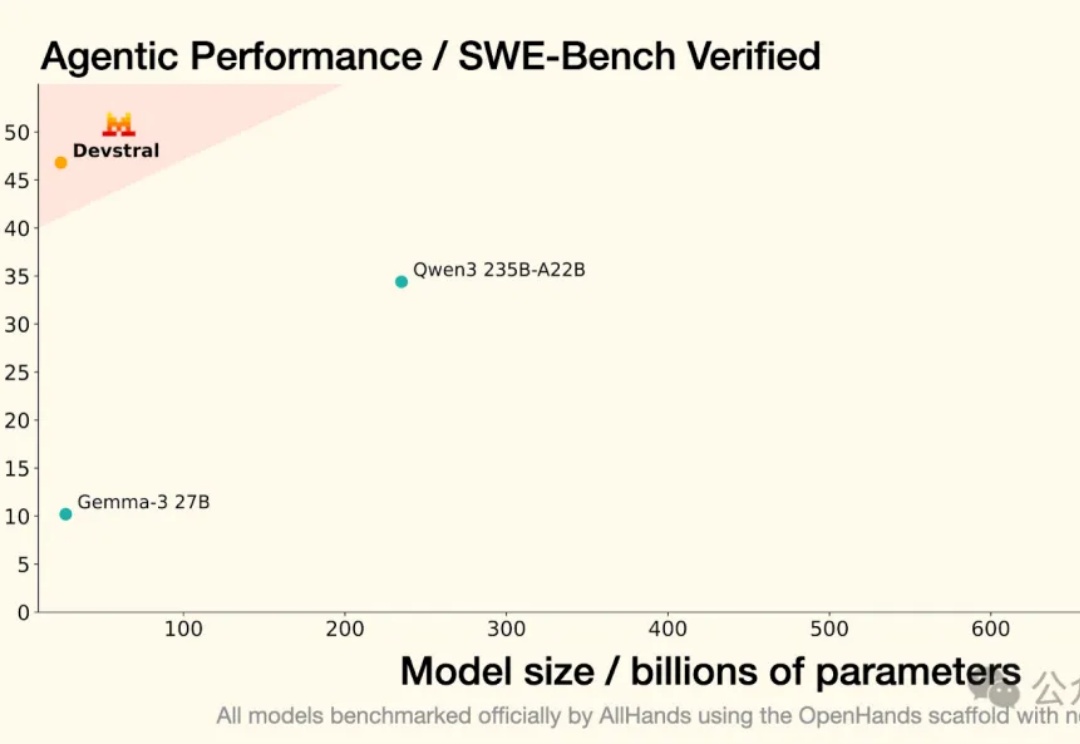
Mistral沉默好久,果然在憋大招。
就在刚刚,OpenAI 正式官宣,将以接近 65 亿美元(折合人民币 468.16 亿元)的价格收购由 OpenAI CEO Sam Altman 与前苹果首席设计官 Jony Ive 联合创办的 AI 设备初创公司 io。
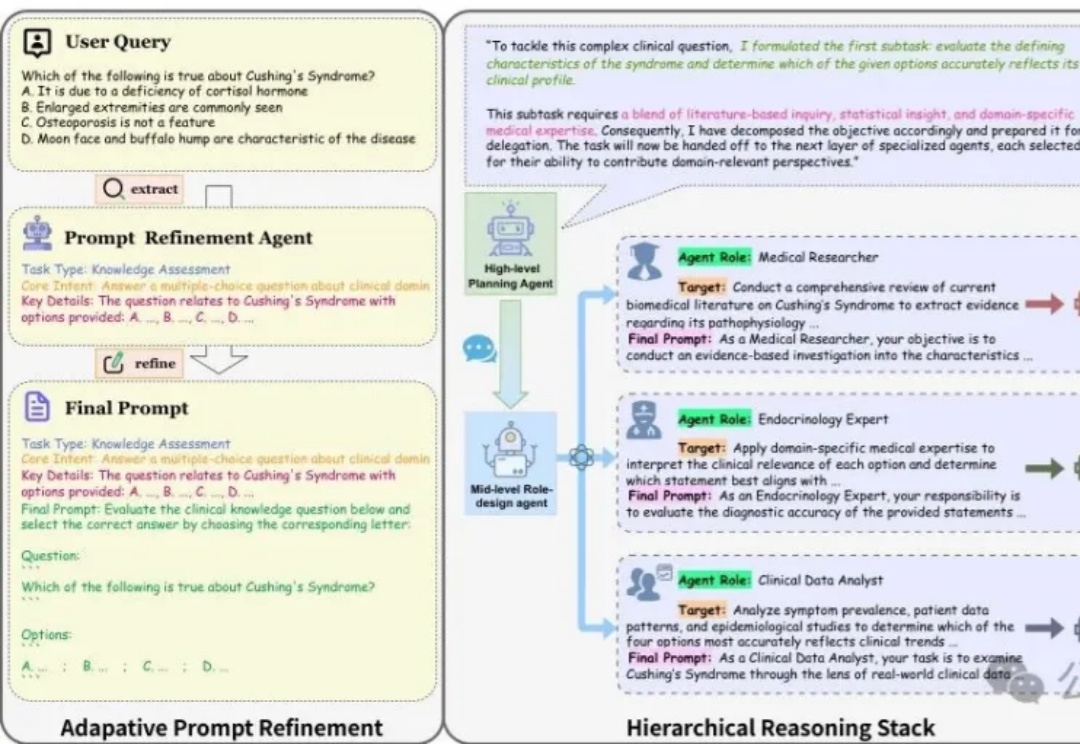
HALO框架通过三大创新机制重塑多Agent(MAS)协作方式:层次化推理架构克服了认知过载问题,让智能体各司其职;动态角色实例化能针对不同任务匹配专业智能体;基于MCTS的搜索引擎自动探索最优推理路径。它能将模糊的用户查询转化为专业提示,分解复杂任务并动态调整执行计划。
北京时间5月21日凌晨,谷歌在每年一度的I/O大会上再度炸场——谷歌搜索的AI模式正式上线。其中,最受瞩目的一个功能是Personal Context(个人上下文)。北京时间5月21日凌晨,谷歌在每年一度的I/O大会上再度炸场——谷歌搜索的AI模式正式上线。其中,最受瞩目的一个功能是Personal Context(个人上下文)。
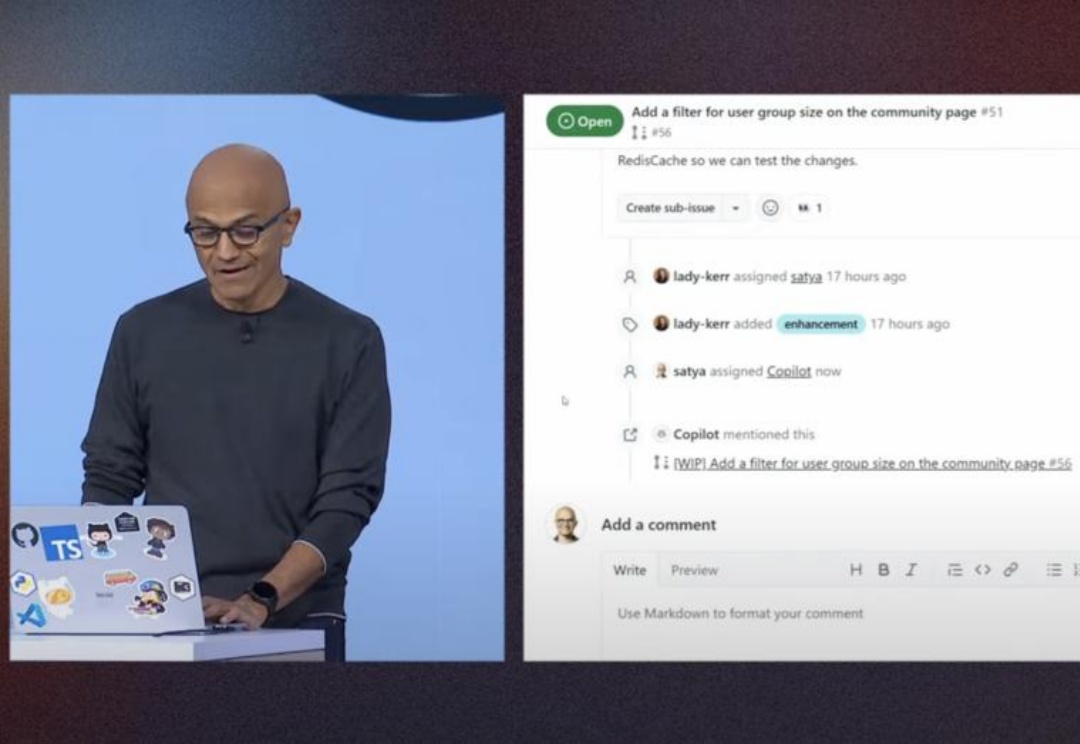
微软Build 2025全面转向AI Agent,整合OpenAI及xAI模型

太震撼了,有开发者代码实证后发现,谷歌AlphaEvolve的矩阵乘法突破,被证明为真!Claude辅助下,他成功证明,它果然仅用了48次乘法,就正确完成了4×4矩阵的乘法运算。接下来,可以坐等AlphaEvolve更「奇点」的发现了。
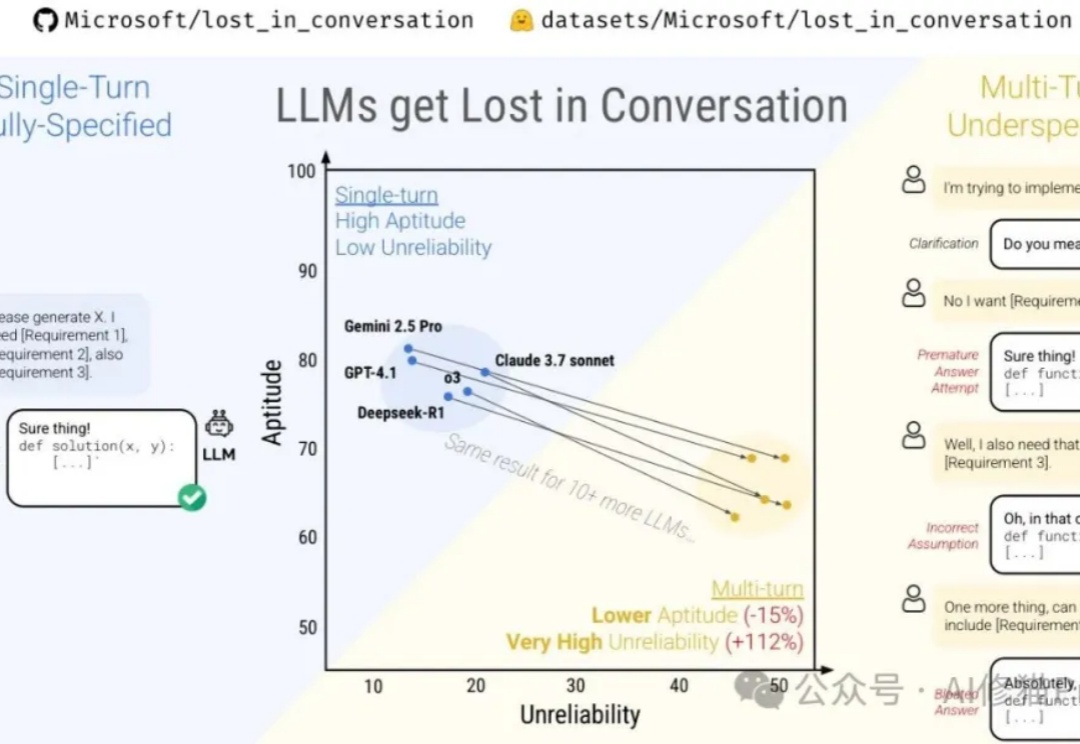
微软最近与Salesforce Research联合发布了一篇名为《Lost in Conversation》的研究,说当前最先进的LLM在多轮对话中表现会大幅下降,平均降幅高达39%。这一现象被称为对话中的"迷失"。文章分析了各大模型(包括Claude 3.7-Sonnet、Deepseek-R1等)在多轮对话中的表现差异,还解析了模型"迷失"的根本原因及有效缓解策略。
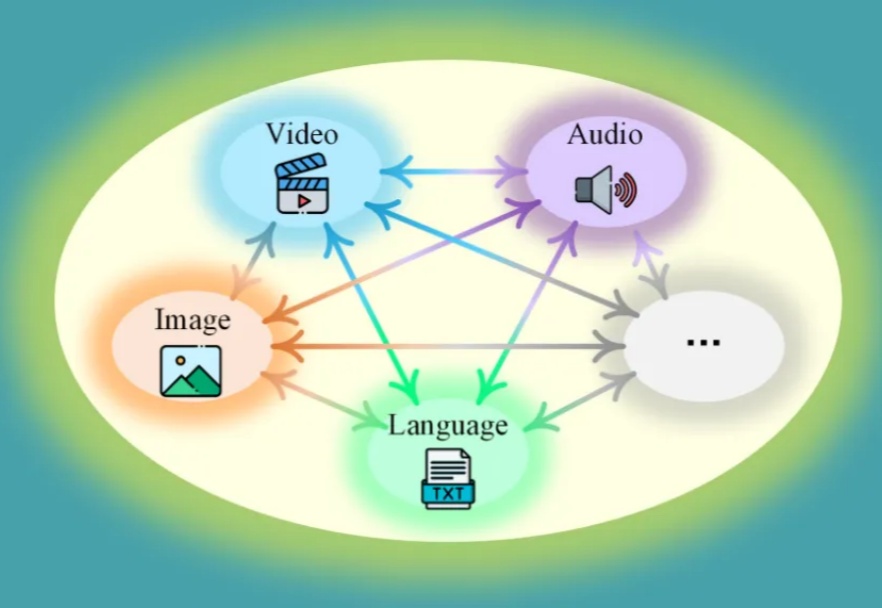
理想中的多模态大模型应该是什么样?十所顶尖高校联合发布General-Level评估框架和General-Bench基准数据集,用五级分类制明确了多模态通才模型的能力标准。当前多模态大语言模型在任务支持、模态覆盖等方面存在不足,且多数通用模型未能超越专家模型,真正的通用人工智能需要实现模态间的协同效应。